이 글은 누구나 자료 구조와 알고리즘(저자 : 제이 웬그로우)의 내용을 개인적으로 정리하는 글임을 알립니다.
버블 정렬
버블 정렬은 단순 정렬(simple sort)이라 알려졌다.
이해하기 쉬워서 이렇게 불리지만, 더 빠르다고 알려진 정렬 알고리즘보다 비효율적이다.
버블 정렬은 아래와 같은 단계를 따른다.
1. 배열 내에서 연속된 두 항목을 가리킨다. 즉, 첫 번째 항목과 두번째 항목을 비교한다.

2. 두 항목의 순서가 뒤바뀌어있으면, 두 항목을 교환한다. (순서가 올바르다면 2단계에선 아무것도 하지 않는다.)

3. 포인터를 오른쪽으로 한 셀씩 옮긴다.

4. 배열의 끝까지 또는 이미 정렬된 값까지 1단계부터 3단계를 반복한다.
이제 배열의 첫 패스스루(pass-through)가 끝났다. 즉, 배열 끝까지 값을 하나하나 가리키며 배열을 통과했다.
5. 이제 두 포인터를 다시 배열의 처음 두 값으로 옮겨서 1단계부터 4단계를 다시 실행함으로써 새로운 패스스루를 실행한다.
교환이 일어나지 않는 패스스루가 생길 때까지 패스스루를 반복한다.
교환할 항목이 없다는 것은 배열이 정렬됐고 문제를 해결했다는 뜻이다.
더 자세히 버블 정렬 살펴보기
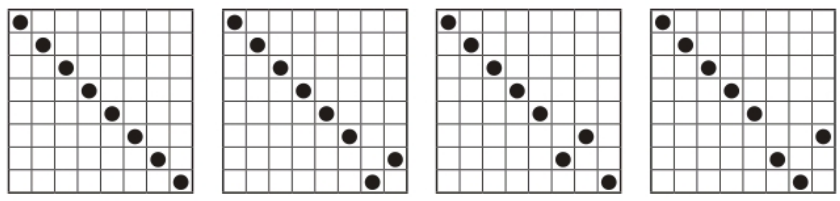
[4, 2, 7, 1, 3] 이라는 배열을 정렬하고 싶다고 가정하자.
순서가 뒤죽박죽인 데다 중복 값까지 있는 배열을 올바르게 오름차순으로 정렬해야한다.
첫 번째 패스스루 시작
배열의 처음 상태는 아래와 같다.

1단계 : 먼저 4와 2를 비교한다.

2단계 : 순서가 맞지 않으므로 둘을 교환한다.

3단계 : 다음으로 4와 7을 비교한다.

순서가 올바르기 때문에 교환할 필요가 없다.
4단계 : 7과 1을 비교한다.

5단계 : 순서가 맞지 않으므로 교환한다.

6단계 : 7과 3을 비교한다.

7단계 : 순서가 맞지 않으므로 교환한다.

이제 7은 확실히 배열 내에서 올바른 위치에 있다.
적절한 위치에 도달할 때까지 7을 계속해서 오른쪽으로 옮겼기 때문이다.
이 알고리즘을 버블 정렬이라 부르는 까닭이 여기에 있다.
각 패스스루마다 정렬되지 않은 값중 가장 큰 값, 버블이 올바른 위치로 가게 된다.
첫 번째 패스스루에서 교환을 적어도 한 번 수행했으니 다음 패스스루도 수행해야 한다.
두 번째 패스스루 시작
8단계 : 2와 4를 비교한다.

올바른 순서이므로 다음 단계로 넘어간다.
9단계 : 4와 1을 비교한다.

10단계 : 순서가 맞지 않으므로 교환한다.

11단계 : 4와 3을 비교한다.

12단계 : 순서가 맞지 않으므로 교환한다.

첫 번째 패스스루를 통해 7이 이미 올바른 위치라는 것을 알고 있으니 4와 7은 비교할 필요가 없다.
또한, 이제 4 역시 올바른 위치로 올라갔다.
이로써 두 번째 패스스루도 끝났다.
두 번째 패스스루에서 교환을 적어도 한 번 수행했으니 다음 패스스루를 수행해야 한다.
세번째 패스스루 시작
13단계 : 2와 1을 비교한다.

14단계 : 순서가 맞지 않으니 교환한다.

15단계 : 2와 3을 교환한다.

순서가 올바르니 교환할 필요가 없다.
이제 3이 올바른 위치로 갔다.

세 번째 패스스루에서 교환을 적어도 한 번 수행했으니 다음 패스스루를 수행해야 한다.
네 번째 패스스루 시작
16단계 : 1과 2를 비교한다.

순서가 올바르니 교환할 필요가 없다. 나머지 값은 모두 이미 정렬되었으니 네 번째 패스스루를 종료할 수 있다.
어떤 교환도 하지 않은 패스스루였으므로 이제 이 배열은 완전히 정렬되었다.

버블 정렬 구현
아래의 코드는 버블 정렬을 파이썬으로 구현한 코드이다.
def bubble_sort(list):
unsorted_until_index = len(list) - 1
sorted = False
while not sorted:
sorted = True
for i in range(unsorted_until_index):
if list[i] > list[i+1]:
list[i], list[i+1] = list[i+1], list[i]
sorted = False
unsorted_until_index -= 1
return list
버블 정렬의 효율성
버블 정렬 알고리즘은 두 가지 중요한 단계를 포함한다.
- 비교 : 어느쪽이 더 큰지 두수를 비교한다.
- 교환 : 정렬하기 위해 두 수를 교환한다.
먼저 버블 정렬에서 얼마나 많은 비교가 일어났는지 보면
5개의 원소를 갖는 배열에서
첫 번째 패스스루 : 4번
두 번째 패스스루 : 3번
세 번째 패스스루 : 2번
네 번째 패스스루 : 1번
총 : 4 + 3 + 2 + 1 = 10번의 비교가 일어났다.
즉, 원소가 N개 있을 때, (N-1) + (N-2) + (N-3) + ... + 1번의 비교를 수행한다.
버블 정렬에서 얼마나 교환이 일어났는지 보면
배열이 오름차순이 아닌 내림차순으로 정렬되어 있는 최악의 시나리오라면 비교할때마다 교환을 해야한다.
이런 시나리오에서는 비교 10번, 교환 10번이 일어나 총 20단계가 필요하다.
값 10개가 역순으로 된 배열에서는 45번의 비교와 45번의 교환이 일어나 총 90단계이고,
값 20개가 역순으로 된 배열에서는 190번의 비교와 190번의 교환이 일어나므로 총 380단계이다.


원소가 N개일 때, 단계는 대략 N²인 것을 확인할 수 있다.
따라서 버블 정렬의 시간 복잡도를 빅 오 표기법으로 나타내면 원소가 N개일때, N²단계가 필요하므로 O(N²)이다.
O(N²)은 데이터가 증가할 때 단계 수가 급격히 늘어나므로 비교적 비효율적인 알고리즘으로 간주된다.

참고로 O(N²)을 이차 시간이라고도 부른다.
또한 중첩 반복문을 사용하는 알고리즘은 대부분 O(N²)의 시간복잡도를 가진다.
'자료구조 & 알고리즘 > 알고리즘' 카테고리의 다른 글
| [알고리즘] 삽입 정렬과 빅 오(Big O) (0) | 2023.09.01 |
|---|---|
| [알고리즘] 선택 정렬과 빅 오(Big O) (0) | 2023.08.31 |
| [Java] 8퀸 문제(분기한정법) (0) | 2023.08.29 |
| [Java] 재귀 알고리즘 메모화 (1) | 2023.08.28 |
| [알고리즘] 빅 오 (Big O) 표기법 (0) | 2023.08.27 |