Docker Compose 로 여러개의 도커 컨테이너가 묶여있고, EC2 인스턴스로 배포된 상황에서 여러가지 이슈들로 인스턴스가 재부팅 되거나 애플리케이션이 종료될 수 있다.
이때 재부팅되거나 배포한 애플리케이션이 종료되었을 때 자동으로 애플리케이션이 시작되게끔 할 수 있다.
먼저 Docker Compose 애플리케이션 서비스 파일을 생성해야 한다.
sudo vi /etc/systemd/system/docker-compose-app.service
이후 아래의 서비스 파일을 입력한다.
[Unit]
Description=Docker Compose Application Service
After=docker.service
Requires=docker.service
[Service]
Restart=always
RestartSec=10s # 재시작 간격 설정
WorkingDirectory=<compose.yml이 있는 폴더 경로>
ExecStart=/usr/bin/docker compose up -d
#ExecStop=/usr/bin/docker compose down 필요시 주석 해제
[Install]
WantedBy=multi-user.target
RestartSec=10s 옵션을 추가하면, 서비스가 실패한 후 재시작하기 전까지 기다리는 시간을 10초로 설정하게 된다. 즉, 서비스가 비정상적으로 종료되었을 때, systemd는 10초 후에 다시 서비스를 재시작한다는 의미이다.
ExecStop=/usr/bin/docker compose down은 systemd 서비스가 종료될 때 실행할 명령어를 정의하는 옵션이다. 이 설정은 시스템이 docker-compose-app.service를 중지하거나, 재시작할 때 기존에 실행 중인 Docker Compose 애플리케이션을 깨끗하게 종료시키는 역할을 한다. 나는 이 설정으로 애플리케이션이 시작과 종료가 계속 반복되어 주석처리하였다.
WorkingDirectory=<compose.yml이 있는 폴더 경로> 는 말그대로 compose.yml이 있는 폴더 경로를 설정한다. 예를들어, /home/ubuntu/server/compose.yml이 있는경우 WorkingDirectory=/home/ubuntu/server 이렇게 지정하면 된다.
이렇게 설정하면 local 환경에서는 콘솔로 로그를 확인할 수 있고, prod 환경에서는 ./log 폴더에 날짜별로 info와 error 로그 내용을 저장할 수 있다.
날짜 뒤에 숫자는 같은 날짜의 로그파일을 구분하는 숫자이고, 로그 파일이 50MB를 넘었을 때 새로운 파일에 로그를 저장하고 숫자가 1 증가하여 저장된다.
예를들어 error-2024-10-11.0.log의 파일 용량이 50mb가 넘었을 시에 error-2024-10-11.1.log이 생성되고 여기에 로그를 마저 저장하는 것이다.
또한 error-2024-10-11.0.log의 파일 용량이 50mb가 넘었을경우 gz라는 확장자로 압축하여 저장하게 된다.
이를 통해 로그 파일의 용량을 최소화하여 저장할 수 있다.
마지막으로 error를 저장하는 로그와 info를 저장하는 로그 파일 각각 60개가 넘었을 시에 가장 오래된 로그파일을 삭제하도록 되어있다.
이 로그파일은 ./log 폴더에 저장되는데 내 프로젝트는 도커 환경에서 실행되므로 도커 볼륨을 통하여 도커 컨테이너 외부에 저장할 필요가 있다.
Docker Volume 을 이용하여 로그파일을 컨테이너 외부에 저장
먼저 dockerfile은 아래와 같다.
dockerfile
# 베이스 이미지로 OpenJDK 17 사용
FROM openjdk:17-jdk
# 애플리케이션을 위한 작업 디렉토리 설정
WORKDIR /spring-boot
# 빌드된 JAR 파일을 컨테이너로 복사
COPY build/libs/*SNAPSHOT.jar promise.jar
# 애플리케이션 실행
ENTRYPOINT ["java", "-jar", "/spring-boot/promise.jar"]
DB에 저장할 때 기본값이 오전 8시인데 자꾸 9시간 뒤인 오후 5시로 설정되는 문제를 확인하였다.
이렇게 9시간 차이가 나는 것은 보통 타임존 설정 문제인데, 나는 이미 타임존 관련 문제를 아래와 같이 세팅해둔 상태라서 더욱 당황했다.
@PostConstruct 를 이용한 JVM 타임존 설정
@SpringBootApplication
public class PromiseApplication {
public static void main(String[] args) {
SpringApplication.run(PromiseApplication.class, args);
}
@PostConstruct
public void init()
{
// JVM의 기본 시간대를 Asia/Seoul로 설정
TimeZone.setDefault(TimeZone.getTimeZone("Asia/Seoul"));
}
}
RDS의 타임존 설정
EC2 인스턴스의 타임존 설정
모두 한국 시간으로 되어있었다.
하지만 EC2에서 실행중인 스프링부트 프로젝트의 로깅 시간을 보면 자꾸 현재 시간보다 9시간이 느렸다.
알람 시간은 9시간 느리고, 로깅 시간은 9시간 빠르고 아주그냥 대 혼란이었다.
해결 방법
GPT에게도 물어봤지만 전부 해결이 안되는 답변이었고, 폭풍 구글링을 한 결과 아래의 글에서 해답을 찾을 수 있었다.
리전을 서울로 설정했더라도 EC2는 기본적으로 외국에 있기 때문에 날짜관련된 로직이 들어갔을 때 정상적으로 작동하지 않을 가능성이 있다.
아래의 두 가지 방법중 하나를 선택해서 이러한 문제를 해결할 수 있다.
@PostConstruct를 이용해 타임존 변경
애플리케이션 시작 시점에 명시적으로 JVM의 시간대를 설정할 수 있다.
@SpringBootApplication
public class PromiseApplication {
public static void main(String[] args) {
SpringApplication.run(PromiseApplication.class, args);
}
@PostConstruct
public void init() {
// JVM의 기본 시간대를 Asia/Seoul로 설정
TimeZone.setDefault(TimeZone.getTimeZone("Asia/Seoul"));
}
}
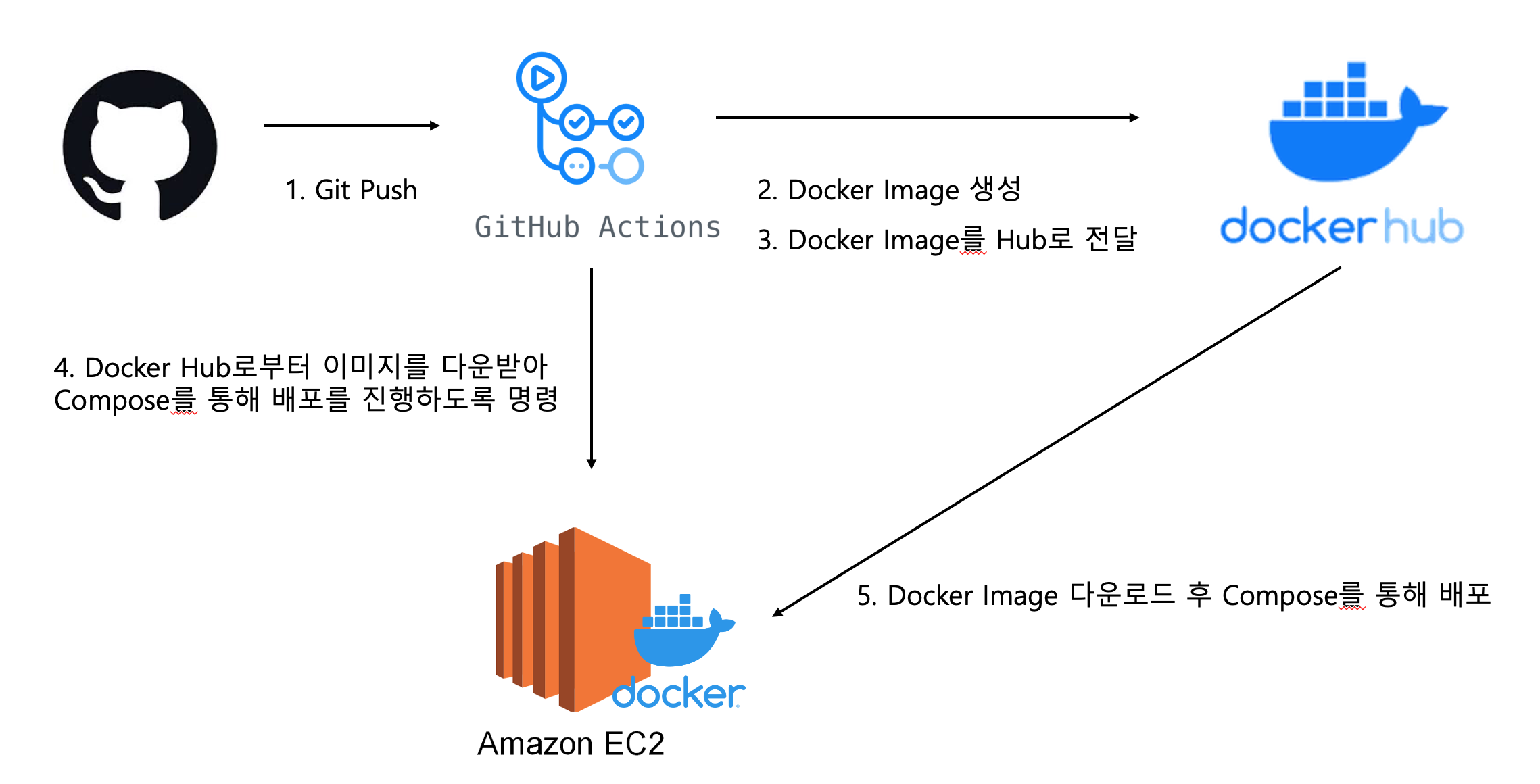
CI/CD는 소프트웨어 개발에서 중요한 개념 중 하나로, “Continuous Integration(지속적 통합)“과 “Continuous Deployment(지속적 배포)” 또는 “Continuous Delivery(지속적 전달)“를 뜻한다.
이 개념은 개발자가 더 효율적으로 코드를 작성하고, 빠르고 안정적으로 사용자에게 소프트웨어를 제공하는 것을 목표로 한다.
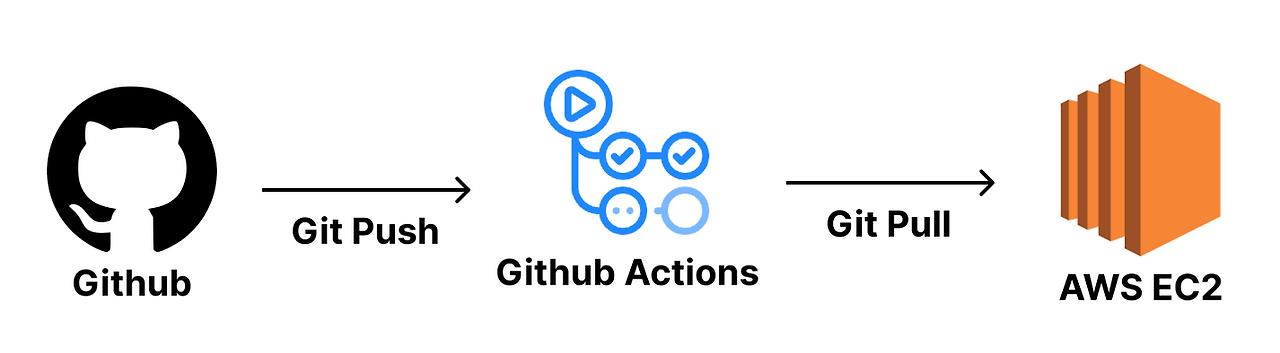
GitHub Actions는 자동화된 워크플로우를 지원하는 강력한 도구로, 저장소의 빌드, 테스트, 배포 등의 작업을 자동화할 수 있다.
즉, GitHub Actions는 CI/CD 과정에서 빌드, 테스트, 배포에 대한 로직을 실행시키는 서버(컴퓨터)의 역할을 한다.
개발자가 코드를 작성 후 커밋 & 푸시를 하는 순간 GitHub Actions는 빌드 및 테스트를 하고 EC2에 배포까지 자동화 할 수 있다.
물론 테스트 코드에서 오류가 난다면 배포가 중단된다.(서비스가 중단되는 것은 아니다.)
기본 문법
GitHub Actions에서 가장 중요한 파일은 deploy.yml인데, 이 파일의 위치는 git으로 관리되는 최상위 루트의 .github/workflows/ 폴더에 저장되어 있어야 한다.
-> 최상위루트/.github/workflows/deploy.yml
# Workflow의 이름
# Workflow : 하나의 yml 파일을 하나의 Workflow라고 부른다.
name: Github Actions 실행시켜보기
# Event : 실행되는 시점을 설정
# main이라는 브랜치에 push 될 때 아래 Workflow를 실행
on:
push:
branches:
- main
# 하나의 Workflow는 1개 이상의 Job으로 구성된다.
# 여러 Job은 기본적으로 병렬적으로 수행된다.
jobs:
# Job을 식별하기 위한 id
My-Deploy-Job:
# Github Actions를 실행시킬 서버 종류 선택
runs-on: ubuntu-latest
# Step : 특정 작업을 수행하는 가장 작은 단위
# Job은 여러 Step들로 구성되어 있다.
steps:
- name: Hello World 찍기 # Step에 이름 붙이는 기능
run: echo "Hello World" # 실행시킬 명령어 작성
- name: 여러 명령어 문장 작성하기
run: |
echo "Good"
echo "Morning"
# 참고: https://docs.github.com/en/actions/learn-github-actions/variables
- name: Github Actions 자체에 저장되어 있는 변수 사용해보기
run: |
echo $GITHUB_SHA
echo $GITHUB_REPOSITORY
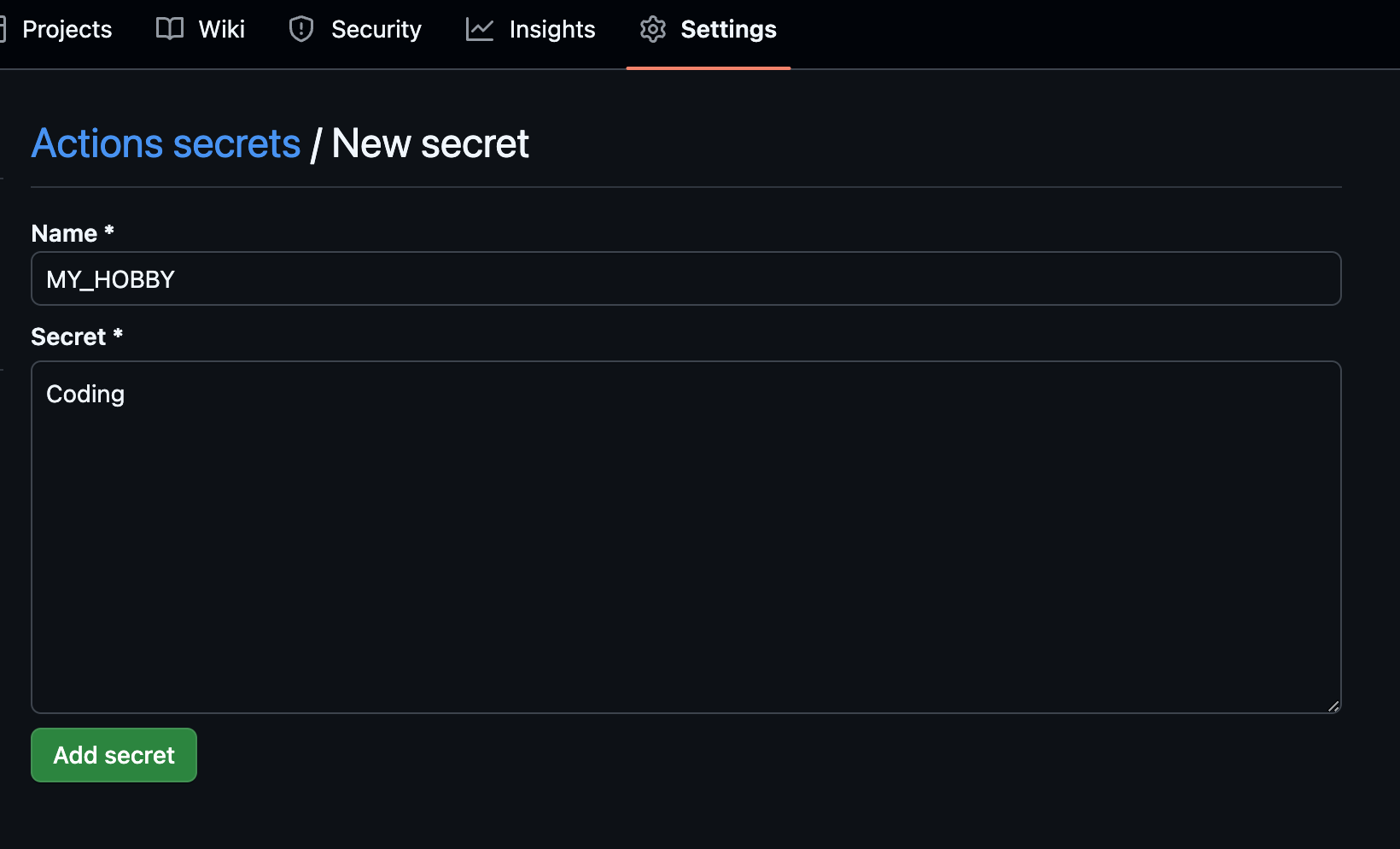
- name: Github Actions Secret 변수 사용해보기
run: |
echo ${{ secrets.MY_NAME }}
echo ${{ secrets.MY_HOBBY }}
시크릿 변수는 아래와 같이 지정할 수 있다.
스프링부트 배포 자동화
EC2에서 빌드하는 방식
이 방식은 깃허브에 저장된 소스코드를 PULL 하고 EC2에서 빌드하는 방식이다.
빌드는 컴퓨터의 자원을 많이 소모하는 작업이다.
장점
git pull을 활용해서 변경된 부분의 프로젝트 코드에 대해서만 업데이트 하기 때문에 CI/CD 속도가 빠르다.
CI/CD 툴로 Github Actions만 사용하기 때문에 인프라 구조가 복잡하지 않고 간단하다.
단점
빌드 작업을 EC2에서 직접 진행하기 때문에 운영하고 있는 서버의 성능에 영향을 미칠 수 있다.
Github 계정 정보가 해당 EC2에 저장되기 때문에 개인 프로젝트 또는 믿을만한 사람들과 같이 진행하는 토이 프로젝트에서만 사용해야 한다.
이 방법은 주로 개인 프로젝트에서 CI/CD를 심플하고 빠르게 적용시키고 싶을 때 적용한다.
name: Deploy To EC2
on:
push:
branches:
- main
jobs:
deploy:
runs-on: ubuntu-latest
steps:
- name: SSH로 EC2에 접속하기
uses: appleboy/ssh-action@v1.0.3
with:
host: ${{ secrets.EC2_HOST }} # EC2의 주소
username: ${{ secrets.EC2_USERNAME }} # EC2 접속 username
key: ${{ secrets.EC2_PRIVATE_KEY }} # EC2접속을 위한 pem 파일 내부 정보
script_stop: true # 아래 script 중 실패하는 명령이 하나라도 있으면 실패로 처리
script: |
cd /home/ubuntu/instagram-server # 여기 경로는 자신의 EC2에 맞는 경로로 재작성하기
git pull origin main
./gradlew clean build
sudo fuser -k -n tcp 8080 || true # || true를 붙인 이유는 8080에 종료시킬 프로세스가 없더라도 실패로 처리하지 않기 위해서이다.
# jar 파일을 실행시키는 명령어이다. 그리고 발생하는 로그들을 ./output.log 파일에 남기는 명령어이다.
nohup java -jar build/libs/*SNAPSHOT.jar > ./output.log 2>&1 &
이렇게 설정하면 output.log를 통해서 로그 데이터를 읽을 수 있다.
민감한 값을 따로 application.yml로 분리하는 경우가 많다. 민감한 값이기에 .gitignore에 추가해서 application.yml가 버전관리 되지 않게 세팅한다.
.gitignore
...
application.yml
deploy.yml 수정
name: Deploy To EC2
on:
push:
branches:
- main
jobs:
deploy:
runs-on: ubuntu-latest
steps:
- name: SSH로 EC2에 접속하기
uses: appleboy/ssh-action@v1.0.3
env:
APPLICATION_PROPERTIES: ${{ secrets.APPLICATION_PROPERTIES }}
with:
host: ${{ secrets.EC2_HOST }} # EC2의 주소
username: ${{ secrets.EC2_USERNAME }} # EC2 접속 username
key: ${{ secrets.EC2_PRIVATE_KEY }} # EC2의 Key 파일의 내부 텍스트
envs: APPLICATION_PROPERTIES
script_stop: true # 아래 script 중 실패하는 명령이 하나라도 있으면 실패로 처리
script: |
cd /home/ubuntu/instagram-server # 여기 경로는 자신의 EC2에 맞는 경로로 재작성하기
rm -rf src/main/resources/application.yml
git pull origin main
echo "$APPLICATION_PROPERTIES" > src/main/resources/application.yml
./gradlew clean build
sudo fuser -k -n tcp 8080 || true # || true를 붙인 이유는 8080에 종료시킬 프로세스가 없더라도 실패로 처리하지 않기 위해서이다.
nohup java -jar build/libs/*SNAPSHOT.jar > ./output.log 2>&1 &
이렇게 하면 application.yml이 git에 추적되지 않고, 배포를 자동화 할 수 있다.
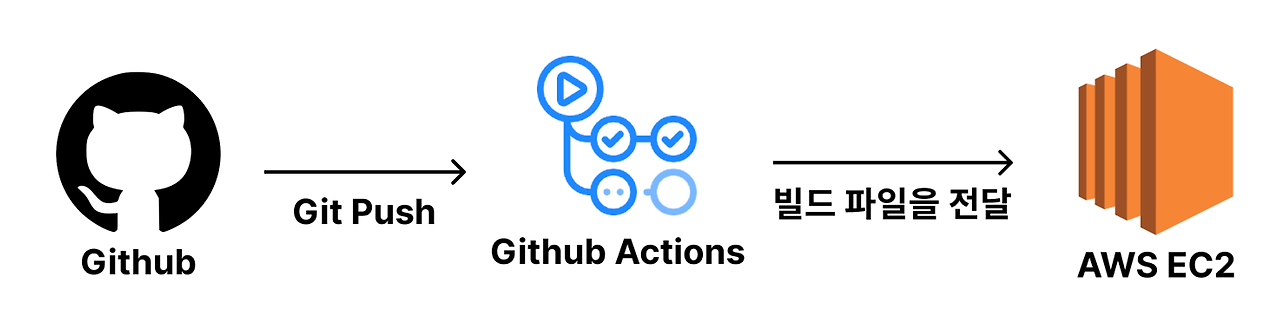
GitHub Actions에서 빌드하는 방식
이 방식은 빌드를 GitHub Actions에서 하는 방식이다.
장점
빌드 작업을 Github Actions에서 하기 때문에 운영하고 있는 서버의 성능에 영향을 거의 주지 않는다.
CI/CD 툴로 Github Actions만 사용하기 때문에 인프라 구조가 복잡하지 않고 간단하다.
단점
무중단 배포를 구현하거나 여러 EC2 인스턴스에 배포를 해야 하는 상황이라면, 직접 Github Actions에 스크립트를 작성해서 구현해야 한다.
Stateless(무상태)는 시스템이나 애플리케이션이 특정 요청 간의 상태를 저장하지 않는 구조를 의미한다. 즉, 각 요청은 서로 독립적이며, 요청을 처리하는 데 있어서 이전의 요청이나 세션 정보를 참조하지 않는다.
Docker에서 Stateless는 컨테이너의 성격과 관련이 깊다. Docker 컨테이너는 애플리케이션의 실행 환경을 격리된 상태로 제공하며, Stateless 방식으로 설계된 애플리케이션을 실행하기에 적합하다.
컨테이너의 Stateless 특성
Docker 컨테이너는 일반적으로 Stateless 특성을 가진다. 즉, 컨테이너를 중지하거나 삭제하면 그 안에서 발생한 모든 변경 사항이 사라진다.
Stateless 애플리케이션은 상태를 컨테이너 내부에 저장하지 않으므로, Docker의 Stateless 특성에 잘 맞는다. 상태를 저장할 필요가 없기 때문에 컨테이너를 언제든지 삭제하거나 다시 시작할 수 있다.
수평적 확장
Stateless 애플리케이션은 상태를 저장하지 않기 때문에 여러 개의 컨테이너로 쉽게 수평적 확장이 가능하다. 애플리케이션의 요청이 어느 컨테이너로 가든 상관없기 때문에 로드 밸런서를 통해 자유롭게 트래픽을 분산할 수 있다.
반면, Stateful 애플리케이션은 상태를 공유해야 하므로 여러 컨테이너로 확장하는 것이 어려울 수 있다.
상태 저장소와의 분리
Stateless 애플리케이션은 데이터를 외부 저장소(예: 데이터베이스, 파일 스토리지 등)에 저장하고, 그 상태는 애플리케이션이 아닌 별도의 시스템에서 관리한다. Docker는 이와 같은 Stateless 애플리케이션을 여러 개 실행하여 높은 가용성을 유지할 수 있도록 도와준다.
컨테이너의 stateless 특징
컨테이너의 이미지는 한번 지정된 후 변경되지 않음(새로운 설정이나 패치가 필요할 경우 새로운 이미지를 만들어야 함).
컨테이너는 언제든지 새로운 컨테이너로 대체할 수 있음.
컨테이너는 어떤 호스트에서든 컨테이너를 실행할 수 있음.
컨테이너는 동일한 컨테이너를 여러개 쉽게 생성해서 트래픽에 대응할 수 있음.
장애가 발생한 경우 새로운 컨테이너를 빠르게 시작할 수 있음.
컨테이너의 Stateless 제약
데이터를 영구적으로 저장하기 위해서는 데이터베이스 사용이 필수.
상태가 없기 때문에 저장 및 공유가 필요한 데이터는 무조건 외부에 저장해야 함.
사용자 세션 정보나 캐시 같은 정보를 캐시 서버나 쿠키를 통해 관리(파일이나 메모리에 저장하지 않아야 함).
동일한 요청은 항상 동일한 결과를 제공해야 함(서버마다 다른 응답을 제공하면 안됨).
환경 변수나 구성 파일을 통해 설정을 외부에서 주입할 수 있어야 함.
Docker Volume
Docker 볼륨(Docker Volume)은 Docker 컨테이너와 호스트 시스템 간의 데이터를 영구적으로 저장하거나 공유할 수 있도록 해주는 메커니즘이다.
컨테이너는 일시적이고 휘발성이기 때문에, 컨테이너를 삭제하거나 중지하면 내부의 데이터는 사라지게 된다.
Docker 볼륨은 이를 해결하기 위한 방법으로, 데이터를 컨테이너 외부에 저장할 수 있게 해준다.
컨테이너가 중지되거나 삭제되더라도, 볼륨에 저장된 데이터는 유지된다. 따라서 중요한 데이터를 안전하게 보관할 수 있다.
하나의 볼륨을 여러 컨테이너에서 공유할 수 있다. 이를 통해 여러 컨테이너가 동일한 데이터를 읽거나 쓸 수 있다.
볼륨을 사용하면 호스트 시스템의 디렉토리와 컨테이너 내부의 특정 경로를 연결할 수 있다. 이를 통해 호스트 시스템에서 생성한 데이터를 컨테이너 내부에서 사용할 수 있다.
Docker 볼륨은 Docker가 독립적으로 관리하므로, 컨테이너와는 별도로 볼륨을 생성, 삭제, 관리할 수 있다.
관리형 볼륨
Docker 관리형 볼륨(Volume)은 Docker가 자동으로 생성하고 관리하는 방식이다.
사용자가 호스트 시스템의 경로를 지정할 필요가 없으며, Docker가 자동으로 볼륨을 생성하고 관리한다.
컨테이너와 별개로 독립된 데이터 저장소로 사용될 수 있다.
또한 하나의 컨테이너가 여러 개의 볼륨을 사용할 수 있다.
여러 개의 컨테이너가 하나의 볼륨을 공유하는 것도 가능하다.
장점: Docker가 자체적으로 관리하므로 이동성과 관리가 용이하다. 볼륨은 컨테이너의 생애주기와 무관하게 존재할 수 있다.
단점: 호스트 시스템의 특정 경로를 직접 연결하는 바인드 마운트에 비해 유연성이 떨어질 수 있다.
바인드 마운트
호스트 시스템의 특정 디렉토리를 컨테이너 내부의 디렉토리와 연결한다.
경로를 명시적으로 지정해야 하며, 호스트 시스템에 있는 데이터와 직접 연결된다.
Docker가 아닌 사용자가 경로를 관리하고, Docker는 그 경로에 대한 관리 권한이 없다.
docker run -v /host/path:/container/path --name my-container
장점: 호스트의 특정 디렉토리와 직접 연결되어 데이터를 쉽게 공유할 수 있다.
단점: 호스트 시스템의 디렉토리 경로를 명시적으로 지정해야 하므로, 이동성과 관리가 어렵다.
이 글은 인프런의 개발자를 위한 쉬운도커(데브위키) 강의를 수강하고 개인적으로 정리하는 글임을 알립니다.
네트워크 기본 개념
공인IP와 사설IP
공인 IP
공인 IP는 전 세계 어디서나 고유하게 사용되며, 인터넷 상에서 서버나 장치가 통신할 때 사용된다. 일반적으로 ISP(인터넷 서비스 제공자)로부터 할당받는다.
그림에서 공유기가 공인 IP를 사용하여 외부 서버와 통신한다.
사설 IP
사설 IP는 특정 네트워크 안에서만 유효하며, 외부 인터넷에서는 사용되지 않는다. 가정이나 회사 내부에서 네트워크 장치 간 통신을 할 때 사용된다.
사설 IP는 라우터나 공유기에 의해 내부 네트워크의 장치(스마트폰, 컴퓨터 등)에 할당된다.
사설 IP 대역은 10.0.0.0~10.255.255.255, 172.16.0.0~172.31.255.255, 192.168.0.0~192.168.255.255가 있다. 이 대역의 IP는 외부 인터넷에서는 사용되지 않는다.
공유기는 내부 네트워크의 장치들에게 사설 IP를 할당하고, 공인 IP를 사용하여 외부와 통신하는 역할을 한다.
이를 통해 여러 장치가 하나의 공인 IP로 외부와 연결될 수 있다. 이 과정에서 NAT(Network Address Translation)라는 기술이 사용된다.
공인망과 사설망
공인망 (Public Network)
공인 IP: 공인망에서는 공인 IP가 사용된다. 이 IP 주소는 전 세계적으로 고유하며, 외부 인터넷에서 접근 가능하다.
이 다이어그램에서는 외부 서버가 공인 IP를 사용하여 외부 네트워크와 통신하고 있다. 일반적으로 웹 서버나 API 서버 등이 공인 IP를 통해 외부와 연결된다.
사설망 (Private Network)
사설 IP: 사설망에서는 사설 IP가 사용된다. 이 IP 주소는 특정 네트워크 내에서만 유효하며, 외부 인터넷에서는 직접 접근할 수 없다.
사설망에서는 라우터가 공인 IP를 사설 IP로 변환해주는 역할을 한다. 이를 통해 내부 네트워크 장치들이 공인 IP를 사용해 외부와 통신할 수 있게 된다.
라우터
라우터는 공인망과 사설망을 연결하는 장치이다. 공인 IP를 통해 외부와 통신하며, 내부 네트워크 장치에 사설 IP를 할당해 준다.
라우터는 NAT(Network Address Translation)을 사용하여 공인 IP로 들어오는 트래픽을 사설 IP를 가진 장치로 전달하고, 반대로 사설망에서 나가는 트래픽을 공인 IP로 변환하여 외부로 나간다.
사설망 통신
사설망 내에서 각각의 장치들(서버들)은 사설 IP로 서로 통신할 수 있다. 이 통신은 외부 인터넷과는 독립적이며, 오로지 내부 네트워크에서만 이루어진다.
각 서버는 192.168.0.x 대역의 IP 주소를 사용하며, 이 IP 주소는 사설망 내에서만 유효하다.
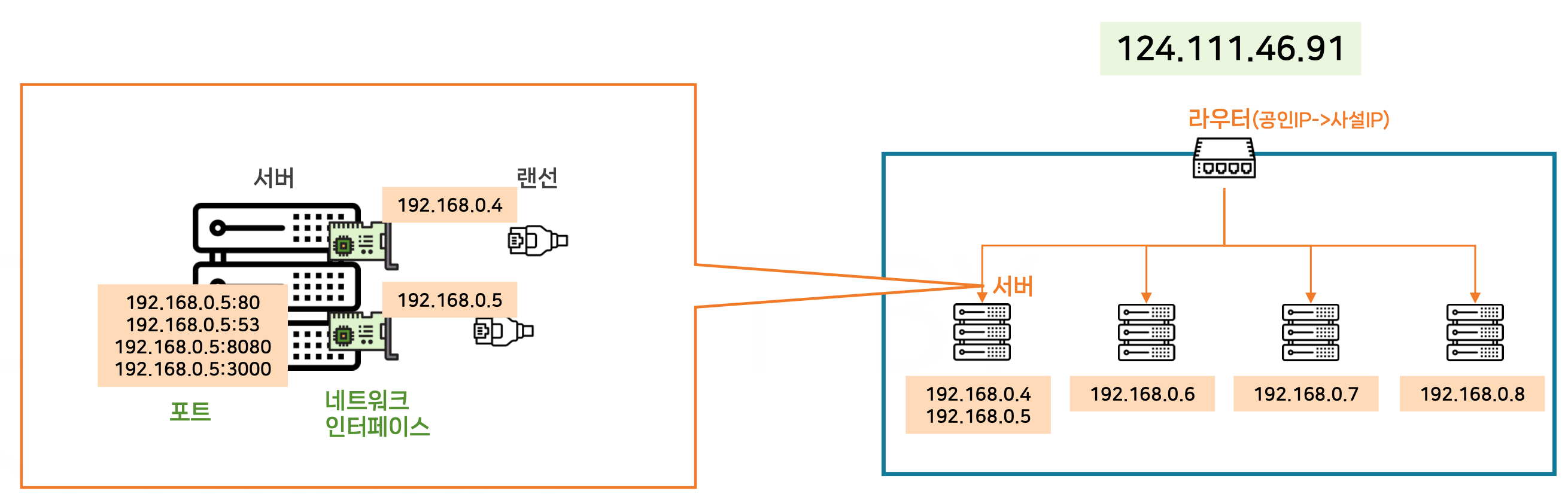
인터페이스와 포트
공인 IP는 외부 인터넷에서 네트워크 장치로 접근할 수 있는 고유한 주소이다. 여기서 124.111.46.91이 공인 IP로 설정되어 있으며, 외부 인터넷 사용자가 이 IP를 통해 내부 네트워크로 접근할 수 있다.
사설 IP는 내부 네트워크에서만 유효한 IP 주소이다. 예를 들어, 192.168.0.4, 192.168.0.5, 192.168.0.7, 192.168.0.8 등의 IP가 내부 네트워크에서 각 서버에 할당되어 있다. 이 사설 IP는 외부에서는 접근할 수 없으며, 라우터가 공인 IP와 사설 IP 간의 트래픽을 관리한다.
네트워크 인터페이스
각 서버는 네트워크 인터페이스를 통해 인터넷 또는 내부 네트워크에 연결된다. 여기서 192.168.0.4와 192.168.0.5가 서로 다른 네트워크 인터페이스를 통해 연결되어 있다.
랜선을 통해 물리적으로 네트워크에 연결된 상태를 나타낸다.
유선 연결: 컴퓨터의 랜포트에 랜선을 꽂아 네트워크에 연결하는 방식. 예를 들어, 컴퓨터와 공유기를 랜선으로 연결하면 그 랜선이 네트워크 인터페이스를 통해 데이터를 주고받는다.
무선 연결: Wi-Fi를 통해 무선으로 네트워크에 연결할 때 사용하는 네트워크 인터페이스. 컴퓨터나 스마트폰의 무선 네트워크 카드가 Wi-Fi 신호를 잡아 네트워크와 통신한다.
가상화된 네트워크 연결: 클라우드 서버나 가상 머신(VM)에서는 실제 물리적인 장치 대신 소프트웨어적으로 만들어진 가상 네트워크 인터페이스를 사용한다. 이를 통해 가상 머신도 네트워크와 연결될 수 있다.
네트워크 인터페이스가 하는 일
데이터 송수신: 네트워크 인터페이스는 컴퓨터에서 나가는 데이터(예: 인터넷 요청)를 네트워크로 보내고, 외부에서 들어오는 데이터(예: 웹사이트 응답)를 받아들인다.
주소 할당: 네트워크 인터페이스는 고유한 IP 주소를 가진다. 이를 통해 장치가 네트워크 상에서 서로 구분될 수 있다. 예를 들어, Wi-Fi를 사용할 때마다 장치가 IP 주소를 할당받고, 그 주소로 데이터를 주고받는다.
포트 (Port)
포트는 네트워크에서 특정 서비스를 식별하기 위한 논리적인 번호이다. 예를 들어, 하나의 서버(예: 192.168.0.5)에서 여러 개의 서비스가 실행될 때, 각 서비스는 고유한 포트를 사용한다.
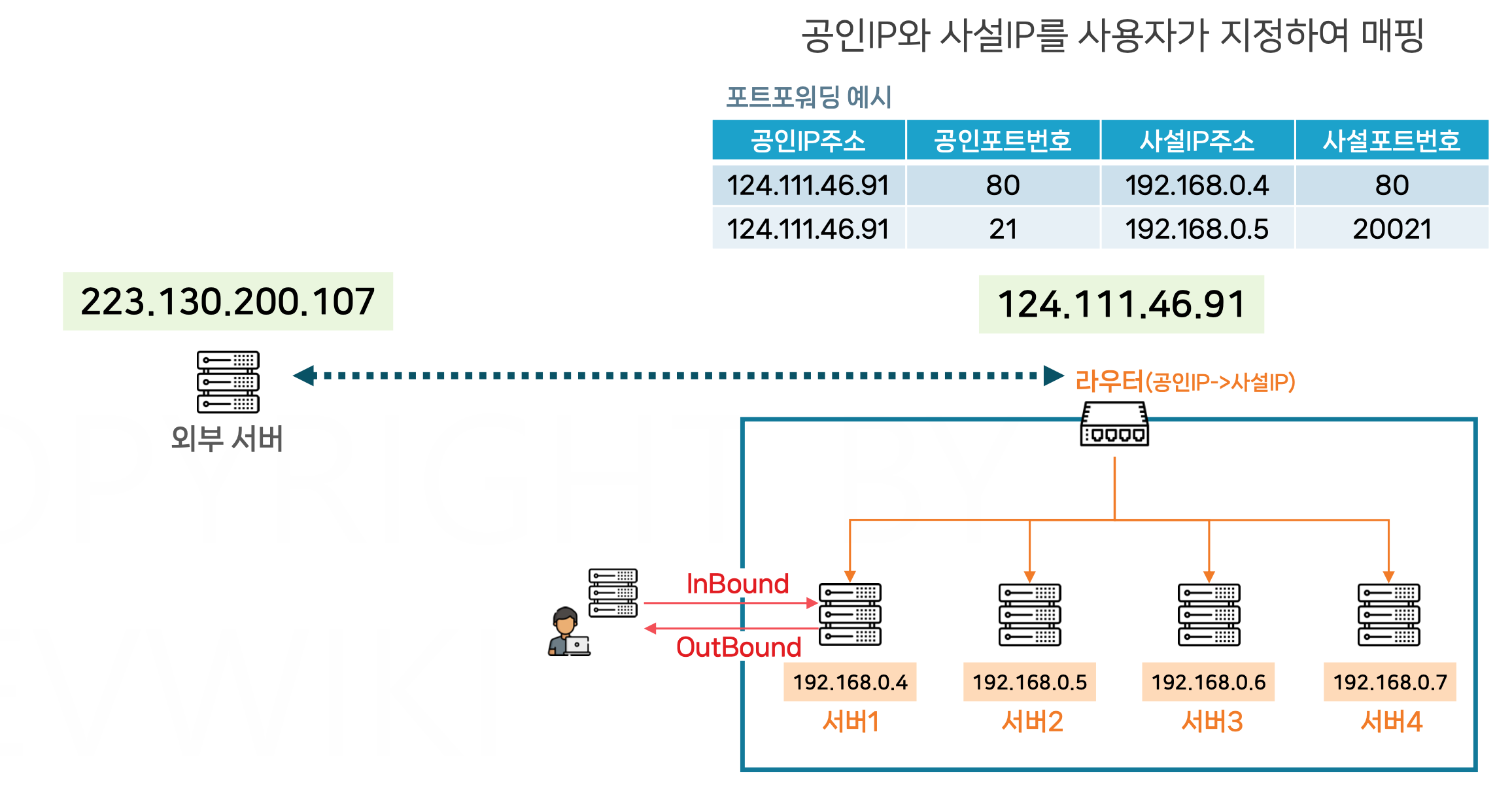
NAT와 포트포워딩
NAT
이 그림은 NAT(Network Address Translation)을 통해 공인 IP와 사설 IP 간의 통신을 설명하는 구조이다.
NAT는 내부 네트워크에서 사용하는 사설 IP 주소를 공인 IP 주소로 변환하여 외부와 통신할 수 있도록 하는 기술이다.
NAT 테이블
NAT 테이블은 공인 IP와 사설 IP 간의 매핑 정보를 저장하는 역할을 한다. 이 테이블에 따라 외부에서 들어오는 요청이 어떤 사설 IP와 연결될지 결정된다.
InBound 트래픽: 외부에서 내부 네트워크로 들어오는 데이터 흐름을 의미한다. 예를 들어, 외부 클라이언트가 공인 IP로 HTTP 요청을 보내는 것이 InBound 트래픽이다.
OutBound 트래픽: 내부 네트워크에서 외부로 나가는 데이터 흐름을 의미한다. 내부 서버에서 외부의 클라이언트나 서버로 데이터를 보내는 것이 OutBound 트래픽이다.
포트포워딩
포트 포워딩
포트 포워딩은 외부에서 들어오는 특정 포트의 요청을 내부 서버의 특정 포트로 전달하는 역할을 한다.
124.111.46.91:80 → 192.168.0.4:80: 외부 클라이언트가 공인 IP의 80번 포트(주로 HTTP 요청)에 접근하면 이 트래픽은 192.168.0.4 서버의 80번 포트로 전달된다.
124.111.46.91:21 → 192.168.0.5:20021: 외부 클라이언트가 공인 IP의 21번 포트(주로 FTP 요청)에 접근하면 이 트래픽은 192.168.0.5 서버의 20021번 포트로 전달된다.
NAT(Network Address Translation)
라우터는 NAT 기술을 사용해 공인 IP와 사설 IP 간의 매핑을 관리한다. 이 과정을 통해 외부에서 공인 IP로 들어오는 요청을 내부 네트워크의 서버로 전달할 수 있다.
NAT와 포트포워딩 차이점
NAT(Network Address Translation)와 포트 포워딩(Port Forwarding)은 네트워크에서 공인 IP와 사설 IP 간의 통신을 관리하는 두 가지 주요 기술이지만, 그 목적과 동작 방식에서 차이가 있다.
NAT (Network Address Translation)
주요 역할: 공인 IP와 사설 IP 간의 주소 변환을 통해 내부 네트워크 장치들이 공인 IP 하나를 사용하여 외부 인터넷과 통신할 수 있도록 한다.
동작 방식: NAT는 주로 내부 네트워크에서 여러 장치(사설 IP 주소)가 하나의 공인 IP 주소를 공유할 수 있도록 한다. 내부 장치들이 외부로 나갈 때 사설 IP 주소를 공인 IP 주소로 변환하고, 반대로 외부에서 들어오는 데이터는 공인 IP에서 사설 IP로 다시 변환된다.
사용 사례: 가정이나 회사에서 여러 장치가 하나의 공인 IP로 인터넷에 접속하는 환경에서 NAT는 필수적이다.
포트 포워딩 (Port Forwarding)
주요 역할: 공인 IP의 특정 포트로 들어오는 외부 요청을 내부 네트워크의 특정 장치(사설 IP)와 특정 포트로 전달하는 기술이다.
동작 방식: 외부에서 들어오는 요청이 공인 IP의 특정 포트에 도착하면, 라우터나 방화벽이 이 요청을 내부의 특정 장치로 전달한다. 이때 공인 IP의 포트와 사설 IP의 포트를 각각 설정하여, 외부에서 내부 서버로의 접근을 가능하게 한다.
사용 사례: 외부에서 내부 네트워크의 특정 서버에 접근하려는 경우, 포트 포워딩을 통해 접근을 허용한다.
항목
NAT
포트 포워딩
기능
공인 IP와 사설 IP 간의 주소 변환
공인 IP의 특정 포트를 사설 IP와 포트로 매핑
목적
내부 네트워크 장치들이 외부와 인터넷 통신을 할 수 있도록 지원
외부에서 특정 내부 서버로 접근할 수 있도록 설정
적용 대상
내부 네트워크 전체 (여러 장치)
특정 포트에 대한 요청 (특정 서비스나 서버)
통신 방향
주로 내부에서 외부로 나가는 트래픽 처리
주로 외부에서 내부로 들어오는 트래픽 처리
사용 사례
여러 장치가 하나의 공인 IP로 인터넷에 나가는 상황
웹 서버, FTP 서버 등에 외부에서 접근할 때, 특정 포트로의 연결 필요
도커 네트워크
가상 네트워크
Docker는 컨테이너 간의 통신을 관리하기 위해 가상 네트워크를 사용하며, 기본적으로 브리지 네트워크(bridge network)를 통해 각 컨테이너에 IP 주소를 할당하고 통신할 수 있도록 한다.
Docker는 가상 네트워크(브리지)를 통해 각 컨테이너에 고유한 IP를 할당하고, 컨테이너 간의 통신을 관리한다.
브리지 네트워크를 통해 컨테이너 간에 직접적인 통신이 가능하며, 외부 네트워크와 통신할 때는 NAT를 사용해 공인 IP와 사설 IP를 변환한다.
Docker 네트워크를 사용하면, 각 컨테이너가 독립적인 네트워크 환경에서 동작하면서도 필요한 경우 외부 네트워크와 통신할 수 있다.
가상 네트워크 브리지 (docker0)
Docker는 기본적으로 가상 브리지 네트워크를 생성한다. 이 브리지 네트워크는 컨테이너들이 같은 네트워크 안에서 서로 통신할 수 있도록 해준다.
그림에서는 docker0이라는 가상 네트워크 인터페이스가 생성되어 있으며, 이 브리지를 통해 각 컨테이너들이 서로 연결된다.
가상의 IP 할당
Docker는 각 컨테이너에 고유한 IP 주소를 할당한다. 이 IP 주소는 Docker가 생성한 브리지 네트워크 내에서만 유효하며, 기본적으로 172.17.0.x 대역을 사용한다.
예시로 컨테이너1은 172.17.0.2, 컨테이너2는 172.17.0.3 등의 IP 주소를 할당받아 서로 독립적으로 동작하지만, 동일한 브리지 네트워크 안에 있기 때문에 서로 통신할 수 있다.
컨테이너 간 통신
동일한 브리지 네트워크에 속해 있는 컨테이너들끼리는 할당된 IP 주소를 통해 직접 통신할 수 있다. 그림에서 컨테이너1은 컨테이너2와 같은 네트워크 내에 있기 때문에 172.17.0.x 대역을 통해 서로 데이터를 주고받을 수 있다.
외부 네트워크(공인망이나 사설망)와의 통신이 필요하다면, Docker가 IP 마스커레이딩(NAT)을 통해 외부와 통신할 수 있도록 한다.
외부 네트워크와의 연결
서버(실습용 PC)의 192.168.0.10 IP는 내부 네트워크에서 할당된 IP이며, 이 서버에 설치된 Docker 컨테이너들은 외부 네트워크로의 접속이 필요할 때 192.168.0.10 또는 공인 IP 124.111.46.91을 통해 외부와 통신하게 된다.
이때 Docker의 NAT 기능이 활용되어, 컨테이너의 내부 IP와 외부 IP 간의 변환을 통해 외부와의 통신이 이루어진다.
주요 동작 과정
가상의 네트워크 브리지 생성: Docker는 기본적으로 docker0이라는 브리지를 자동으로 생성하여, 각 컨테이너가 이 브리지 네트워크에 연결되도록 한다.
컨테이너에 가상 IP 할당: 브리지 네트워크에 연결된 각 컨테이너는 172.17.0.x 대역의 IP 주소를 할당받는다. 이 IP 주소는 컨테이너 간 통신을 가능하게 한다.
컨테이너 간의 통신 전달: 같은 브리지 네트워크에 속해 있는 컨테이너끼리는 IP 주소를 통해 서로 통신할 수 있다. 외부 네트워크와 통신할 경우 NAT를 통해 IP 주소를 변환하여 외부와 연결한다.
가상 네트워크와 가상 인터페이스
기본적으로 각 브릿지 네트워크는 서로 격리되어 있다. 즉, 서로 다른 브릿지 네트워크에 속한 컨테이너들은 직접적으로 통신할 수 없다.
docker0 브릿지 네트워크는 Docker 컨테이너 간의 통신을 위한 가상 네트워크를 제공하며, 각 컨테이너는 가상 인터페이스(Veth)를 통해 연결된다.
Veth 인터페이스는 각 컨테이너에 고유한 IP를 할당하고, 이 인터페이스를 통해 트래픽을 주고받는다.
iptables는 Docker가 자동으로 설정하는 트래픽 관리 도구로, 컨테이너 간 통신이나 외부 네트워크로의 트래픽 흐름을 제어한다.
물리적 인터페이스인 eth0는 외부 네트워크와 연결되며, Docker 컨테이너가 외부 네트워크와 통신할 때 사용된다.
브릿지 네트워크 (docker0)
docker0는 Docker가 기본적으로 생성하는 가상 브리지 네트워크이다. Docker는 이 네트워크를 통해 모든 컨테이너들이 서로 연결될 수 있도록 한다.
Docker는 기본적으로 docker0이라는 브릿지 네트워크를 생성하며, 모든 컨테이너는 이 기본 브릿지 네트워크에 속하게 된다. 하지만, 사용자가 새로운 브릿지 네트워크를 생성하여 특정 컨테이너들을 격리할 수 있다. 이러한 경우, 각각의 브릿지 네트워크는 독립적으로 작동하며, 그 안에 속한 컨테이너끼리만 통신이 가능하다.
IP 주소: docker0의 IP는 172.17.0.1로 설정되어 있으며, 이는 가상 네트워크 안에서 컨테이너들과 통신할 때 사용된다.
가상 인터페이스 (Veth 인터페이스)
Veth(Virtual Ethernet)는 각 컨테이너와 호스트 머신 간에 가상 네트워크 인터페이스를 제공하는 장치이다. 그림에서 각 컨테이너는 Veth 인터페이스를 통해 호스트 머신의 docker0와 연결된다.
예를 들어, 컨테이너1은 Veth1(172.17.0.2), 컨테이너2는 Veth2(172.17.0.3)로 연결된다. 각 컨테이너가 브리지 네트워크를 통해 독립적으로 통신할 수 있도록 Veth 인터페이스가 만들어진다.
Veth 인터페이스는 페어로 구성되며, 한 쪽은 컨테이너 내부에, 다른 쪽은 호스트 머신에 존재한다.
물리 인터페이스 (eth0)
eth0는 실제 물리적 네트워크 인터페이스로, 호스트 머신(서버)이 외부 네트워크와 연결되기 위해 사용하는 인터페이스이다.
호스트 머신의 IP는 192.168.0.10으로 설정되어 있으며, 이 IP를 통해 물리적으로 외부 네트워크와 통신한다.
iptables
iptables는 Linux 시스템에서 네트워크 트래픽을 관리하고 제어하는 방화벽 역할을 하는 도구이다. Docker는 iptables 규칙을 자동으로 생성하여, 컨테이너 간의 통신과 외부 네트워크와의 트래픽 흐름을 제어한다.
Docker가 생성하는 규칙은 Veth 인터페이스를 통해 흐르는 트래픽을 제어하며, 이를 통해 네트워크 보안을 유지하거나 특정 통신을 차단할 수 있다.
트래픽 흐름 및 제어
각 컨테이너는 가상 인터페이스를 통해 docker0 브릿지에 연결되고, 외부 네트워크와 연결되려면 물리적 인터페이스인 eth0를 통해 통신한다.
컨테이너1 (172.17.0.2)과 같은 컨테이너는 Veth1을 통해 네트워크에 연결되고, 다른 컨테이너나 외부와 통신할 때 iptables 규칙을 따르게 된다.
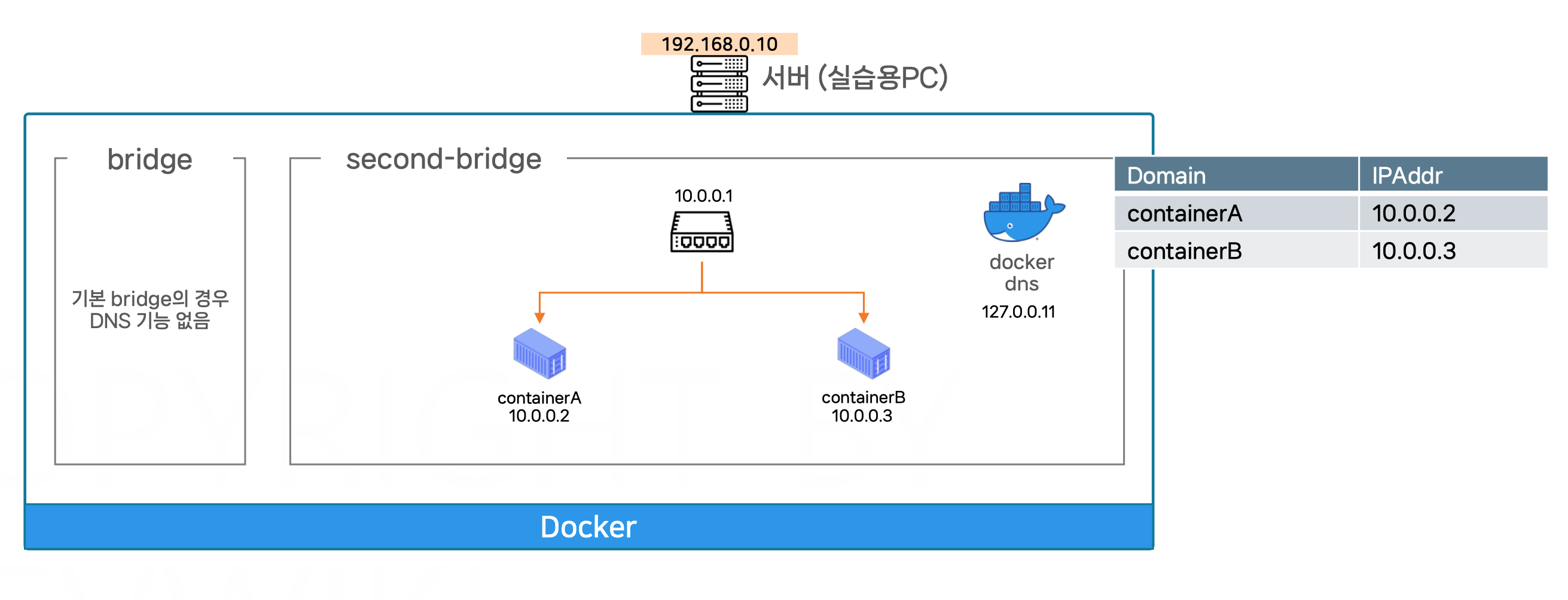
가상 네트워크와 DNS
기본 브리지 네트워크에서는 DNS 기능이 제공되지 않으며, 컨테이너들은 IP 주소로만 통신할 수 있다.
커스텀 브리지 네트워크(second-bridge)에서는 Docker DNS를 통해 도메인 이름으로 통신이 가능하다. 이로 인해 컨테이너 간 통신이 더 쉽고 직관적으로 이루어진다.
Docker DNS는 도메인 이름을 IP 주소로 변환해주며, 이를 통해 컨테이너 간에 IP 주소 대신 도메인 이름으로 쉽게 접근할 수 있다.
브리지 네트워크
브리지 네트워크(Bridge)는 Docker에서 기본적으로 제공하는 네트워크로, 각 컨테이너가 가상 네트워크에 연결되어 동일한 네트워크 내에서 통신할 수 있게 한다.
그림에서 기본 브리지 네트워크는 DNS 기능이 제공되지 않는다. 즉, 기본 브리지 네트워크에 있는 컨테이너는 IP 주소로만 서로 통신할 수 있으며, 도메인 이름을 사용한 통신이 불가능하다.
second-bridge 네트워크
second-bridge는 사용자가 정의한 커스텀 브리지 네트워크이다. 이 네트워크에서는 Docker DNS를 사용하여 컨테이너들이 도메인 이름을 통해 통신할 수 있다.
그림에서는 containerA와 containerB가 이 커스텀 브리지 네트워크에 연결되어 있으며, 각각의 컨테이너에 IP 주소가 할당되어 있다. containerA는 10.0.0.2, containerB는 10.0.0.3의 IP 주소를 가진다.
Docker DNS
Docker는 기본적으로 커스텀 네트워크에서는 내장된 DNS 서비스를 제공한다. 이를 통해 컨테이너들은 서로를 IP 주소 대신 도메인 이름(Domain Name)으로 접근할 수 있다.
예를 들어, containerA는 containerB의 IP 주소(10.0.0.3)를 직접 사용할 필요 없이, 도메인 이름 containerB를 사용해 통신할 수 있다.
Docker DNS의 IP는 127.0.0.11로 설정되어 있으며, 이 주소를 통해 도메인 이름을 IP 주소로 변환해준다.
도메인 이름을 통한 통신
커스텀 브리지 네트워크 내에서 containerA는 containerB의 도메인 이름을 통해 쉽게 통신할 수 있다.
예를 들어, containerA가 containerB로 데이터를 전송하려면 containerB라는 도메인 이름을 사용하면 Docker DNS가 이 도메인 이름을 10.0.0.3으로 변환해 준다.