이 게시글은 이것이 자바다(저자 : 신용권, 임경균)의 책과 동영상 강의를 참고하여 개인적으로 정리하는 글임을 알립니다.
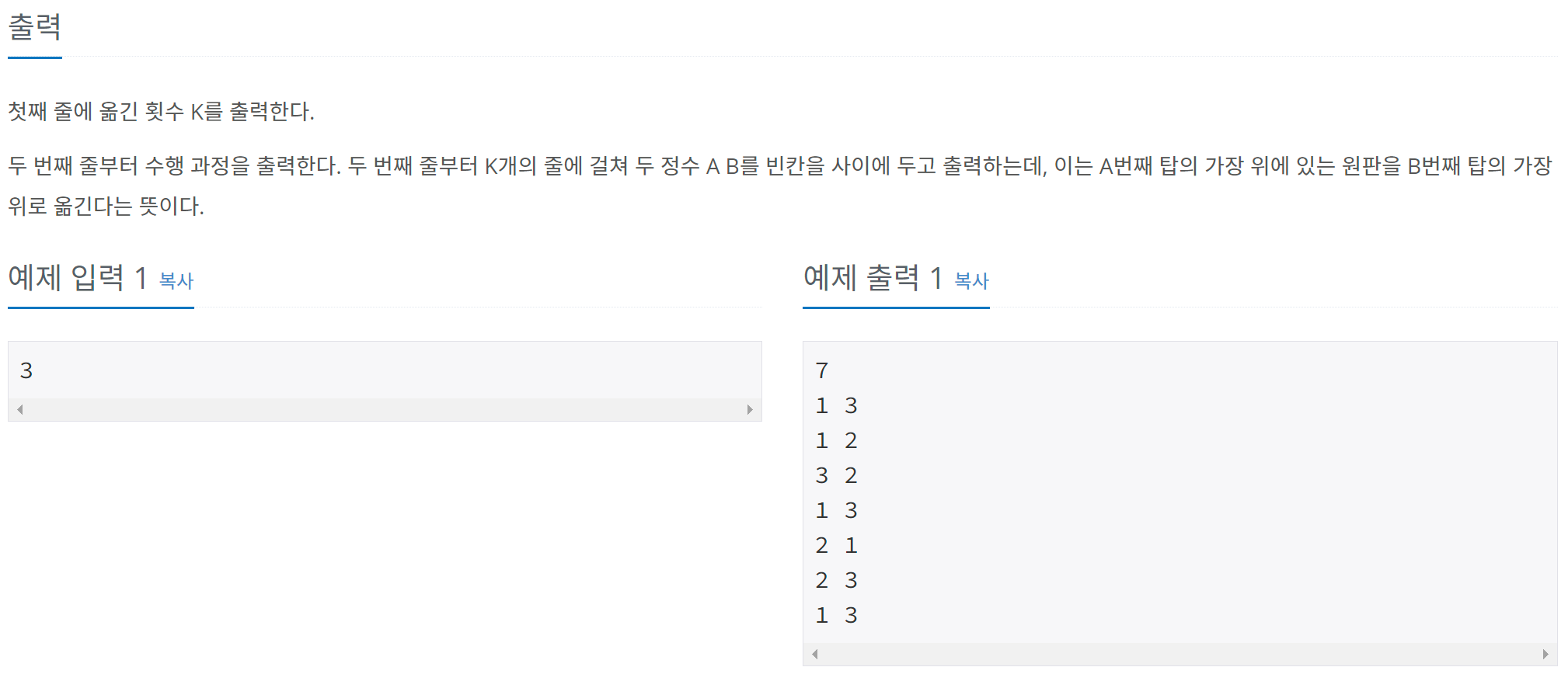
네트워크
네트워크 : 여러 컴퓨터들을 통신 회선으로 연결한 것
LAN(Local Area Network) : 가정, 회사, 건물, 특정 영역에 존재하는 컴퓨터를 연결한 것
WAN(Wide Area Network) : LAN을 연결한 것
WAN이 우리가 흔히 말하는 인터넷이다.
출처 : 이것이 자바다 유튜브 동영상 강의
Switch(Hub) : 특정 영역에 존재하는 컴퓨터를 연결하는 물리적인 장치
스위치와 허브의 개념은 엄연히 다르지만 특정 영역에 존재하는 컴퓨터를 연결하는 물리적인 장치라는 면에서 공통점을 가진다.
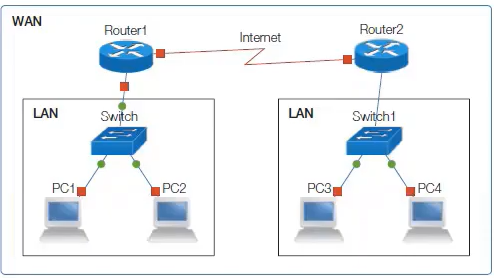
서버와 클라이언트
네트워크에서 유무선으로 컴퓨터가 연결되어 있다면 실제로 데이터를 주고받는 행위는 프로그램들이 한다.
Server(서버) : 서비스를 제공하는 프로그램
Client(클라이언트) : 서비스를 요청하는 프로그램
인터넷에서 두 프로그램이 통신하기 위해서 먼저 클라이언트가 서비스를 요청하고, 서버는 처리 결과를 응답으로 제공해 준다.
출처 : 이것이 자바다 유튜브 동영상 강의
IP 주소
IP(Internet Protocol)란 컴퓨터의 고유한 주소이다.
IP 주소는 네트워크 어댑터(LAN 카드) 마다 할당된다.
만약 컴퓨터에 두 개의 네트워크 어댑터가 장착되어 있다면, 두 개의 IP 주소를 할당받을 수 있다.
자동으로 IP주소 받기가 설정되어 있다면 Switch또는 Hub가 할당해 주는 IP주소를 사용하는 것이고, 사용자가 직접 설정할 수도 있다.
IP는 3자리의 부호 없는 0~255 사이의 정수가 4자리로 구성되어 있다. (xxx.xxx.xxx.xxx)
IP 주소는 아래의 두 가지로 나뉜다.
내부 IP : 같은 LAN에서 컴퓨터를 식별하기 위한 고유 번호
외부 IP : WAN에서 컴퓨터를 식별하기 위한 고유 번호
내부 IP로 네트워킹을 하려면 같은 LAN에 있어야 하고, 한정된 공간이 아닌 광범위한 인터넷이 가능한 지역에서 네트워킹을 하려면 외부 IP로 통신을 해야 한다.
네트워크 어댑터에서 내부 IP 주소를 확인하려면 윈도우에서 ipconfig 명령어를, 맥OS 에서는 ifconfig 명령어를 실행하면 된다.
외부 IP 주소를 확인하려면 윈도우 기준 CMD 창에서 아래의 명령어를 입력하면 된다.
외부 IP 확인하는 명령어 nslookup myip.opendns.com resolver1.opendns.com
MAC Address 명령프롬프트에서 ipconfig /all 을 입력하면 아래와 같이 물리적 주소를 확인할 수 있는데, 이것이 MAC Address이다. 맥 어드레스는 네트워크 어댑터마다 모두 고유한 값을 가지고 있다. 따라서 스위치는 해당 주소를 통해 컴퓨터를 구별하고, IP주소를 부여해 준다.
연결한 상대방 컴퓨터의 IP 주소를 모르면 프로그램들은 서로 통신할 수 없다.
우리가 모르면 114로 문의하듯이 프로그램은 DNS를 이용해서 컴퓨터의 IP 주소를 검색한다.
DNS DNS는 도메인 이름으로, IP를 등록하는 저장소이다. 대중에게 서비스를 제공하는 대부분의 컴퓨터는 도메인 이름과 IP를 DNS에 미리 등록해 놓는다. 또한 DNS도 하나의 서버이다.
DNS도 서버이므로 IP를 알아야 우리가 요청을 할 수 있는데, 이는 명령프롬프트에서 ipconfig /all 명령어로 알 수 있다. 그리고 DNS 서버의 IP 주소는 Switch가 제공한다.
DNS 서버 또한 사용자가 다른 서버로 변경할 수 있는데, 유효한 서버 주소여야 한다.
웹 브라우저는 웹 서버와 통신하는 클라이언트로, 사용자가 입력한 도메인 이름으로 DNS에서 IP 주소를 검색해 찾은 다음 웹 서버와 연결해서 웹 페이지를 받는다.
Port 번호
DNS를 통해 IP 주소를 알았다고 하더라도 포트 번호를 모르면 정상적으로 네트워킹을 할 수 없다.
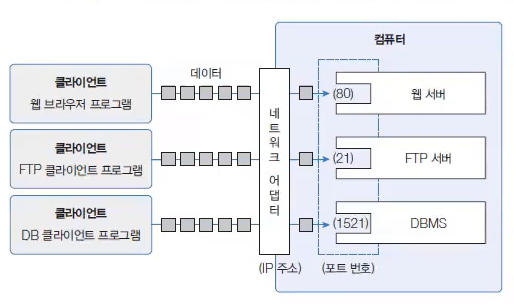
한 대의 컴퓨터에는 다양한 서버 프로그램들이 실행될 수 있다.
예를 들어 웹 서버, DBMS, FTP 서버 등이 하나의 IP 주소를 갖는 컴퓨터에서 동시에 실행될 수 있다.
이 경우 클라이언트는 어떤 서버와 통신해야 할지 결정해야 한다.
IP는 컴퓨터의 네트워크 어댑터까지만 갈 수 있는 정보이기 때문에, 컴퓨터 내부에서 실행하는 서버를 선택하기 위해서는 추가적인 Port 번호가 필요하다.
Port 번호 Port는 운영체제가 관리하는 서버 프로그램의 연결번호이다. 서버는 시작할 때 특정 Port 번호에 바인딩한다. 예를 들어 웹서버는 80번으로, DBMS는 1521(오라클 DBMS)번으로 바인딩할 수 있다. 따라서 클라이언트가 웹 서버와 통신하려면 80번으로, DBMS와 통신하려면 1521번으로 요청을 해야 한다. 출처 : 이것이 자바다 유튜브 동영상 강의
클라이언트가 서버의 IP 번호와 Port 번호까지 알아서 서버에 특정 작업을 요청을 했다면, 이제는 반대로 서버가 클라이언트의 IP 주소와 Port번호를 알아야 한다.
클라이언트의 Port 번호는 서버와 같이 고정적인 Port 번호에 바인딩하는 것이 아니라 운영체제가 자동으로 부여하는 번호를 사용하기 때문에 애초에 클라이언트가 서버에 요청을 할 때, 클라이언트의 IP 주소와 Port 번호를 같이 전송된다.
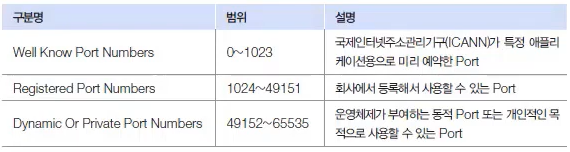
프로그램에서 사용할 수 있는 전체 Port 번호의 범위는 0~65535로, 아래와 같이 사용 목적에 따라 세 가지 범위를 가진다.
출처 : 이것이 자바다 유튜브 동영상 강의
Well Know Port Numbers : 특정 프로그램이 아니라 전 세계 사람들이 공통적으로 사용하는 포트 번호(고유함)
Registered Port Numbers : 특정 회사가 비용을 지불하여 고정적인 포트 번호를 사용(고유함)
Dynamic Or Private Port Numbers : 이 포트 번호는 동적 포트 번호이므로 수시로 바뀔 수 있고, 고유하지 못하다. 따라서 다른 서버와 포트가 겹칠 수 있고, 겹친다면 네트워킹을 할 수 없다.
IP 주소 얻기
자바는 IP 주소를 java.net 패키지의 InetAddress로 표현한다.
InetAddress를 이용하면 로컬 컴퓨터의 IP 주소를 얻을 수 있고, 도메인 이름으로 DNS에서 검색한 후 IP 주소를 가져올 수도 있다.
로컬 컴퓨터의 InetAddress를 얻고 싶다면 InetAddress.getLocalHost() 메소드를 호출하면 된다.
InetAddress ia = InetAddress.getLocalHost();
InetAddress의 객체를 통해 IP를 얻고 싶다면 아래와 같이 호출하면 된다.
리턴값은 문자열로 된 IP주소이다.
String ip = ia.getHostAddress();
만약 컴퓨터의 도메인 이름을 알고 있다면 아래 두 개의 메소드를 사용하여 InetAddress 객체를 얻을 수 있다.
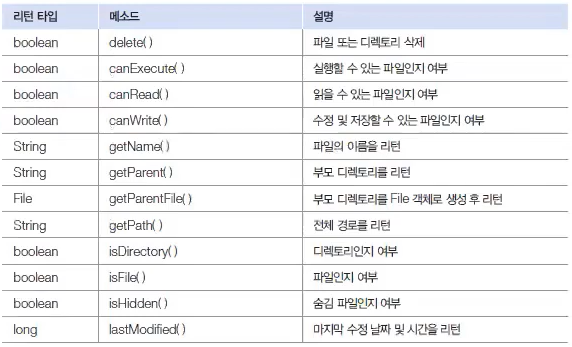
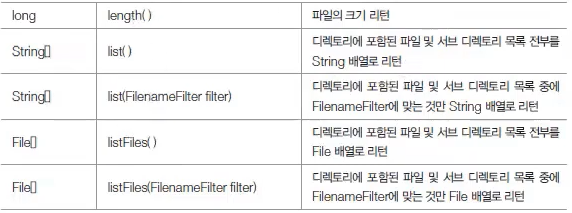
exists() 메소드가 false를 리턴할 경우, 아래 메소드로 파일 또는 폴더를 생성할 수 있다.
출처 : 이것이 자바다 유튜브 동영상 강의
mkdir()과 mkdirs()의 차이 mkdir()는 C:/dir/dir2 경로에 dir 폴더가 있으면 dir2를 생성시킨다. dir 폴더가 없으면 dir2를 생성시키지 못한다. mkdirs()는 C:/dir/dir2 경로에 없는 폴더를 모두 생성시킨다.
exists() 메소드의 리턴값이 true라면 아래 메소드를 사용할 수 있다.
출처 : 이것이 자바다 유튜브 동영상 강의
import java.io.File;
import java.text.SimpleDateFormat;
import java.util.Date;
public class FileExample {
public static void main(String[] args) throws Exception {
//File 객체 생성
File dir = new File("C:/Temp/images");
File file1 = new File("C:/Temp/file1.txt");
File file2 = new File("C:/Temp/file2.txt");
File file3 = new File("C:/Temp/file3.txt");
//존재하지 않으면 디렉토리 또는 파일 생성
if(dir.exists() == false) { dir.mkdirs(); }
if(file1.exists() == false) { file1.createNewFile(); }
if(file2.exists() == false) { file2.createNewFile(); }
if(file3.exists() == false) { file3.createNewFile(); }
//Temp 폴더의 내용을 출력
File temp = new File("C:/Temp");
File[] contents = temp.listFiles();
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd a HH:mm");
for(File file : contents) {
System.out.printf("%-25s", sdf.format(new Date(file.lastModified())));
if(file.isDirectory()) {
System.out.printf("%-10s%-20s", "<DIR>", file.getName());
} else {
System.out.printf("%-10s%-20s", file.length(), file.getName());
}
System.out.println();
}
}
}
/*
2023-07-31 오후 15:02 0 file1.txt
2023-07-31 오후 15:02 0 file2.txt
2023-07-31 오후 15:02 0 file3.txt
2023-07-31 오후 15:02 <DIR> images
2023-07-31 오전 03:14 201 object.dat
2023-07-31 오전 01:56 46 primitive.db
2023-07-31 오전 02:07 172 printstream.txt
2023-07-31 오전 01:29 42405 targetFile1.jpg
2023-07-31 오전 01:29 42405 targetFile2.jpg
2023-07-30 오후 14:47 42405 test.jpg
2023-07-31 오전 00:48 43 test.txt
2023-07-30 오후 13:51 3 test1.db
2023-07-30 오후 14:03 3 test2.db
2023-07-30 오후 15:00 42405 test2.jpg
*/
최근 수정한 날짜 얻기
new Date(file.lastModified())
위 코드에서 file.lastModified()는 long 타입 값을 리턴하는데, Date()는 이를 날짜로 만든다.
입출력 스트림을 생성할 때 File 객체 활용하기 파일 또는 폴더의 정보를 얻기 위해 File 객체를 단독으로 사용할 수 있지만, 파일 입출력 스트림을 생성할 때 경로 정보를 제공할 목적으로 사용되기도 한다.
//첫 번째 방법
FileInputStream fis = new FileInputStream("C://temp/image.gif");
//두 번째 방법
File file = new File("C://temp/image.gif");
FileInputStream fis = new FileInputStream(file);
Files 클래스
Files 클래스는 정적 메소드로 구성되어 있기 때문에 File 클래스처럼 객체를 만들 필요가 없다.
Files의 정적 메소드는 운영체제의 파일 시스템에게 파일 작업을 수행하도록 위임한다.
출처 : 이것이 자바다 유튜브 동영상 강의
이 메소드들은 매개값으로 Path 객체를 받는다.
Path 객체는 파일이나 디렉토리를 찾기 위한 경로 정보를 가지고 있는데, 정적 메소드인 get() 메소드로 아래와 같이 얻을 수 있다.
Path path = Path.get(String first, String...more)
get() 메소드의 매개값은 파일 경로인데, 전체 경로를 한꺼번에 지정해도 되고, 상위 디렉토리와 하위 디렉토리를 나열해서 지정해도 된다.
이 글은 누구나 자료 구조와 알고리즘(저자 : 제이 웬그로우)의 내용을 개인적으로 정리하는 글임을 알립니다.
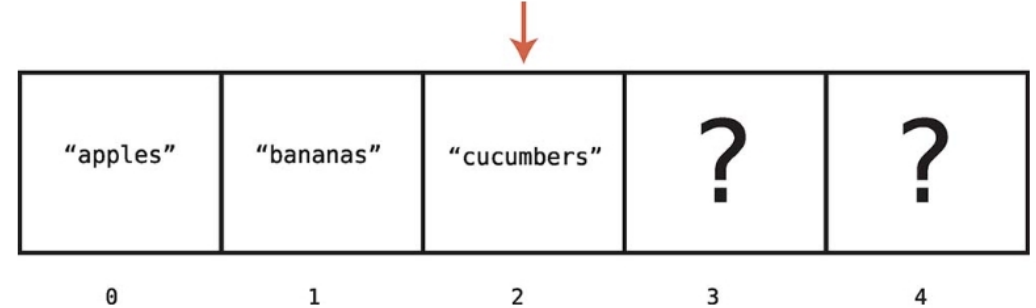
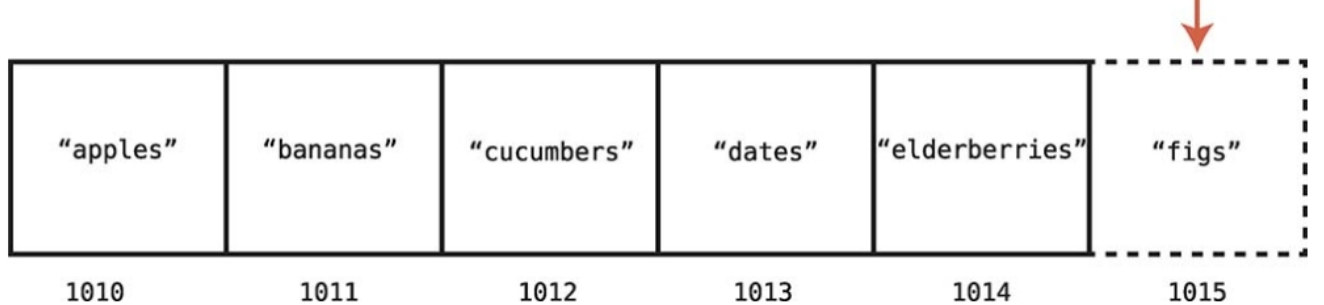
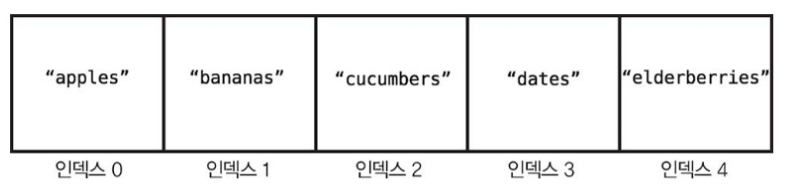
배열의 크기와 인덱스
배열의 크기 : 배열에 데이터 원소가 얼마나 들어있는지를 나타낸다. 위 그림에서 배열의 크기는 5이다.
배열의 인덱스 : 특정 데이터가 배열의 어디에 있는지 알려주는 숫자다.
자료구조 연산
대부분의 자료 구조는 네 가지 기본 방법을 사용하며 이를 연산이라 부른다.
연산은 아래와 같다.
읽기
검색
삽입
삭제
연산의 속도 측정
연산이 얼마나 '빠른가'를 측정 할 때는 순수하게 시간 관점에서 연산이 빠른가가 아니라,
얼마나 많은 단계가 필요한지를 논해야 한다.
왜 코드의 속도를 시간으로 측정하지 않을까? 누구도 어떤 연산이, 정확히 몇초가 걸린다고 단정할 수 없기 때문이다. 같은 연산도 어떤 컴퓨터에서는 1초가 걸리고, 구형 하드웨어에서는 더 오래걸릴 수 있기 때문이다. 슈퍼 컴퓨터는 훨씬 빠를 수도 있다. 시간은 실행하는 하듸웨어에 따라 항상 바뀌므로 시간을 기준으로 속도를 측정하면 신뢰할 수 없다.
연산의 속도를 측정할 때 얼마나 많은 단계(step)가 필요한가를 따져볼 수 있다.
같은 작업을 처리하는데, A 알고리즘은 5단계가 필요하고, B 알고리즘은 500단계가 필요하면, 모든 하드웨어에서 연산 A가 연산 B보다 항상 빠를 거라고 가정할 수 있다.
결국 단계 수 측정이 연산 속도를 분석하는 핵심 비결이다.
읽기
읽기는 배열 내 특정 인덱스에 어떤 값이 들어있는지 찾아보는 것이다.
컴퓨터는 딱 한 단계로 배열에서 읽을 수 있다.
위 배열에서 인덱스 2를 찾아본다면 컴퓨터는 인덱스 2로가서 cucumbers라는 값이 있다고 알려줄 것이다.
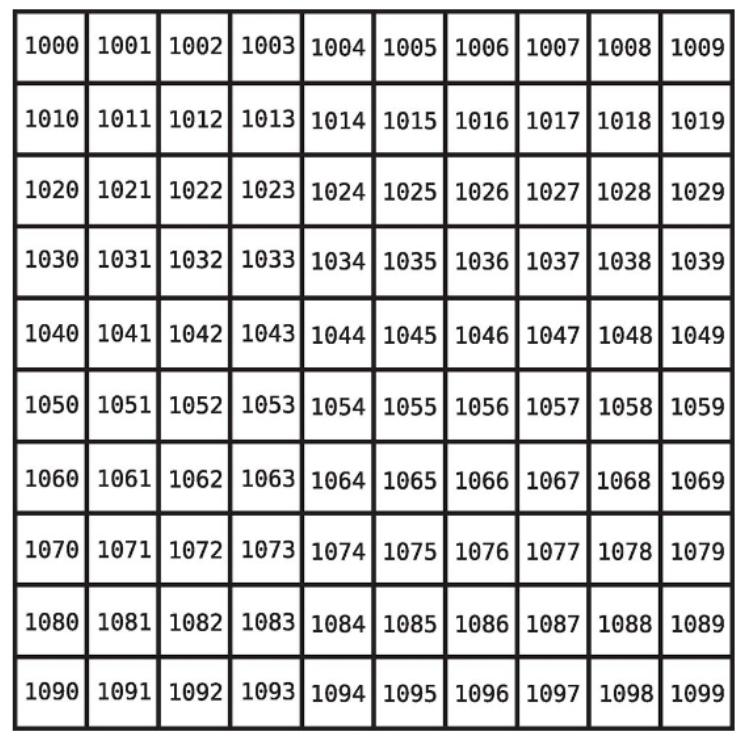
컴퓨터의 메모리는 어떻게 단 한 단계로 배열의 인덱스를 찾아볼 수 있는가? 컴퓨터의 메모리는 셀로 구성된 거대한 컬렉션이라 할 수 있다. 어떤 셀은 비어 있고, 어떤 셀에는 데이터가 들어있다. 예를 들어 원소 다섯 개를 넣을 배열을 생성하면 컴퓨터는 한 줄에서 5개의 빈 셀 그룹을 찾아 사용자가 사용할 배열로 지정한다. 컴퓨터 메모리 내에 각 셀에는 특정 주소가 있다. 각 셀의 메모리 주소는 앞 셀의 주소에서 1씩 증가한다. -컴퓨터는 모든 메모리 주소에 한 번에 갈 수있다.(특정 메모리의 값을 조사 요청을 받으면 검색 과정 없이 바로 간다) -컴퓨터는 배열을 할당할 때 어떤 메모리 주소에서 시작하는지도 기록해 둔다. 위와 같은 점들이 컴퓨터가 배열의 첫 번째 값을 어떻게 한 번에 찾아내는지 설명한다.
컴퓨터에 인덱스 3에 있는 값을 읽으라고 명령하면 컴퓨터는 아래와 같은 과정을 밟는다. 1. 배열의 인덱스는 0부터 시작하며 인덱스 0의 메모리 주소는 1010이다. 2. 인덱스 3은 인덱스 0부터 정확히 세 슬롯 뒤에 있다. 3. 따라서 인덱스 3을 찾으려면 1010 + 3인 1013 메모리 주소로 간다.
인덱스 3의 메모리 주소가 1013임을 알아낸 컴퓨터는 바로 접근해서 "dates"라는 값을 찾을 수 있다.
검색
검색은 배열에 특정 값이 있는지 알아본 후, 있다면 어떤 인덱스에 있는지 찾는 것이다.
읽기는 컴퓨터에 인덱스를 제공하고 그 인덱스에 들어있는 값을 반환하라고 요청
검색은 컴퓨터에 값을 제공하고 그 값이 들어 있는 인덱스를 반환하라고 요청
읽기와 검색은 비슷해 보이지만 효율성 측면에서 매우 큰 차이를 보인다.
검색은 컴퓨터가 특정 값으로 바로 갈 수 없으니 오래 걸린다.
왜냐하면, 컴퓨터는 모든 메모리 주소에 한 번에 접근하지만 각 메모리 주소에 어떤 값이 있는지 바로 알지 못하기 때문이다.
배열에서 어떤 원소를 찾으려면 컴퓨터는 각 셀을 한 번에 하나씩 조사하는 방법밖에 없다.
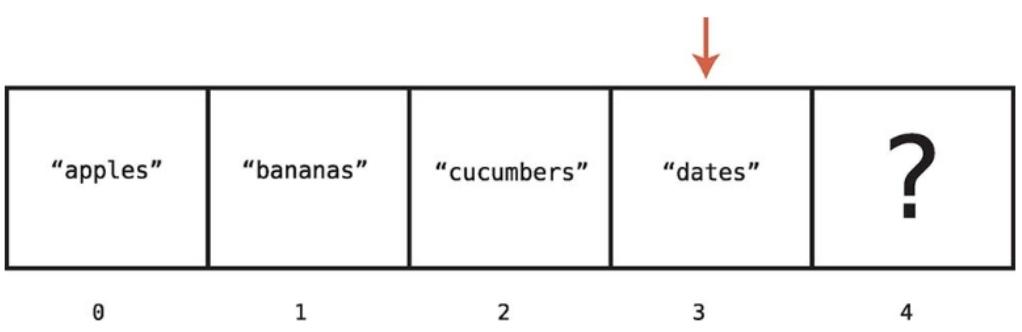
아래의 그림은 'dates'를 찾는 과정이다.
dates를 찾았고, 인덱스 3에 있음을 알았다.
찾고 있던 값을 발견했으니 컴퓨터는 배열의 다음 셀로 이동해서 검색할 필요가 없다.
컴퓨터는 찾으려던 값을 발견할 때까지 4개의 셀을 확인하므로 이 연산에는 총 4단계가 걸렸다고 할 수 있다.
컴퓨터가 한 번에 한 셀씩 확인하는 방법을 선형 검색이라고 부른다.
N칸의 배열에서의 선형 검색을 수행하는데 필요한 최대 단계수는 N개이다.
크기가 5인 배열에서 선형 검색을 수행하는데 필요한 최대 단계수는 5개
크기가 100인 배열에서 선형 검색을 수행하는데 필요한 최대 단계수는 100개
삽입
배열에 새 데이터를 삽입하는 연산은 배열의 어디에 데이터를 삽입하는가에 따라 효율성이 다르다.
맨 끝에 데이터 삽입
배열의 맨 끝에 데이터를 추가하는 것은 딱 한 단계만 필요하다.
문제점 하나 애초에 컴퓨터는 배열에 5개의 메모리 셀을 할당했고 6번째 원소를 추가하려면 이 배열에 셀을 추가로 할당해야 할 수 있다.
많은 프로그래밍 언어가 내부에서 자동으로 처리하지만 언어마다 방식이 다르다.
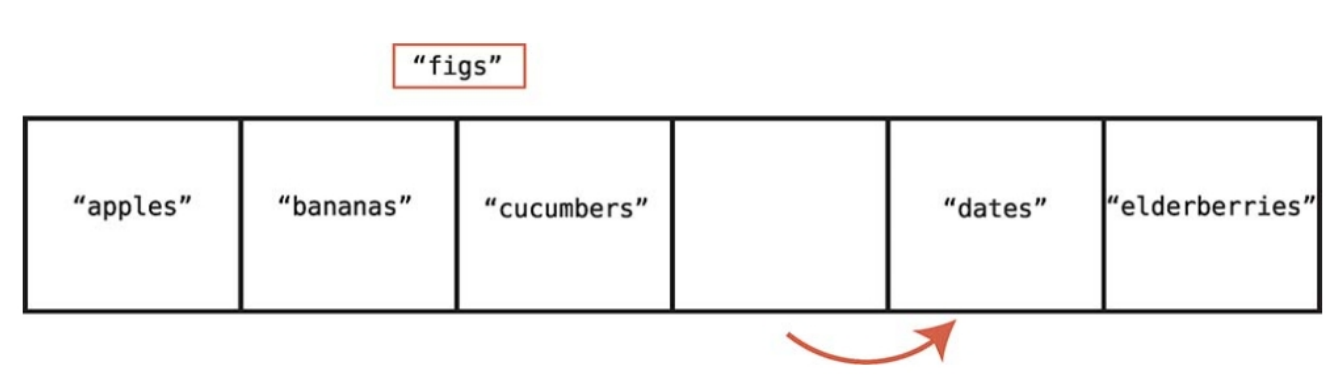
중간에 삽입
데이터를 중간에 삽입하면 삽입할 공간을 만들기 위해 많은 데이터 조각을 이동시켜야 하므로 단계가 늘어난다.
1단계2단계3단계4단계
"figs" 가 들어가려는 자리 뒤에 3개가 있었고, 마지막에 데이터를 삽입하는 단계 1을 합해서 4단계가 걸렸다(3+1)
맨앞에 삽입
배열 삽입에서 최악의 시나리오, 즉 삽입에 가장 많은 단계가 걸리는 시나리오는 데이터를 배열의 맨 앞에 삽입할 때다.
배열의 앞에 삽입하면 배열 내 모든 값을 한 셀씩 오른쪽으로 옮겨야 하기 때문이다.
N개의 원소를 포함하는 배열에서 최악의 시나리오일 때 삽입에는 N+1단계가 걸린다.
N개의 모든 원소를 뒤로 밀어버린다.
데이터를 맨 앞에 삽입한다.
삭제
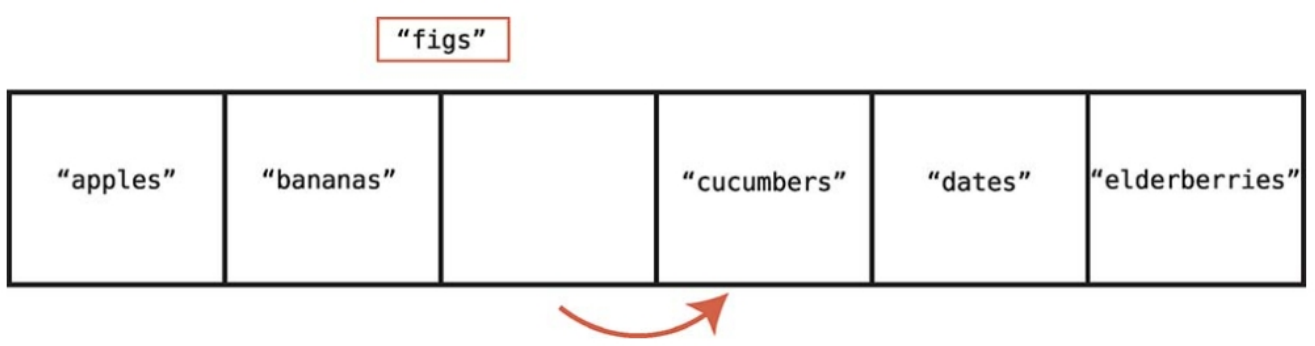
삭제는 특정 인덱스의 값을 제거하는 과정이다.
인덱스 2의 값을 삭제해보자.
원소 삭제에서 최악의 시나리오는 배열의 첫 번째 원소를 삭제하는 것이다.
원소 5개를 포함하는 배열이면 1단계는 첫 번째 원소 삭제에, 4단계는 남아 있는 원소 4개를 이동하는데 쓰인다.
따라서 원소 N개를 가지는 배열에서 삭제에 필요한 최대 단계 수는 N단계라고 할 수 있다.
집합 배열
집합은 중복 값을 허용하지 않는 자료구조다.
집합의 종류는 다양하지만 여기서는 배열 기반 집합을 다룬다.
일반 배열과 집합 배열의 차이점은 집합은 중복 값의 삽입을 절대 허용하지 않는다는 점이다.
예를 들어 ["a", "b", "c"]라는 집합에 b를 추가하려고 하면 b가 이미 있으므로 삽입을 허용하지 않는다.
집합 배열의 읽기 : 컴퓨터는 특정 인덱스에 들어 있는 값을 한 단계 만에 찾는다.
집합 배열의 검색 : 집합에서 어떤 값을 찾는 데 최대 N단계가 걸린다.
집합 배열의 삭제 : 집합에서 어떤 값을 삭제하고 배열을 옮겨 빈공간을 메꾸는 데 최대 N단계가 걸린다.
이렇게 집합과 집합 배열은 읽기, 검색, 삭제는 모두 동일한 단계 수를 가진다.
하지만 삽입만큼은 배열과 배열 집합은 다르다.
배열에서 최선의 시나리오였던 맨 끝에 삽입하는 경우 한 단계만에 값을 끝에 삽입했다.
하지만 집합 배열에서는 먼저 이 값이 이미 집합에 들어 있는지 결정해야 한다.
중복 데이터를 막는 게 집합의 역할이기 때문이다.
중복 데이터 삽입을 막기위해 삽입하려는 값이 집합에 이미 있는지부터 먼저 검색해야 한다.
집합에 새 값이 없을 때에만 컴퓨터는 삽입을 허용한다.
따라서 모든 삽입에는 검색이 우선이다.
모든 원소를 검색해야하므로 N단계가 소요되고, 삽입까지 총 N+1 단계가 소요된다.
값을 집합의 맨 앞에 삽입하는 최악의 시나리오일 때 컴퓨터는 셀 N개를 검색해서 집합이 그 값을 포함하지 않음을 확인한 후, 또 다른 N단계로 모든 데이터를 오른쪽으로 옮겨야 하며, 마지막 단계에서 새 값을 삽입해야한다.
이 게시글은 이것이 자바다(저자 : 신용권, 임경균)의 책과 동영상 강의를 참고하여 개인적으로 정리하는 글임을 알립니다.
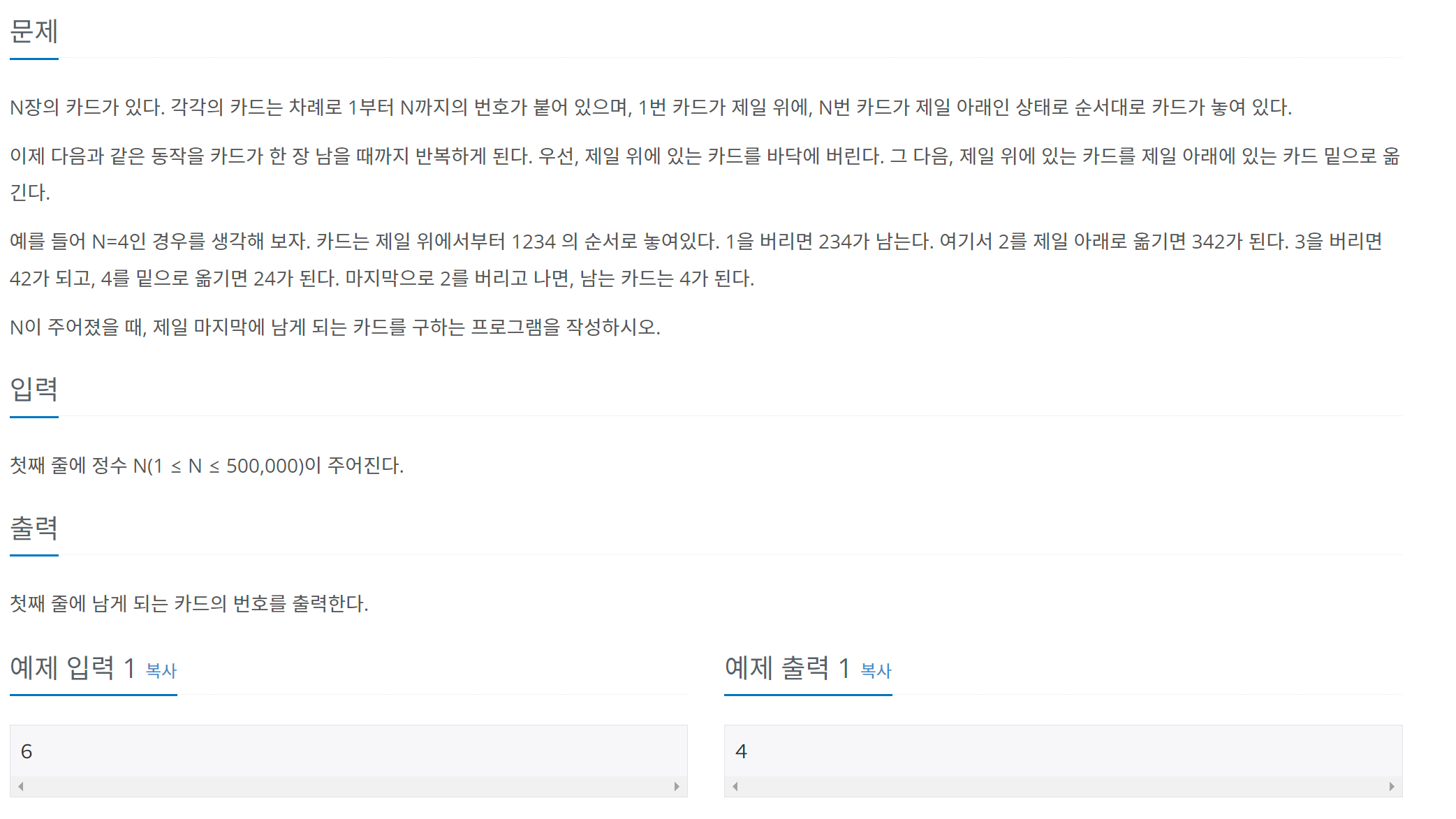
보조 스트림이란 다른 스트림과 연결되어 여러 가지 편리한 기능을 제공해 주는 스트림을 말한다.
보조 스트림은 자체적으로 입출력을 수행할 수 없기 때문에 입출력 소스로부터 직접 생성된 입출력 스트림에 연결해서 사용해야 한다.
출처 : 이것이 자바다 유튜브 동영상 강의
입출력 스트림에 보조 스트림을 연결하려면 보조 스트림을 생성할 때 생성자 매개값으로 입출력 스트림을 제공하면 된다.
보조스트림 변수 = new 보조스트림(입출력스트림);
InputStream is = new FileInputStream("...");
Reader reader = new InputStreamReader(is);
보조 스트림은 또 다른 보조 스트림과 연결되어 스트림 체인으로 구성할 수 있다.
출처 : 이것이 자바다 유튜브 동영상 강의
InputStream is = new FileInputStream("...");
Reader reader = new InputStreamReader(is);
BufferedReader br = new BufferedReader(reader);
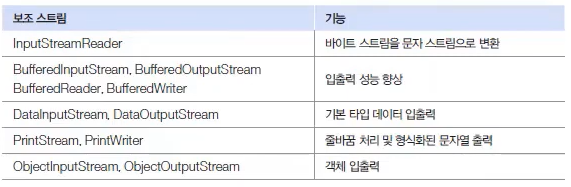
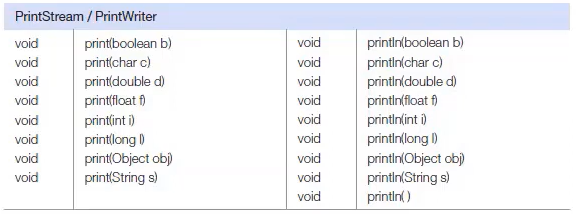
자주 사용되는 보조 스트림은 아래와 같다.
출처 : 이것이 자바다 유튜브 동영상 강의
보조 스트림을 닫으면 자동적으로 주 스트림도 닫힌다.
문자 변환 스트림
바이트 스트림(InputStream, OutputStream)에서 입출력할 데이터가 문자라면 문자 스트림(Reader, Writer)로 변환해서 사용하는 것이 좋다.
문자로 바로 입출력하는 편리함이 있고, 문자셋의 종류를 지정할 수 있기 때문이다.
InputStream을 Reader로 변환
InputStream을 Reader로 변환하려면 InputStreamReader 보조 스트림을 연결하면 된다.
출처 : 이것이 자바다 유튜브 동영상 강의
FileReader의 원리 FileInputStream에 InputStreamReader를 연결하지 않고 FileReader를 직접 생성할 수 있다. FileReader는 InputStreamReader의 자식 클래스이다. 이것은 FileReader가 내부적으로 FileInputStream에 InputStreamReader 보조 스트림을 연결한 것이라고 볼 수 있다.
아래는 InputStream을 Reader로 변환하는 코드를 나타낸다.
InputStream is = new FileInputStream("C:/Temp/test.txt");
Reader reader = new InputStreamReader(is);
보통 성능 향상 스트림인 BufferedReader을 추가적으로 장착하여 더 편리하게 문자열을 읽는다.
OutputStream을 Writer로 변환
OutputStream을 Writer로 변환하려면 OutputStreamWriter 보조 스트림을 연결하면 된다.
출처 : 이것이 자바다 유튜브 동영상 강의
OutputStream os = new FileOutputStream("C:/Temp/test.txt");
Writer writer = new OutputStreamWriter(os);
FileWriter의 원리 FileOutputStream에 OutputStreamWriter를 연결하지 않고 FileWriter를 직접 생성할 수 있다. FileWriter는 OutputStreamWriter의 자식 클래스이다. 이것은 FileWriter가 내부적으로 FileOutputStream에 OutputStreamWriter 보조 스트림을 연결한 것이라고 볼 수 있다.
사용 예제
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.io.OutputStream;
import java.io.OutputStreamWriter;
import java.io.Reader;
import java.io.Writer;
public class CharacterConvertStreamExample {
public static void main(String[] args) throws Exception {
write("문자 변환 스트림을 사용합니다.");
String data = read();
System.out.println(data);
}
public static void write(String str) throws Exception {
OutputStream os = new FileOutputStream("C:/Temp/test.txt");
Writer writer = new OutputStreamWriter(os, "UTF-8"); //인코딩 문자셋 지정
writer.write(str);
writer.flush();
writer.close();
}
public static String read() throws Exception {
InputStream is = new FileInputStream("C:/Temp/test.txt");
Reader reader = new InputStreamReader(is, "UTF-8"); //디코딩 문자셋 지정
char[] data = new char[100];
int num = reader.read(data);
reader.close();
String str = new String(data, 0, num);
return str;
}
}
/*
문자 변환 스트림을 사용합니다.
*/
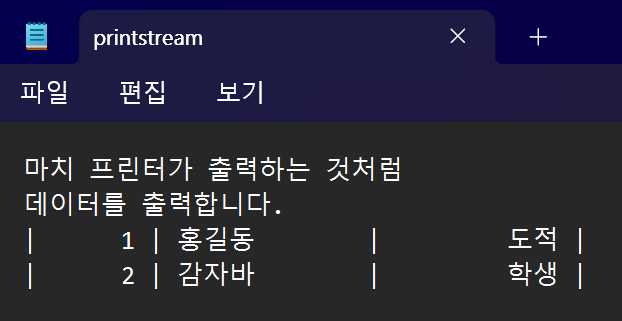
정상적으로 파일이 작성된 것을 볼 수 있다.
성능 향상 스트림
프로그램이 입출력 소스와 직접 작업하지 않고 중간에 메모리 버퍼와 작업함으로써 실행 성능을 향상시킬 수 있다.
출력 스트림의 경우 직접 하드 디스크에 데이터를 보내지 않고 메모리 버퍼에 데이터를 보냄으로써 출력 속도를 향상 시킬 수 있다.
버퍼는 데이터가 쌓이기를 기다렸다가 꽉 차게 되면 데이터를 한꺼번에 하드 디스크로 보냄으로써 출력 횟수를 줄여준다.
BufferedInputStream bis = new BufferedInputStream(바이트 입력 스트림);
BufferedOutputStream bos = new BufferedOutputStream(바이트 출력 스트림);
////////////////////////
BufferedReader br = new BufferedReader(문자 입력 스트림);
BufferedWriter bw = new BufferedWriter(문자 출력 스트림);
BufferedRead 버퍼의 사이즈가 Scanner가 1024 char인데 비해, BufferedReader는 8192 char이기 때문에 입력이 많을 때 BufferedReader가 유리하다. 또한 BufferedReader는 동기화 되기 때문에 멀티 쓰레드 환경에서 안전하고, Scanner는 동기화가 되지 않기 때문에 멀티 쓰레드 환경에서 안전하지 않다.
아래의 더보기를 누르면 성능 향상 보조 스트림을 사용하지 않았을 때와 했을 때의 파일 복사 성능 차이 예제를 볼 수 있다.
public class BufferExample {
public static void main(String[] args) throws Exception {
//입출력 스트림 생성
String originalFilePath1 = BufferExample.class.getResource("originalFile1.jpg").getPath();
String targetFilePath1 = "C:/Temp/targetFile1.jpg";
FileInputStream fis = new FileInputStream(originalFilePath1);
FileOutputStream fos = new FileOutputStream(targetFilePath1);
//입출력 스트림 + 버퍼 스트림 생성
String originalFilePath2 = BufferExample.class.getResource("originalFile2.jpg").getPath();
String targetFilePath2 = "C:/Temp/targetFile2.jpg";
FileInputStream fis2 = new FileInputStream(originalFilePath2);
FileOutputStream fos2 = new FileOutputStream(targetFilePath2);
BufferedInputStream bis = new BufferedInputStream(fis2);
BufferedOutputStream bos = new BufferedOutputStream(fos2);
//버퍼를 사용하지 않고 복사
long nonBufferTime = copy(fis, fos);
System.out.println("버퍼 미사용:\t" + nonBufferTime + " ns");
//버퍼를 사용하고 복사
long bufferTime = copy(bis, bos);
System.out.println("버퍼 사용:\t" + bufferTime + " ns");
fis.close();
fos.close();
bis.close();
bos.close();
}
public static long copy(InputStream is, OutputStream os) throws Exception {
//시작 시간 저장
long start = System.nanoTime();
//1 바이트를 읽고 1 바이트를 출력
while(true) {
int data = is.read();
if(data == -1) break;
os.write(data);
}
os.flush();
//끝 시간 저장
long end = System.nanoTime();
//복사 시간 리턴
return (end-start);
}
/*
버퍼 미사용: 102628400 ns
버퍼 사용: 1826600 ns
*/
}
문자 입력 스트림 Reader에 BufferedReader를 연결하면 성능 향상뿐만 아니라 행 단위로 문자열을 읽는 매우 편리한 readLine() 메소드를 제공한다.
import java.io.*;
public class ReadLineExample {
public static void main(String[] args) throws Exception {
BufferedReader br = new BufferedReader(
new FileReader("src/ch18/sec07/exam02/ReadLineExample.java")
);
int lineNo = 1;
while(true) {
String str = br.readLine();
if(str == null) break;
System.out.println(lineNo + "\t" + str);
lineNo++;
}
br.close();
}
}
//출력 내용
/*
1 package ch18.sec07.exam02;
2
3 import java.io.*;
4
5 public class ReadLineExample {
6 public static void main(String[] args) throws Exception {
7 BufferedReader br = new BufferedReader(
8 new FileReader("src/ch18/sec07/exam02/ReadLineExample.java")
9 );
10
11 int lineNo = 1;
12 while(true) {
13 String str = br.readLine();
14 if(str == null) break;
15 System.out.println(lineNo + "\t" + str);
16 lineNo++;
17 }
18
19 br.close();
20 }
21 }
*/
BufferedReader는 파일을 다 읽었다면 null을 리턴한다.
기본 타입 스트림
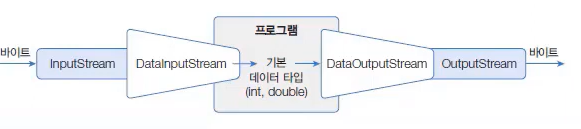
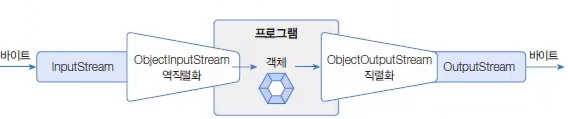
바이트 스트림에 DataInputStream과 DataOutputStream 보조 스트림을 연결하면 기본 타입 값을 입출력할 수 있다.
출처 : 이것이 자바다 유튜브 동영상 강의
DataInputStream dis = new DataInputStream(바이트 입력 스트림);
DataOutputStream dos = new DataOutputStream(바이트 출력 스트림);
아래는 DataInputStream과 DataOutputStream이 제공하는 메소드이다.
출처 : 이것이 자바다 유튜브 동영상 강의
주의 사항 데이터 타입의 크기가 모두 다르므로 DataOutputStream으로 출력한 데이터를 다시 DataInputStream으로 읽어 올 때에는 출력한 순서와 동일한 순서로 읽어야 한다. 출력할 때 순서가 int -> boolean -> double이라면 읽을 때의 순서도 동일해야 한다.