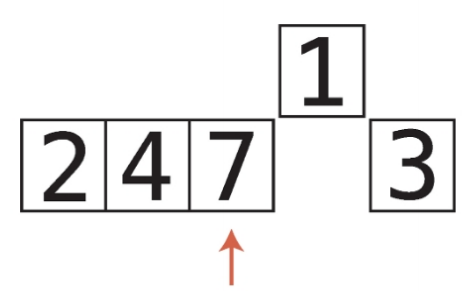
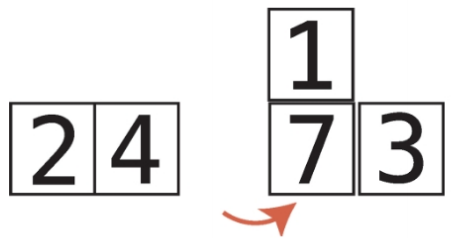
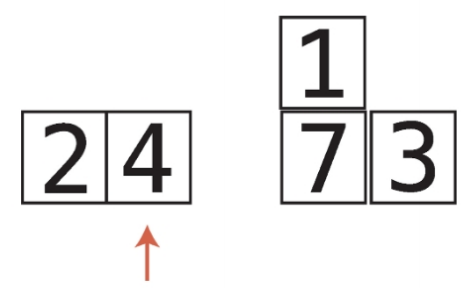
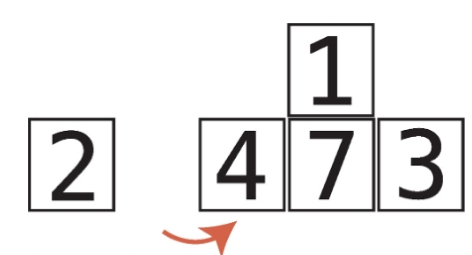
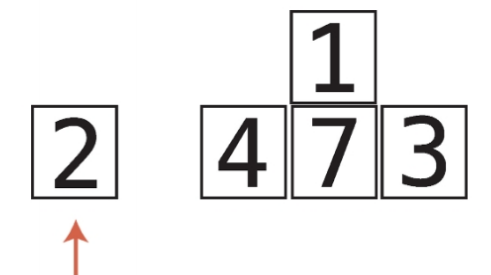
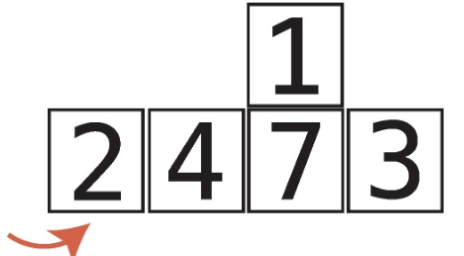
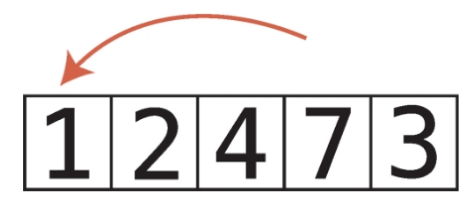
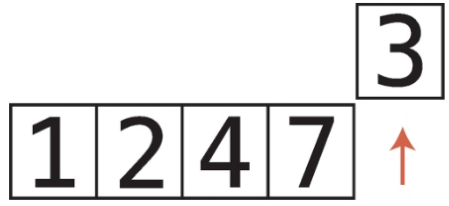
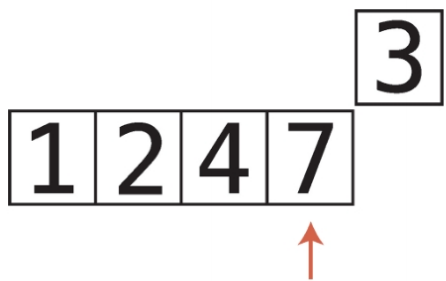
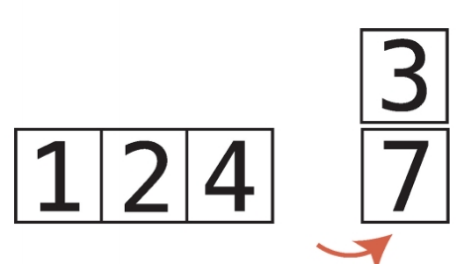
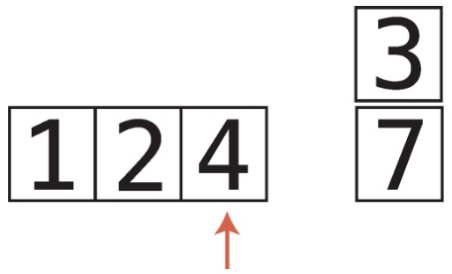
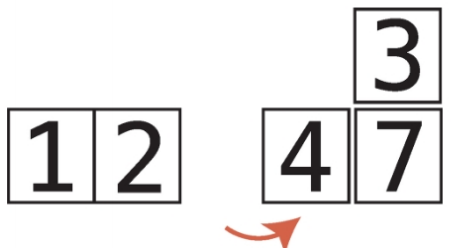
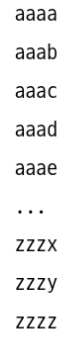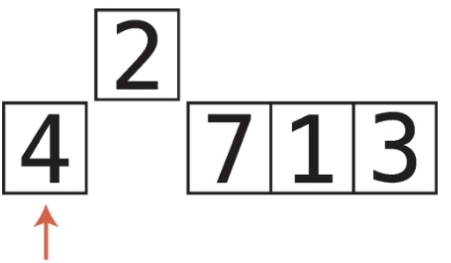비내림차순 비내림차순은 내림차순과 반대되는 개념이다. 즉, 오름차순과 비슷한 개념이다. 하지만 오름차순과는 차이가 있다. 오름차순은 왼쪽에서 오른쪽으로 갈때 무조건 숫자가 커져야하지만, 비내림차순은 왼쪽에서 오른쪽으로 갈때 같은숫자가 있을 수도 있다. chatGPT 답변내용
import java.util.Arrays;
import java.util.Collections;
import java.util.Scanner;
public class Main
{
public static void main(String[] args)
{
Scanner sc = new Scanner(System.in);
int N = sc.nextInt();
int me = sc.nextInt(); //나 == 다솜
Integer arr[] = new Integer[N-1]; //내림차순 정렬을 위해 박싱
int count = 0; //매수해야 하는 사람 수
for(int i = 0; i < arr.length; ++i) arr[i] = sc.nextInt();
while(true)
{
Arrays.sort(arr, Collections.reverseOrder()); //내림차순 정렬
if(N == 1 || arr[0] < me) break; //N이 0이거나 배열의 가장 큰 수가 나보다 작으면 탈출
else
{
++me;
--arr[0];
++count;
}
}
System.out.print(count);
}
}
설명
나(다솜)과 다른 후보의 득표 수를 받는다.
다른 후보의 득표수를 저장한 배열을 내림차순으로 정렬시킨다.
가장 큰 득표수(arr[0])이 나보다 작으면 반복문을 탈출하고, 그렇지 않다면 가장 많은 득표수를 받은 후보의 지지자 한명을 매수한다.
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.util.Arrays;
import java.util.Collections;
import java.util.StringTokenizer;
public class Main
{
public static void main(String[] args) throws Exception
{
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
int n = Integer.parseInt(br.readLine());
int A[] = new int[n];
Integer B[] = new Integer[n];
StringTokenizer st = new StringTokenizer(br.readLine());
for(int i = 0; st.hasMoreTokens() == true; ++i) A[i] = Integer.parseInt(st.nextToken());
st = new StringTokenizer(br.readLine());
for(int i = 0; st.hasMoreTokens() == true; ++i) B[i] = Integer.parseInt(st.nextToken());
Arrays.sort(A);
Arrays.sort(B, Collections.reverseOrder());
int sum = 0;
for(int i = 0; i < n; ++i) sum += A[i] * B[i];
System.out.print(sum);
}
}
설명
A는 오름차순으로 정렬하고, B는 내림차순으로 정렬하여 인덱스가 같은 수 끼리 곱해서 더한 값을 출력한다.
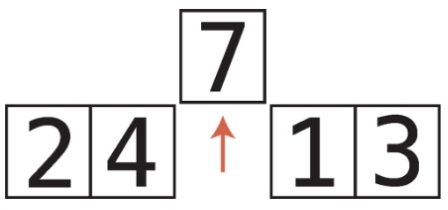
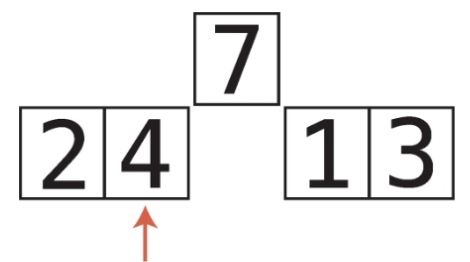
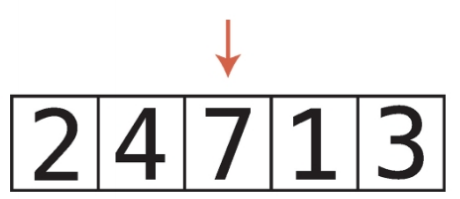
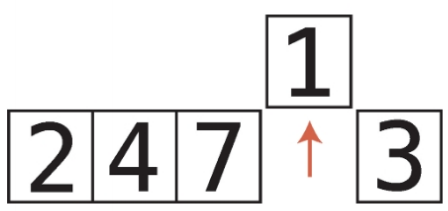
배열의 오름차순과 내림차순 정렬 오름차순 정렬
int A[] = new int[n];
StringTokenizer st = new StringTokenizer(br.readLine());
for(int i = 0; st.hasMoreTokens() == true; ++i) A[i] = Integer.parseInt(st.nextToken());
Arrays.sort(A); // 오름차순 정렬
내림차순 정렬
Integer B[] = new Integer[n]; //Integer로 박싱
StringTokenizer st = new StringTokenizer(br.readLine());
for(int i = 0; st.hasMoreTokens() == true; ++i) B[i] = Integer.parseInt(st.nextToken());
Arrays.sort(B, Collections.reverseOrder()); //내림차순 정렬, 포장 객체만 올 수 있음
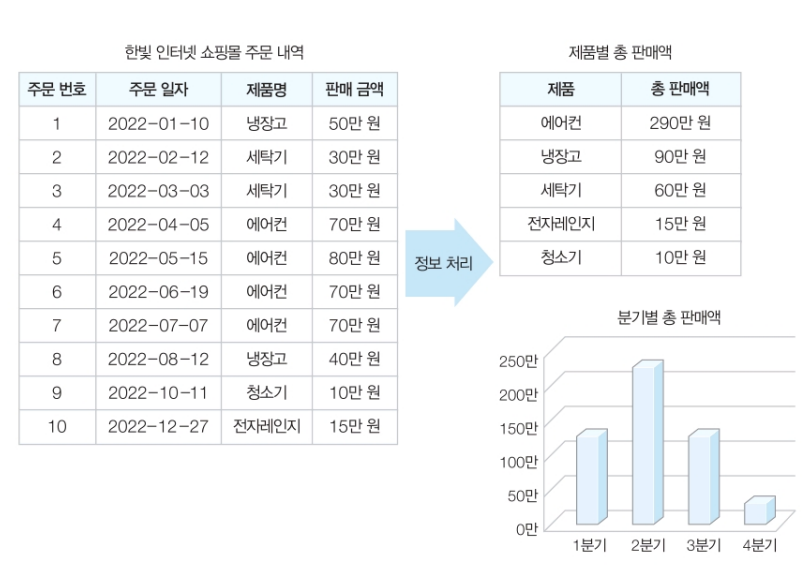
데이터 : 현실 세계에서 단순히 관찰하거나 측정하여 수집한 시실이나 값으로, 자료라고도 한다.
정보 : 데이터를 의사 결정에 유용하게 활용할 수 있도록 처리하여 체계적으로 조직한 결과물이다.
데이터에서 정보를 추출하는 과정 또는 방법을 정보 처리라 한다.
즉, 정보 처리는 데이터를 상황에 맞게 분석하거나 해석하여 데이터 간의 의미 관계를 파악하는 것이다.
현재성과 정확성을 보장하는 가치 있는 정보를 얻으려면 현재 상황을 정확히 관찰하고 측정하여 의미 있는 데이터를 많이 수집해야 한다.
하지만 데이터를 많이 수집하는 데 그쳐서는 안된다.
수집한 데이터를 효율적으로 저장했다가 필요할 때 언제든 사용할 수 있어야 한다.
유용하게 활용할 수 있는 정보를 정확히 추출할 수 있도록 데이터를 대신 관리해주는 역할은 데이터베이스가 담당한다.
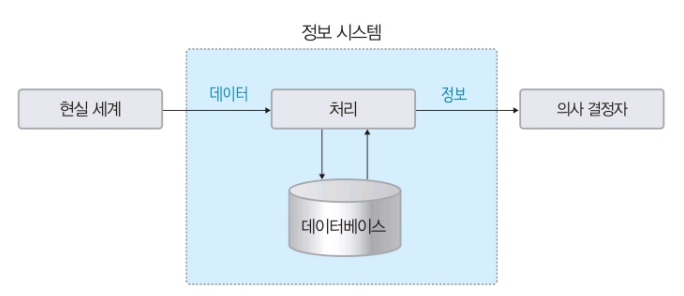
정보 시스템과 데이터 베이스
조직 운영에 필요한 데이터를 수집하여 저장해두었다가 의사 결정이 필요할 때 처리하여 유용한 정보를 만들어주는 수단을 정보 시스템이라 한다.
정보 시스템 안에서 데이터를 저장하고 있다가 필요할 때 제공하는 핵심 역할은 데이터베이스가 담당한다.
복합적이고 광범위한 의사 결정을 위해 사용되는 정보 시스템은 의사 결정 지원 시스템이라 한다.
이외에도 다양한 정보 시스템이 사회 전반에서 활용되고 있다. 그에 따라 정보 시스템의 핵심 요소인 데이터베이스가 매우 중요해졌다.
데이터베이스 흔히 데이터베이스, 데이터베이스 관리 시스템, 데이터베이스 시스템이라는 용어를 구분하지 않고 섞어쓰는데 모두 다른 용어다.
데이터베이스의 정의와 특징
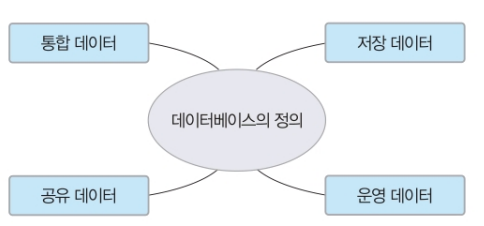
데이터베이스의 정의
일반적으로 데이터베이스는 특정 조직의 여러 사용자가 '공유'하여 사용할 수 있도록 '통합'해서 '저장'한 '운영' 데이터의 집합이라고 정의한다.
공유 데이터 데이터베이스는 특정 조직의 여러 사용자가 함께 사요하고 이용할 수 있어야 하는 공용 데이터다. 그러므로 사용 목적이 다른 사용자들을 두루 고려하여 데이터베이스를 구성해야 한다.
통합 데이터 데이터베이스는 데이터 중복성 즉, 똑같은 데이터가 여러 개 존재하는 것을 허용하지 않는다. 하지만 효율성 때문에 중복을 의도적으로 혀용하는 경우가 있으므로, 통합 데이터는 데이터의 중복을 최소화하고 통제가 가능한 중복만 허용하는 데이터라는 의미로 이해해야 한다.
저장 데이터 데이터베이스의 데이터는 주로 컴퓨터가 처리하므로, 컴퓨터가 접근할 수 있는 매체에 데이터베이스를 저장해야 한다.
운영 데이터 데이터베이스는 조직을 운영하고 조직의 주요 기능을 수행하기 위해 꼭 필요하다. 일시적으로 사용하고 마는 것이 아닌, 지속적으로 유지해야 하는 데이터다.
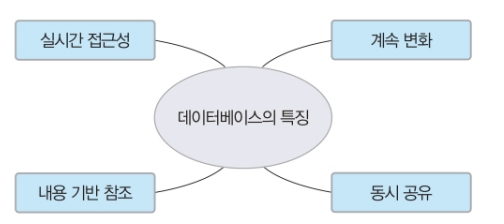
데이터베이스의 특징
실시간 접근성 데이터베이스는 사용자의 데이터 요구에 실시간으로 응답할 수 있어야 한다.
계속 변화 데이터베이스는 현실 세계의 상태를 정확히 반영해야 의미가 있다. 그런데 현실 세계는 끊임없이 변하므로 데이터베이스에 저장된 데이터도 계속 변해야 한다. 즉, 데이터를 계속 삽입, 삭제, 수정하여 현재의 정확한 데이터를 유지해야 한다.
동시 공유 데이터베이스는 여러 사용자가 동시에 이용할 수 있는 동시 공유의 특징을 제공해야 한다. 동시 공유는 여러 사용자가 서로 다른 데이터를 동시에 사용하는 것뿐 아니라, 같은 데이터를 동시에 사용하는 것도 모두 지원한다는 의미다.
내용 기반 참조 데이터베이스는 저장된 주소나 위치가 아닌 데이터의 내용, 즉 값으로 참조할 수 있다. 찾고자 하는 데이터의 내용 조건만 제시하면 조건에 맞는 데이터가 서로 다른 위치에 저장되어 있어도 모두 검색할 수 있다.
데이터 과학 시대의 데이터
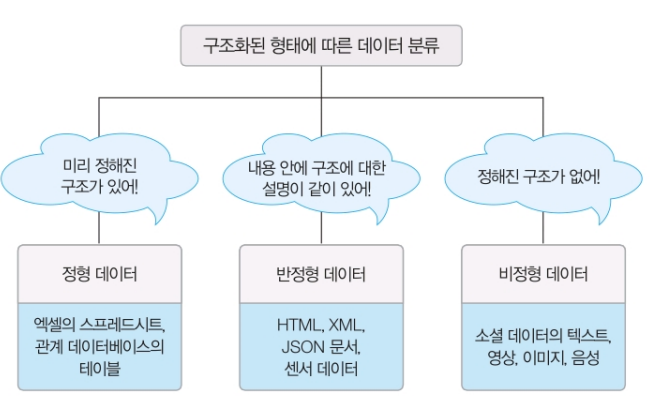
형태에 따른 데이터 분류
데이터는 구조화된 형태에 따라 정형 데이터, 반정형 데이터, 비정형 데이터로 분류할 수 있다.
정형 데이터 정형 데이터는 구조화된 데이터, 즉 미리 정해진 구조에 따라 저장된 데이터다. 표 안에서 행과 열에 의해 지정된 각 칸에 데이터를 저장하는 엑셀의 스프레드시트, 관계 데이터베이스의 테이블이 정형 데이터를 담고 있는 대표적인 예다. 데이터 구조에 대한 설명과 데이터 내용은 별도로 유지된다.
반정형 데이터 반정형 데이터는 구조에 따라 저장된 데이터지만 정형 데이터와 달리 데이터 내용 안에 구조에 대한 설명이 함께 존재한다. 따라서 데이터 내용에 대한 설명, 즉 구조를 파악하는 파싱 과정이 필요하고, 보통 파일 형태로 저장된다.
비정형 데이터 비정형 데이터는 정해진 구조가 없이 저장된 데이터다. 소셜 데이터의 텍스트, 영상, 이미지, 음성, 워드나 PDF 문서와 같은 멀티미디어 데이터가 대표적인 예다.
내용과 함께 설명된 데이터 구조를 스키마라고도 하지만 메타 데이터라고도 한다.
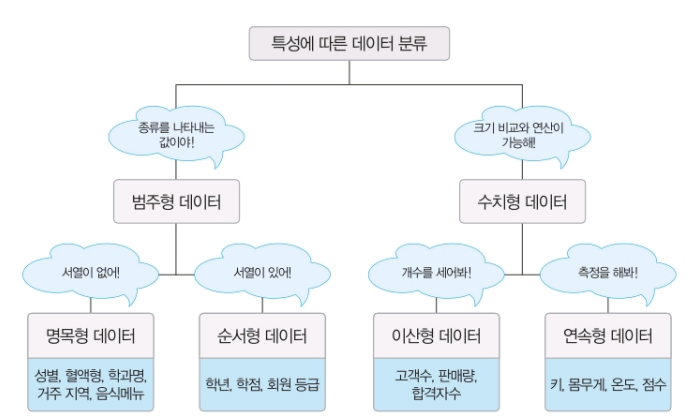
특성에 따른 데이터 분류
일반적으로 데이터를 특성에 따라 범주형 데이터와 수치형 데이터로 분류한다.
이러한 분류는 통계적 관점에서 데이터 특성에 따라 보다 적합한 분석방법을 선택하기 위해 데이터 분석 분야에서 주로 활용한다.
범주형 데이터
범주형 데이터는 명목형 데이터와 순서형 데이터로 나뉜다.
범주형 데이터는 범주로 구분할 수 있는 값, 즉 종류를 나타내는 값을 가진 데이터를 의미한다.
남자와 여자로 구분되는 성별이나 1학년 2학년 등으로 구분되는 학년이 범주형 데이터에 해당한다.
명목형 데이터 남자와 여자로 구분되는 성별이나, 혈액형 등 순서, 즉 서열이 없는 값을 가지는 데이터를 의미한다.
순서형 데이터 순서, 즉 서열이 있는 값을 가지는 데이터로 1학년 2학년 등으로 구분되는 학년이나 학점, 회원 등급 등이 순서형 데이터에 속한다.
범주형 데이터는 대부분 문자 타입의 값으로, 양적 측면에서 크기 비교와 산술적인 연산이 가능하지 않기 때문에 질적 데이터라고도 한다.
수치형 데이터
수치형 데이터는 이산형 데이터와 연속형 데이터로 나뉜다.
수치형 데이터는 양적 측면에서 크기 비교와 산술적인 연산이 가능한 숫자 값을 가진 데이터를 의미한다. 그래서 양적 데이터라고도 한다.
키, 몸무게, 고객수, 판매량 등이 수치형 데이터에 해당한다.
이산형 데이터 개수를 셀 수있는 고객 수, 판매량, 합격자 수와 같이 이어지지 않고 띄엄띄엄 단절된 숫자 값을 가지는 데이터를 의미 보통 소수점이 없는 정수 타입의 값으로 표현된다.
연속형 데이터 측정을 통해 얻어지는 키, 몸무게, 온도, 점수와 같이 연속적으로 이어진 숫자 값을 가지는 데이터를 의미 모통 소수점이 있는 실수 타입의 값으로 표현된다.
정성적 데이터와 정량적 데이터 데이터 유형을 정성적 데이터와 정량적 데이터로 분류하기도 한다. 좁은 의미로는 범주형 데이터를 정성적 데이터로, 수치형 데이터를 정량적 데이터로 볼 수 있다. 넓은 의미로 제품이나 서비스에 대한 후기와 같이 사람의 주관적인 생각과 평가를 기술한 비정형 데이터를 정성적 데이터로, 객관적인 측정을 통해 수치나 도형, 기호 등으로 표현한 정형 데이터를 정량적 데이터로 정의하기도 한다. 정량적 데이터에 비해 정성적 데이터가 저장 및 처리 측면에서 더 큰 비용이 드는 경우가 많다.
이 글은 누구나 자료 구조와 알고리즘(저자 : 제이 웬그로우)의 내용을 개인적으로 정리하는 글임을 알립니다.
패스트푸드점에서 손님이 음식을 주문하는 프로그램을 작성 중이고, 음식마다 각각 가격이 있는 메뉴를 구현하고 있다고 상상해 보자.
메뉴 배열 안에 메뉴의 이름과 가격을 포함하는 배열이 또 있다고 가정하면, 메뉴 배열안에 있는 하위 배열을 찾는데 O(N)의 단계가 걸린다.
정렬된 배열이라면 이진탐색을 통해O(logN)이 걸린다.
하지만 해시 테이블을 사용하면 데이터를 O(1)만에 룩업할 수 있다.
해시 테이블
해시 테이블은 다양한 프로그래밍 언어에서 서로 다른 이름으로 불린다.
해시, 맵, 해시맵, 딕셔너리, 연관 배열 등의 이름을 갖는다.
대부분의 프로그래밍 언어는 해시 테이블(hash table)이라는 자료구조를 포함하며, 해시 테이블에는 빠른 읽기라는 놀랍고 엄청난 능력이 있다.
해시 테이블은 쌍으로 이뤄진 값들의 리스트다.
첫 번째 항목을 키라 부르고, 두 번째 항목을 값이라 부른다.
french fries가 키이고, 0.75가 값이다.
이렇게 해시 테이블로 구성되어 있다면 프랜치프라이가 가격이 얼마인지 딱 한 단계만에 알 수 있다.
해시 테이블의 값 룩업은 딱 한 단계만 걸리므로 평균적으로 효율성이 O(1)이다.
해시 함수로 해싱
비밀 코드를 만들고 해독한다고 가정해보자.
예를 들어 아래처럼 단순하게 글자와 숫자를 짝지을 수 있다.
위 코드에 따르면, ACE는 135로, CAB는 312로, DAB는 412로, BAD는 214로 변환된다.
문자를 가져와 숫자로 변환하는 과정을 해싱(hasing)이라 부른다.
글자를 특정 숫자로 변환하는데 사용한 코드를 해시 함수(hash function)라 부른다.
이 밖에도 해시 함수는 많다. 또 다른 해시 함수 예제는 각 문자에 해당하는 숫자를 가져와 모든 수를 합쳐 반환하는 것이다.
이렇게 하면 BAD는 아래와 같은 두 단계의 과정을 거쳐 숫자 7이 된다.
먼저 BAD를 214로 변환한다.
각 숫자를 가져와 합한다.
2 + 1 + 4 = 7
또 다른 해시 함수 예제는 문자에서 해당하는 모든 수를 곱해서 반환하는 것이다.
BAD를 214로 변환한다.
각 숫자를 가져와 곱한다.
2 x 1 x 4 = 8
실제 쓰이는 해시 함수는 이보다 더 복잡하지만 이러한 "곱셈" 해시 함수를 사용하면 예제가 명확하고 간단해진다.
해시 함수가 유효하려면 딱 한 가지 기준을 충족해야 한다.
해시 함수는 동일한 문자열을 해시 함수에 적용할 때마다 항상 동일한 숫자로 변환해야 한다.
주어진 문자에 대해 반환하는 결과가 일관되지 않으면 그 해시함수는 유효하지 않다.
따라서 난수나 현재 시간을 계산에 넣어 사용하는 해시 함수는 유효하지 않다.
하지만 곱셈 해시 함수를 쓰면 BAD는 항상 8로 변환된다.
B는 항상 2고, A는 항상 1이고, D는 항상 4이기 때문이다.
따라서 2 x 1 x 4는 항상 8이다.
곱셈 해시 함수를 쓰면 DAB역시 BAD처럼 8로 변환된다는 것에 유의한다. 이로 인해 실제로 문제가 발생한다.
유의어 사전 만들기
사용자가 당신이 만든 사전에서 단어를 룩업하면 구식 유의어 사전 앱처럼 가능한 유의어를 모두 반환하는 대신 유의어를 딱 하나만 반환한다.
모든 단어에는 각각 연관된 동의어가 있으므로 동의어는 해시 테이블의 좋은 사용 사례다.
다음과 같이 해시테이블로 유의어 사전을 표현한다고 하자.
배열과 유사하게 해시 테이블은 내부적으로 데이터를 한 줄로 이뤄진 셀 묶음에 저장한다.
각 셀마다 주소가 있다.
예를 들면 아래와 같다.
곱셈 해시 함수로는 인덱스 0에 아무 값도 저장되지 않으므로 인덱스 0은 제외
첫 번째 항목을 해시 테이블에 추가하자
컴퓨터는 해시 테이블을 만들기 위해 키에 해시 함수를 적용한다.
BAD = 2 x 1 x 4 = 8
키("bad")는 8로 해싱되므로 컴퓨터는 값("evil")을 아래와 같이 셀 8에 넣는다.
다시 한번 컴퓨터는 키를 해싱한다.
CAB = 3 x 1 x 2 = 6
결괏값이 6이므로 컴퓨터는 값("taxi")를 셀 6에 저장한다.
ACE = 1 x 3 x 5 = 15
ACE는 15로 해싱되고 "star"는 셀 15로 들어간다.
해시 테이블 룩업
해시 테이블에서 항목을 룩업할 때는 키를 사용해 연관된 값을 찾는다.
키 bad의 값을 룩업하고 싶다고 하자.
bad의 값을 찾기 위해 컴퓨터는 간단히 두 단계를 실행한다.
컴퓨터는 룩업하고 있는 키를 해싱한다. BAD = 2 x 1 x 4 = 8
결과가 8이므로 셀 8을 찾아가서 저장된 값을 반환한다. 즉, evil을 반환한다.
해시 테이블에서 각 값의 위치는 키로 결정된다.
즉, 키 자체를 해싱해 키와 연관된 값이 놓여야 하는 인덱스를 계산한다.
키가 값의 위치를 결정하므로 이 원리를 사용하면 룩업이 아주 쉬워진다.
어떤 키가 있고 그 키의 값을 찾고 싶으면 키 자체로 값을 어디서 찾을 수 있는지 알 수 있다.
이제 왜 해시 테이블의 값 룩업이 전형적으로 O(1)인지 명확해졌다.
단방향 룩업
키를 사용해 값을 찾을 때만 O(1) 룩업이 가능하다.
거꾸로 값을 이용해 연관된 키를 찾을 때는 해시 테이블의 빠른 룩업 기능을 활용할 수 없다.
이는 키가 값의 위치를 결정한다는 해시 테이블의 대전제 때문이다.
하지만 이 전제는 한 방향으로만, 다시 말해 키를 사용해 값을 찾는 식으로만 동작한다.
세부적으로는 언어에 따라 다르지만 어떤 언어는 값 바로 옆에 키를 저장한다.
이렇게 저장하면 다음 절에서 다룰 충돌에서 매우 유용하다.
또한 각 키는 해시 테이블에 딱 하나 존재할 수 있으나 값은 여러 인스턴스가 존재할 수 있다.
처음에 살펴봤던 메뉴 예제를 떠올리면 같은 햄버거를 두 번 나열할 수 없다.
하지만 값은 여러 인스턴스가 존재할 수 있다.
즉 다른 햄버거라도 가격은 같을 수 있다.
대부분의 언어는 이미 존재하는 키에 키/값 쌍을 저장하려 하면 키는 그대로 두고 기존 값만 덮어쓴다.
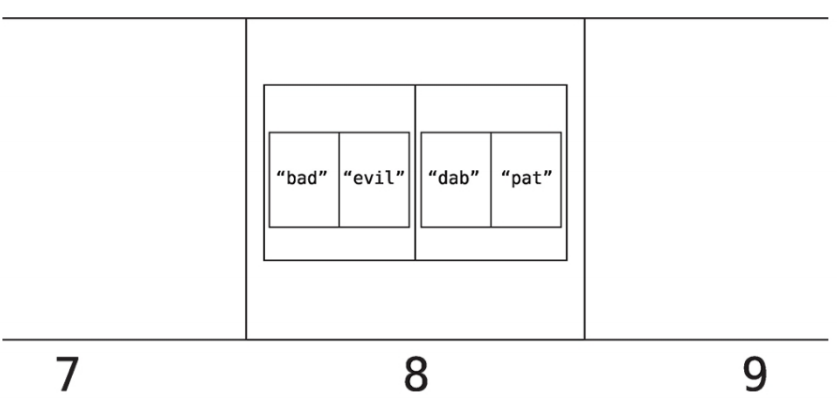
충돌 해결
해시 테이블은 좋은 자료구조이지만 문제도 있다.
유의어 사전 예제를 살펴보자.
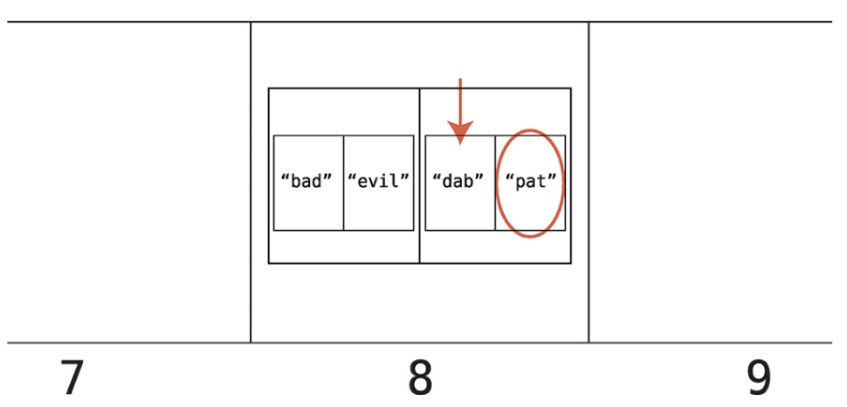
아래와 같은 항목을 예제의 유의어 사전에 추가하면 아래와 같은 일이 벌어진다.
DAB = 4 x 1 x 2 = 8
pat을 해시 테이블의 셀 8에 추가하려 한다.
셀 8에는 이미 값이 존재한다.
이미 채워진 셀에 데이터를 추가하는 것을 충돌이라 부른다.
다행히 이 문제를 해결하는 방법들이 있다.
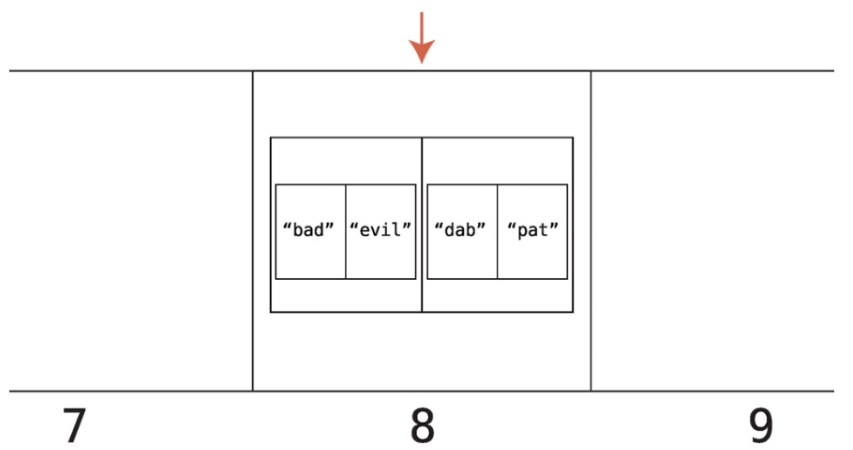
충돌을 해결하는 고전적인 방법하나가 분리 연결법이다.
충돌이 발생했을 때 셀에 하나의 값을 넣는 대신 배열로의 참조를 넣는 방법이다.
이렇게 되어 있던 배열을 아래와 같이 바꾼다.
이렇게 바꿨을 때 해시 테이블 룩업은 thesaurus["dab"]을 룩업할 때 컴퓨터는 아래와 같은 단계를 거친다.
DAB = 4 x 1 x 2 = 8
셀 8을 룩업 한다. 컴퓨터는 셀 8이 하나의 값이 아닌 배열들의 배열을 포함하고 있음을 알게 된다.
각 하위 배열의 인덱스를 찾아보며 룩업하고 있는 단어인 dab을 찾을 때까지 배열을 차례대로 검색한다. 일치하는 하위 배열의 인덱스 1에 있는 값을 반환한다.
컴퓨터가 확인 중인 셀이 배열을 참조할 경우 다수의 값이 들어 있는 배열을 선형 검색해야 하므로 검색 단계가 더 걸린다.
만약 모든 데이터가 해시 테이블의 한 셀에 들어가게 된다면 해시 테이블은 배열보다 나을게 없다.
따라서 최악의 경우 해시 테이블 룩업 성능은 사실상 O(N)이다.
이렇기 때문에 해시 테이블에 충돌이 거의 없도록 O(N) 시간이 아닌 O(1) 시간 내에 일반적으로 룩업을 수행하도록 디자인해야 한다.
효율적인 해시 테이블 만들기
궁극적으로 해시 테이블은 아래 세 요인에 따라 효율성이 정해진다.
해시 테이블에 얼마나 많은 데이터를 저장하는가
해시 테이블에서 얼마나 많은 셀을 쓸 수 있는가
어떤 해시 함수를 사용하는가
처음 두 요인이 중요한 이유는 적은 셀에 많은 데이터를 저장하면 충돌이 많을 테고 해시 테이블의 효율성은 떨어진다.
세 번째 요인이 중요한 이유는
이러한 셀이 있다고 가정하면, 어떤 해시 함수를 사용하면 10에서 16 사이의 셀은 이용할 수 없다고 하면 셀의 낭비가 되고 낭비되는 만큼 효율이 저하된다.
따라서 좋은 해시 함수란 사용 가능한 모든 셀에 데이터를 분산시키는 함수이다.
데이터를 넓게 퍼뜨릴수록 충돌이 적다.
충돌 조정을 위해 컴퓨터 과학자는 해시테이블에 저장된 데이터가 7개면 셀은 10개여야 한다고 말한다. 데이터와 셀 간 이러한 비율을 부하율이라 부른다. 데이터를 더 추가하기 시작하면 새 데이터가 새로운 셀들에 균등하게 분산되도록 컴퓨터는 셀을 더 추가하고 해시 함수를 바꿔서 해시 테이블을 확장한다.
이 글은 누구나 자료 구조와 알고리즘(저자 : 제이 웬그로우)의 내용을 개인적으로 정리하는 글임을 알립니다.
다양한 빅오 카테고리
단어 생성기
이 예제는 문자 배열로부터 두 글자짜리 모든 문자열 조합을 모으는 알고리즘이다.
예를 들어, [a,b,c,d]라는 배열이 주어지면 다음과 같은 문자열 조합을 포함하는 새 배열을 리턴한다.
아래는 이 알고리즘을 자바스크립트로 구현한 코드이다.
이 알고리즘의 효율성은 바깥 루프는 N개 원소를 모두 순회하고 각 원소마다 안쪽 루프는 다시 N개 원소를 모두 순회하니 O(N²)이다.
세 글자짜리 모든 문자열 조합을 계산하도록 알고리즘을 수정하면 함수는 아래와 같은 배열을 반환할 것이다.
function wordBuilder(array) {
let collection = [];
for(let i = 0; i < array.length; i++) {
for(let j = 0; j < array.length; j++) {
for(let k = 0; k < array.length; k++) {
if (i !== j && j !== k && i !== k) {
collection.push(array[i] + array[j] + array[k]);
}
}
}
}
return collection;
}
이 알고리즘은 중첩 루프가 총 3개 있으며, 3개 모두 N개의 원소를 순회하니 총 단계는 N x N x N = N³단계가 걸린다.
따라서 이를 빅 오 표기법으로 나타내면 O(N³)이다.
샘플 채취
배열에서 소규모 샘플을 취하는 함수를 생성한다.
아주 큰 배열이라 생각하고 맨 앞과 가운데, 맨 뒤 값을 샘플링한다.
def sample(array):
first = array[0]
middle = array[int(len(array) / 2)]
last = array[-1]
return [first, middle, last]
데이터의 개수는 배열의 원소 수이다.
하지만 이 함수는 배열의 원소 수(N)와 상관없이 단계 수가 동일하다.
시작과 중간, 마지막 인덱스읽기는 배열의 크기와 상관 없이 모두 딱 한 단계면 충분하다.
배열의 길이를 찾고 그 길이를 2로 나누는 것 역시 한 단계다.
단계 수가 상수이므로, 즉 N에 관계 없이 일정하므로 이 알고리즘은 O(1)이다.
의류 상표
의류 업체가 쓸 소프트웨어를 작성 중이라고 가정하자.
새로 생산한 의류 품목과 각 사이즈(1~5)가 들어가야 한다.
예를 들어, ["Purple Shirt", "Green Shirt"]라는 배열을 받았다면 이 셔츠에 들어갈 상표 텍스트는 아래와 같다.
def mark_inventory(clothing_items):
clothing_options = []
for item in clothing_items:
for size in range(1, 6):
clothing_options.append(item + " Size: " + str(size))
return clothing_options
이 알고리즘에 중첩 루프가 들어갔다고 해서 O(N²)라고 판단하면 안된다.
바깥 루프가 N번 실행되는 동안 안쪽 루프가 5번 실행된다.
따라서 단계수는 5N이다.
빅 오 표기법은 상수를 무시하니 O(N)이다.
1 세기
이 예제는 배열들의 배열을 받는다. 이때 안쪽 배열들은 다수의 1과 0으로 이뤄진다.
함수는 배열들에 들어 있는 1의 개수를 반환한다.
예를 들어, 입력이 아래와 같을 때
1이 7개이니 함수는 7을 리턴한다.
def count_ones(outer_array):
count = 0
for inner_array in outer_array:
for number in inner_array:
if number == 1:
count += 1
return count
이 함수 또한 중첩루프가 있다고 해서 섣불리 O(N²)로 판단하면 안된다.
루프 두 개가 완전히 다른 배열을 순회하기 때문이다.
바깥 루프는 안쪽 배열을 순회하고 안쪽 배열은 실제 수를 순회한다.
결국에는 안쪽 루프가 총 수 개수 만큼만 실행된다.
따라서 N은 수의 개수다.
따라서 이 함수의 시간복잡도는 O(N)이다.
팰린드롬 검사기
팰린드롬은 앞으로 읽으나 뒤로 읽으나 똑같은 단어 혹은 구절이다.
"racecar", "kayak", "deified" 등이 팰린드롬이다.
다음은 어떤 문자열이 팰린드롬인지 판단하는 자바스크립트 함수이다.
function isPalindrome(string) {
let leftIndex = 0;
let rightIndex = string.length - 1;
while (leftIndex < string.length / 2) {
if (string[leftIndex] !== string[rightIndex]) {
return false;
}
leftIndex++;
rightIndex--;
}
return true;
}
N은 함수에 전달된 문자열의 크기다.
while루프는 문자열의 반만 순회한다.
즉, 루프가 N / 2 단계를 실행한다는 뜻이다.
빅 오는 상수를 무시하기 때문에 O(N)이다.
모든 곱 구하기
예제1
이 예제는 수 배열을 받아 모든 두 숫자 조합의 곱을 리턴하는 알고리즘이다.
예를 들어 [1, 2, 3, 4, 5]라는 배열을 전달하면 함수는 아래처럼 반환한다.
[2, 3, 4, 5, 6 ,8 ,10, 12, 15, 20]
1 x (2, 3, 4, 5) = 2, 3, 4, 5
2 x (3, 4, 5) = 6, 8, 10
3 x (4, 5) = ,12, 15
4 x 5 = 20
위 알고리즘을 자바스크립트로 구현하면 아래와 같다.
function twoNumberProducts(array) {
let products = [];
for(let i = 0; i < array.length - 1; i++) {
for(let j = i + 1; j < array.length; j++) {
products.push(array[i] * array[j]);
}
}
return products;
}
함수에 원소 수가 N개인 배열이 들어온다면
바깥 루프는 약 N번 순회한다.(실제로는 N-1)
안쪽 루프는 바깥 루프를 한 번씩 돌 때마다 단계 수는 1씩 감소한다.
원소가 5개인 배열에서 안쪽 루프는
4 + 3 + 2 + 1 번 실행된다.
이러한 바깥 루프와 안쪽 루프의 관계의 패턴은 N² / 2 단계로 계산된다.
예를 들어 N이 8이라고 가정하면
맨 윗줄은 N칸 모두 회색으로 칠해져 있다. 다음 줄은 N-1개가 회색이고, 그 다음 줄은 N-2가 회색 칸이다. 한 칸만 회색인 마지막 줄까지 이 패턴이 이어진다. 이는 N + (N - 1) + (N - 2) + (N - 3) + ... + 1 이고 이 패턴은 약 N² / 2와 비슷하다
따라서 O(N²)이다.
예제2
배열 한 개의 모든 두 수의 곱을 계산하는 대신, 한 배열의 모든 수와 다른 한 배열의 모든 수의 곱을 계산하면,
예를 들어 배열 [1, 2, 3]과 배열 [10, 100, 1000]이 있으면 곱은 아래처럼 계산된다.
[10, 100, 1000, 20, 200, 2000, 30, 300, 3000]
function twoNumberProducts(array1, array2) {
let products = [];
for(let i = 0; i < array1.length; i++) {
for(let j = 0; j < array2.length; j++) {
products.push(array1[i] * array2[j]);
}
}
return products;
}
첫 번째 배열의 원소 수가 N이고, 두 번째 배열의 원소 수가 M이면
이 때 두 가지 시나리오를 세울 수 있다.
N = M
N != M
예를 들어 첫 번째 시나리오대로 N=M이어서 두 배열 5의 크기를 가지는 배열이라고 가정하면
5 x 5 = 25 즉, O(N²)이다.
두 번째 시나리오대로 N != M이면, N=9, M= 1이면
9 x 1 = 9 즉,대략 N단계이므로 O(N)이다.
이렇게 N과 M의 크기에 따라 달라지는 관계에선 O(NxM)으로 표기한다.
O(NxM)은 O(N)과 O(N²)의 사이 정도로 이해할 수 있다.
암호 크래커
소문자 a~z까지의 알파벳으로 이루어진 n자리 암호문을 브루트 포스 알고리즘으로 푼다면 아래와 같다.
위 함수는 n이 3이라면 aaa와 zzz범위 내 가능한 모든 문자열을 순회한다.
n이 4라면 아래와 같이 순회를 한다.
이는 n=1이면 26번 루프를 돌고, n=2면 26²번 루프를 돈다.
즉, 26ⁿ번 루프를 돈다.
따라서 빅 오 표기법으로는 O(26ⁿ)로 표기한다.
O(2ⁿ)는 O(N³)보다 어느 시점부턴 훨씬 느리다.
O(26ⁿ)은 O(2ⁿ)보다 훨씬 느리다.
O(2ⁿ)은 O(log N)의 반대이다. O(log N)는 데이터가 두 배 늘어날 때 단계수가 1늘어난다. O(2ⁿ)는 데이터가 1늘어날 때 단계수가 두 배 늘어난다.
이 글은 누구나 자료 구조와 알고리즘(저자 : 제이 웬그로우)의 내용을 개인적으로 정리하는 글임을 알립니다.
선택 정렬
선택 정렬은 아래와 같은 단계를 따른다.
1. 배열의 각 셀을 왼쪽부터 오른쪽 방향으로 확인하면서 어떤 값이 최솟값인지 결정한다. 한 셀씩 이동하면서 현재까지 가장 작은 값을 기록한다.(실제로는 그 인덱스를 변수에 저장) 변수에 들어 있는 값보다 작은 값이 들어 있는 셀을 만나면 변수가 새 인덱스를 가리키도록 값을 대체한다.
2. 최솟값이 어느 인덱스에 있는지 알았으므로 그 인덱스의 값과 패스스루를 처음 시작했을 때의 값을 교환한다. 패스스루를 시작했을 때 인덱스는 첫 패스스루에서는 인덱스 0일 것이고, 두 번째 패스스루에서는 인덱스 1일 것이다.
3. 매 패스스루는 1, 2 단계로 이뤄진다. 배열 끝에서 시작하는 패스스루에 도달할 때까지 패스스루를 반복한다. 마지막 패스스루에서는 배열이 완벽히 정렬되어 있을 것이다.
더 자세히 선택 정렬 살펴보기
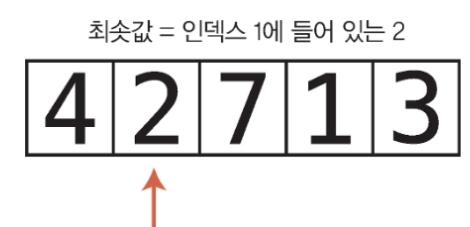
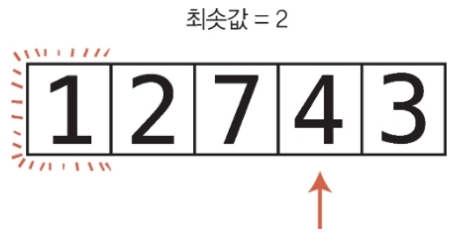
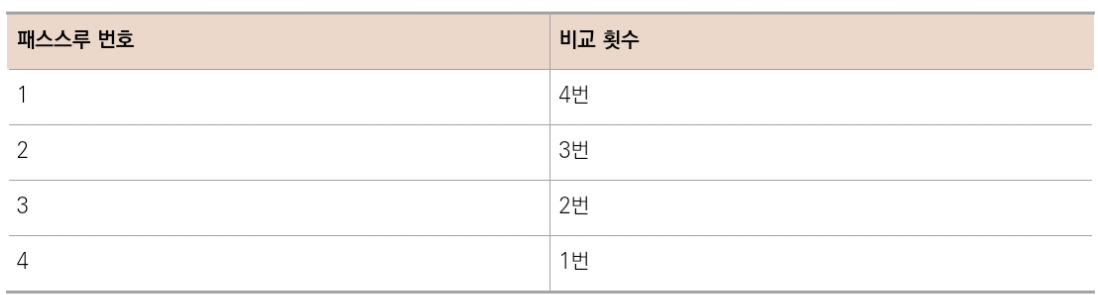
배열 [4, 2, 7, 1, 3]을 선택 정렬로 정렬해보자.
첫 번째 패스스루 시작
인덱스 0에 들어 있는 값을 확인하며 시작한다.
이 값이 지금까지 본 유일한 값이므로 이 인덱스를 변수에 저장한다.
1단계 : 현재 최솟값과 2를 비교한다.
2는 4보다 작으므로 2가 현재까지의 최솟값이 된다.
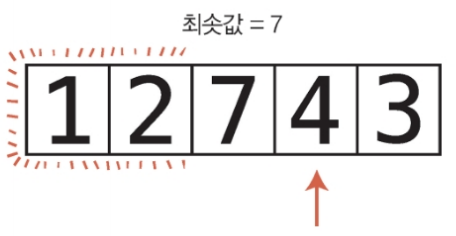
2단계 : 현재 최솟값과 다음 값인 7을 비교한다. 7은 2보다 크므로 2가 여전히 최솟값이다.
3단계 : 현재 최솟값과 1을 비교한다.
1은 2보다 작으므로 1이 새로운 최솟값이 된다.
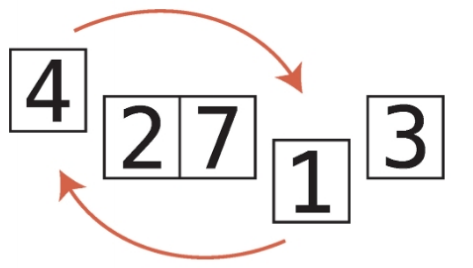
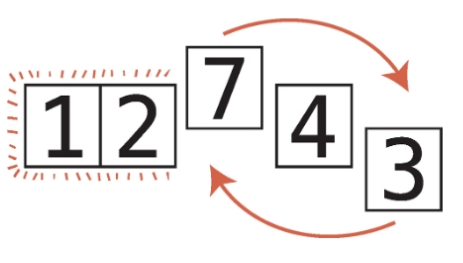
4단계 : 현재 최솟값인 1과 3을 비교한다. 배열의 끝에 도달했으므로 전체 배열의 최솟값이 1로 결정되었다.
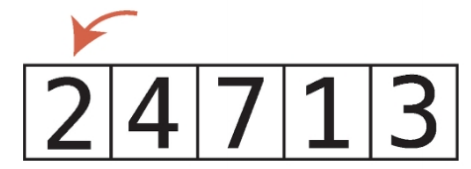
5단계 : 1이 최솟값이므로 1과 인덱스 0(패스스루를 시작했던 인덱스)의 값을 교환한다.
최솟값을 배열 맨 앞으로 옮겼으니 이제 최솟값이 배열 내에 올바른 위치에 있게 되었다.
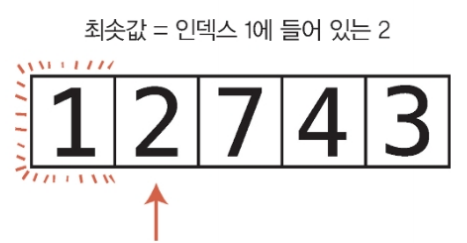
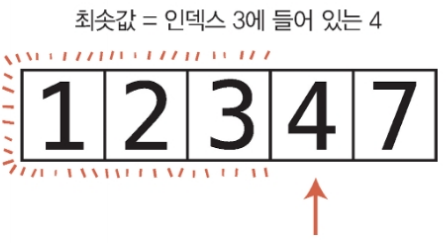
두 번째 패스스루 시작
첫 번째 셀, 즉 인덱스 0은 이미 정렬됐으므로 두 번째 패스스루는 다음 셀인 인덱스 1부터 시작한다.
인덱스 1의 값은 2이며, 이 값이 두 번째 패스수루의 현재 최솟값이다.
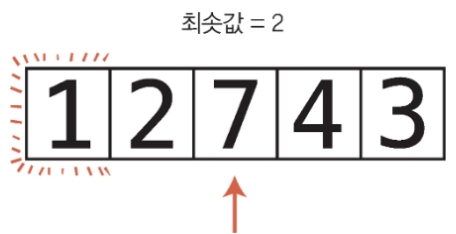
6단계 : 현재 최솟값과 7을 비교한다. 2는 7보다 작으므로 2는 여전히 최솟값이다.
7단계 : 현재 최솟값과 4를 비교한다. 2는 4보다 작으므로 2는 여전히 최솟값이다.
8단계 : 현재 최솟값과 4를 비교한다. 2는 4보다 작으므로 2는 여전히 최솟값이다.
배열의 끝에 도달했다.
이 패스스루의 최솟값이 이미 올바른 위치에 있으니 교환하지 않아도 된다.
이로써 아래와 같은 생태로 두 번째 패스스루가 끝났다.
세 번째 패스스루 시작
7이 들어 있는 인덱스 2에서 시작한다.
7은 세 번째 패스스루에서 현재까지의 최솟값이다.
9단계 : 4와 7을 비교한다.
4가 새로운 최솟값이다.
10단계 : 4보다 작은 3이 나타났다.
이제 3이 새로운 최솟값이다.
11단계 : 배열의 끝에 도달했으므로 3과 패스스루를 시작했던 값, 즉 7을 교환한다.
이제 3이 배열 내에 올바른 위치에 있게 되었다.
이 시점에서는 우리는 정렬이 모두 되었음을 알지만, 컴퓨터는 아직 모르므로 네 번째 패스스루를 시작해야 한다.
네 번째 패스스루 시작
인덱스 3에서 패스스루를 시작한다.
4가 현재까지의 최솟값이다.
12단계 : 4와 7을 비교한다.
4가 여전히 이 패스스루의 최솟값이고 올바른 위치에 있으니 교환하지 않아도 된다.
마지막 셀을 제외한 모든 셀이 올바르게 정렬 됐고, 마지막 셀 역시 당연히 올바른 순서이므로 이제 전체 배열이 올바르게 정렬됐다.
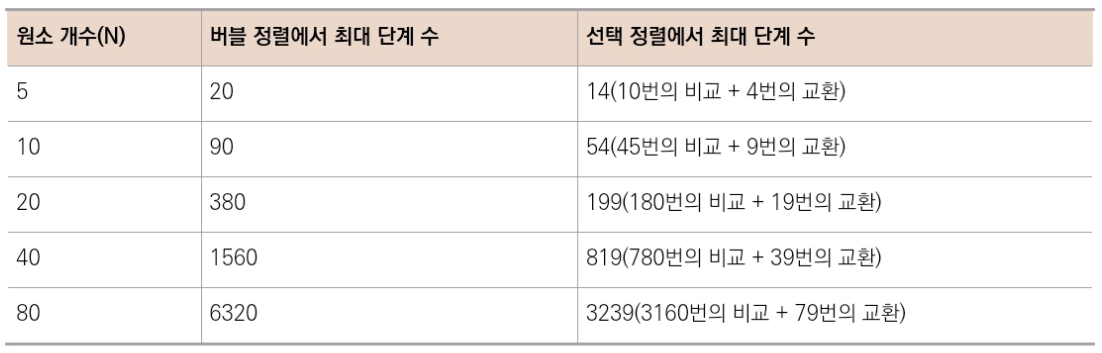
선택 정렬의 효율성
선택 정렬은 비교와 교환, 두 종료의 단계를 포함한다.
5개의 원소를 포함하는 배열 예제로 돌아가면, 총 10번의 비교를 해야 했다.
총 4 + 3 + 2 + 1 = 10번의 비교다.
즉, 원소 N개가 있을 때 (N - 1) + (N - 2)+ (N - 3) + ... + 1번의 비교다.
교환은 한 패스스루 당 최대 한 번이 일어난다.
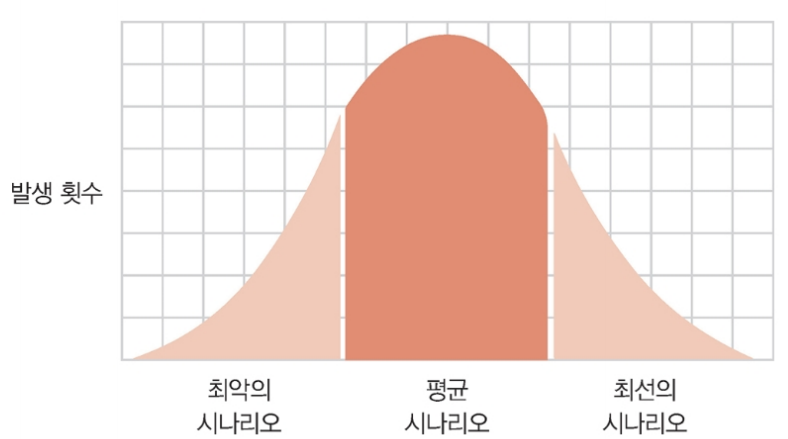
배열이 역순으로 정렬된 최악의 시나리오에서는 버블 정렬과 달리 비교할 때마다 빠짐없이 교환을 한 번 해야 한다.
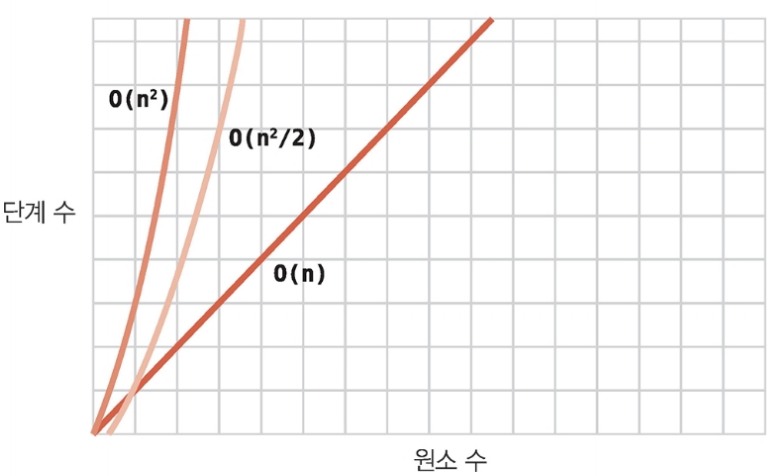
표로 보는 것과 같이 선택 정렬은 버블 정렬 보다 대략 절반 정도의 단계 수를 가지고 있다.
즉, 선택 정렬이 두 배 정도 더 빠르다.
선택 정렬과 빅 오
선택 정렬은 약 절반정도 버블 정렬보다 적은 단계수를 가지고 있지만 둘 다 모두 O(N²)로 빅 오를 표현 한다.
선택 정렬이 버블 정렬 보다 절반정도 단계수가 적으니, O(N² / 2)로 표현하는 게 올바르게 표현한 것이라고 생각할지 모르지만, 빅 오 표기법은 상수를 무시한다.
즉, 빅 오 표기법은 지수가 아닌 수는 포함하지 않는다.
N / 2단계가 필요한 알고리즘은 O(N)으로 표현
N² + 10단계가 필요한 알고리즘은 O(N²)으로 표현
2N 단계가 필요한 알고리즘은 O(N)으로 표현
O(N)보다 100배 느린 O(100N)이라 해도 마찬가지로 O(N)
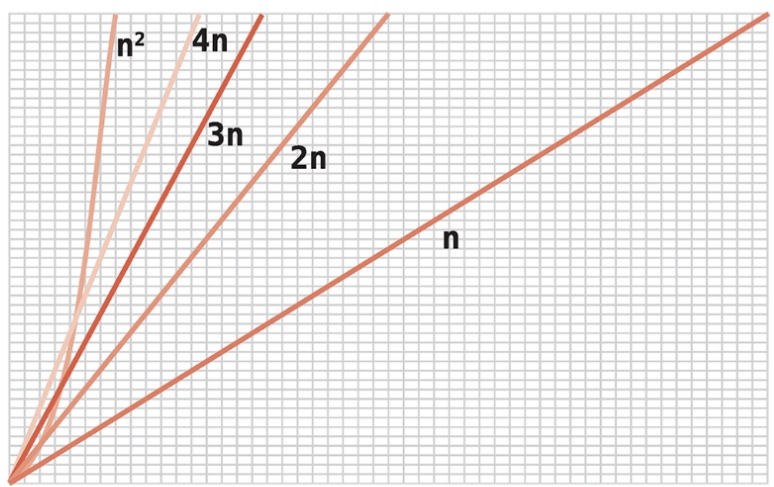
빅 오 카테고리 빅 오 표기법은 일반적인 카테고리의 알고리즘 속도만 고려한다. 왜냐하면 일반적인 카테고리로만 분류해도 현저한 차이를 나타내기 충분하기 때문이다.
예를 들어, O(N) 알고리즘과 O(N²) 알고리즘을 비교할 때 두 효율성간 차이가 너무 커서 O(N)이 실제로 O(N / 2)든 O(100N)이든 별로 중요하지 않다.
빅 오 표기법은 데이터가 늘어날 때 알고리즘 단계 수가 장기적으로 어떤 궤적을 그리는지가 중요하다. O(N)에 어떤 수를 곱하든 데이터가 커지다 보면 언젠가 결국 O(N²)이 더 느려진다는 사실을 깨달으면 완전히 이해가 간다.
선택 정렬과 버블 정렬은 어쨌든 같은 카테고리에 속하더라도 서로 처리 속도가 다르다.
따라서 빅 오에서 다른 카테고리에 속하는 알고리즘을 대조할 때는 빅 오가 완벽한 도구지만 같은 카테고리에 속하는 두 알고리즘이라면 어떤 알고리즘이 더 빠를지 알기 위해 더 분석해야 한다.