이 글은 인프런 김영한님의 Spring 강의를 바탕으로 개인적인 정리를 위해 작성한 글입니다.
즉시 로딩과 지연 로딩

public void printUserAndTeam(String memberId) {
Member member = em.find(Member.class, memberId);
Team team = member.getTeam();
System.out.println("회원 이름: " + member.getUsername());
System.out.println("소속팀: " + team.getName());
}회원과 팀을 함게 출력해야하는 로직에서는 상관 없지만, 단순히 회원만 출력하는 로직에서는 굳이 팀까지 DB에서 조회해서 가져올 필요가 없다.
public void printUser(String memberId) {
Member member = em.find(Member.class, memberId);
Team team = member.getTeam();
System.out.println("회원 이름: " + member.getUsername());
}
지연 로딩
@ManyToOne(fetch = FetchType.LAZY) 어노테이션은 JPA에서 연관 관계를 정의할 때 사용되며, fetch = FetchType.LAZY 옵션을 통해 지연 로딩(Lazy Loading)을 지정할 수 있다.
이는 연관된 엔티티를 실제로 사용할 때까지 데이터베이스 조회를 지연시키는 방식이다.
- @ManyToOne, @OneToOne은 기본(default)이 즉시 로딩
- @OneToMany, @ManyToMany는 기본(default)이 지연 로딩

@Entity
public class Member {
@Id @GeneratedValue
@Column(name = "MEMBER_ID")
private Long ID;
@Column(name = "USERNAME")
private String username;
@ManyToOne(fetch = FetchType.LAZY) //지연 로딩 설정
@JoinColumn(name = "TEAM_ID")
private Team team;
//getter and setter...
}
@Entity
public class Team {
@Id @GeneratedValue
@Column(name = "TEAM_ID")
private Long id;
private String name;
@OneToMany
@JoinColumn(name = "TEAM_ID")
private List<Member> members = new ArrayList<>();
//getter and setter...
}
Team team = new Team();
team.setName("TeamA");
em.persist(team);
Member member1 = new Member();
member1.setUsername("member1");
member1.setTeam(team);
em.persist(member1);
em.flush();
em.clear();
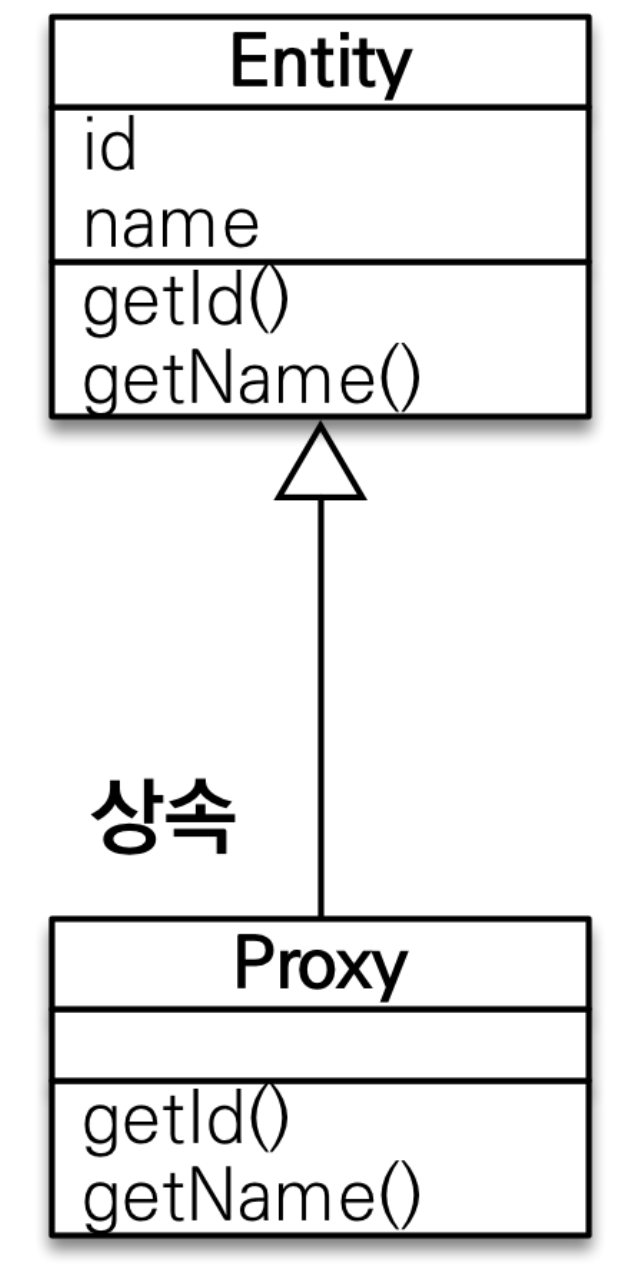
Member m = em.find(Member.class, member1.getID());
System.out.println("m = " + m.getTeam().getClass()); //프록시
System.out.println("=======");
m.getTeam().getName(); //프록시 초기화

즉시 로딩
@ManyToOne(fetch = FetchType.EAGER) 어노테이션은 JPA에서 연관된 엔티티를 즉시 로딩하도록 설정하는 방법이다.
즉, 해당 엔티티를 조회할 때 연관된 엔티티도 함께 로드된다. 이는 기본적으로 사용되는 로딩 방식이기도 하다.
하지만 실무에서는 즉시 로딩을 사용해선 안된다!

@Entity
public class Member {
@Id @GeneratedValue
private Long id;
@Column(name = "USERNAME")
private String name;
@ManyToOne(fetch = FetchType.EAGER) //즉시 로딩 설정
@JoinColumn(name = "TEAM_ID")
private Team team;
}
Team team = new Team();
team.setName("TeamA");
em.persist(team);
Member member1 = new Member();
member1.setUsername("member1");
member1.setTeam(team);
em.persist(member1);
em.flush();
em.clear();
Member m = em.find(Member.class, member1.getID());
System.out.println("m = " + m.getTeam().getClass());
System.out.println("=======");
m.getTeam().getName();

즉시 로딩의 문제점
- 즉시 로딩을 적용하면 예상하지 못한 SQL이 발생
- 즉시 로딩은 JPQL에서 N+1 문제를 일으킨다.
- @ManyToOne, @OneToOne은 기본이 즉시 로딩 -> LAZY로 설정을 변경해서 사용
- @OneToMany, @ManyToMany는 기본이 지연 로딩
- 가급적 지연 로딩을 사용해야 한다.
영속성 전이(CASCADE)
JPA에서 영속성 전이(Cascade)는 엔티티의 상태 변화가 연관된 엔티티에게도 전이되는 것을 의미한다.
특정 엔티티를 영속 상태로 만들 때 연관된 엔티티도 함께 영속 상태로 만들도 싶을 때 사용한다.
예를 들어, 부모 엔티티를 저장할 때 자식 엔티티도 함께 저장해야할 때 사용한다.
참조하는 곳이 하나일 때 사용해야한다. 여러 곳에 연관관계가 있을 때 사용하면 안 된다.
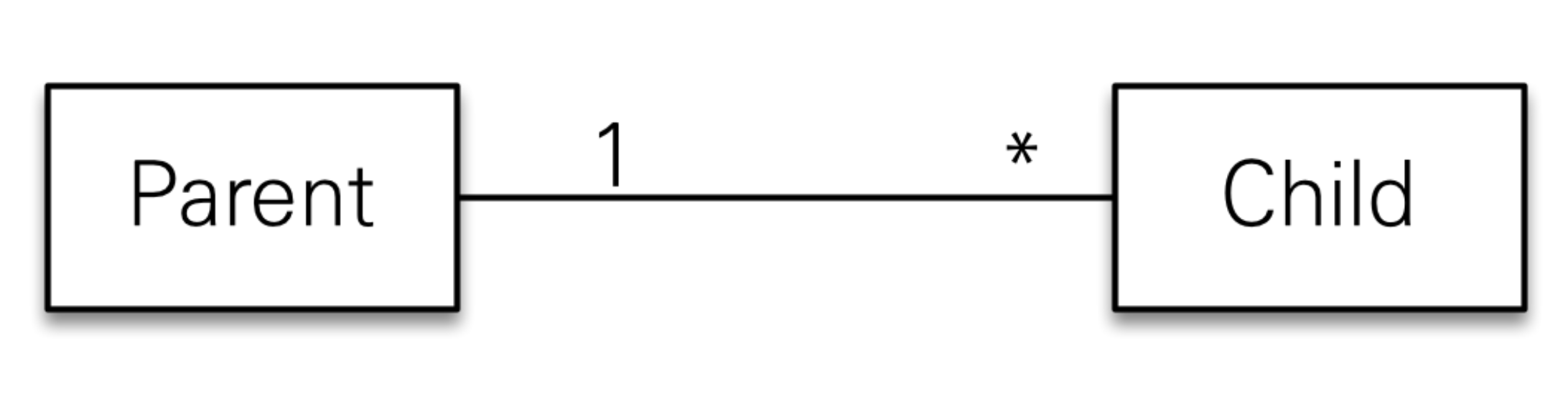
이를 통해 개발자는 연관된 엔티티의 상태를 관리하기 쉽게 할 수 있다. @ManyToOne, @OneToMany, @OneToOne, @ManyToMany와 같은 관계에서 cascade 속성을 설정할 수 있다.
@OneToMany(mappedBy="parent", cascade=CascadeType.PERSIST)
주의
영속성 전이는 연관관계를 매핑하는 것과 아무 관련이 없다.
엔티티를 영속화할 때 연관된 엔티티도 함께 영속화하는 편리함을 제공할 뿐이다.
Cascade 유형
- CascadeType.PERSIST: 엔티티를 영속화할 때 연관된 엔티티도 함께 영속화한다.
- CascadeType.MERGE: 엔티티를 병합할 때 연관된 엔티티도 함께 병합한다.
- CascadeType.REMOVE: 엔티티를 삭제할 때 연관된 엔티티도 함께 삭제한다.
- CascadeType.REFRESH: 엔티티를 새로고침할 때 연관된 엔티티도 함께 새로고침한다.
- CascadeType.DETACH: 엔티티를 준영속 상태로 만들 때 연관된 엔티티도 함께 준영속 상태로 만든다.
- CascadeType.ALL: 모든 Cascade 유형을 포함한다.
@Entity
public class Parent {
@Id @GeneratedValue
private Long id;
private String name;
@OneToMany(mappedBy = "parent", cascade = CascadeType.ALL) //영속성 전이 설정
private List<Child> childList = new ArrayList<>();
public void addChild(Child child) {
childList.add(child);
child.setParent(this);
}
//getter and setter...
}
@Entity
public class Child {
@Id
@GeneratedValue
private Long id;
private String name;
@ManyToOne
@JoinColumn(name = "parent_id")
private Parent parent;
//getter and setter...
}
Child child1 = new Child();
Child child2 = new Child();
Parent parent = new Parent();
parent.addChild(child1);
parent.addChild(child2);
//em.persist(parent);
//em.persist(child1);
//em.persist(child2);
em.persist(parent);
고아 객체
orphanRemoval = true
JPA에서 고아 객체(orphan entity)란 부모 엔티티와의 연관 관계가 제거되어 더 이상 참조되지 않는 자식 엔티티를 의미한다. 이러한 고아 객체는 데이터베이스에서 자동으로 삭제되도록 설정할 수 있다. 이를 위해 JPA에서는 orphanRemoval 속성을 제공한다
고아 객체 제거: 부모 엔티티와 연관관계가 끊어진 자식 엔티티를 자동으로 삭제
orphanRemoval = true 설정을 통해 고아 객체가 발생할 경우 자동으로 삭제되도록 할 수 있다.
이 설정은 @OneToMany 및 @OneToOne 관계에서만 사용 가능하다.
Parent parent1 = em.find(Parent.class, id);
parent1.getChildren().remove(0);//자식 엔티티를 컬렉션에서 제거
//DELETE FROM CHILD WHERE ID=?
참조하는 곳이 하나일 때 사용해야 한다.
특정 엔티티가 개인 소유할 때 사용해야 한다.
@Entity
public class Parent {
@Id @GeneratedValue
private Long id;
private String name;
@OneToMany(mappedBy = "parent", cascade = CascadeType.ALL, orphanRemoval = true) //영속성 전이 설정, 고아객체 삭제 설정
private List<Child> childList = new ArrayList<>();
public void addChild(Child child) {
childList.add(child);
child.setParent(this);
}
//getter and setter...
}
@Entity
public class Child {
@Id
@GeneratedValue
private Long id;
private String name;
@ManyToOne
@JoinColumn(name = "parent_id")
private Parent parent;
//getter and setter...
}
Child child1 = new Child();
Child child2 = new Child();
Parent parent = new Parent();
parent.addChild(child1);
parent.addChild(child2);
em.persist(parent);
em.flush();
em.clear();
Parent findParent = em.find(Parent.class, parent.getId());
findParent.getChildList().remove(0);
개념적으로 부모를 제거하면 자식은 고아가 된다.
따라서 고아 객체 제거 기능을 활성화 하면, 부모를 제거할 때 자식도 함께 제거된다.
이것은 CascadeType.REMOVE처럼 동작한다.
CascadeType.ALL + orphanRemoval=true
두 옵션을 모두 활성화 하면 부모 엔티티를 통해서 자식의 생명주기를 관리할 수 있다.
쉽게 설명하면, 부모 엔티티는 영속성 컨텍스트를 통해 관리되지만, 자식 엔티티는 영속성 컨텍스트가 아닌 부모 엔티티를 통해서 관리되는 것 처럼 보이는 것이다
'Java Category > JPA' 카테고리의 다른 글
| [JPA] JPQL 기본 문법 (0) | 2024.07.29 |
|---|---|
| [JPA] 값 타입(Value Type) (0) | 2024.07.28 |
| [JPA] 프록시(Proxy) (0) | 2024.07.26 |
| [JPA] 상속관계 매핑 (0) | 2024.07.25 |
| [JPA] 다양한 연관관계 매핑 (5) | 2024.07.24 |