이 알고리즘 문제는 인프런의 자바(Java) 알고리즘 문제풀이 입문: 코딩테스트 대비 (김태원)의 문제입니다.
문제 설명
코드
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.HashMap;
public class sec04_04 {
public static int solution(String S, String T) {
int count = 0;
HashMap<Character, Integer> sMap = new HashMap<>();
HashMap<Character, Integer> tMap = new HashMap<>();
for (char c : T.toCharArray()) tMap.put(c, tMap.getOrDefault(c, 0) + 1); //T를 관리하는 맵 초기화
for (int i = 0; i < T.length() - 1; ++i) sMap.put(S.charAt(i), sMap.getOrDefault(S.charAt(i), 0) + 1); //S를 관리하는 맵 초기화
int lPtr = 0;
for (int rPtr = T.length() - 1; rPtr < S.length(); ++rPtr)
{
sMap.put(S.charAt(rPtr), sMap.getOrDefault(S.charAt(rPtr), 0) + 1);
if (sMap.equals(tMap)) ++count;
sMap.put(S.charAt(lPtr), sMap.get(S.charAt(lPtr)) - 1);
if (sMap.get(S.charAt(lPtr)) == 0) sMap.remove(S.charAt(lPtr));
++lPtr;
}
return count;
}
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
String S = br.readLine();
String T = br.readLine();
System.out.println(solution(S, T));
}
}
설명
해시맵 초기화 -> tMap: 문자열 T의 각 문자 빈도수를 저장. -> sMap: 초기 슬라이딩 윈도우에 해당하는 S의 첫 T.length() - 1 만큼의 문자 빈도수를 저장.
슬라이딩 윈도우 설정 -> lPtr과 rPtr 두 개의 포인터를 사용하여 윈도우를 이동시키면서 S의 각 부분 문자열을 탐색한다. -> rPtr이 가리키는 문자를 sMap에 추가하고, lPtr이 가리키는 문자의 빈도수를 감소시키며 윈도우를 한 칸 오른쪽으로 이동한다. -> sMap과 tMap이 동일한지 비교하여, 같으면 애너그램이므로 count를 증가시킨다.
이 글은 인프런 김영한님의 Spring 강의를 바탕으로 개인적인 정리를 위해 작성한 글입니다.
경로 표현식
JPQL(Java Persistence Query Language)에서 경로 표현식(Path Expression)은 엔터티의 속성에 접근하거나 연관된 엔터티를 탐색하기 위해 사용된다. 이는 객체 그래프를 따라갈 수 있게 하며, 다양한 쿼리에서 데이터를 필터링하고 조회하는 데 중요한 역할을 한다.
쉽게 말하자면 .(점)을 찍어 객체 그래프를 탐색하는 것이다.
select m.username -> 상태 필드
from Member m
join m.team t -> 단일 값 연관 필드
join m.orders o -> 컬렉션 값 연관 필드
where t.name = '팀A'
경로 표현식 용어 정리
상태 필드(state field): 단순히 값을 저장하기 위한 필드 (ex: m.username)
연관 필드(association field): 연관관계를 위한 필드
단일 값 연관 필드 : @ManyToOne, @OneToOne, 대상이 엔티티(ex: m.team)
컬렉션 값 연관 필드: @OneToMany, @ManyToMany, 대상이 컬렉션(ex: m.orders)
경로 표현식의 특징
-상태 필드(state field)
경로 탐색의 끝, 객체 그래프 탐색 불가능
JPQL: select m.username, m.age from Member m
SQL: select m.username, m.age from Member m
-단일 값 연관 경로
묵시적 내부 조인(inner join) 발생, 객체 그래프 탐색 가능
JPQL: select o.member from Order o
SQL: select m.* from Orders o inner join Member m on o.member_id = m.id
-컬렉션 값 연관 경로
묵시적 내부 조인 발생, 객체 경로 탐색 불가능
FROM 절에서 명시적 조인을 통해 별칭을 얻으면 별칭을 통해 탐색 가능
명시적 조인, 묵시적 조인
명시적 조인: join 키워드 직접 사용 select m from Member m join m.team t
묵시적 조인: 경로 표현식에 의해 묵시적으로 SQL 조인 발생 (내부 조인만 가능) select m.team from Member m
경로 탐색을 사용한 묵시적 조인 시 주의사항 -항상 내부 조인이 일어난다. -컬렉션은 경로 탐색의 끝, 명시적 조인을 통해 별칭을 얻어야 한다. -경로 탐색은 주로 SELECT, WHERE 절에서 사용하지만 묵시적 조인으로 인해 SQL의 FROM (JOIN)절에 영향을 준다.
실무에서는 묵시적 조인을 지양하고 명시적 조인을 사용해야 한다.
경로 표현식 예시
select o.member.team from Order o -> 성공
select t.members from Team -> 성공
select t.members.username from Team t -> 실패
select m.username from Team t join t.members m -> 성공
FETCH JOIN
JPA에서의 Fetch Join은 여러 엔터티를 조인하면서 관련된 엔터티의 데이터도 함께 가져오는 방법이다.
이는 N+1 문제를 해결하기 위해 자주 사용된다.
Fetch Join을 사용하면 필요한 데이터를 한 번의 쿼리로 모두 가져올 수 있어 성능을 최적화할 수 있다.
엔티티 Fetch Join(Entity Fetch Join)과 컬렉션 Fetch Join(Collection Fetch Join)은 JPA에서 연관된 엔터티를 로딩하기 위해 사용되는 두 가지 페치 조인 방식이다. 이 두 방식은 사용하는 목적과 데이터 구조에 따라 차이점이 있다.
관계의 유형
엔티티 Fetch Join 조인은 주로 다대일(N:1) 또는 일대일(1:1) 관계에 사용된다.
컬렉션 Fetch Join 조인은 주로 일대다(1:N) 또는 다대다(N:M) 관계에 사용된다.
로딩되는 데이터의 구조
엔티티 Fetch Join은 단일 엔터티를 로드한다. 예를 들어, Member가 Team을 로드하는 경우, 각 Member는 하나의 Team 객체를 포함한다.
컬렉션 Fetch Join은 여러 개의 엔터티(컬렉션)를 로드한다. 예를 들어, Team이 여러 Member를 로드하는 경우, 각 Team 객체에는 여러 Member 객체가 포함된다.
데이터 중복 가능성
엔티티 Fetch Join은 데이터 중복 문제가 상대적으로 적다.
컬렉션 Fetch Join은 여러 행의 데이터베이스 결과가 동일한 부모 엔터티를 포함할 수 있어 중복된 데이터가 발생할 수 있다.
페이징 처리의 제약
컬렉션 Fetch Join은 페이징 처리(setFirstResult, setMaxResults)가 올바르게 작동하지 않을 수 있다. 이는 조인 결과의 크기가 예측 불가능하기 때문에, 데이터베이스 수준에서 정확한 페이징을 적용하기 어렵기 때문이다.
엔티티 FETCH JOIN
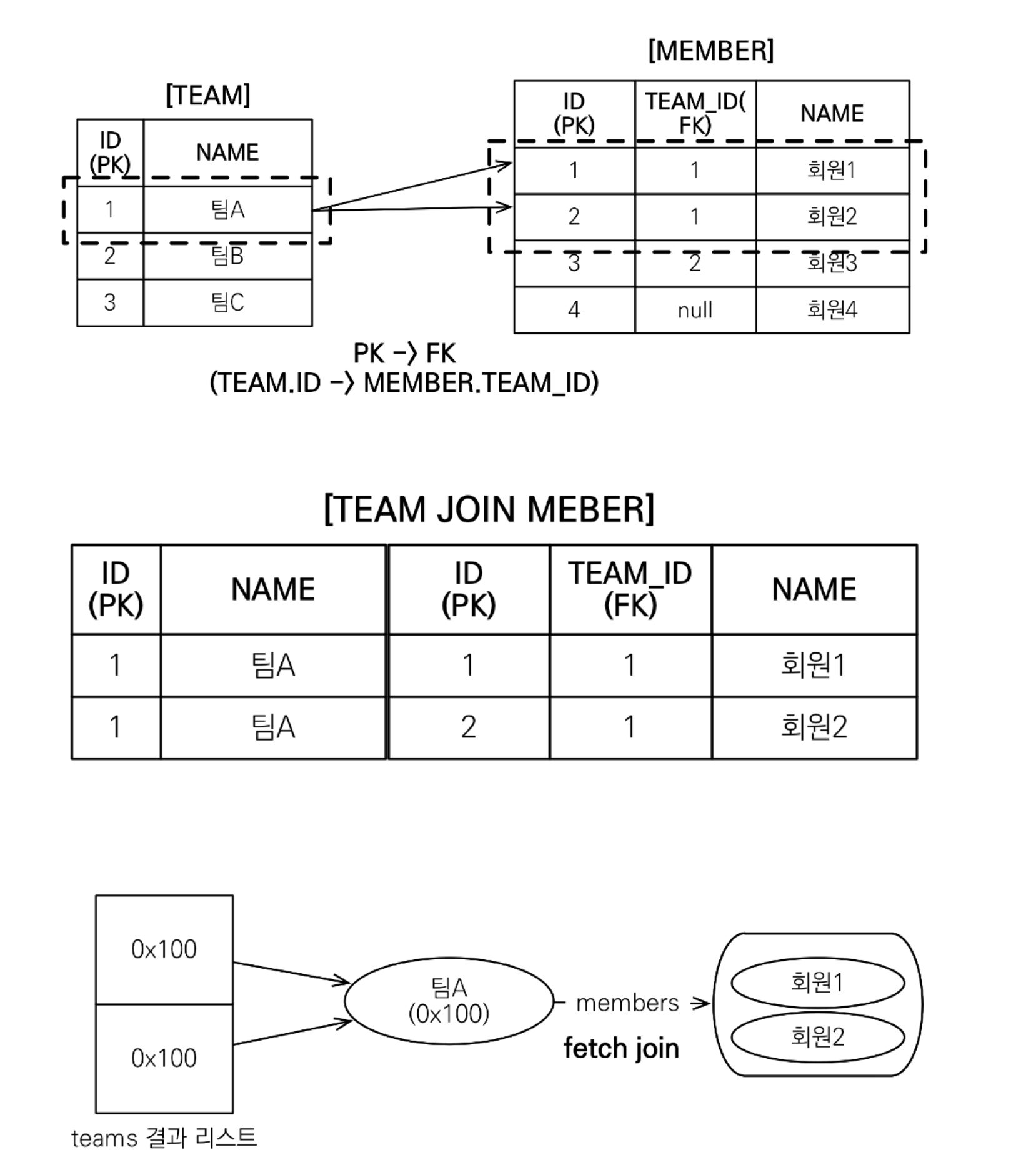
회원을 조회하면서 연관된 팀도 함께 조회(SQL 한 번에)
SQL을 보면 회원 뿐만 아니라 팀(T.*)도 함께 SELECT -[JPQL] select m from Member m join fetch m.team -[SQL]SELECT M.*, T.* FROM MEMBER M INNER JOIN TEAM T ON M.M.TEAM_ID=T.ID
Team teamA = new Team();
teamA.setName("teamA");
em.persist(teamA);
Team teamB = new Team();
teamB.setName("teamB");
em.persist(teamB);
Member member1 = new Member();
member1.setUsername("member1");
member1.setAge(10);
member1.setTeam(teamA);
em.persist(member1);
Member member2 = new Member();
member2.setUsername("member2");
member2.setAge(10);
member2.setTeam(teamA);
em.persist(member2);
Member member3 = new Member();
member3.setUsername("member3");
member3.setAge(10);
member3.setTeam(teamB);
em.persist(member3);
em.flush();
em.clear();
String jpql = "select m from Member m join fetch m.team"; //페치 조인으로 회원과 팀을 함께 조회해서 지연 로딩X
List<Member> members = em.createQuery(jpql, Member.class).getResultList();
for (Member m : members) {
System.out.println("username = " + m.getUsername() + ", " + "teamName = " + m.getTeam().getName());
}
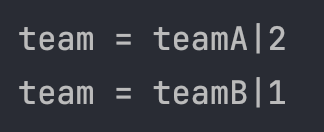
컬렉션 FETCH JOIN
일대다 관계에서 JOIN(FETCH JOIN도 마찬가지)을 사용하면 데이터 중복 문제가 발생한다.
[JPQL] select t from Team t join fetch t.members where t.name = ‘팀A'
[SQL] SELECT T.*, M.* FROM TEAM T INNER JOIN MEMBER M ON T.ID=M.TEAM_ID WHERE T.NAME = '팀A'
Team teamA = new Team();
teamA.setName("teamA");
em.persist(teamA);
Team teamB = new Team();
teamB.setName("teamB");
em.persist(teamB);
Member member1 = new Member();
member1.setUsername("member1");
member1.setAge(10);
member1.setTeam(teamA);
em.persist(member1);
Member member2 = new Member();
member2.setUsername("member2");
member2.setAge(10);
member2.setTeam(teamA);
em.persist(member2);
Member member3 = new Member();
member3.setUsername("member3");
member3.setAge(10);
member3.setTeam(teamB);
em.persist(member3);
em.flush();
em.clear();
String query = "select t from Team t join fetch t.members";
List<Team> result = em.createQuery(query, Team.class).getResultList();
for (Team team : result) {
System.out.println("team = " + team.getName() + "|" + team.getMembers().size());
}
String jpql = "select t from Team t join fetch t.members where t.name = 'teamA'";//페치 조인으로 팀과 회원을 함께 조회해서 지연 로딩 발생 안함
List<Team> teams = em.createQuery(jpql, Team.class).getResultList();
for(Team team : teams) {
System.out.println("teamname = " + team.getName() + ", team = " + team);
for (Member member : team.getMembers()) {
System.out.println("-> username = " + member.getUsername()+ ", member = " + member);
}
}
필자의 개발 환경에서는 데이터 중복 문제가 발생하지 않았다.(Member 엔티티 지연로딩 확인함)
아마 하이버네이트가 버전이 업되면서 데이터 중복 문제를 해결한 것으로 보인다.
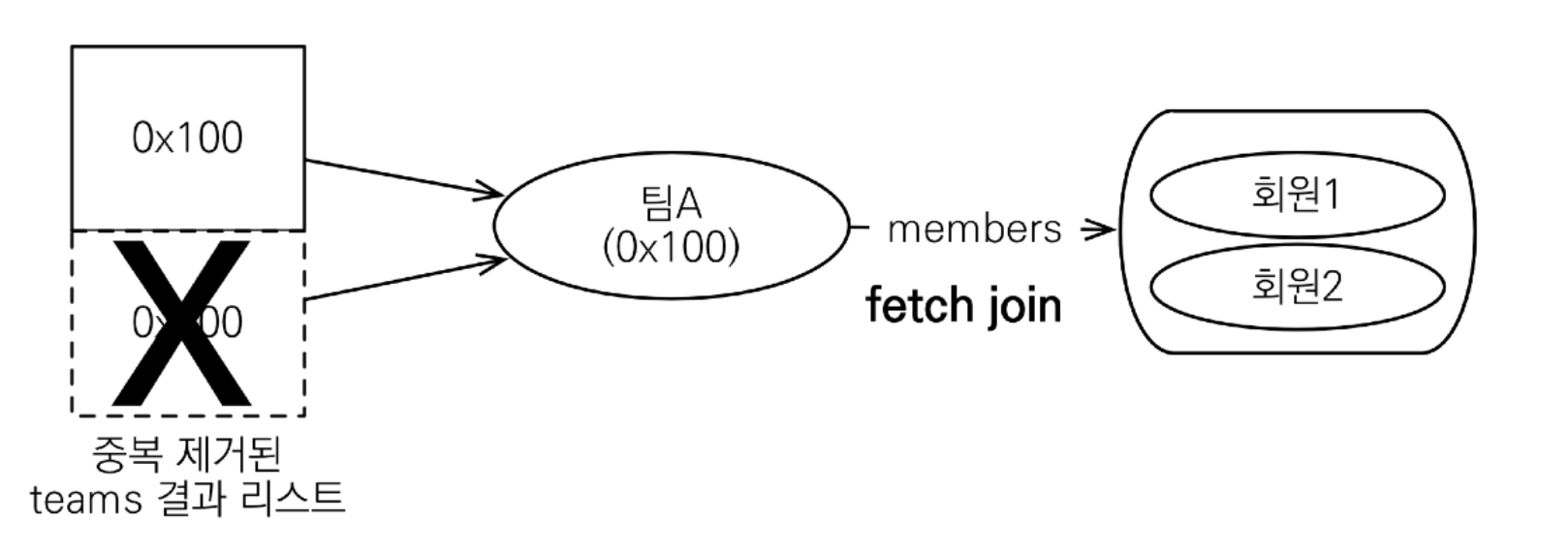
하이버네이트6 부터는 DISTINCT 명령어를 사용하지 않아도 애플리케이션에서 중복 제거가 자동으로 적용
어찌되었든간에 데이터 중복 문제를 해결하려면 DISTINCT를 사용해야 한다.
String query = "select distinct t from Team t join fetch t.members";
List<Team> result = em.createQuery(query, Team.class).getResultList();
DISTINCT가 추가로 애플리케이션에서 중복 제거시도를 하게되어서 같은 식별자를 가진 Team 엔티티 제거한다.
애플리케이션 레벨에서 중복제거 쿼리 실행 후 애플리케이션 레벨에서 중복된 엔터티를 제거할 수도 있다. 이는 Fetch Join을 사용하지 않고, 필요한 데이터를 가져온 후 Java 코드에서 중복을 필터링하는 방식이다. 예를 들어, Set 컬렉션을 사용하여 중복된 엔터티를 자동으로 제거할 수 있다.
List<Team> result = em.createQuery(query, Team.class).getResultList();
Set<Team> uniqueTeams = new HashSet<>(result);
JOIN 과 FETCH JOIN의 차이점
일반 조인 실행시 연관된 엔티티를 함께 조회하지 않음 [JPQL] select t from Team t join t.members m where t.name = ‘팀A' [SQL] SELECT T.* FROM TEAM T INNER JOIN MEMBER M ON T.ID=M.TEAM_ID WHERE T.NAME = '팀A'
JPQL은 결과를 반환할 때 연관관계 고려X 단지 SELECT 절에 지정한 엔티티만 조회할 뿐임 여기서는 팀 엔티티만 조회하고, 회원 엔티티는 조회X FETCH JOIN을 사용할 때만 연관된 엔티티도 함께 조회(즉시 로딩) FETCH JOIN은 객체 그래프를 SQL 한번에 조회하는 개념
FETCH JOIN의 특징과 한계
1. 페치 조인 대상에는 별칭을 줄 수 없다.
하이버네이트는 가능, 가급적 사용X
select t from Team t join t.members m where m.age > 10 //t.members에 별명 부여(m)
2. 둘 이상의 컬렉션은FETCH JOIN 할 수 없다.
3. 컬렉션을 FETCH JOIN하면 페이징 API(setFirstResult,setMaxResults)를 사용할 수 없다.
일대일, 다대일 같은 단일 값 연관 필드들은 페치 조인해도 페이징 가능
하이버네이트는 경고 로그를 남기고 메모리에서 페이징(매우 위험)
4. 연관된 엔티티들을 SQL 한 번으로 조회 - 성능 최적화
엔티티에 직접 적용하는 글로벌 로딩 전략보다 우선함
@OneToMany(fetch = FetchType.LAZY) //글로벌 로딩 전략
실무에서 글로벌 로딩 전략은 모두 지연 로딩
최적화가 필요한 곳은 페치 조인 적용
@BatchSize
@BatchSize는 JPA와 Hibernate에서 지연 로딩(Lazy Loading)을 최적화하기 위한 어노테이션이다. 이 어노테이션은 엔터티나 컬렉션 필드에 적용되어, 한 번에 로드할 데이터의 개수를 설정할 수 있다. 이를 통해 N+1 문제를 완화하고, 데이터베이스 접근 횟수를 줄여 성능을 향상시킬 수 있다.
1. 엔티티 클레스에 사용 엔터티 클래스에 @BatchSize를 적용하면, 해당 엔터티가 지연 로딩될 때 한 번에 로드할 엔터티의 개수를 지정할 수 있다.
@Entity
@BatchSize(size = 10)
public class Team {
@Id
@GeneratedValue
private Long id;
private String name;
@OneToMany(mappedBy = "team")
private List<Member> members = new ArrayList<>();
}
위 예제에서는 Team 엔터티에 @BatchSize(size = 10)을 적용하였다. 이는 Team 엔터티가 지연 로딩될 때, 한 번에 최대 10개의 Team 엔터티를 로드하라는 의미이다.
2. 컬렉션 필드에 사용 컬렉션 필드에 @BatchSize를 적용하면, 해당 컬렉션이 지연 로딩될 때 한 번에 로드할 엔터티의 개수를 설정할 수 있다.
@Entity
public class Team {
@Id
@GeneratedValue
private Long id;
private String name;
@OneToMany(mappedBy = "team")
@BatchSize(size = 5)
private List<Member> members = new ArrayList<>();
}
위 예제에서는 members 컬렉션 필드에 @BatchSize(size = 5)를 적용하였다. 이는 Team 엔터티의 members 컬렉션이 지연 로딩될 때, 한 번에 최대 5개의 Member 엔터티를 로드하라는 의미이다.
장점 지연 로딩 시 한 번에 여러 엔터티를 가져옴으로써 N+1 문제를 줄일 수 있다. 예를 들어, @BatchSize(size = 10)을 사용하면 최대 10개의 엔터티를 한 번의 쿼리로 가져온다. 필요한 경우 여러 엔터티를 한 번에 로드하여 데이터베이스 접근 횟수를 줄이고, 네트워크 트래픽을 줄일 수 있다.
단점 한 번에 많은 엔터티를 로드하면 메모리 사용량이 증가할 수 있다. 따라서 설정 값에 따라 메모리 사용을 신중히 고려해야 한다. 배치 크기를 너무 크게 설정하면 오버헤드가 증가할 수 있고, 너무 작게 설정하면 성능 향상을 기대하기 어려울 수 있다. 적절한 크기를 설정하는 것이 중요하다.
5. 모든 것을 페치 조인으로 해결할 수는 없음
페치 조인은 객체 그래프를 유지할 때 사용하면 효과적
여러 테이블을 조인해서 엔티티가 가진 모양이 아닌 전혀 다른 결과를 내야 하면, 페치 조인 보다는 일반 조인을 사용하고 필요한 데이터들만 조회해서 DTO로 반환하는 것이 효과적
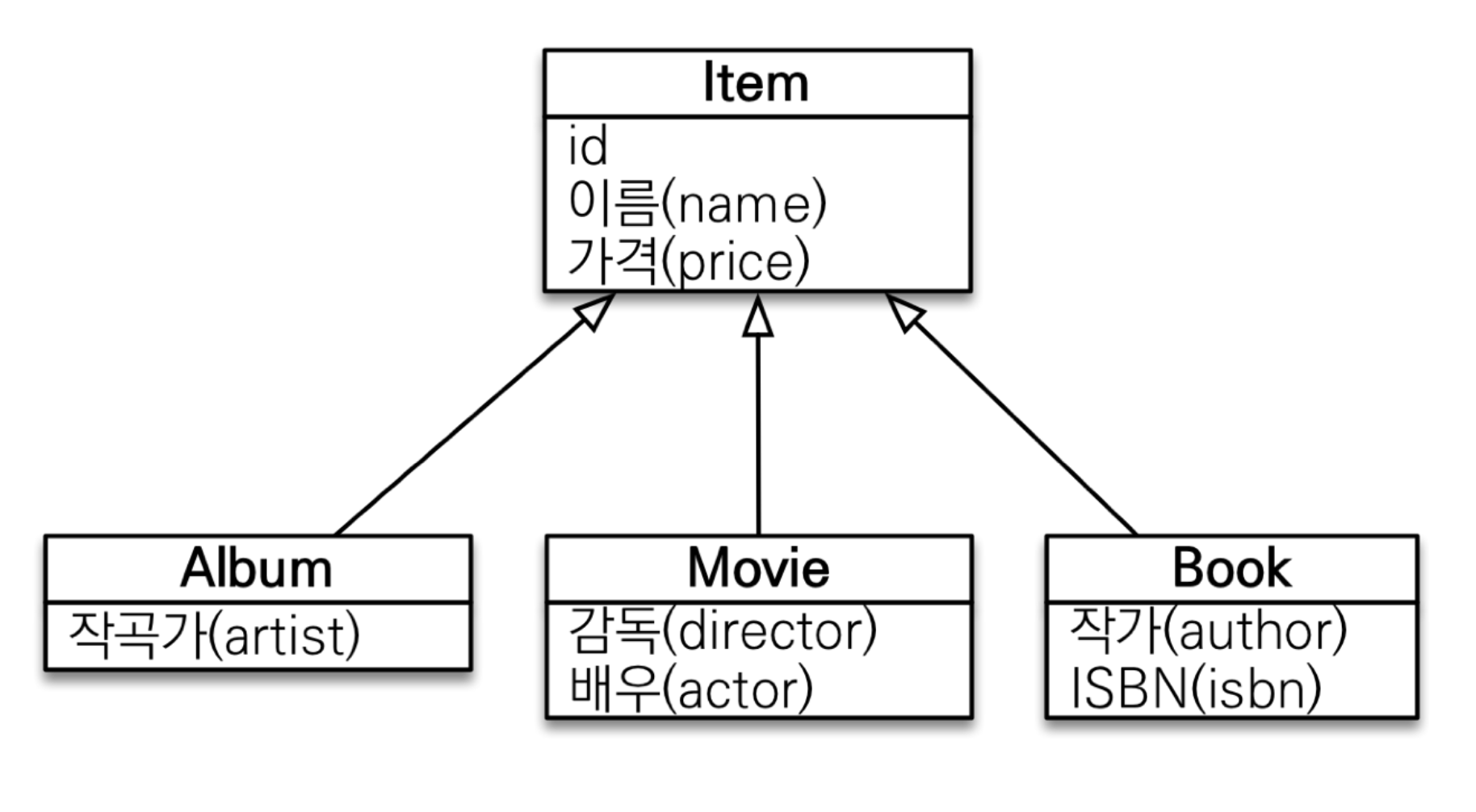
다형성 쿼리
TYPE
TYPE은 특정 엔티티 타입을 구분하는 데 사용되는 기능이다. 부모 클래스나 상위 클래스의 쿼리를 수행하면서 특정 하위 클래스나 서브타입만 필터링하고 싶을 때 사용된다.
예를 들어, 상속 계층에서 여러 서브타입이 있을 때, 특정 서브타입의 엔티티만 조회하고 싶을 때 유용하다.
->조회 대상을 특정 자식으로 한정
예) Item 중에 Book, Movie를 조회해라
[JPQL] select i from Item i where type(i) IN (Book, Movie)
[SQL] select i from i where i.DTYPE in (‘B’, ‘M’)
String jpql = "SELECT i FROM Item i WHERE TYPE(i) IN (Book, Movie)";
List<Item> items = em.createQuery(jpql, Item.class).getResultList();
TREAT
TREAT는 부모 클래스 타입을 하위 클래스 타입으로 변환할 때 사용된다. 이는 상속 관계에서 부모 타입으로 정의된 엔티티를 하위 타입으로 취급하여 하위 클래스에만 있는 속성에 접근하고자 할 때 유용하다.
TREAT를 사용하면 특정 서브타입의 필드나 메서드를 사용할 수 있다.
->자바의 타입 캐스팅과 유사
->상속 구조에서 부모 타입을 특정 자식 타입으로 다룰 때 사용
->FROM, WHERE, SELECT(하이버네이트 지원) 사용
예) Item 클래스를 상속받는 Book 클래스에서 author 필드가 “kim”인 데이터를 조회
[JPQL] select i from Item i where treat(i as Book).author = ‘kim’
[SQL] select i.* from Item i where i.DTYPE = ‘B’ and i.author = ‘kim’
상위 클래스 타입을 하위 클래스 타입으로 변환하고, 변환된 하위 클래스의 속성에 접근하는 예시
String jpql = "SELECT i FROM Item i WHERE TREAT(i AS Book).author = 'kim'";
List<Book> books = em.createQuery(jpql, Book.class).getResultList();
TYPE과 TREAT의 조합
TYPE과 TREAT을 함께 사용하여 특정 타입을 선택한 후 해당 타입의 필드를 사용하는 예시도 있다.
예를 들어, 모든 Item 중에서 Book 타입을 선택하고, 그중 특정 작가의 책을 찾는 경우는 다음과 같다.
String jpql = "SELECT b FROM Item i JOIN TREAT(i AS Book) b WHERE TYPE(i) = Book AND b.author = 'Jane Austen'";
List<Book> books = em.createQuery(jpql, Book.class).getResultList();
이 쿼리는 Item 중에서 Book 타입을 선택하고, author가 “Jane Austen”인 책들을 조회한다
엔티티 직접 사용
기본 키 값
JPQL에서 엔티티를 직접 사용하면 SQL에서 해당 엔티티의 기본 키 값을 사용
[JPQL]
엔티티의 아이디를 사용: select count(m.id) from Member m
엔티티를 직접 사용: select count(m) from Member m
[SQL](JPQL 둘다 같은 다음 SQL 실행)
select count(m.id) as cnt from Member m
엔티티를 파라미터로 전달
String jpql = “select m from Member m where m = :member”;
List resultList = em.createQuery(jpql)
.setParameter("member", member)
.getResultList();
.
식별자를 직접 전달
String jpql = “select m from Member m where m.id = :memberId”;
List resultList = em.createQuery(jpql)
.setParameter("memberId", memberId)
.getResultList();
실행된 SQL
select m.* from Member m where m.id=?
외래 키 값
엔티티를 파라미터로 전달
Team team = em.find(Team.class, 1L);
String qlString = “select m from Member m where m.team = :team”;
List resultList = em.createQuery(qlString)
.setParameter("team", team)
.getResultList();
식별자를 직접 전달
String qlString = “select m from Member m where m.team.id = :teamId”;
List resultList = em.createQuery(qlString)
.setParameter("teamId", teamId)
.getResultList();
실행된 SQL
select m.* from Member m where m.team_id=?
Named 쿼리
Named 쿼리(Named Query)는 엔티티 클래스에 미리 정의된 정적 쿼리이다.
보통 애플리케이션 로딩 시점에 컴파일되므로 문법 오류를 사전에 확인할 수 있고, 코드 내에서 재사용할 수 있어 편리하다.
애플리케이션 로딩 시점에 초기화 후 재사용
애플리케이션 로딩 시점에 쿼리를 검증
@Entity
@NamedQuery(
name = "Member.findByUsername",
query="select m from Member m where m.username = :username")
public class Member {
...
}
Named 쿼리 -정적 쿼리: 엔티티 클래스나 XML 파일에 미리 정의된 정적 쿼리이다. -재사용성: 한 번 정의된 Named 쿼리는 여러 곳에서 재사용할 수 있다. -문법 오류 사전 확인: 애플리케이션 로딩 시점에 쿼리 문법이 검증되어 런타임 오류를 줄일 수 있다.
@Query -동적 쿼리: Spring Data JPA에서 메서드 레벨에서 사용하는 애노테이션으로, 메서드에 대한 JPQL이나 네이티브 SQL 쿼리를 정의할 수 있다. -유연성: @Query를 사용하면 메서드마다 다르게 쿼리를 정의할 수 있으며, 동적으로 쿼리를 작성할 수 있다. -런타임 쿼리 정의: 애플리케이션 로딩 시점에 쿼리 문법이 검증되고 런타임 시점에 쿼리가 해석되기 때문에 코드의 가독성을 높일 수 있다.
연관성 -둘 다 JPA에서 특정 엔티티나 데이터베이스 테이블의 데이터를 조회하기 위한 쿼리를 정의하는 방법이다. -둘 다 정적 쿼리를 정의할 수 있으며, 로딩 시점에 문법 검증이 이루어진다.
-쿼리 정의 위치의 차이: Named 쿼리는 클래스 레벨에 정의되거나 XML 파일에 정의되며, 애플리케이션 전역에서 사용할 수 있다. 반면에 @Query는 특정 리포지토리 인터페이스의 메서드에 직접 정의된다. -용도: Named 쿼리는 정적이고 전역적인 용도로 사용되며, 여러 곳에서 재사용 가능하다. @Query는 특정 메서드에 대한 동적 쿼리를 정의하는 데 적합하다.
벌크 연산
JPQL에서 벌크 연산(Bulk Operation)은 데이터베이스의 여러 행을 한 번에 업데이트하거나 삭제하는 연산을 말한다.
벌크 연산은 일반적으로 많은 데이터를 한꺼번에 처리할 때 사용되며, 데이터베이스에 대한 성능을 최적화할 수 있는 장점이 있다.
JPQL에서는 주로 UPDATE, DELETE 문을 사용하여 벌크 연산을 수행할 수 있다.
쿼리 한 번으로 여러 테이블 로우 변경(엔티티)
executeUpdate()의 결과는 영향받은 엔티티 수 반환
UPDATE, DELETE 지원
INSERT(insert into .. select, 하이버네이트 지원)
특징
성능: 벌크 연산은 단일 쿼리로 여러 행을 처리하므로, 데이터베이스와의 상호작용 횟수를 줄여 성능을 향상시킬 수 있다.
영속성 컨텍스트 영향: 벌크 연산은 데이터베이스에서 직접 수행되기 때문에, JPA의 영속성 컨텍스트에 있는 엔티티들의 상태를 무시하고 직접 변경을 가한다. 따라서 영속성 컨텍스트와 데이터베이스의 상태가 일치하지 않을 수 있다.
벌크 연산 주의
벌크 연산은 영속성 컨텍스트를 무시하고 데이터베이스에 직접 쿼리를 날린다.
따라서 영속성 컨텍스트와 DB 상에 내용이 일치하지 않을 수 있다.
데이터를 서로 일치시키려면 벌크 연산을 먼저 실행 하거나 벌크 연산 수행 후 연속성 컨텍스트 초기화해야 한다.
벌크 연산 수행 후 영속성 컨텍스트 초기화 예제
Team teamA = new Team();
teamA.setName("teamA");
em.persist(teamA);
Team teamB = new Team();
teamB.setName("teamB");
em.persist(teamB);
Member member1 = new Member();
member1.setUsername("member1");
member1.setAge(10);
member1.setTeam(teamA);
em.persist(member1);
Member member2 = new Member();
member2.setUsername("member2");
member2.setAge(10);
member2.setTeam(teamA);
em.persist(member2);
Member member3 = new Member();
member3.setUsername("member3");
member3.setAge(10);
member3.setTeam(teamB);
em.persist(member3);
int resultCount = em.createQuery("update Member m set m.age = 20").executeUpdate();//이때 FLUSH 가 일어남
Member findMember = em.find(Member.class, member1.getId());
System.out.println(findMember.getAge());
em.clear(); //영속성 컨텍스트 초기화
findMember = em.find(Member.class, member1.getId());
System.out.println(findMember.getAge());
이 알고리즘 문제는 인프런의 자바(Java) 알고리즘 문제풀이 입문: 코딩테스트 대비 (김태원)의 문제입니다.
문제 설명
코드
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.HashMap;
import java.util.StringTokenizer;
public class sec04_03 {
public static int[] solution(int[] arr, int K) {
int[] result = new int[arr.length - K + 1];
HashMap<Integer, Integer> map = new HashMap<>();
for (int i = 0; i < K; i++) map.put(arr[i], map.getOrDefault(arr[i], 0) + 1);
result[0] = map.size();
int lPtr = 0;
for (int rPtr = K; rPtr < arr.length; ++rPtr)
{
map.put(arr[rPtr], map.getOrDefault(arr[rPtr], 0) + 1);
map.put(arr[lPtr], map.get(arr[lPtr]) - 1);
if (map.get(arr[lPtr]) == 0) map.remove(arr[lPtr]);
++lPtr;
result[rPtr - K + 1] = map.size();
}
return result;
}
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
StringTokenizer st = new StringTokenizer(br.readLine());
int N = Integer.parseInt(st.nextToken());
int K = Integer.parseInt(st.nextToken());
st = new StringTokenizer(br.readLine());
int[] arr = new int[N];
for (int i = 0; i < N; i++) arr[i] = Integer.parseInt(st.nextToken());
for (int i : solution(arr, K)) System.out.print(i + " ");
}
}
설명
해시맵과 슬라이딩 윈도우 알고리즘을 사용한다.
배열의 처음 K개 원소를 HashMap에 추가하여 각 원소의 빈도를 기록하고, 첫 번째 결과를 result[0]에 저장한다.
왼쪽 포인터(lPtr)와 오른쪽 포인터(rPtr)를 사용하여 윈도우를 한 칸씩 이동한다.
오른쪽 포인터가 가리키는 새로운 원소를 HashMap에 추가하고, 왼쪽 포인터가 가리키는 원소를 제거하여 HashMap을 업데이트한다.
이 글은 인프런 김영한님의 Spring 강의를 바탕으로 개인적인 정리를 위해 작성한 글입니다.
Java Persistence Query Language (JPQL)은 Java Persistence API (JPA)에서 사용하는 쿼리 언어이다. JPQL은 객체 지향 쿼리 언어로, SQL과 유사하지만 엔티티 객체를 대상으로 하여 데이터베이스와 상호작용한다. JPQL을 사용하면 데이터베이스의 특정 데이터를 조회하거나 조작할 수 있다.
JPA는 SQL을 추상화한 JPQL이라는 객체 지향 쿼리 언어 제공
SQL과 문법 유사, SELECT, FROM, WHERE, GROUP BY, HAVING, JOIN 지원
JPQL은 엔티티 객체를 대상으로 쿼리(테이블과 컬럼이 아닌 엔티티와 엔티티의 속성을 대상)
SQL은 데이터베이스 테이블을 대상으로 쿼리
SQL을 추상화해서 특정 데이터베이스 SQL에 의존X
JPQL을 한마디로 정의하면 객체 지향 SQL
//검색
String jpql = "select m From Member m where m.name like ‘%hello%'";
List<Member> result = em.createQuery(jpql, Member.class).getResultList();
--실행된 SQL
select
m.id as id,
m.age as age,
m.USERNAME as USERNAME,
m.TEAM_ID as TEAM_ID
from
Member m
where
m.age>18
QueryDSL
문자가 아닌 자바코드로 JPQL을 작성할 수 있음
JPQL 빌더 역할
컴파일 시점에 문법 오류를 찾을 수 있음
동적쿼리 작성 편리함
단순하고 쉬움
실무 사용 권장
//JPQL
//select m from Member m where m.age > 18
JPAFactoryQuery query = new JPAQueryFactory(em);
QMember m = QMember.member;
List<Member> list = query.selectFrom(m).where(m.age.gt(18)).orderBy(m.name.desc()).fetch();
네이티브 SQL
JPA가 제공하는 SQL을 직접 사용하는 기능
JPQL로 해결할 수 없는 특정 데이터베이스에 의존적인 기능
예) 오라클 CONNECT BY, 특정 DB만 사용하는 SQL 등은 네이티브 SQL을 사용
String sql = “SELECT ID, AGE, TEAM_ID, NAME FROM MEMBER WHERE NAME = ‘kim’";
List<Member> resultList = em.createNativeQuery(sql, Member.class).getResultList();
JDBC 직접 사용, SpringJdbcTemplate 등
JPA를 사용하면서 JDBC 커넥션을 직접 사용하거나, 스프링 JdbcTemplate, 마이바티스등을 함께 사용 가능
단 영속성 컨텍스트를 적절한 시점에 강제로 플러시 필요
예) JPA를 우회해서 SQL을 실행하기 직전에 영속성 컨텍스트 수동 플러시
기본 문법과 쿼리 API
JPQL은 객체지향 쿼리 언어다.따라서 테이블을 대상으로 쿼리 하는 것이 아니라 엔티티 객체를 대상으로 쿼리한다.
JPQL은 SQL을 추상화해서 특정 관계형 데이터베이스 SQL에 의존하지 않는다.
JPQL은 결국 SQL로 변환된다.
@Entity
public class Member {
@Id @GeneratedValue
private Long id;
private String username;
private int age;
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "TEAM_ID")
private Team team;
@Enumerated(EnumType.STRING)
private MemberType type;
//getter and setter...
}
@Entity
public class Team {
@Id @GeneratedValue
private Long id;
private String username;
@OneToMany(mappedBy = "team")
private List<Member> members = new ArrayList<>();
//getter and setter...
}
@Embeddable
public class Address {
private String city;
private String street;
private String zipcode;
//getter and setter...
}
@Entity
@Table(name = "ORDERS")
public class Order {
@Id @GeneratedValue
private Long id;
private int orderAmount;
@Embedded
private Address address;
@ManyToOne
@JoinColumn(name = "PRODUCT_ID")
private Product product;
//getter and setter...
}
@Entity
public class Product {
@Id @GeneratedValue
private Long id;
private int price;
private int stockAmount;
//getter and setter...
}
//검색
String jpql = "select m from Member m where m.age > 18";
List<Member> result = em.createQuery(jpql, Member.class).getResultList();
엔티티와 속성은 대소문자 구분O (Member, age)
JPQL 키워드는 대소문자 구분X (SELECT, FROM, where)
엔티티 이름 사용, 테이블 이름이 아님(Member)
별칭은 필수(m) (as는 생략가능)
집합과 정렬
select
COUNT(m), // Member 수
SUM(m.age), // Member의 나이 합
AVG(m.age), // Member의 평균 나이
MAX(m.age), // Member의 최대 나이
MIN(m.age) // Member의 최소 나이
from Member m
GROUP BY, HAVING, ORDER BY 등 모두 사용이 가능하다.
TypeQuery, Query
TypeQuery: 반환 타입이 명확할 때 사용
Query: 반환 타입이 명확하지 않을 때 사용
TypedQuery<Member> query = em.createQuery("SELECT m FROM Member m", Member.class);
TypedQuery<Member> query = em.createQuery("SELECT m.username FROM Member m", String.class);
Query query = em.createQuery("SELECT m.username, m.age from Member m");
결과 조회
query.getResultList(): 결과가 하나 이상일 때, 리스트 반환 -> 결과가 없으면 빈 리스트 반환
query.getSingleResult(): 결과가 정확히 하나 일때 사용, 단일 객체 반환 -> 결과가 없으면: javax.persistence.NoResultException -> 둘 이상이면: javax.persistence.NonUniqueResultException
Member member = new Member();
member.setUsername("member1");
member.setAge(10);
em.persist(member);
TypedQuery<Member> query = em.createQuery("select m from Member m where m.id = 1", Member.class);
List<Member> resultList = query.getResultList();
Member singleResult = query.getSingleResult();
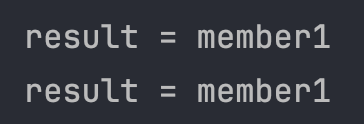
System.out.println("result = " + resultList.get(0).getUsername());
System.out.println("result = " + singleResult.getUsername());
Spring Data JPA 를 사용하면 query.getSingleResult() 를 사용할 때 NoResultException 와 NonUniqueResultException 예외를 잡아서 Optional, 리스트 또는 빈 리스트로 반환하니까 걱정안해도 된다.
파라미터 바인딩 (이름 기준, 위치 기준)
이름 기준
Member member = new Member();
member.setUsername("member1");
member.setAge(10);
em.persist(member);
Member result = em.createQuery("SELECT m FROM Member m where m.username=:username", Member.class)
.setParameter("username", "member1")
.getSingleResult();
위치 기준
Member member = new Member();
member.setUsername("member1");
member.setAge(10);
em.persist(member);
Member result = em.createQuery("SELECT m FROM Member m where m.username= ?1", Member.class)
.setParameter(1, "member1")
.getSingleResult();
프로젝션(여러 값 조회)
SELECT 절에 조회할 대상을 지정하는 것
프로젝션 대상: 엔티티, 임베디드 타입, 스칼라 타입(숫자, 문자등 기본 데이터 타입)
SELECT m FROM Member m -> 엔티티 프로젝션
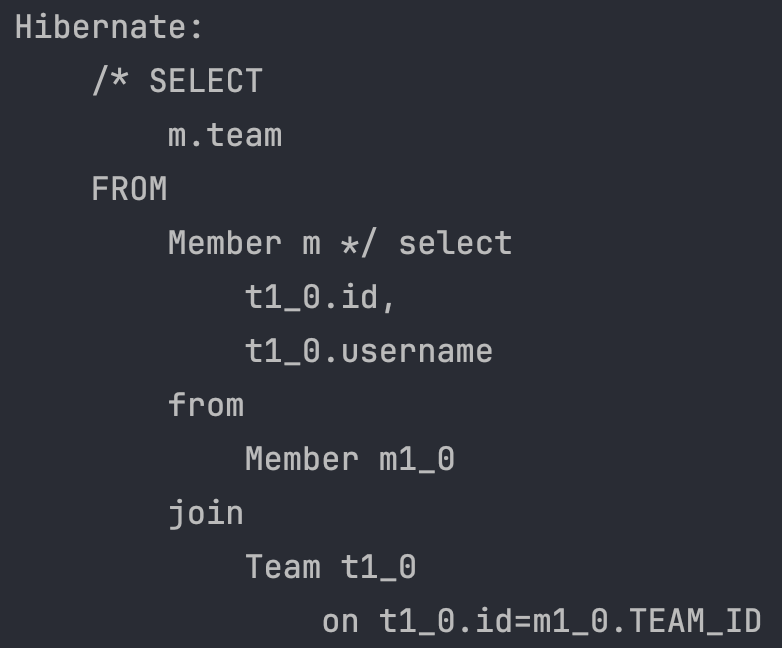
SELECT m.team FROM Member m -> 엔티티 프로젝션
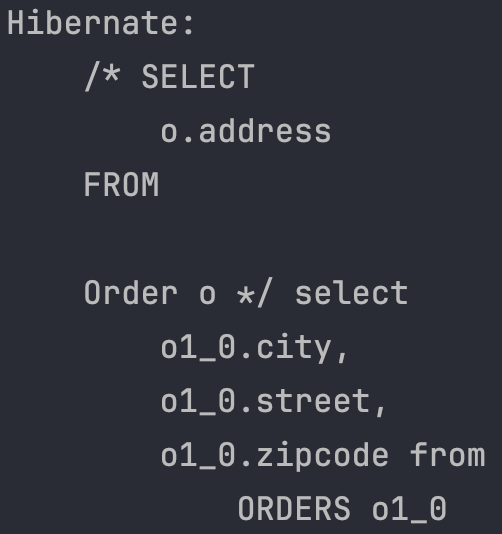
SELECT o.address FROM Order o -> 임베디드 타입 프로젝션
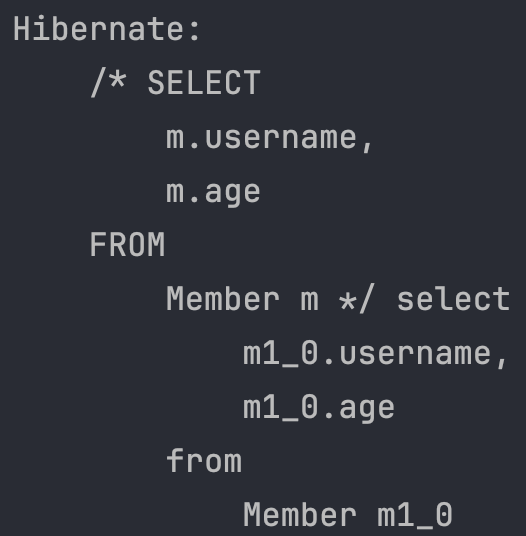
SELECT m.username, m.age FROM Member m -> 스칼라 타입 프로젝션
DISTINCT로 중복 제거 가능
List<Team> result = em.createQuery("SELECT m.team FROM Member m", Team.class).getResultList();
em.createQuery("SELECT o.address FROM Order o", Address.class).getResultList();
em.createQuery("SELECT m.username, m.age FROM Member m").getResultList();
이와 같은 경우 여러가지 방법으로 조회하는 방법이 있지만 단순 값을 DTO로 바로 조회하는 방법이 편하다.
package hellojpa.jpql;
public class MemberDTO {
private String username;
private int age;
public MemberDTO(String username, int age) {
this.username = username;
this.age = age;
}
public String getUsername() {
return username;
}
public void setUsername(String username) {
this.username = username;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
}
Member member = new Member();
member.setUsername("member1");
member.setAge(10);
em.persist(member);
List<MemberDTO> resultList = em.createQuery("SELECT new hellojpa.jpql.MemberDTO(m.username, m.age) FROM Member m", MemberDTO.class)
.getResultList();
MemberDTO memberDTO = resultList.get(0);
System.out.println(memberDTO.getUsername());
System.out.println(memberDTO.getAge());
패키지 명을 포함한 전체 클래스 명 입력
순서와 타입이 일치하는 생성자 필요
페이징
JPA는 페이징을 다음 두 API로 추상화
setFirstResult(int startPosition) : 조회 시작 위치 setFirstResult(10)으로 설정하면, 쿼리 결과의 11번째 항목부터 데이터를 가져오기 시작한다. 이는 0부터 시작하기 때문이다.
setMaxResults(int maxResult) : 조회할 데이터 수 setMaxResults(10)으로 설정하면, 최대 10개의 결과를 가져온다.
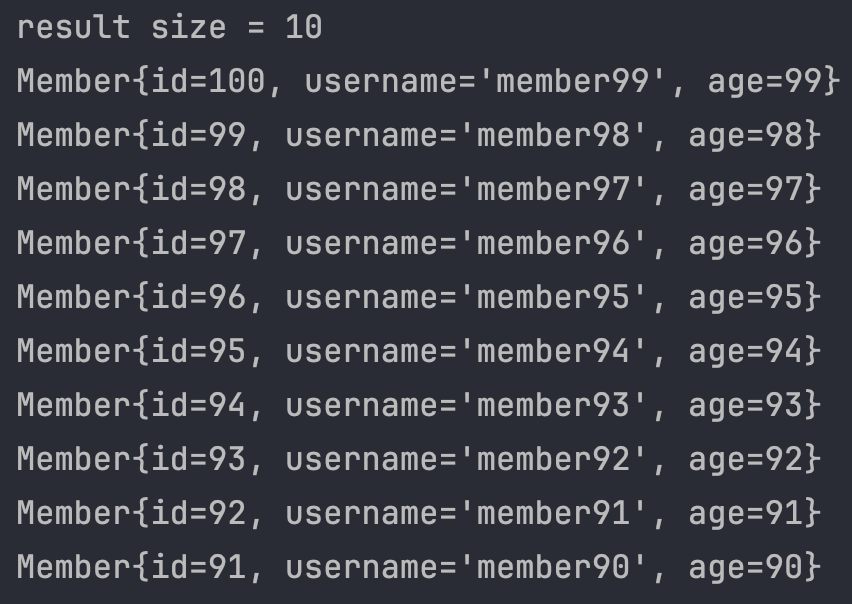
for(int i = 0; i < 100; ++i)
{
Member member = new Member();
member.setUsername("member" + i);
member.setAge(i);
em.persist(member);
}
String jpql = "select m from Member m order by m.age desc";
List<Member> resultList = em.createQuery(jpql, Member.class)
.setFirstResult(0)
.setMaxResults(10)
.getResultList();
System.out.println("result size = " + resultList.size());
for(Member member : resultList){
System.out.println(member);
}
조인
내부 조인 : SELECT m FROM Member m [INNER] JOIN m.team t
외부 조인 : SELECT m FROM Member m LEFT [OUTER] JOIN m.team t
세타 조인 : select count(m) from Member m, Team t where m.username = t.name
Team team = new Team();
team.setName("teamA");
em.persist(team);
Member member = new Member();
member.setUsername("member1");
member.setAge(10);
member.setTeam(team);
em.persist(member);
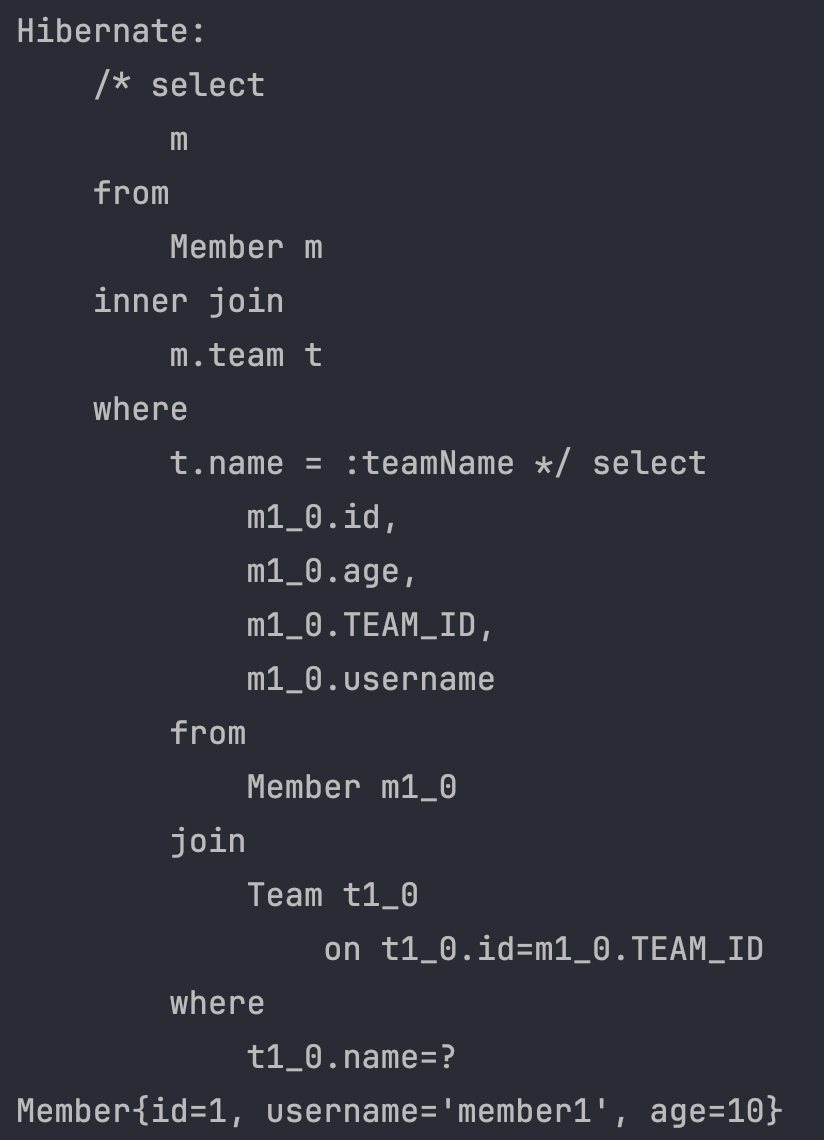
String query = "select m from Member m inner join m.team t where t.name = :teamName";
List<Member> resultList = em.createQuery(query, Member.class)
.setParameter("teamName", "teamA")
.getResultList();
for (Member m : resultList) System.out.println(m);
주어진 JPQL 쿼리는 teamA라는 이름을 가진 팀에 속한 모든 멤버를 조회하는 쿼리이다.
조인 대상 필터링
예) 회원과 팀을 조인하면서, 팀 이름이 A인 팀만 조인
JPQL
SELECT m, t FROM Member m LEFT JOIN m.team t on t.name = 'A'
SQL
SELECT m.*, t.* FROM Member m LEFT JOIN Team t ON m.TEAM_ID = t.id and t.name='A'
연관관계 없는 엔티티 외부 조인
예) 회원의 이름과 팀의 이름이 같은 대상 외부 조인
JPQL
SELECT m, t FROM Member m LEFT JOIN Team t on m.username = t.name
SQL
SELECT m.*, t.* FROM Member m LEFT JOIN Team t ON m.username = t.name
Team team = new Team();
team.setName("teamA");
em.persist(team);
Member member = new Member();
member.setUsername("member1");
member.setAge(10);
member.setTeam(team);
em.persist(member);
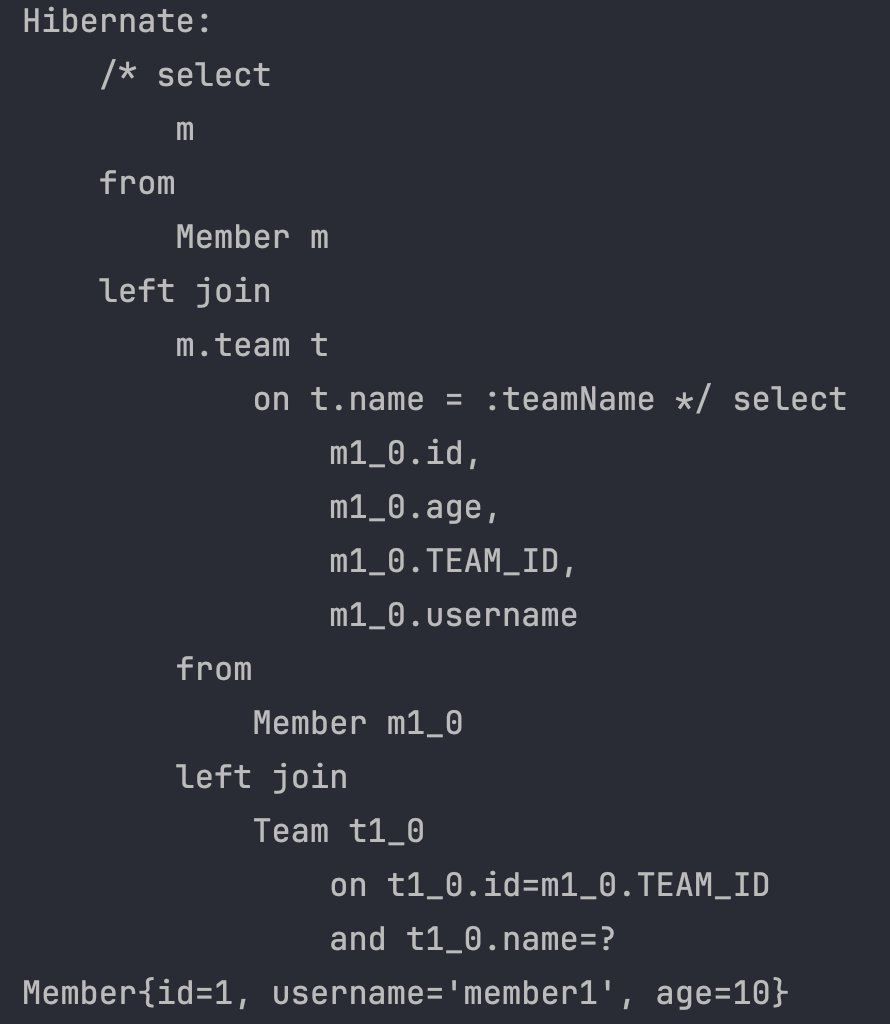
String query = "select m from Member m left join m.team t on t.name = :teamName";
List<Member> resultList = em.createQuery(query, Member.class)
.setParameter("teamName", "teamA")
.getResultList();
for (Member m : resultList) System.out.println(m);
서브 쿼리
나이가 평균보다 많은 회원
select m from Member m
where m.age > (select avg(m2.age) from Member m2)
outter 쿼리의 m과 inner 쿼리의 m2는 상관이 없다.
또한 outter와 inner의 대상이 서로 달라야(상관이 없어야) 쿼리의 성능이 향상된다.
한 건이라도 주문한 고객
select m from Member m
where (select count(o) from Order o where m = o.member) > 0
서브 쿼리 지원 함수
[NOT] EXISTS (subquery): 서브쿼리에 결과가 존재하면 참
{ALL | ANY | SOME} (subquery)
ALL 모두 만족하면 참
ANY, SOME: 같은 의미, 조건을 하나라도 만족하면 참
[NOT] IN (subquery): 서브쿼리의 결과 중 하나라도 같은 것이 있으면 참
팀A 소속인 회원
select m from Member m
where exists (select t from m.team t where t.name = ‘팀A')
전체 상품 각각의 재고보다 주문량이 많은 주문들
select o from Order o
where o.orderAmount > ALL (select p.stockAmount from Product p)
어떤 팀이든 팀에 소속된 회원
select m from Member m
where m.team = ANY (select t from Team t)
JPQL 타입 표현
문자: ‘HELLO’, ‘She’’s’
숫자: 10L(Long), 10D(Double), 10F(Float)
Boolean: TRUE, FALSE
ENUM: jpabook.MemberType.Admin (패키지명 포함)
엔티티 타입: TYPE(m) = Member (상속 관계에서 사용)
Team team = new Team();
team.setName("teamA");
em.persist(team);
Member member = new Member();
member.setUsername("member1");
member.setAge(10);
member.setTeam(team);
member.setType(MemberType.USER);
em.persist(member);
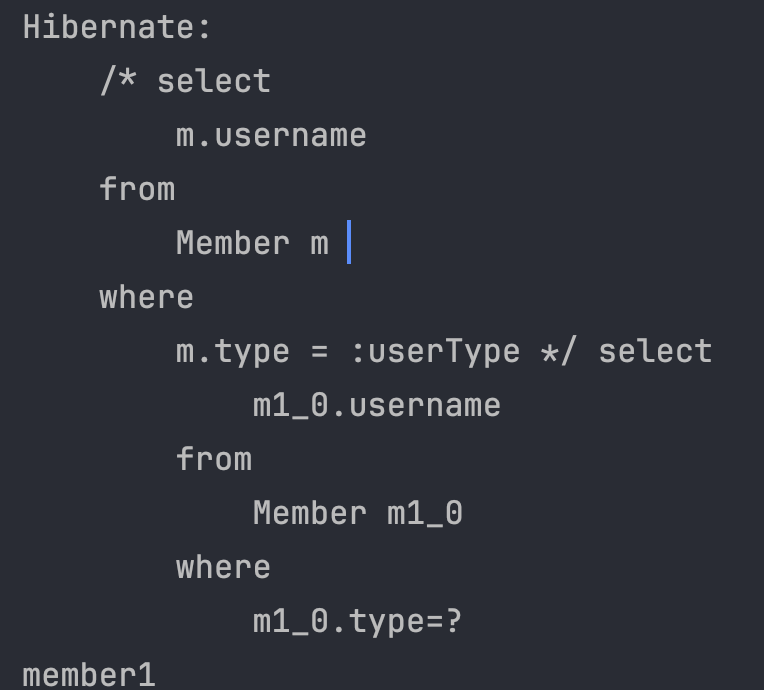
//String query = "select m.username from Member m where m.type = hellojpa.jpql.MemberType.USER";
String query = "select m.username from Member m where m.type = :userType";
Object singleResult = em.createQuery(query)
.setParameter("userType", MemberType.USER)
.getSingleResult();
System.out.println(singleResult);
기타
SQL과 문법이 같은 식
EXISTS, IN
AND, OR, NOT
=, >, >=, <, <=, <>
BETWEEN, LIKE, IS NULL
CASE(조건식)
기본 CASE 식
select
case when m.age <= 10 then '학생요금'
when m.age >= 60 then '경로요금'
else '일반요금'
end
from Member m
Team team = new Team();
team.setName("teamA");
em.persist(team);
Member member = new Member();
member.setUsername("member1");
member.setAge(10);
member.setTeam(team);
member.setType(MemberType.USER);
em.persist(member);
em.flush();
em.clear();
String query = "select case when m.age <= 10 then '학생요금' " +
"when m.age >= 60 then '경로요금' " +
"else '일반요금' " +
"end " +
"from Member m";
List<String> resultList = em.createQuery(query, String.class).getResultList();
for (String result : resultList) {
System.out.println("result = " + result);
}
단순 CASE식
select
case t.name
when '팀A' then '인센티브110%'
when '팀B' then '인센티브120%'
else '인센티브105%'
end
from Team t
COALESCE: 여러 인수를 받아서 그 중 첫 번째로 널이 아닌 값을 반환
Team team = new Team();
team.setName("teamA");
em.persist(team);
Member member = new Member();
member.setUsername(null); //null
member.setAge(10);
member.setTeam(team);
member.setType(MemberType.USER);
em.persist(member);
em.flush();
em.clear();
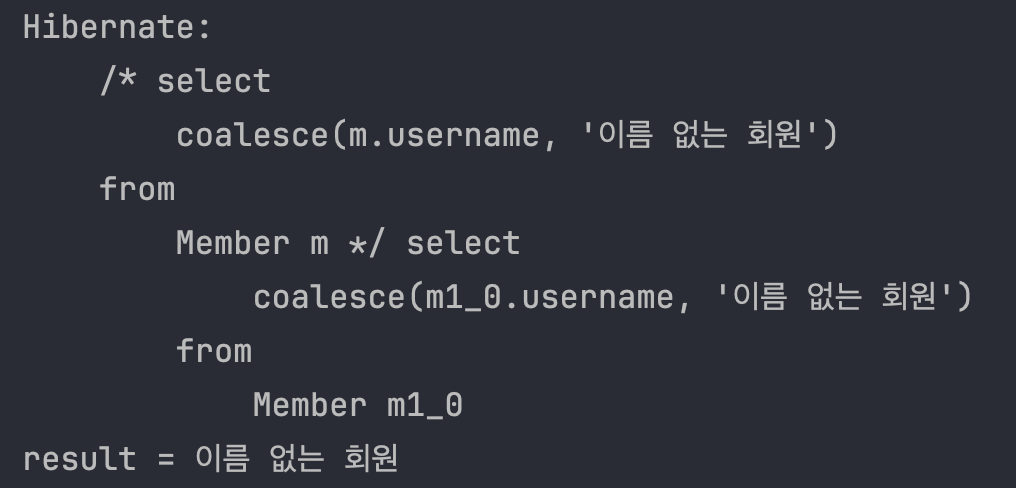
String query = "select coalesce(m.username, '이름 없는 회원') from Member m";
List<String> resultList = em.createQuery(query, String.class).getResultList();
for (String result : resultList) {
System.out.println("result = " + result);
}
COALESCE 함수는 SQL 및 JPQL에서 널(null) 값을 처리하는 데 사용된다. 여러 인수를 받아서 그 중 첫 번째로 널이 아닌 값을 반환한다. COALESCE는 데이터베이스 쿼리에서 널 값을 대체하거나 기본 값을 제공하는 데 매우 유용하다.
COALESCE 함수 설명 용도: 여러 인수 중 첫 번째 널이 아닌 값을 반환한다. 형식: COALESCE(value1, value2, ..., valueN) 반환 값: 인수 중 첫 번째 널이 아닌 값. 모든 인수가 널이면 널을 반환한다.
String jpql = "SELECT COALESCE(m.nickname, m.username) FROM Member m";
TypedQuery<String> query = em.createQuery(jpql, String.class);
List<String> names = query.getResultList();
for (String name : names) {
System.out.println(name);
}
SELECT COALESCE(m.nickname, m.username) FROM Member m -> Member 엔티티에서 nickname이 널인 경우 username을 반환한다.
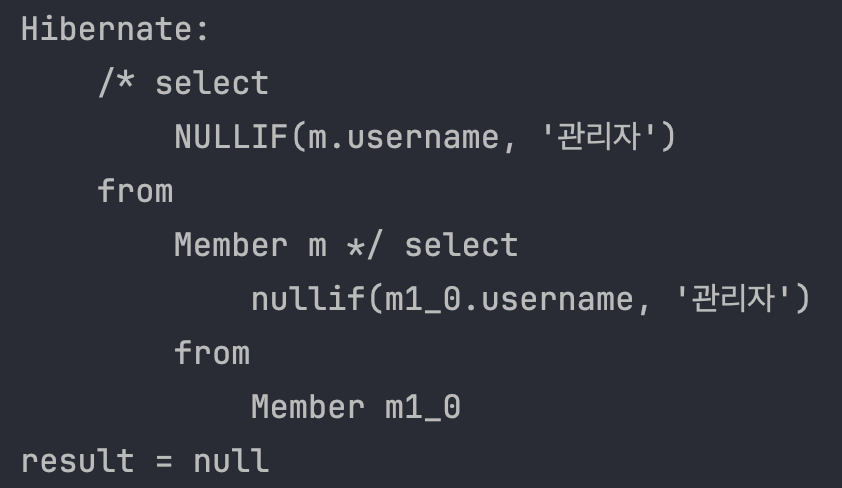
NULLIF: 두 값이 같으면 null 반환, 다르면 첫번째 값 반환
Team team = new Team();
team.setName("teamA");
em.persist(team);
Member member = new Member();
member.setUsername("관리자"); //null
member.setAge(10);
member.setTeam(team);
member.setType(MemberType.USER);
em.persist(member);
em.flush();
em.clear();
String query = "select NULLIF(m.username, '관리자') from Member m";
List<String> resultList = em.createQuery(query, String.class).getResultList();
for (String result : resultList) {
System.out.println("result = " + result);
}
String jpql = "SELECT NULLIF(m.nickname, m.username) FROM Member m";
TypedQuery<String> query = em.createQuery(jpql, String.class);
List<String> results = query.getResultList();
for (String result : results) {
System.out.println(result);
}
SELECT NULLIF(m.nickname, m.username) FROM Member m
이 알고리즘 문제는 인프런의 자바(Java) 알고리즘 문제풀이 입문: 코딩테스트 대비 (김태원)의 문제입니다.
문제 설명
코드
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.HashMap;
public class sec04_01 {
public static char solution(String str) {
HashMap<Character, Integer> map = new HashMap<>();
char result = 0;
int max = 0;
for (char c : str.toCharArray())
{
int count = map.getOrDefault(c, 0) + 1;
map.put(c, count);
if (count > max)
{
max = count;
result = c;
}
}
return result;
}
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
int N = Integer.parseInt(br.readLine());
System.out.println(solution(br.readLine()));
}
}
설명
map.getOrDefault(c, 0)는 map에서 문자 c의 현재 값(value)을 가져오며, 만약 map에 c가 없으면 기본값 0을 반환
map의 각 키를 순회하면서 가장 큰 빈도(max)를 찾고, 그에 해당하는 문자를 result에 저장
Map의 주요 메서드
put(K key, V value) 지정된 키와 값을 맵에 추가하거나, 키가 이미 존재하면 그 값을 갱신
get(Object key) 지정된 키에 대응하는 값을 반환한다. 키가 없으면 null을 반
getOrDefault(Object key, V defaultValue) 지정된 키에 대응하는 값을 반환한다. 키가 없으면 기본값을 반환
이 글은 인프런 김영한님의 Spring 강의를 바탕으로 개인적인 정리를 위해 작성한 글입니다.
JPA에서 값 타입(Value Type)은 엔티티(Entity)와는 다른 개념으로, 데이터베이스의 테이블에 독립적으로 저장되지 않으며 엔티티에 포함되는 속성을 말한다.
JPA 값 타입은 크게 세 가지로 구분된다
기본 값 타입 -자바 기본 타입(int, double) -래퍼 클래스(Integer, Long) -String
임베디드 값 타입(embedded type, 복합 값 타입)
컬렉션 값 타입(collection value type)
이를 통해 객체지향적으로 데이터를 더 효율적으로 관리할 수 있다.
엔티티 타입과 값 타입의 구분
엔티티 타입
값 타입
@Entity로 정의하는 객체
int, Integer, String처럼 단순히 값으로 사용하는 자바 기본 타입이나 객체
데이터가 변해도 식별자로 지속해서 추적 가능
식별자가 없고 값만 있으므로 변경시 추적 불가
예)회원 엔티티의 키나 나이 값을 변경해도식별자로 인식가능
예) 숫자 100을 200으로 변경하면 완전히 다른 값으로 대체
기본값 타입
기본 값 타입들은 생명주기가 엔티티에 의존되어 있다.
예를 들어 Student라는 엔티티에 있는 int age, String name은 student1객체가 삭제 되면 같이 삭제 된다.
자바의 기본 타입은 절대 공유되지 않는다. int, double과 같은 기본 타입(primitive type)은 항상 값을 복사하기 때문에 절대 공유해서는 안되고, Integer같은 래퍼 클래스나 String 같은 특수한 클래스는 공유는 가능한 객체이지만 변경 할 수 없다.
임베디드 타입(embedded type, 복합 값 타입)
주로 기본 값 타입을 모아서 만들기 때문에 복합 값 타입이라고도 한다.
복합 값타입으로 새로운 값타입을 직접 정의할 수 있다.
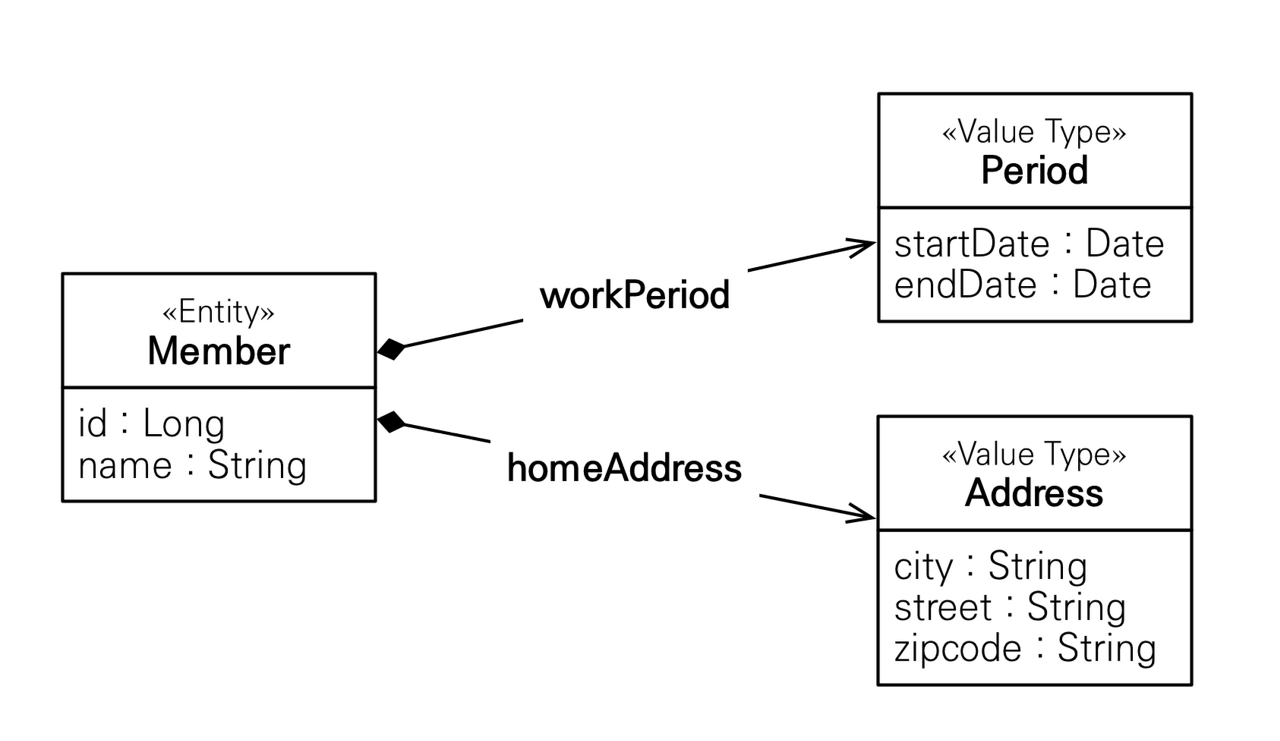
예를들어 회원 정보에서 비슷한 정보끼리 묶어 관리하고 싶다면 그런 묶음을 임베디드 타입으로 만들어 주고 사용하면 된다.
위와 같이 회원 정보 중 startDate와 endDate를 묶어 Period로 city, street, zipcode를 묶어 Address로 관리하려면, 아래와 같이 Address와 Period 클래스에(값 타입을 정의하는 곳에) @Embeddable을 붙여주고, 값 타입을 사용하는 곳이 Member에는 @Embedded를 붙여주면 된다.
이 때 임베디드타입들은 기본생성자가 필수적으로 있어야한다.
@Embeddable
public class Address {
private String city;
private String street;
private String zipcode;
public Address() { // 기본생성자 필수
}
}
@Embeddable
public class Period {
private LocalDateTime startDate;
private LocalDateTime endDate;
public Period() { // 기본생성자 필수
}
}
public class Member {
@Id @GeneratedValue
@Column(name = "MEMBER_ID")
private Long id;
@Column(name = "USERNAME")
private String username;
//period
@Embedded
private Period period;
//address
@Embedded
private Address homeAddress;
}
이런 임베디드 타입의 장점은 재사용, 높은 응집도, 그리고 Period.isWork()처럼 임베디드 타입에 사용할 특정 메소드를 따로 관리할 수 있다는 점이다.
임베디드 타입으로 빼서 관리를 해도 결국 Member 테이블에 변화는 없다.
임베디드 타입으로 만들어준 Period와 Address가 모두 Member테이블에 들어가 있다.
임베디드 타입은 엔티티의 값일 뿐이고, 임베디드 타입을 사용하기 전과 후에 매핑하는 테이블은 같다. 객체와 테이블을 아주 세밀하게(find-grained) 매핑하는 것이 가능하다.
값 타입과 불변 객체
값 타입은 복잡한 객체 세상을 조금이라도 단순화하려고 만든 개념이다.
따라서 최대한 단순하고 안전하게 다룰 수 있어야 한다. 우선 값 타입들은 서로 공유를 하면 안된다.
다른 회원의 나이가 변경되었다고 다른 회원의 이름도 변경되면 안되는 것처럼 기본값 타입은 애초에 값을 복사하기 때문에 공유를 할 수 없고, 래퍼 클래스나 String은 참조값을 복사하기 때문에 공유가 가능하지만 수정이 불가능하기 때문에 괜찮다.
하지만 임베디드 타입은 직접 정의한 객체 타입이기 때문에 기본값 타입과는 다르게 공유가 가능하고 수정 또한 가능해서 유의해야한다.
위 그림과 같이 회원1과 회원2의 주소가 같아서, 하나의 Address객체를 만든 뒤 같이 넣어주면 값을 공유하게 된다.
// 위 그림에 대한 코드
Address address = new Address("city","street","zipcode");
Member member1 = new Member();
member1.setUsername("A");
member1.setAddress(address);
Member member2 = new Member();
member2.setUsername("B");
member2.setAddress(member1.getAddress());
이렇게되면 회원1이나 2가 이후 주소를 변경해도 함께 변경되기 때문에 문제가 생길 수 있다.
그래서 값 타입의 실제 인스턴스인 값을 공유하는 방식 대신, 값(인스턴스)를 복사해서 사용한다.
더 정확히 말하면 실제 인스턴스 값을 공유하는 것이 아니라 새로운 인스턴스를 만들어서 사용해야 한다.
불변객체란 생성 시점이후에 변경할 수 없는 객체로 Integer, String 등이 이에 속한다.
불변객체로 만드는 방법은 setter를 정의하지 않거나 private로 정의하면 된다. (생성자로만 모든 값 처리를 하는 방법)
값 타입 비교
동일성 비교
인스턴스의 참조 값을 비교한다. == 을 이용해서 비교하는 방법. 자바의 기본타입은 값이 같으면 같은 공간을 쓰기 때문에 아래와 같은 경우 최종적으로 b와 c는 같은 값, 같은 주소를 갖게 된다.
int a = 10;
int b = a; // 기본타입으로, 공유 x
int c = 10;
a = 20;
System.out.println("a = " + a); // a = 20
System.out.println("b = " + b); // b = 10
System.out.println("c = " + c); // c = 10
System.out.println("b == c : " + (b == c)); // b == c : true
System.out.println("b = " + System.identityHashCode(b)); // b = 157627094
System.out.println("c = " + System.identityHashCode(c)); // c = 157627094
동등성 비교
equals() 사용해서 인스턴스의 값을 비교한다.
자바의 기본타입을 제외하고는 동등성 비교를 해줘야 값만 비교가 가능하다.
따라서 값 타입은 자바의 기본타입을 제외하고는 모두 equals연산을 사용해야하며, 오브젝트 타입 같이 따로 정의해준 타입은 equals를 따로 정의해줘야한다.
Address같은 경우 이렇게 equals와 hashCode를 오버라이딩해서 각각의 요소마다 비교를 할 수 있도록 해야한다.
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Address address = (Address) o;
return Objects.equals(city, address.city) && Objects.equals(street, address.street) && Objects.equals(zipcode, address.zipcode);
}
@Override
public int hashCode() {
return Objects.hash(city, street, zipcode);
}
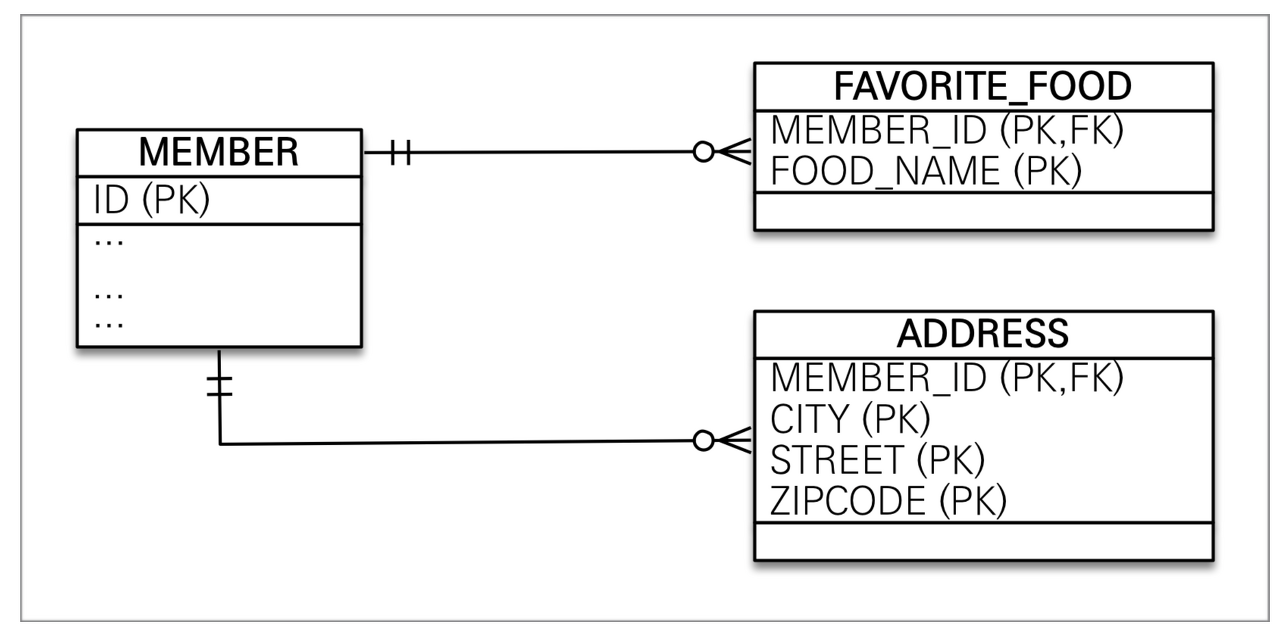
컬렉션 값 타입 동작 방식 joinColumns에는 FK로 쓸 값을 넣어주고 식별자는 모든 컬럼의 PK의 조합이 된다.
컬렉션을 위한 별도의 테이블이 만들어진다. 지연 로딩을 사용해서 Member를 가져올 때 FAVORITE FOOD는 프록시 객체로 들어오고 실제로 쓰일 때 쿼리가 날아간다.
영속성 전이(Cascade)와 고아 객체 제거 기능을 필수로 가진다고 볼 수 있다.
값 타입 컬렉션에는 제약사항 값을 수정할 시 추적이 어렵다. 값 타입 컬렉션에 변경 사항이 발생하면 주인 엔티티와 연관된 모든 데이터를 삭제하고, 값 타입 컬렉션에 있는 현재 값을 모두 다시 저장한다.
지금 Favorite food는 자료형이 Set이기 때문에 최적화가 되어 있어서 delete 쿼리 하나와 insert 쿼리 하나가 나가지만 List와 같이 그렇지 않은 다른 자료형이었다면 전부 지워지고 남은 것들이 다시 추가된다. 예를 들어 기존에 3개가 있었고 1개를 지우고 1개를 넣는다면 delete 전체삭제 쿼리 + insert 3개가 나가는 것이다.
이런 상황이 생기는 이유는 값 타입이 엔티티와 다르게 식별자 개념이 없기 때문이다. 식별자가 PK가 조합으로 이뤄져있어서 조회가 번거롭다.
위와 같은 제약사항 때문에 실무에서는 상황에 따라 값 타입 컬렉션 대신에 일대다 관계를 고려해야한다.
일대다 관계를 위한 엔티티를 만들고, 여기에서 값 타입을 사용해서 영속성 전이(Cascade) + 고아 객체 제거로 값 타입 컬렉션'처럼' 사용하자.
@Entity
public class Member {
@Id @GeneratedValue
@Column(name = "MEMBER_ID")
private Long ID;
@Column(name = "USERNAME")
private String username;
@ManyToOne
@JoinColumn(name = "TEAM_ID", insertable = false, updatable = false)
private Team team;
@OneToMany(cascade = CascadeType.ALL, orphanRemoval = true)
@JoinColumn(name = "MEMBER_ID")
private List<AddressEntity> addressHistory = new ArrayList<>();
@Embedded
private Address homeAddress;
@ElementCollection
@CollectionTable(name = "FAVORIT_FOOD", joinColumns = @JoinColumn(name = "MEMBER_ID"))
@Column(name = "FOOD_NAME")
private Set<String> favoriteFoods = new HashSet<>();
//getter and setter...
}
@Embeddable
public class Address {
private String city;
private String street;
private String zipcode;
public Address() {
}
public Address(String city, String street, String zipcode) {
this.city = city;
this.street = street;
this.zipcode = zipcode;
}
//getter and setter...
}
@Entity
@Table(name = "ADDRESS")
public class AddressEntity {
@Id @GeneratedValue
private Long id;
private Address address;
public AddressEntity() {
}
public AddressEntity(String city, String street, String zipcode) {
this.address = new Address(city, street, zipcode);
}
//getter and setter...
}
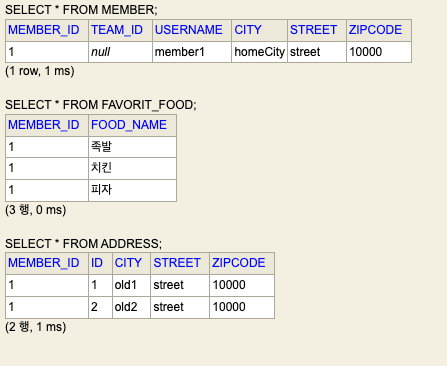
Member member = new Member();
member.setUsername("member1");
member.setHomeAddress(new Address("homeCity", "street", "10000"));
member.getFavoriteFoods().add("치킨");
member.getFavoriteFoods().add("족발");
member.getFavoriteFoods().add("피자");
member.getAddressHistory().add(new AddressEntity("old1", "street", "10000"));
member.getAddressHistory().add(new AddressEntity("old2", "street", "10000"));
em.persist(member);
em.flush();
em.clear();
System.out.println("====================");
em.find(Member.class, member.getID());
식별자가 필요하고, 지속해서 값을 추적, 변경해야 한다면 그것은 값 타입이 아닌 엔티티로 구현해야 한다.
이 알고리즘 문제는 인프런의 자바(Java) 알고리즘 문제풀이 입문: 코딩테스트 대비 (김태원)의 문제입니다.
문제 설명
코드
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.StringTokenizer;
public class sec03_06 {
public static int solution(int[] arr, int N, int K) {
int maxLength = 0;
int lPtr = 0, count = 0;
for(int rPtr = 0; rPtr < N; ++rPtr)
{
if(arr[rPtr] == 0) ++count;
while(count > K) if(arr[lPtr++] == 0) --count;
if(rPtr - lPtr + 1 > maxLength) maxLength = rPtr - lPtr + 1;
}
return maxLength;
}
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
StringTokenizer st = new StringTokenizer(br.readLine());
int N = Integer.parseInt(st.nextToken());
int K = Integer.parseInt(st.nextToken());
st = new StringTokenizer(br.readLine());
int[] arr = new int[N];
for (int i = 0; i < N; i++) arr[i] = Integer.parseInt(st.nextToken());
System.out.println(solution(arr, N, K));
}
}
설명
투 포인터와 슬라이딩 윈도우 알고리즘 사용 -lPtr과 rPtr 두 개의 포인터를 사용하여 현재 윈도우를 관리한다. -count는 현재 윈도우 내에 있는 0의 개수를 저장한다. -rPtr을 증가시키면서 윈도우를 오른쪽으로 확장한다. -윈도우 내의 0의 개수가 K 를 초과하면 lPtr을 증가시켜 윈도우를 축소한다. -윈도우의 길이가 최대 길이를 갱신할 때마다 maxLength를 업데이트한다.
슬라이딩 윈도우 확장 -배열의 시작부터 끝까지 반복 (rPtr 오른쪽 포인터를 0부터 N-1까지 이동). -현재 요소(arr[rPtr])가 0이면, count를 증가시킨다.
윈도우 축소 -만약 count가 K 보다 커지면, 즉 윈도우 내의 0의 개수가 K 를 초과하면: -윈도우의 왼쪽 끝(lPtr)을 오른쪽으로 이동하여 윈도우를 축소한다. -만약 lPtr이 가리키는 요소가 0이면, count를 감소시킨다.
최대 길이 갱신 -현재 윈도우의 길이(rPtr - lPtr + 1)가 maxLength보다 크면, maxLength를 갱신한다.