엔티티의 기본키가 자바의 기본 타입이 아니라 String 등이고, 식별자(기본키)가 null 이면 영속성 컨텍스트에서 관리하지 않는 새로운 객체라고 판단한다.
이 때, 주의를 해야하는 점이 있다.
데이터베이스에서 자동으로 식별자를 지정해주는 전략이 아니라 애플리케이션에서 자체적으로 식별자를 지정해주는 전략이라면 새로운 엔티티가 생성될 때, persist가 아니라 merge가 작동하게 된다.
따라서 영속성 컨텍스트는 데이터베이스에서 데이터를 조회하게 되고, DB에 데이터가 없다는 것을 뒤 늦게 알고 그제서야 새로운 객체로 판단하게 된다.
JPA 식별자 생성 전략이 @Id 만 사용해서 직접 할당이면 이미 식별자 값이 있는 상태로 save() 를 호출한다. 따라서 이 경우 merge() 가 호출된다. merge() 는 우선 DB를 호출해서 값 을 확인하고, DB에 값이 없으면 새로운 엔티티로 인지하므로 매우 비효율적이다. 따라서 Persistable 를 사용해서 새로운 엔티티 확인 여부를 직접 구현하게는 효과적이다.
식별자가 자바 기본 타입일 때 0으로 판단
int 나 long 등 자바의 기본 타입이라면 초기화를 하지 않았다면 기본적으로 0으로 세팅되어있다.
따라서 엔티티의 식별자가 0이면 영속성 컨텍스트에서 관리하지 않는 새로운 객체라고 판단한다.
@Entity
public class Item {
@Id @GeneratedValue
private Long id;
}
식별자 생성 전략이 @GenerateValue 면 save() 호출 시점에 식별자가 없으므로 새로운 엔티티 로 인식해서 정상 동작
Persistable 인터페이스를 구현
등록시간( @CreatedDate )을 조합해서 사용하면 이 필드로 새로운 엔티티 여부를 편리하게 확인할 수 있다.
(@CreatedDate에 값이 없으면 새로운 엔티티로 판단)
Persistable 인터페이스
package org.springframework.data.domain;
public interface Persistable<ID> {
ID getId();
boolean isNew();
}
Persistable 구현
@Entity
@EntityListeners(AuditingEntityListener.class)
@NoArgsConstructor(access = AccessLevel.PROTECTED)
public class Item implements Persistable<String> {
@Id
private String id;
@CreatedDate
private LocalDateTime createdDate;
public Item(String id) {
this.id = id;
}
@Override
public String getId() {
return id;
}
@Override
public boolean isNew() {
return createdDate == null; //생성 시간이 null이면 새로운 객체로 판단하도록 유도
}
}
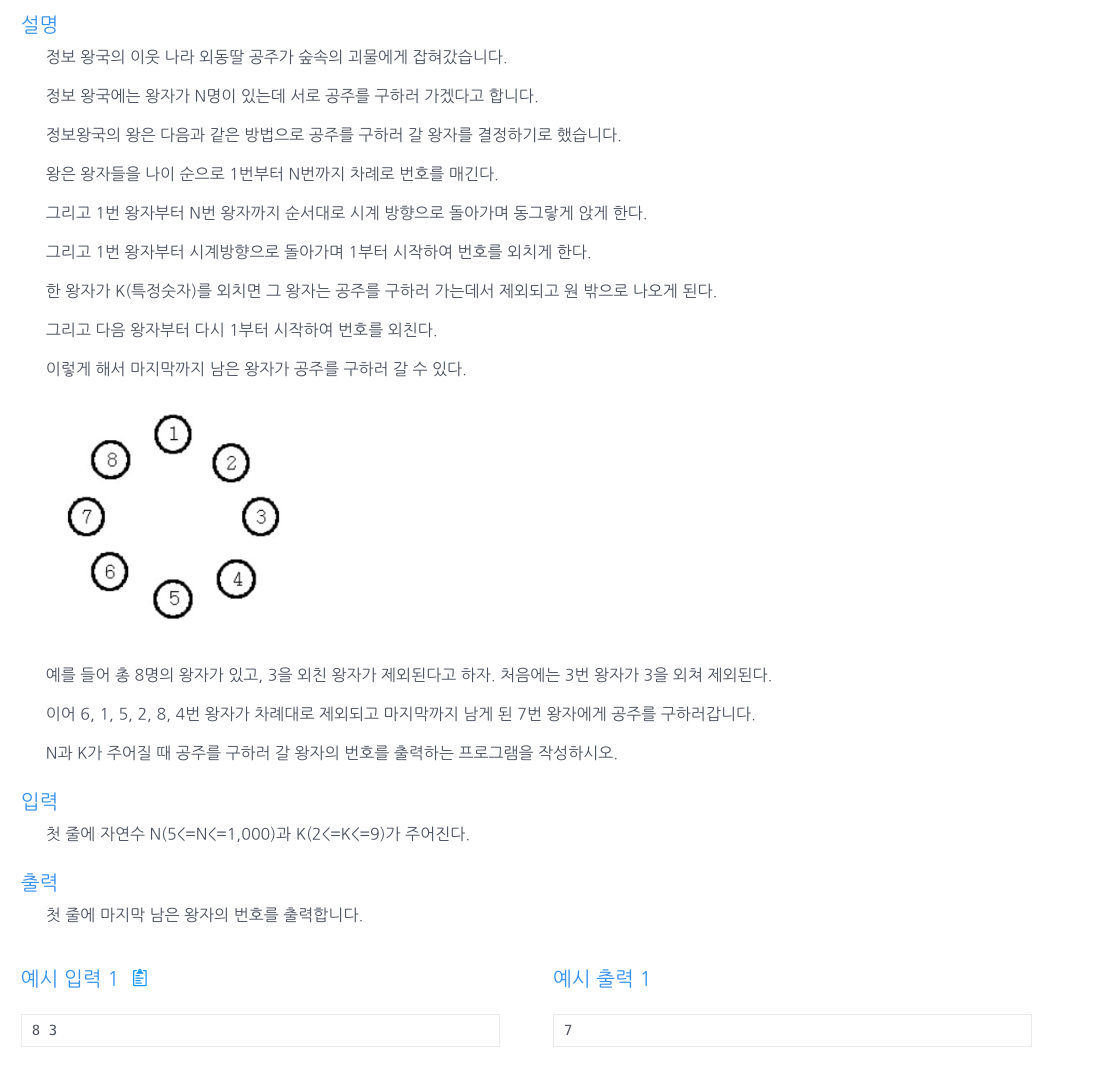
이 알고리즘 문제는 인프런의 자바(Java) 알고리즘 문제풀이 입문: 코딩테스트 대비 (김태원)의 문제입니다.
문제 설명
코드
첫 번째 코드(시간 복잡도 O(N^2))
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.*;
public class sec05_08 {
public static class Person
{
private int priority;
private int idx;
Person(int priority, int idx)
{
this.priority = priority;
this.idx = idx;
}
}
public static int solution(int N, int M, int[] arr)
{
Queue<Person> queue = new LinkedList<>();
for (int i = 0; i < N; ++i) queue.offer(new Person(arr[i], i));
int count = 0;
while (!queue.isEmpty())
{
Person current = queue.poll();
boolean hasHigherPriority = false;
for (Person person : queue) {
if (person.priority > current.priority)
{
hasHigherPriority = true;
break;
}
}
if (hasHigherPriority) queue.offer(current);
else
{
count++;
if (current.idx == M) return count;
}
}
return count;
}
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
StringTokenizer st = new StringTokenizer(br.readLine());
int N = Integer.parseInt(st.nextToken());
int M = Integer.parseInt(st.nextToken());
st = new StringTokenizer(br.readLine());
int[] arr = new int[N];
for (int i = 0; i < N; ++i) arr[i] = Integer.parseInt(st.nextToken());
System.out.println(solution(N, M, arr));
}
}
두 번째 코드(시간 복잡도 개선 O(N log N))
package inflearn_algorithm.chapter5;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.*;
public class sec05_08 {
public static class Person
{
private int priority;
private int idx;
Person(int priority, int idx)
{
this.priority = priority;
this.idx = idx;
}
}
public static int solution(int N, int M, int[] arr)
{
Queue<Person> que = new LinkedList<>();
PriorityQueue<Integer> pq = new PriorityQueue<>(Collections.reverseOrder());
for (int i = 0; i < N; ++i)
{
que.offer(new Person(arr[i], i));
pq.offer(arr[i]);
}
int count = 0;
while (!que.isEmpty())
{
Person current = que.poll();
if (current.priority == pq.peek())
{
count++;
pq.poll();
if (current.idx == M) return count;
}
else que.offer(current);
}
return count;
}
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
StringTokenizer st = new StringTokenizer(br.readLine());
int N = Integer.parseInt(st.nextToken());
int M = Integer.parseInt(st.nextToken());
st = new StringTokenizer(br.readLine());
int[] arr = new int[N];
for (int i = 0; i < N; ++i) arr[i] = Integer.parseInt(st.nextToken());
System.out.println(solution(N, M, arr));
}
}
설명
첫 번째 코드 설명
큐에서 환자를 하나씩 꺼내어(poll) 현재 큐에 남아 있는 다른 환자들과 우선순위를 비교한다.
만약 현재 환자보다 우선순위가 높은 다른 환자가 있으면, 현재 환자를 다시 큐의 뒤로 넣는다.
그렇지 않으면 현재 환자를 진료하고(count 증가), 이 환자가 목표로 한 환자(M)인지 확인한다. 만약 맞다면, 현재까지의 count 값을 반환하여 몇 번째로 진료를 받았는지 결과를 돌려준다.
두 번째 코드 설명
Queue<Person> que에 모든 환자를 입력 순서대로 추가한다.
PriorityQueue<Integer> pq는 환자의 우선순위를 내림차순으로 저장하여, 항상 가장 높은 우선순위를 빠르게 조회할 수 있게 한다.
큐에서 환자를 하나씩 꺼내어(poll), 그 환자의 우선순위가 현재 대기 중인 환자들 중 가장 높은지 확인한다(pq.peek()).
만약 가장 높은 우선순위라면 그 환자는 진료를 받게 되고(count 증가), 우선순위 큐에서도 해당 우선순위를 제거한다(pq.poll()).
목표 환자(M)가 진료를 받게 되면 그때까지의 count를 반환하여 몇 번째로 진료를 받았는지를 반환한다.
만약 현재 환자가 가장 높은 우선순위가 아니라면 큐의 끝으로 다시 보내서 나중에 다시 확인하도록 한다.
이 글은 인프런 김영한님의 Spring 강의를 바탕으로 개인적인 정리를 위해 작성한 글입니다.
사용자 정의 리포지토리
사용자 정의 인터페이스
public interface MemberRepositoryCustom {
List<Member> findMemberCustom();
}
사용자 정의 인터페이스 구현 클래스
@RequiredArgsConstructor
public class MemberRepositoryCustomImpl implements MemberRepositoryCustom {
private final EntityManager em;
@Override
public List<Member> findMemberCustom() {
return em.createQuery("select m from Member m", Member.class)
.getResultList();
}
}
규칙: 사용자 정의 인터페이스 이름(리포지토리 인터페이스 이름도 가능) + Impl
스프링 데이터 JPA가 인식해서 스프링 빈으로 등록
사용자 정의 인터페이스 상속
public interface MemberRepository extends JpaRepository<Member, Long>, MemberRepositoryCustom {
}
사용자 정의 메서드 호출 코드
List<Member> result = memberRepository.findMemberCustom();
실무에서는 주로 QueryDSL이나 SpringJdbcTemplate을 함께 사용할 때 사용자 정의 리포지토리 기능 자주 사용
항상 사용자 정의 리포지토리가 필요한 것은 아니다. 그냥 임의의 리포지토리를 만들어도 된다. 예를들어 MemberQueryRepository를 인터페이스가 아닌 클래스로 만들고 스프링 빈으로 등록해서 그냥 직접 사용해도 된다. 물론 이 경우 스프링 데이터 JPA와는 아무런 관계 없이 별도로 동작한다.
Auditing
엔티티를 생성 및 변경할 때 변경한 사람과 시간을 추적하고 싶을 때 쓰는 기능
(등록일, 수정일, 등록자, 수정자 등)
@EnableJpaAuditing //Auditing
@SpringBootApplication
public class DataJpaApplication {
public static void main(String[] args) {
SpringApplication.run(DataJpaApplication.class, args);
}
//Auditing
@Bean
public AuditorAware<String> auditorProvider() {
return () -> Optional.of(UUID.randomUUID().toString()); //UUID
//실무에선 세션에서 가져오거나, 스프링 시큐리티에서 가져와야 한다.
}
}
@EnableJpaAuditing
auditorProvider() 메서드 등록(등록자와 수정자를 처리해줌)
@EnableJpaAuditing
이 어노테이션은 JPA 엔티티에 대해 자동으로 @CreatedDate, @LastModifiedDate, @CreatedBy, @LastModifiedBy 같은 어노테이션을 사용해 엔티티의 생성 및 수정 시간을 자동으로 관리할 수 있게 한다.
이를 사용하려면, JpaAuditing 기능을 활성화하기 위해 스프링 부트 애플리케이션 클래스나 설정 클래스에 @EnableJpaAuditing을 추가해야 한다.
실무에서 대부분의 엔티티는 등록시간, 수정시간이 필요하지만, 등록자, 수정자는 없을 수도 있다.
그래서 다음과 같이 Base 타입을 분리하고, 원하는 타입을 선택해서 상속하면 된다.
public class BaseTimeEntity {
@CreatedDate
@Column(updatable = false)
private LocalDateTime createdDate;
@LastModifiedDate
private LocalDateTime lastModifiedDate;
}
public class BaseEntity extends BaseTimeEntity { //상속
@CreatedBy
@Column(updatable = false)
private String createdBy;
@LastModifiedBy
private String lastModifiedBy;
}
저장시점에 등록일, 등록자는 물론이고, 수정일, 수정자도 같은 데이터가 저장된다. 데이터가 중복 저장되는 것 같지만, 이렇게 해두면 변경 컬럼만 확인해도 마지막에 업데이트한 유저를 확인할 수 있으므로 유지보수 관점 에서 편리하다. 이렇게 하지 않으면 변경 컬럼이 null 일때 등록 컬럼을 또 찾아야 한다.
저장시점에 저장데이터만 입력하고 싶으면 @EnableJpaAuditing(modifyOnCreate = false) 옵션을 사용하면 된다.
기본적으로 @EnableJpaAuditing은 엔티티가 처음 생성될 때(@PrePersist 시점)에 @LastModifiedDate 필드도 함께 설정되도록 되어 있다.
그러나 modifyOnCreate = false를 설정하면, 엔티티가 처음 생성될 때는 @LastModifiedDate 필드를 설정하지 않는다. 즉, 생성 시에는 수정 시간이 기록되지 않고, 이후 엔티티가 업데이트될 때만 @LastModifiedDate 필드가 변경된다.
페이징과 정렬(Web 확장)
스프링 데이터가 제공하는 페이징과 정렬 기능을 스프링 MVC에서 편리하게 사용할 수 있다.
public String list(
@Qualifier("member") Pageable memberPageable,
@Qualifier("order") Pageable orderPageable, ...
DTO로 변환
엔티티를 API로 노출하면 다양한 문제가 발생한다. 그래서 엔티티를 꼭 DTO로 변환해서 반환해야 한다.
Page는 map() 을 지원해서 내부 데이터를 다른 것으로 변경할 수 있다.
@Data
public class MemberDto {
private Long id;
private String username;
public MemberDto(Member m) {
this.id = m.getId();
this.username = m.getUsername();
}
}
스프링 데이터 JPA를 사용하면 실무에서 Named Query를 직접 등록해서 사용하는 일은 드물다. 대신 @Query 를 사용해서 리파지토리 메소드에 쿼리를 직접 정의한다.
@Query
리포지토리 메소드에 쿼리 정의하기
public interface MemberRepository extends JpaRepository<Member, Long> {
@Query("select m from Member m where m.username= :username and m.age = :age")
List<Member> findUser(@Param("username") String username, @Param("age") int age);
}
List<Member> result = memberRepository.findUser("AAA", 10);
@org.springframework.data.jpa.repository.Query 어노테이션을 사용 실행할 메서드에 정적 쿼리를 직접 작성하므로 이름 없는 Named 쿼리라 할 수 있음
JPA Named 쿼리처럼 애플리케이션 실행 시점에 문법 오류를 발견할 수 있음
값, DTO 조회하기
단순히 컬럼 하나를 조회
@Query("select m.username from Member m")
List<String> findUsernameList();
JPA 값 타입( @Embedded )도 이 방식으로 조회할 수 있다.
DTO로 직접 조회
@Data
public class MemberDto {
private Long id;
private String username;
private String teamName;
public MemberDto(Long id, String username, String teamName) {
this.id = id;
this.username = username;
this.teamName = teamName;
}
}
@Query("select new study.datajpa.dto.MemberDto(m.id, m.username, t.name) from Member m join m.team t")
List<MemberDto> findMemberDto();
select m from Member m where m.username = ?0 --위치 기반
select m from Member m where m.username = :name --이름 기반
import org.springframework.data.repository.query.Param
public interface MemberRepository extends JpaRepository<Member, Long> {
@Query("select m from Member m where m.username = :name")
Member findMembers(@Param("name") String username);
}
Member findMember = memberRepository.findMembers("AAA");
코드 가독성과 유지보수를 위해 이름 기반 파라미터 바인딩을 사용해야 한다.
컬렉션 바인딩
Collection 타입으로 in절 지원
@Query("select m from Member m where m.username in :names")
List<Member> findByNames(@Param("names") List<String> names);
List<Member> result = memberRepository.findByNames(Arrays.asList("AAA", "BBB"));
단건으로 지정한 메서드를 호출하면 스프링 데이터 JPA는 내부에서 JPQL의 Query.getSingleResult() 메서드를 호출한다. 이 메서드를 호출했을 때 조회 결과가 없으면 javax.persistence.NoResultException 예외가 발생하는데 개발자 입장에서 다루기가 상당히 불편하다. 스프링 데이터 JPA는 단건을 조회할 때 이 예외가 발생하면 예외를 무시하고 대신에 null 을 반환한다.
페이징과 정렬
페이징과 정렬 파라미터
org.springframework.data.domain.Sort : 정렬 기능
org.springframework.data.domain.Pageable : 페이징 기능 (내부에 Sort 포함)
Sort
Sort는 데이터베이스 쿼리 결과를 특정 필드 기준으로 정렬할 때 사용된다. 정렬 기준은 필드명과 정렬 방향(오름차순 또는 내림차순)을 지정하여 정의한다.
Sort.by(String... properties): 정렬할 필드를 지정한다.
Sort.Order.asc(String property): 특정 필드를 오름차순으로 정렬한다.
Sort.Order.desc(String property): 특정 필드를 내림차순으로 정렬한다.
Pageable은 페이징 처리와 관련된 정보를 캡슐화하는 인터페이스로, 페이지 번호, 페이지 크기(한 페이지에 표시할 데이터 수), 그리고 정렬 정보를 포함한다.
Pageable 인터페이스는 PageRequest 클래스와 함께 자주 사용되며, 정렬 정보는 Sort 객체로 제공된다.
(int) getPageNumber(): 현재 페이지 번호를 반환한다.
(int) getPageSize(): 한 페이지에 표시할 데이터 수를 반환한다.
(Sort) getSort(): 정렬 정보를 반환한다.
PageRequest.of(int page, int size): 특정 페이지와 페이지 크기를 지정하여 Pageable 객체를 생성한다.
PageRequest.of(int page, int size, Sort sort): 특정 페이지, 페이지 크기, 정렬 정보를 함께 지정하여 Pageable 객체를 생성한다.
Page는 1부터 시작이 아니라 0부터 시작
특별한 반환 타입(Page, Slice)
org.springframework.data.domain.Page : 추가 count 쿼리 결과를 포함하는 페이징
org.springframework.data.domain.Slice : 추가 count 쿼리 없이 다음 페이지만 확인 가능(내부적으로 limit + 1조회)
List (자바 컬렉션): 추가 count 쿼리 없이 결과만 반환
요약
Page: 페이징된 결과와 함께 전체 데이터 개수(count)를 얻고 싶은 경우에 사용.
Slice: 다음 페이지가 있는지 여부만 확인하고, 전체 데이터 개수는 필요하지 않을 때 사용.
List: 단순히 페이징 없이 데이터를 조회할 때 사용.
Page
public interface Page<T> extends Slice<T> {
int getTotalPages(); //전체 페이지 수
long getTotalElements(); //전체 데이터 수
<U> Page<U> map(Function<? super T, ? extends U> converter); //변환기
}
Page는 페이징된 결과와 함께 전체 데이터 개수를 제공한다.
이는 페이징된 데이터를 가져올 때, 전체 데이터 수를 계산하는 count 쿼리가 추가로 실행된다는 의미이다.
이 count 쿼리를 통해 전체 페이지 수, 현재 페이지, 총 항목 수 등의 메타데이터를 제공받을 수 있다.
장점: 페이징된 결과를 제공하면서도 전체 데이터 수와 관련된 추가 정보를 얻을 수 있어, 전체 페이지 수나 현재 페이지가 몇 번째인지 등의 정보를 쉽게 파악할 수 있다.
단점: 추가적인 count 쿼리가 실행되기 때문에 성능에 영향을 줄 수 있다.
Page<Member> members = memberRepository.findByAge(25, PageRequest.of(0, 10));
int totalPages = members.getTotalPages();
long totalElements = members.getTotalElements();
Slice
public interface Slice<T> extends Streamable<T> {
int getNumber(); //현재 페이지
int getSize(); //페이지 크기
int getNumberOfElements(); //현재 페이지에 나올 데이터 수
List<T> getContent(); //조회된 데이터
boolean hasContent(); //조회된 데이터 존재 여부
Sort getSort(); //정렬 정보
boolean isFirst(); //현재 페이지가 첫 페이지인지 여부
boolean isLast(); //현재 페이지가 마지막 페이지인지 여부
boolean hasNext(); //다음 페이지 존재 여부
boolean hasPrevious(); //이전 페이지 존재 여부
Pageable getPageable(); //페이지 요청 정보
Pageable nextPageable(); //다음 페이지 객체
Pageable previousPageable();//이전 페이지 객체
<U> Slice<U> map(Function<? super T, ? extends U> converter); //변환기
}
Slice는 Page와 비슷하지만, 추가적인 count 쿼리를 실행하지 않는다.
대신, 다음 페이지가 있는지 여부만을 확인하기 위해 limit + 1의 데이터를 조회한다. 이를 통해 다음 페이지가 존재하는지 여부를 확인할 수 있다.
장점: count 쿼리가 없기 때문에 성능이 더 좋다. 필요한 데이터만 가져오고, 다음 페이지가 있는지 여부만을 확인하고 싶을 때 적합하다.
단점: 전체 페이지 수나 전체 데이터 수에 대한 정보가 제공되지 않는다.
Slice<Member> members = memberRepository.findByAge(25, PageRequest.of(0, 10));
boolean hasNext = members.hasNext(); // 다음 페이지가 있는지 여부
List
List는 페이징 처리가 전혀 없는, 단순한 데이터 목록을 반환한다.
Spring Data JPA에서 페이징이나 슬라이싱을 사용하지 않고, 그냥 데이터만 반환받고 싶을 때 사용된다.
장점: count 쿼리나 추가적인 메타데이터 처리가 없으므로 가장 간단하고 빠르다.
단점: 페이징 관련 정보가 전혀 제공되지 않는다.
List<Member> members = memberRepository.findByAge(25);
Page 타입을 반환하기 때문에, 전체 데이터의 수를 계산하는 추가적인 count 쿼리가 실행된다.
전체 페이지 수, 현재 페이지, 총 항목 수 등의 메타데이터를 포함하는 Page 객체를 반환한다.
count 쿼리가 추가로 실행되어 전체 데이터 수를 계산한다.
Page<Member> result = memberRepository.findByUsername("John", PageRequest.of(0, 10));
int totalPages = result.getTotalPages();
long totalElements = result.getTotalElements();
List<Member> members = result.getContent(); // 실제 데이터 리스트
이 메서드는 주어진 username에 해당하는 멤버들을 페이징하여 반환하지만, Slice 타입을 반환하기 때문에 추가적인 count 쿼리를 실행하지 않는다.
대신, 다음 페이지가 있는지 여부만 확인하기 위해 limit + 1 개의 데이터를 조회한다.
전체 데이터 수나 전체 페이지 수에 대한 정보는 제공되지 않는다.
다음 페이지가 있는지 여부만 알 수 있다.
성능상 이점이 있다(추가 count 쿼리가 없기 때문).
Slice<Member> result = memberRepository.findByUsername("John", PageRequest.of(0, 10));
boolean hasNext = result.hasNext(); // 다음 페이지가 있는지 여부
List<Member> members = result.getContent(); // 실제 데이터 리스트
//페이징 조건과 정렬 조건 설정
@Test
public void page() throws Exception {
//given
memberRepository.save(new Member("member1", 10));
memberRepository.save(new Member("member2", 10));
memberRepository.save(new Member("member3", 10));
memberRepository.save(new Member("member4", 10));
memberRepository.save(new Member("member5", 10));
//when
PageRequest pageRequest = PageRequest.of(0, 3, Sort.by(Sort.Direction.DESC, "username"));
Page<Member> page = memberRepository.findByAge(10, pageRequest);
//then
List<Member> content = page.getContent(); //조회된 데이터
assertThat(content.size()).isEqualTo(3); //조회된 데이터 수
assertThat(page.getTotalElements()).isEqualTo(5); //전체 데이터 수
assertThat(page.getNumber()).isEqualTo(0); //페이지 번호
assertThat(page.getTotalPages()).isEqualTo(2); //전체 페이지 번호
assertThat(page.isFirst()).isTrue(); //첫번째 항목인가?
assertThat(page.hasNext()).isTrue(); //다음 페이지가 있는가?
}
두 번째 파라미터로 받은 Pageable 은 인터페이스다. 따라서 실제 사용할 때는 해당 인터페이스를 구현한 org.springframework.data.domain.PageRequest 객체를 사용한다.
PageRequest 생성자의 첫 번째 파라미터에는 현재 페이지를, 두 번째 파라미터에는 조회할 데이터 수를 입력한다. 여기에 추가로 정렬 정보도 파라미터로 사용할 수 있다. 참고로 페이지는 0부터 시작한다.
@Query 어노테이션을 사용하여 사용자 정의 쿼리를 작성할 때, 페이징된 결과와 함께 count 쿼리를 명시적으로 지정할 수 있다. 이를 통해 데이터를 조회하는 쿼리와 전체 데이터 개수를 계산하는 쿼리를 각각 다르게 지정할 수 있다.
@Query(value = "select m from Member m",
countQuery = "select count(m.username) from Member m")
Page<Member> findMemberAllCountBy(Pageable pageable);
value: 실제 데이터를 조회하는 JPQL 쿼리를 지정한다. • value = "select m from Member m"은 Member 엔티티의 모든 레코드를 가져오는 쿼리이다.
countQuery: 페이징 처리를 위해 전체 데이터 수를 계산하는 count 쿼리를 지정한다. • countQuery = "select count(m.username) from Member m"은 Member 엔티티의 username 필드를 기준으로 전체 레코드 수를 계산하는 쿼리이다. • 일반적으로는 count(m)을 사용하지만, 여기서는 count(m.username)을 사용하고 있다. 하지만, 두 쿼리의 결과는 동일하다. countQuery는 페이징 처리에서 전체 페이지 수를 계산하기 위해 사용된다.
Page<Member> findMemberAllCountBy(Pageable pageable); • 반환 타입이 Page<Member>인 메서드로, 페이징된 결과를 반환한다. • Pageable pageable 인자를 통해 페이지 번호, 페이지 크기, 정렬 조건 등을 전달할 수 있다. • Page 객체는 페이징된 데이터 리스트와 함께 전체 데이터 개수, 총 페이지 수, 현재 페이지 번호 등의 정보를 포함한다.
이 알고리즘 문제는 인프런의 자바(Java) 알고리즘 문제풀이 입문: 코딩테스트 대비 (김태원)의 문제입니다.
문제 설명
코드
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.LinkedList;
import java.util.Queue;
import java.util.StringTokenizer;
public class Main {
public static int solution(int N, int K) {
Queue<Integer> que = new LinkedList<>();
for(int i = 1; i <= N; ++i) que.add(i);
int count = 0;
while(que.size() > 1)
{
++count;
if(count == K)
{
que.poll();
count = 0;
}
else que.add(que.poll());
}
return que.poll();
}
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
StringTokenizer st = new StringTokenizer(br.readLine());
int N = Integer.parseInt(st.nextToken());
int K = Integer.parseInt(st.nextToken());
System.out.println(solution(N, K));
}
}
설명
이 문제는 요세푸스 문제라고 불린다.
count 변수를 초기화하여 사람을 제거할 때까지의 카운트를 유지한다.
while(que.size() > 1) 루프는 큐에 한 명만 남을 때까지 반복된다.
++count;를 통해 카운트를 증가시킨다.
if(count == K)에서 카운트가 K와 같아지면, que.poll();을 통해 큐의 첫 번째 요소(즉, 현재 사람)를 제거하고, count를 0으로 초기화한다.
else que.add(que.poll());에서 카운트가 K와 같지 않은 경우, 현재 사람을 큐의 뒤로 이동시킨다. 이때, poll()로 큐의 첫 번째 요소를 제거한 후, 그 요소를 다시 add()로 큐의 끝에 추가한다.
add() 메서드와 offer() 메서드 차이
1. 예외 처리 방식의 차이 -add() 메서드: 큐의 용량 제한을 초과하거나 다른 이유로 요소를 추가할 수 없을 때 IllegalStateException을 던진다. 즉, add()는 요소를 큐에 추가하는 작업이 실패할 경우 예외를 발생시키며, 이를 통해 실패 원인을 알 수 있게 한다. -offer() 메서드: offer()는 큐의 용량 제한을 초과하거나 다른 이유로 요소를 추가할 수 없을 때 false를 반환한다. 예외를 던지지 않고, boolean 값을 반환하여 추가가 성공했는지 여부를 확인할 수 있다.
2. 메서드 반환 타입 -add(): 반환 타입은 boolean이다. 요소가 정상적으로 추가되면 true를 반환한다. 다만, 이 메서드는 큐가 용량을 초과할 경우 예외를 던지기 때문에, 반환값을 사용하는 경우는 드물다. -offer(): 반환 타입도 boolean이다. 추가가 성공하면 true, 실패하면 false를 반환한다.
3. 사용 의도 -add(): 주로 큐가 용량 제한이 없거나, 특정 조건에 대해 강력한 에러 처리를 요구하는 경우 사용한다. -offer(): 주로 큐가 용량 제한이 있거나, 큐가 꽉 찼을 때도 예외를 던지지 않고 부드럽게 실패 처리를 하고자 할 때 사용한다.
이 글은 인프런 김영한님의 Spring 강의를 바탕으로 개인적인 정리를 위해 작성한 글입니다.
Spring Data JPA는 스프링 프레임워크에서 제공하는 데이터 접근 계층(Data Access Layer)을 쉽게 구현할 수 있도록 지원하는 모듈이다.
JPA(Java Persistence API)를 사용하여 데이터베이스와의 상호작용을 단순화하고, 보일러플레이트 코드를 최소화하는 데 중점을 둔다.
레포지토리 추상화
Spring Data JPA는 JPA 엔티티를 관리하기 위한 기본적인 CRUD(Create, Read, Update, Delete) 작업을 자동으로 생성해주는 레포지토리 인터페이스를 제공한다.
JpaRepository, CrudRepository, PagingAndSortingRepository와 같은 기본 인터페이스를 확장하면, 수동으로 구현하지 않고도 대부분의 데이터 접근 작업을 처리할 수 있다.
제네릭은 <엔티티 타입, 식별자 타입> 설정
import org.springframework.data.jpa.repository.JpaRepository;
public interface ItemRepository extends JpaRepository<Item, Long> { //제네릭은 <엔티티 타입, 식별자 타입> 설정
}
이 인터페이스만 정의하면, Spring Data JPA는 기본적인 CRUD 메서드(예: save, findById, findAll, deleteById 등)를 자동으로 구현한다.
쿼리 메서드 생성
Spring Data JPA는 메서드 이름을 기반으로 쿼리를 자동으로 생성할 수 있다.
예를 들어, findByUsername이라는 메서드를 정의하면, Spring Data JPA는 이 메서드를 호출하여 username 필드를 기반으로 데이터를 조회하는 쿼리를 생성한다.
public interface MemberRepository extends JpaRepository<Member, Long> { //제네릭은 <엔티티 타입, 식별자 타입> 설정
List<Member> findByUsername(String username);
}
여기서 findByUsername 메서드는 username 필드 값을 기준으로 Member 엔티티를 조회하는 SQL 쿼리를 자동으로 생성한다.
JPQL 및 네이티브 쿼리 지원
복잡한 쿼리가 필요한 경우, @Query 어노테이션을 사용하여 JPQL(Java Persistence Query Language) 또는 네이티브 SQL 쿼리를 직접 정의할 수 있다.
import org.springframework.data.jpa.repository.Query;
import org.springframework.data.repository.query.Param;
public interface MemberRepository extends JpaRepository<Member, Long> {
@Query("SELECT m FROM Member m WHERE m.username = :username AND m.age = :age")
List<Member> findUser(@Param("username") String username, @Param("age") int age);
}
이 예제는 username과 age를 매개변수로 받아 특정 조건에 맞는 Member를 조회하는 JPQL 쿼리를 정의한 것이다.
페이징 및 정렬 기능
Spring Data JPA는 페이징과 정렬 기능을 쉽게 구현할 수 있도록 지원한다.
메서드에 Pageable 또는 Sort 파라미터를 추가하면 자동으로 페이징 및 정렬된 결과를 제공한다.