이 글은 인프런의 개발자를 위한 쉬운도커(데브위키) 강의를 수강하고 개인적으로 정리하는 글임을 알립니다.
도커 이미지
이미지는 애플리케이션을 실행하기 위한 모든 파일, 라이브러리, 설정을 미리 포함한 패키지라고 생각하면 된다. 이미지는 변하지 않는 읽기 전용 파일 시스템으로 구성되며, 이를 기반으로 컨테이너를 생성하고 실행한다.
도커의 이미지는 애플리케이션과 그 실행에 필요한 모든 요소를 포함한 애플리케이션 실행 패키지이다.
이미지는 읽기 전용으로 유지되며, 컨테이너를 생성할 때 이 이미지를 기반으로 애플리케이션을 실행한다.
여러 계층으로 구성되어 있어 효율적으로 관리할 수 있으며, 이미지를 공유하고 재사용할 수 있다.
애플리케이션 패키지
이미지에는 특정 애플리케이션을 실행하기 위해 필요한 모든 것이 들어 있다. 예를 들어, 애플리케이션 코드, 라이브러리, 환경 설정 파일, OS 파일 등이 포함된다.
예시: 이미지에는 파이썬 애플리케이션을 실행하기 위해 파이썬 해석기와 해당 애플리케이션 코드가 포함될 수 있다.
읽기 전용
도커 이미지는 읽기 전용(Read-Only)이다. 이미지를 기반으로 컨테이너가 생성되면, 컨테이너는 해당 이미지를 복사하여 실행하지만, 이미 자체는 변경되지 않는다.
계층 구조
도커 이미지는 여러 계층(layer)으로 구성되어 있으며, 각 계층은 이전 계층 위에 덧붙여진다. 이 덕분에 이미지에서 수정이 필요한 경우 전체를 새로 만드는 것이 아니라 일부 계층만 변경하여 효율적으로 이미지를 관리할 수 있다.
예시: 우분투 기반 이미지 위에 Nginx 웹 서버를 추가하면, 우분투는 이미 있는 계층으로 남아있고, Nginx는 그 위에 새로운 계층으로 추가된다.
컨테이너 생성의 기반
이미지를 사용하면 컨테이너를 쉽게 생성할 수 있다. 이미지를 기반으로 컨테이너를 생성할 때, 컨테이너는 해당 이미지의 사본을 가지고 실행되며, 그 안에서 애플리케이션이 동작한다.
예시: docker run 명령어로 특정 이미지를 사용하여 컨테이너를 실행할 수 있다. 실행된 컨테이너는 이미지의 내용을 그대로 따라가며 동작한다.
공유와 재사용
이미지는 누구나 만들 수 있고, 도커 허브(Docker Hub)와 같은 중앙 저장소에 올려서 다른 사람과 공유할 수 있다. 이미지를 공유하면 모든 사람이 동일한 환경에서 애플리케이션을 실행할 수 있다.
예시: 도커 허브에서 ‘nginx’ 이미지를 내려받아 웹 서버를 실행할 수 있다.
이미지 메타데이터
도커 이미지의 메타데이터는 이미지에 대한 정보를 포함하는 데이터로, 이미지의 구성 요소, 생성 방법, 버전 정보 등을 포함한다. 이 메타데이터는 도커가 이미지와 컨테이너를 효율적으로 관리하고 추적할 수 있도록 도와준다.
Env (Environment Variables, 환경 변수)
Env 필드는 컨테이너 내에서 사용할 환경 변수를 설정하는 데 사용된다. 환경 변수는 애플리케이션이 실행되는 동안 필요한 설정값을 외부에서 유연하게 전달할 수 있도록 도와준다.
사용 목적: 환경 변수를 사용하여 애플리케이션의 설정을 코드 변경 없이 변경할 수 있다. 예를 들어, 데이터베이스 URL, API 키, 포트 번호 등의 값을 환경 변수로 설정하여 컨테이너 실행 시 해당 값을 사용할 수 있다.
설정 방법: Dockerfile에서 ENV 명령어를 사용해 환경 변수를 설정할 수 있다.
# Dockerfile에 환경 변수 설정
ENV APP_ENV=production
ENV DATABASE_URL=mysql://localhost:3306/mydb
위의 예시에서는 APP_ENV와 DATABASE_URL이라는 환경 변수가 설정되며, 해당 값들은 컨테이너가 실행되는 동안 참조될 수 있다.
또한 도커 명령어로 컨테이너를 실행할 때 -e 플래그를 사용하여 환경 변수를 지정할 수도 있다.
docker run -e APP_ENV=production myimage
Cmd (Command, 기본 실행 명령어)
Cmd 필드는 컨테이너가 시작될 때 기본적으로 실행할 명령어를 정의한다. Cmd는 주로 실행할 애플리케이션이나 스크립트를 지정하는데 사용된다.
사용 목적: 도커 이미지는 여러 명령을 실행할 수 있지만, Cmd를 통해 컨테이너가 시작될 때 기본으로 실행해야 할 명령어를 지정한다. 예를 들어, 웹 서버 컨테이너라면 Cmd 필드에 Nginx나 Apache와 같은 서버 실행 명령어를 넣을 수 있다.
설정 방법: Dockerfile에서 CMD 명령어로 설정할 수 있다.
# Dockerfile에서 기본 실행 명령어 설정
CMD ["nginx", "-g", "daemon off;"]
위의 예시에서는 Nginx 웹 서버를 데몬 모드로 실행하지 않고, 포그라운드에서 실행하는 명령어가 설정되어 있다. 컨테이너가 시작되면 Nginx가 기본적으로 실행된다.
Cmd와 Entrypoint의 차이
Cmd는 컨테이너가 시작될 때 기본으로 실행될 명령어를 지정하지만, 도커 명령어로 다른 명령어를 실행하면 Cmd는 무시된다. Entrypoint는 Cmd보다 더 강력한 역할을 하며, Entrypoint에 의해 설정된 명령은 덮어쓸 수 없다. 대신 Cmd는 Entrypoint 명령의 인자로 사용될 수 있다.
요약
-Env 필드는 컨테이너 실행 시 환경 변수를 설정하여 애플리케이션이 유연하게 환경에 따라 동작할 수 있게 한다. -Cmd 필드는 컨테이너가 시작될 때 기본으로 실행할 명령을 지정하며, 특정 명령어가 따로 지정되지 않으면 Cmd에 정의된 명령이 실행된다.
컨테이너
컨테이너는 애플리케이션을 실행하기 위한 가벼운 독립적인 환경이다. 컨테이너는 애플리케이션과 그 애플리케이션이 제대로 실행되기 위한 모든 요소(라이브러리, 설정 파일 등)를 함께 묶어서 제공한다. 쉽게 말해, 컨테이너는 애플리케이션과 실행 환경을 함께 담은 상자라고 생각할 수 있다.
컨테이너는 애플리케이션과 그 실행 환경을 묶어서 제공하는 작은 독립된 공간이다.
다른 애플리케이션과 격리된 상태에서 실행되며, 어디서나 동일한 환경을 제공한다.
가상 머신보다 가볍고 빠르게 실행되며, 리소스 사용 효율이 높다.
애플리케이션을 위한 작은 독립 공간
컨테이너는 애플리케이션이 실행되는 별도의 공간을 제공한다. 이 공간은 다른 애플리케이션과 격리되어 있어, 각각의 애플리케이션이 서로에게 영향을 주지 않고 독립적으로 실행될 수 있다.
예를 들어, A라는 애플리케이션이 필요한 환경과 B라는 애플리케이션이 필요한 환경이 달라도, 각각의 컨테이너에서 서로 독립적으로 실행되기 때문에 문제없이 동작한다.
모든 것을 포함하는 패키지
컨테이너는 해당 애플리케이션이 동작하는 데 필요한 모든 파일(라이브러리, 의존성, 설정 파일 등)을 하나로 묶어서 제공한다. 이를 통해, 어느 환경에서든 동일하게 동작할 수 있다.
예를 들어, 개발자가 로컬 컴퓨터에서 만든 애플리케이션을 컨테이너로 패키징한 후 서버에 옮겨도, 컨테이너는 동일한 환경을 유지하므로 그대로 실행할 수 있다.
가벼운 가상화 기술
컨테이너는 기존의 가상 머신보다 훨씬 가벼운 가상화 기술이다. 가상 머신처럼 전체 운영체제를 설치하지 않고, 호스트 운영체제의 커널을 공유하면서도 각 컨테이너는 격리된 공간에서 실행된다. 덕분에 더 적은 리소스로 더 많은 애플리케이션을 실행할 수 있다.
어디서나 동일한 환경 제공
컨테이너는 한 번 패키징되면 어디서든 실행할 수 있다. 로컬 컴퓨터, 클라우드 서버, 테스트 환경 등 어떤 환경에서도 동일한 컨테이너를 실행할 수 있어 배포와 관리가 매우 편리하다.
예를 들어, 로컬에서 개발한 애플리케이션을 컨테이너로 묶어서 서버에 배포하면, 로컬에서 실행한 것과 같은 환경에서 애플리케이션이 실행된다.
빠른 시작과 종료
컨테이너는 매우 빠르게 시작하고 종료할 수 있다. 가상 머신처럼 운영체제를 부팅하는 시간이 필요하지 않기 때문에, 애플리케이션 실행 속도가 빠르다. 이는 빠른 배포와 롤백에 큰 장점을 제공한다.
컨테이너 라이프 사이클
생성(Created): 컨테이너가 생성되었으나 실행되지 않은 상태.
시작(start): 생성된(Created) 컨테이너를 실행(Running) 상태로 전환하는 명령.
이 글은 인프런의 개발자를 위한 쉬운도커(데브위키) 강의를 수강하고 개인적으로 정리하는 글임을 알립니다.
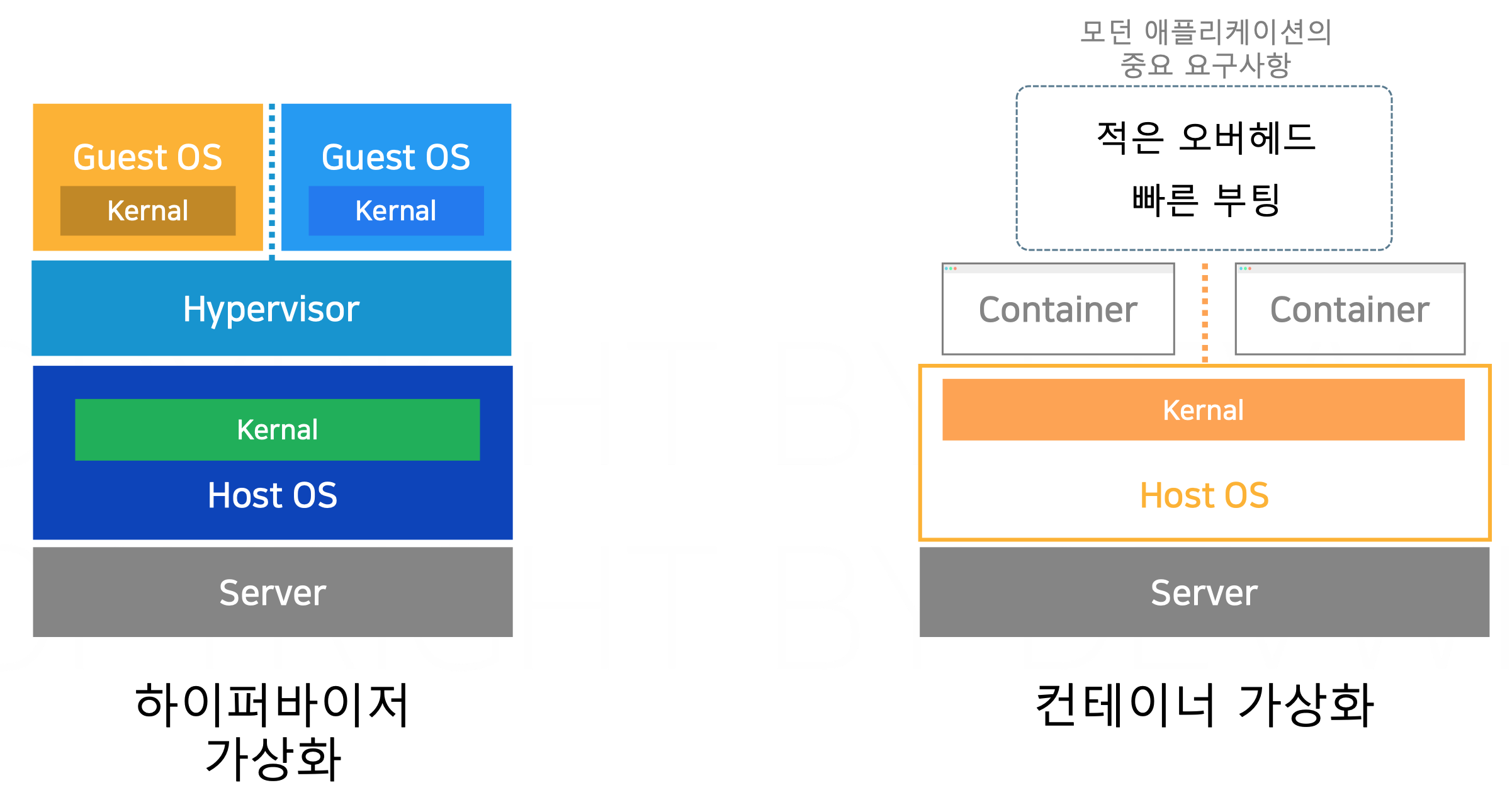
하이퍼바이저 가상화
가상 머신(Virtual Machine)
두 개의 가상 머신이 물리적 서버에서 실행되고 있으며, 각각 리눅스(Linux)와 맥(MacOS) 운영체제를 사용하는 게스트 OS(Guest OS)를 가지고 있다.
가상 머신은 각기 독립적인 프로세스를 실행하고, 리소스(예: CPU, 메모리, 저장공간)를 할당받아 운영된다.
각 게스트 OS는 자체 커널(Kernel)을 가지고 있으며, 사용자 프로세스는 이 커널을 통해 시스템 자원에 접근하게 된다.
하이퍼바이저(Hypervisor)
가상 머신들을 관리하는 소프트웨어 계층이다.
하이퍼바이저는 물리적 서버 자원을 추상화하여 각 가상 머신에 필요한 리소스를 할당하고 관리한다.
게스트 OS 간에는 커널이 독립적이기 때문에, 그림에서 표시된 것처럼 서로 간의 커널 호출은 허용되지 않는다. 즉, 서로의 커널로 직접 접근할 수 없으며, 하이퍼바이저를 통해서만 자원을 요청하거나 할당받는다.
호스트 OS(Host OS)
하이퍼바이저는 호스트 운영체제 위에서 실행되며, 물리적 서버 자원에 접근하고 관리하는 역할을 수행한다.
그림에서 보여지는 호스트 OS는 윈도우(Windows) 기반이다.
서버(Server)
물리적 하드웨어 자원(CPU, RAM, 디스크 등)을 제공하는 실제 서버이다. 이 서버 위에서 하이퍼바이저와 가상 머신들이 운영된다.
전체적인 흐름
각 가상 머신의 프로세스는 시스템 호출(System Call)을 통해 자신의 커널을 거쳐 자원을 요청한다.
자원 사용 요청은 하이퍼바이저를 통해 물리적 서버의 리소스와 연결된다.
각 가상 머신은 독립적으로 운영되며, 하이퍼바이저는 가상 머신 간의 리소스 충돌을 방지하고, 필요한 자원을 관리한다.
컨테이너 가상화
컨테이너 가상화는 하이퍼바이저 가상화에 비해 가볍고 빠르다라는 장점을 가지고 있다.
컨테이너 가상화는 가상 머신(VM)과는 다른 방식으로 가상화된 환경을 제공하는 기술이다. 컨테이너는 응용 프로그램과 그 실행에 필요한 모든 라이브러리, 종속성, 설정 파일 등을 하나의 패키지로 묶어 독립적으로 실행할 수 있게 해준다.
호스트 OS 공유
컨테이너는 호스트 운영체제의 커널을 공유한다. 따라서 각 컨테이너는 별도의 커널을 사용하지 않고, 호스트 커널에서 격리된 환경에서 동작한다.
이는 가상 머신처럼 하이퍼바이저가 물리적 하드웨어를 추상화하고 각 VM에 커널을 할당하는 방식과는 다르다. 즉, 가상 머신에 비해 리소스 사용이 효율적이다.
가벼움(Lightweight)
컨테이너는 VM과 달리 게스트 운영체제를 포함하지 않기 때문에 더 가볍고 빠르게 시작할 수 있다. 컨테이너는 수 MB에서 수백 MB 정도의 크기지만, 가상 머신은 수 GB에 달할 수 있다.
컨테이너는 수 초 내에 시작하거나 중단할 수 있어 애플리케이션 배포 및 관리를 매우 빠르게 수행할 수 있다.
격리성(Isolation)
컨테이너는 각기 독립적인 프로세스와 파일 시스템을 가지고 있지만, 호스트 운영체제의 커널을 공유하는 특성 때문에 완전한 하드웨어 격리는 제공하지 않는다.
그러나 네임스페이스(Namespaces)와 cgroups(Control Groups) 기술을 통해 프로세스, 네트워크, 파일 시스템, 메모리, CPU 등 자원들을 서로 격리할 수 있다.
효율적인 자원 사용
하이퍼바이저 기반의 가상 머신에 비해 컨테이너는 더 적은 자원으로 더 많은 애플리케이션을 실행할 수 있다. 여러 컨테이너가 하나의 호스트 커널을 공유하기 때문에 메모리와 CPU 사용량을 줄일 수 있다.
리소스를 동적으로 할당할 수 있어 자원을 보다 효율적으로 사용할 수 있다.
이식성(Portability)
컨테이너는 애플리케이션을 실행하는데 필요한 모든 라이브러리와 종속성을 포함하므로, 한 번 빌드된 컨테이너는 어디서든지 동일하게 실행될 수 있다.
예를 들어, 로컬 개발 환경에서 테스트한 컨테이너를 클라우드나 다른 서버 환경으로 옮겨도 동일한 환경에서 실행이 가능하다.
오케스트레이션 가능
여러 개의 컨테이너를 관리하고 조정할 수 있는 오케스트레이션 도구(예: Kubernetes)를 통해 대규모 애플리케이션을 유연하고 안정적으로 관리할 수 있다.
이를 통해 컨테이너의 배포, 확장, 모니터링 등이 자동화될 수 있다.
보안
컨테이너는 VM에 비해 커널을 공유하기 때문에 이론적으로 더 많은 보안 취약점을 가질 수 있다. 그러나 SELinux, AppArmor 등의 보안 강화 도구를 통해 보안성을 높일 수 있다.
빠른 배포 및 롤백
컨테이너는 애플리케이션 배포 속도가 매우 빠르다. 이미지를 빌드한 후 신속하게 배포할 수 있으며, 문제가 발생하면 이전 버전으로의 롤백도 간단하게 처리할 수 있다.
하이버바이저 가상화와 컨테이너 가상화 비교
아키텍처 구조
하이퍼바이저 가상화: -하이퍼바이저(타입 1 혹은 2)가 물리적 하드웨어를 가상화하여 여러 가상 머신(VM)을 생성하고 관리한다. -각 가상 머신은 자체 운영체제(게스트 OS)를 가지고 있으며, 이 운영체제는 각기 독립적인 커널을 사용한다. -하이퍼바이저는 물리적 서버 자원을 관리하며, 각 가상 머신이 요청하는 자원을 분배한다.
컨테이너 가상화: -컨테이너는 호스트 운영체제의 커널을 공유하며, 각 컨테이너는 애플리케이션과 필요한 라이브러리만을 포함한다. -컨테이너는 하드웨어 가상화가 아닌 OS 수준에서 가상화된다. -네임스페이스와 cgroups 같은 기술을 통해 자원과 프로세스를 격리하지만, 각 컨테이너는 동일한 커널을 사용한다.
운영체제(커널)
하이퍼바이저 가상화: -각 가상 머신은 자체 운영체제(리눅스, 윈도우 등)를 가질 수 있다. 따라서, 서로 다른 운영체제를 한 물리 서버에서 동시에 실행할 수 있다. -각 가상 머신은 독립적인 커널을 실행하므로, 운영체제 간 충돌 없이 격리된 환경을 제공한다.
컨테이너 가상화: -컨테이너는 호스트 운영체제의 커널을 공유하기 때문에, 호스트 OS와 동일한 커널을 사용해야 한다. 예를 들어, 리눅스 기반 호스트에서 윈도우 컨테이너를 실행할 수 없다. -게스트 OS 레벨에서의 격리가 아닌, 애플리케이션과 라이브러리 수준에서의 격리를 제공한다.
자원 효율성
하이퍼바이저 가상화: -각 가상 머신은 별도의 운영체제와 커널을 실행하기 때문에 더 많은 메모리와 CPU 자원을 소비한다. -VM을 시작하는 데 시간이 걸리고, 리소스 사용량이 상대적으로 크다.
컨테이너 가상화: -컨테이너는 호스트 커널을 공유하므로, 운영체제에 관련된 오버헤드가 적어 더 적은 자원으로 많은 애플리케이션을 실행할 수 있다. -매우 빠르게 시작되며(수 초 내), 리소스 사용이 매우 효율적이다.
격리성
하이퍼바이저 가상화: -각 가상 머신은 물리적 하드웨어 수준에서 완전히 격리된 환경을 제공한다. 각 VM은 독립적인 커널과 운영체제를 가지므로, 격리 수준이 높고 보안적 이점이 있다. -게스트 OS가 직접 다른 VM의 자원에 접근할 수 없다.
컨테이너 가상화: -컨테이너는 OS 수준에서 격리되지만, 커널을 공유하므로 하이퍼바이저 가상화보다 격리 수준이 낮다. -네임스페이스와 cgroups로 격리되지만, 보안 문제나 커널 공유로 인한 취약점이 있을 수 있다.
이식성
하이퍼바이저 가상화: -가상 머신은 호스트 운영체제에 관계없이 이식성이 크다. 예를 들어, VM 이미지를 다른 서버로 옮길 수 있고, 다른 하이퍼바이저에서도 실행할 수 있다.
컨테이너 가상화: -컨테이너는 OS와 독립적인 애플리케이션 패키지이므로, 어디서든 동일한 환경에서 실행 가능하다. 컨테이너 이미지를 클라우드, 온프레미스, 로컬 서버 등 다양한 환경에서 동일하게 사용할 수 있다.
운영 및 관리
하이퍼바이저 가상화: -운영체제 자체를 설치하고 관리해야 하므로 복잡하고 관리가 다소 번거롭다. 운영체제 업데이트나 유지보수가 필요하다. -VM은 일반적으로 시스템 리소스를 많이 사용하기 때문에, 가상 머신의 수를 늘리면 자원 관리가 어려워질 수 있다.
컨테이너 가상화: -컨테이너는 더 간단하게 운영되고 관리할 수 있다. 컨테이너 이미지와 오케스트레이션 도구(Kubernetes 등)를 사용하여 자동으로 배포, 확장 및 관리를 할 수 있다. -애플리케이션 수준에서만 관리하면 되므로, 운영체제와 관련된 유지보수 부담이 적다.
보안
하이퍼바이저 가상화: -물리적 하드웨어 수준에서의 격리로 인해 보안 수준이 상대적으로 높다. VM 간 간섭이 없고, VM 자체가 다른 VM의 운영체제나 데이터를 침범할 가능성이 낮다.
컨테이너 가상화: -컨테이너는 호스트 커널을 공유하므로, 이 커널의 취약점이 있으면 모든 컨테이너에 영향을 미칠 수 있다. 네임스페이스와 cgroups를 사용한 격리가 있으나, 완벽한 보안을 제공하지는 않는다.
도커 아키텍쳐
클라이언트(Client)
사용자는 도커 클라이언트를 통해 명령어를 실행한다. 예를 들어, docker run 명령어를 사용하여 컨테이너를 실행할 수 있다.
클라이언트는 도커 서버와 상호작용하여 사용자의 요청을 처리한다. 이 과정에서 명령어를 도커 서버로 전달하는 역할을 한다.
도커 데몬(Docker Daemon)
도커 데몬은 도커 서버의 핵심 역할을 하며, 사용자로부터 받은 명령을 실제로 처리한다.
도커 데몬은 API를 통해 클라이언트와 통신하며, 컨테이너의 생성, 시작, 중단, 삭제 등의 작업을 수행한다.
도커 데몬은 호스트 운영체제에서 실행되며, 호스트의 자원을 이용하여 컨테이너를 관리한다.
API
도커 데몬과 클라이언트 간의 통신을 가능하게 하는 인터페이스이다.
사용자가 클라이언트에서 입력한 명령어는 API를 통해 도커 데몬으로 전달되며, 그 결과도 다시 API를 통해 클라이언트로 전달된다.
컨테이너 관리
도커 데몬은 실제로 호스트 운영체제의 자원을 이용하여 컨테이너를 관리한다.
각 컨테이너는 도커 데몬에 의해 생성되며, 해당 컨테이너는 애플리케이션과 그 애플리케이션을 실행하는데 필요한 모든 파일을 포함한다.
여러 개의 컨테이너가 호스트 OS 위에서 동시에 실행되며, 도커 데몬은 이 컨테이너들의 실행 상태를 관리한다.
호스트 OS (Host OS)
도커는 호스트 운영체제 위에서 실행되며, 컨테이너는 이 호스트 운영체제의 자원을 사용하여 동작한다.
리눅스 기반 운영체제에서 도커는 호스트 커널을 공유하면서도 격리된 환경을 제공한다.
서버 (Server)
실제 물리적 하드웨어 자원을 제공하는 서버이다.
이 서버에서 도커 데몬이 실행되며, 도커 데몬은 서버의 CPU, 메모리, 스토리지 등의 자원을 사용하여 컨테이너를 관리하고 실행한다.
전체적인 흐름
사용자는 클라이언트에서 명령어를 실행하면, 해당 명령은 API를 통해 도커 데몬으로 전달된다.
docker -v # Docker 버전 확인
docker compose version # Docker Compose 버전 확인
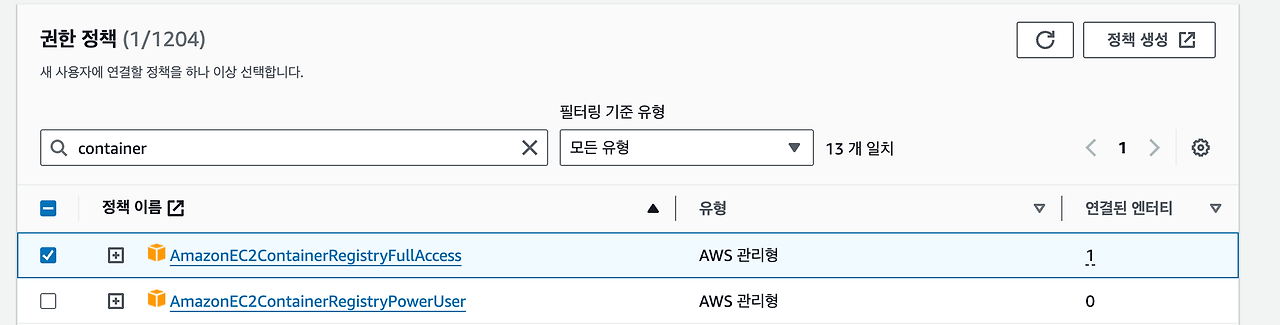
AWS ECR 설치
필자는 Mac OS를 사용중이므로 맥 기준으로 설명
로컬 PC에 AWS ECR 설치
brew install awscli
aws --version # 잘 출력된다면 정상 설치된 상태
EC2에도 AWS ECR 설치
sudo apt install unzip
curl "https://awscli.amazonaws.com/awscli-exe-linux-x86_64.zip" -o "awscliv2.zip"
unzip awscliv2.zip
sudo ./aws/install
aws --version # 잘 출력된다면 정상 설치된 상태
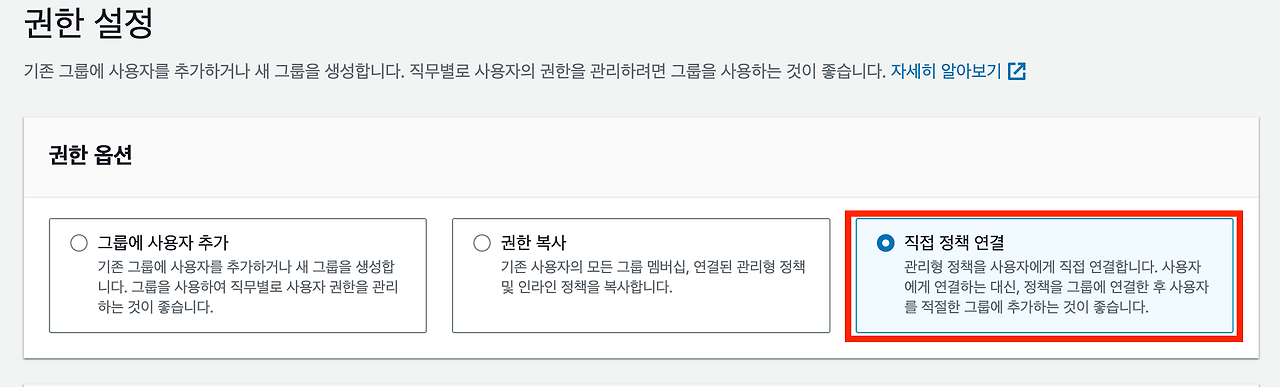
IAM 생성
사용자 생성
액세스 키 발급
액세스 키와 비밀 액세스 키는 따로 적어놓거나 보관해두어야 한다.
AWS CLI로 액세스 키 등록
$ aws configure
AWS Access Key ID [None]: <위에서 발급한 Key id>
AWS Secret Access Key [None]: <위에서 발급한 Secret Access Key>
Default region name [None]: ap-northeast-2
Default output format [None]:
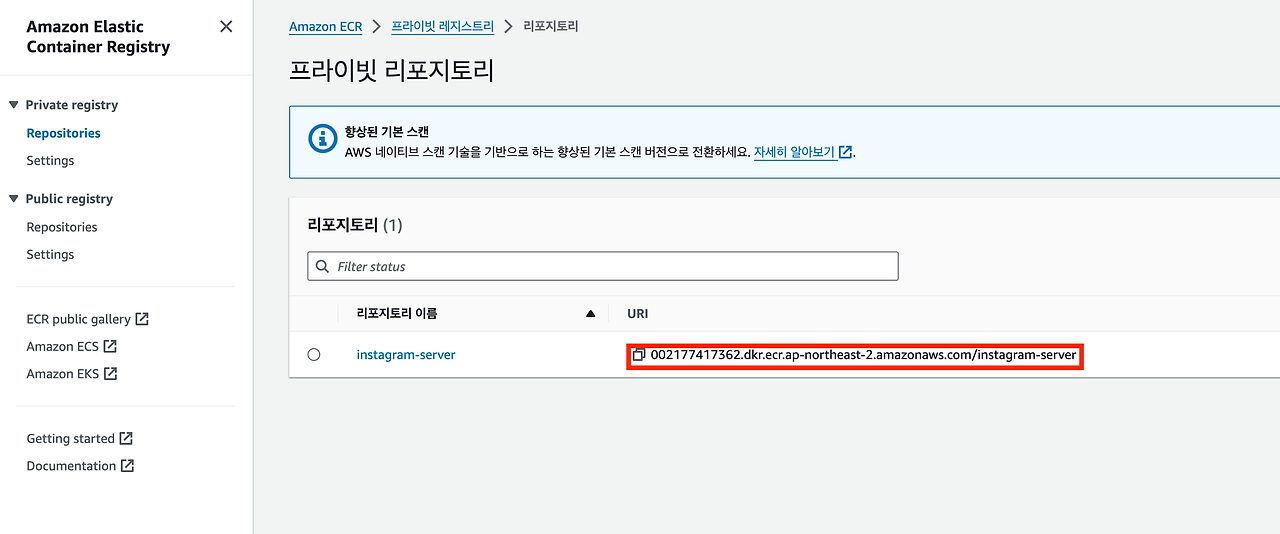
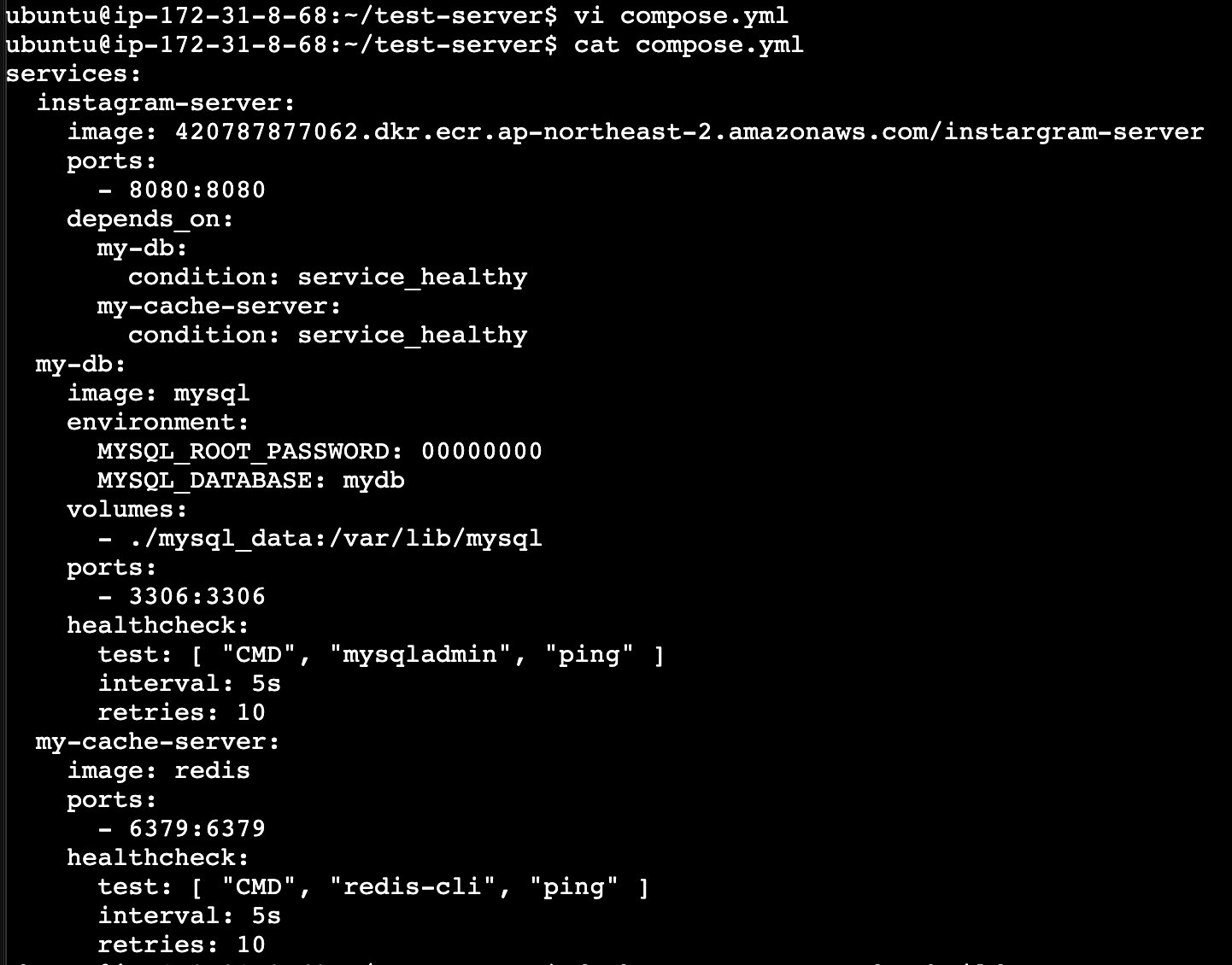
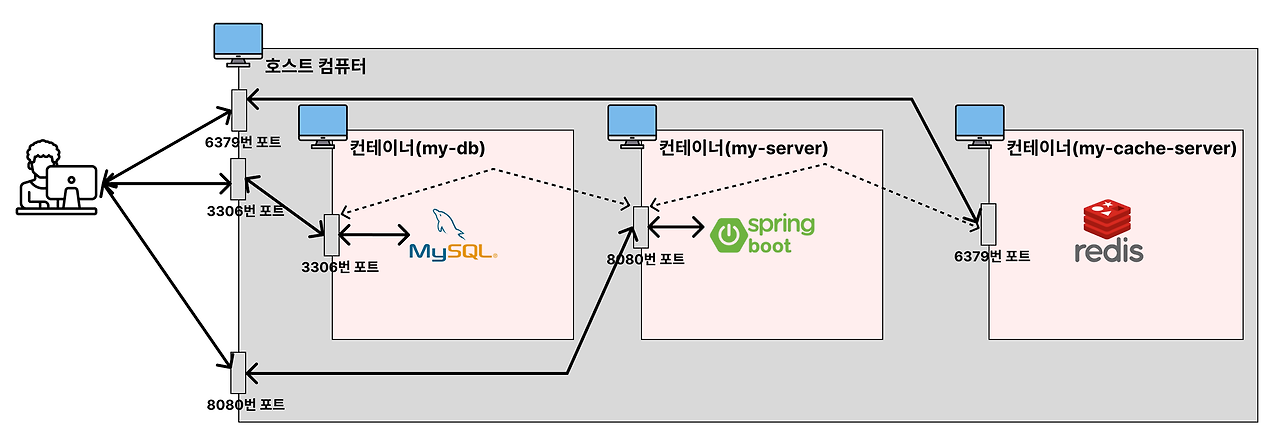
instagram-server: -이미지: <이전에 입력한 URI> 이 Docker 이미지가 AWS ECR에 저장되어 있다. Docker Compose는 이 이미지를 사용하여 컨테이너를 시작한다. -포트: 8080:8080 로컬 머신의 포트 8080을 컨테이너의 포트 8080에 매핑하여 외부에서 웹 애플리케이션에 접근할 수 있도록 한다. -의존성(depends_on): my-db와 my-cache-server가 service_healthy 조건을 만족할 때까지 이 서버는 시작되지 않는다. 이는 서비스가 실행되는 순서를 정의한다.
my-db: -이미지: mysql mysql 이미지를 사용하여 MySQL 데이터베이스를 설정한다. -환경 변수: MYSQL_ROOT_PASSWORD: MySQL의 루트 비밀번호를 설정한다. MYSQL_DATABASE: mydb라는 데이터베이스를 생성한다. -볼륨: ./mysql_data:/var/lib/mysql: 로컬 디렉토리 ./mysql_data를 컨테이너의 MySQL 데이터 디렉토리 /var/lib/mysql에 마운트하여 데이터를 유지한다. -포트: 3306:3306 로컬 머신의 포트 3306을 컨테이너의 MySQL 포트 3306에 매핑한다. -헬스체크: MySQL이 정상적으로 실행되고 있는지 확인하기 위해 mysqladmin ping 명령을 사용하여 상태를 주기적으로 체크한다.
my-cache-server: -이미지: redis Redis 이미지를 사용하여 캐시 서버를 실행한다. -포트: 6379:6379 로컬 머신의 포트 6379를 컨테이너의 Redis 포트 6379에 매핑한다. -헬스체크: redis-cli ping 명령을 사용하여 Redis가 정상적으로 실행 중인지 확인한다.
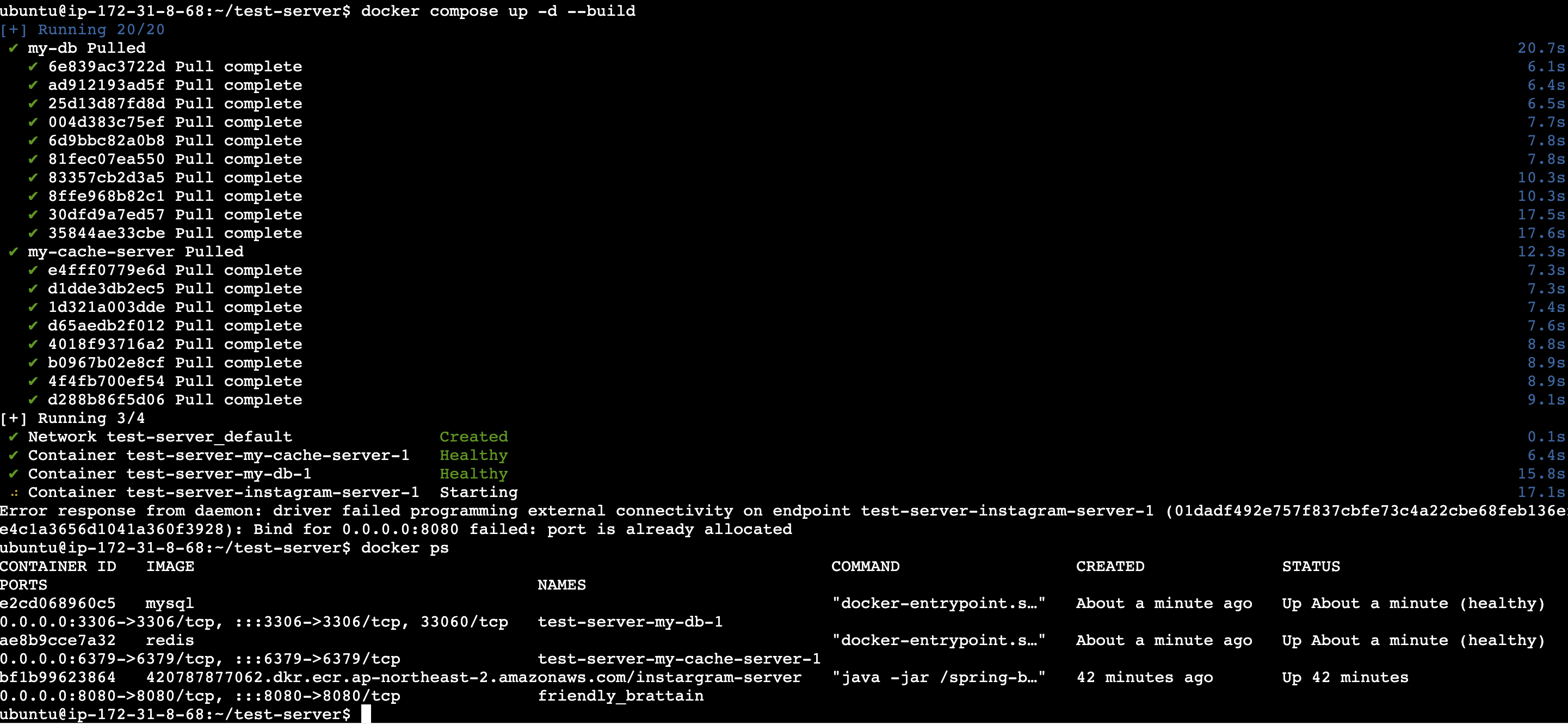
이후 Compose를 실행시켜야 한다.
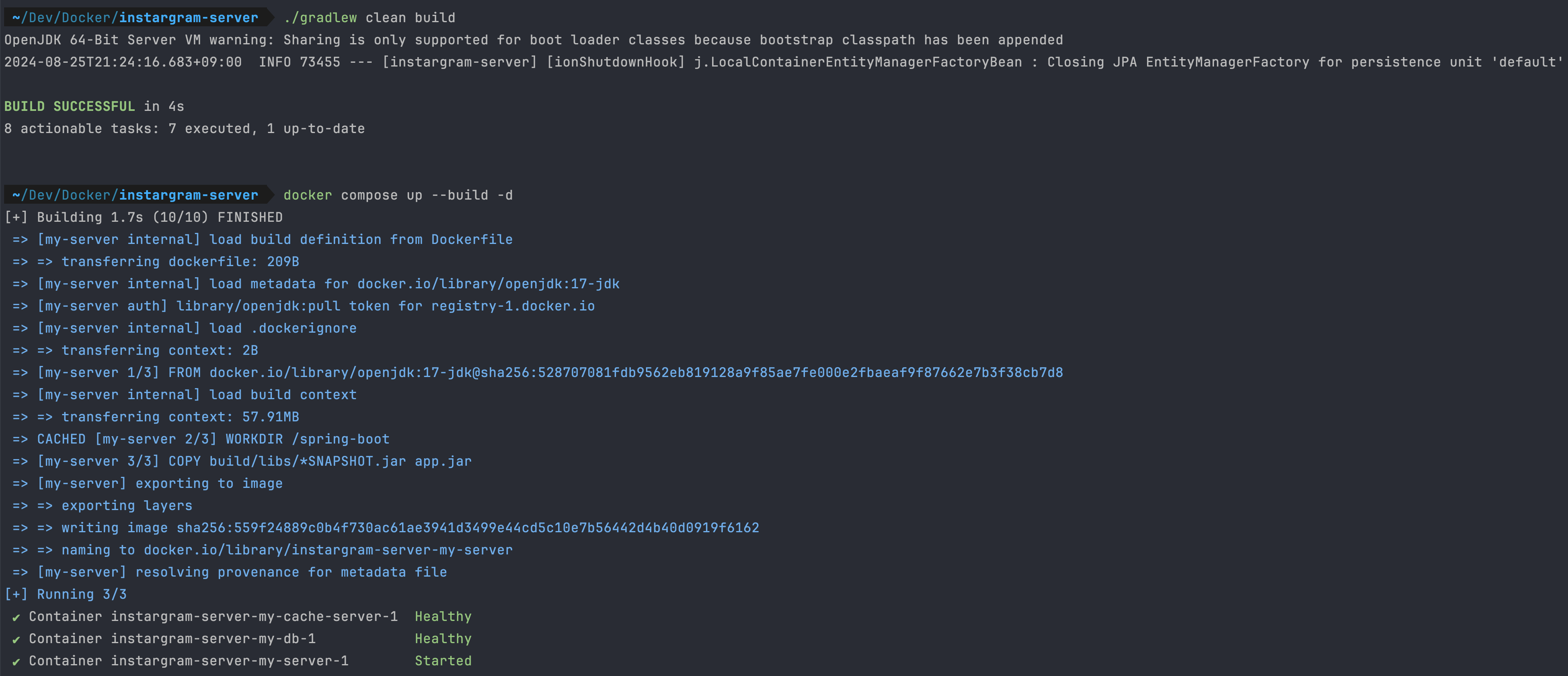
docker compose up -d --build
스프링 부트, mysql, redis가 모두 정상적으로 실행되고 있는 것을 확인할 수 있다.
FROM openjdk:17-jdk -Docker 이미지를 생성할 때 기본으로 사용할 베이스 이미지를 설정하는 명령어이다. -이 경우, openjdk:17-jdk 이미지를 사용하여 JDK(Java Development Kit) 17이 설치된 환경에서 애플리케이션을 실행할 수 있도록 한다. -OpenJDK는 자바 애플리케이션을 실행하는 데 필요한 런타임 환경을 제공한다.
WORKDIR /spring-boot -Docker 컨테이너 내에서 작업 디렉토리를 /spring-boot로 설정한다. 이후의 모든 명령어는 이 디렉토리 내에서 실행된다. 이 디렉토리가 존재하지 않으면 자동으로 생성된다.
COPY build/libs/*SNAPSHOT.jar app.jar -호스트 시스템의 build/libs/ 경로에 있는 *SNAPSHOT.jar 파일을 Docker 컨테이너의 /spring-boot/ 디렉토리에 app.jar 파일로 복사한다. -build/libs/에 *SNAPSHOT.jar 파일이 존재해야 한다.
my-server -Spring Boot 애플리케이션을 8080 포트에서 실행한다. -depends_on 옵션을 사용해 MySQL 데이터베이스와 Redis 캐시 서버가 먼저 준비된 후에 서버가 실행되도록 설정했다. -depends_on에서 condition: service_healthy를 사용해 각 서비스가 정상적으로 준비된 후에 서버가 실행될 수 있도록 보장한다.
my-db (MySQL 데이터베이스) -image: mysql로 MySQL 컨테이너를 설정한다. MySQL의 기본 이미지가 사용된다. -환경 변수로 MYSQL_ROOT_PASSWORD와 MYSQL_DATABASE를 설정해 MySQL의 root 비밀번호와 데이터베이스 이름을 지정한다. -로컬의 ./mysql_data 디렉터리를 컨테이너 내부의 /var/lib/mysql에 마운트하여 데이터가 유지되도록 설정했다. -ports 옵션을 사용해 3306 포트를 노출시켜 외부에서 데이터베이스에 접근할 수 있다. -healthcheck를 설정해 MySQL 서버가 정상적으로 실행 중인지 확인한다. 5초마다 mysqladmin ping 명령어로 상태를 확인하고, 최대 10번의 시도를 한다.
my-cache-server (Redis 캐시 서버): -image: redis로 Redis 캐시 서버를 설정한다. -ports 옵션을 통해 6379 포트를 노출시켜 외부에서 Redis에 접근할 수 있다. -healthcheck를 설정해 Redis 서버가 정상적으로 실행 중인지 확인한다. 5초마다 redis-cli ping 명령어로 상태를 확인하고, 최대 10번의 시도를 한다.
위 설정과 스프링부트의 application.properties 파일을 살펴보면 아래와 같은 그림이 이해가 될 것이다.
컨테이너들: -my-db: MySQL 데이터베이스 컨테이너로, 3306번 포트를 통해 외부(호스트 컴퓨터)와 연결된다. my-server 컨테이너는 내부적으로 이 데이터베이스와 통신한다. -my-server: Spring Boot 서버 애플리케이션이 동작하는 컨테이너로, 8080번 포트를 통해 외부와 통신하며, my-db와 my-cache-server와 내부적으로 연결되어 있다. -my-cache-server: Redis 캐시 서버가 동작하는 컨테이너로, 6379번 포트를 통해 호스트와 통신한다. my-server 컨테이너는 내부적으로 이 캐시 서버를 사용한다.
각 컨테이너는 외부로부터 특정 포트를 통해 접근할 수 있으며, 컨테이너들끼리는 내부적으로 연결되어 통신한다. my-server는 Spring Boot 기반 애플리케이션으로서 MySQL 데이터베이스(my-db)와 Redis 캐시 서버(my-cache-server)를 이용해 데이터 처리를 한다.
FROM openjdk:17-jdk -Docker 이미지를 생성할 때 기본으로 사용할 베이스 이미지를 설정하는 명령어이다. -이 경우, openjdk:17-jdk 이미지를 사용하여 JDK(Java Development Kit) 17이 설치된 환경에서 애플리케이션을 실행할 수 있도록 한다. -OpenJDK는 자바 애플리케이션을 실행하는 데 필요한 런타임 환경을 제공한다.
WORKDIR /spring-boot -Docker 컨테이너 내에서 작업 디렉토리를 /spring-boot로 설정한다. 이후의 모든 명령어는 이 디렉토리 내에서 실행된다. 이 디렉토리가 존재하지 않으면 자동으로 생성된다.
COPY build/libs/*SNAPSHOT.jar app.jar -호스트 시스템의 build/libs/ 경로에 있는 *SNAPSHOT.jar 파일을 Docker 컨테이너의 /spring-boot/ 디렉토리에 app.jar 파일로 복사한다. -build/libs/에 *SNAPSHOT.jar 파일이 존재해야 한다.
이 Dockerfile은 OpenJDK 17을 기반으로 한 자바 애플리케이션을 Docker 컨테이너에서 실행하기 위한 설정이다. 애플리케이션의 빌드 결과물인 SNAPSHOT.jar 파일을 컨테이너로 복사하고, 컨테이너가 시작될 때 해당 파일을 자바 명령어로 실행하는 방식이다.
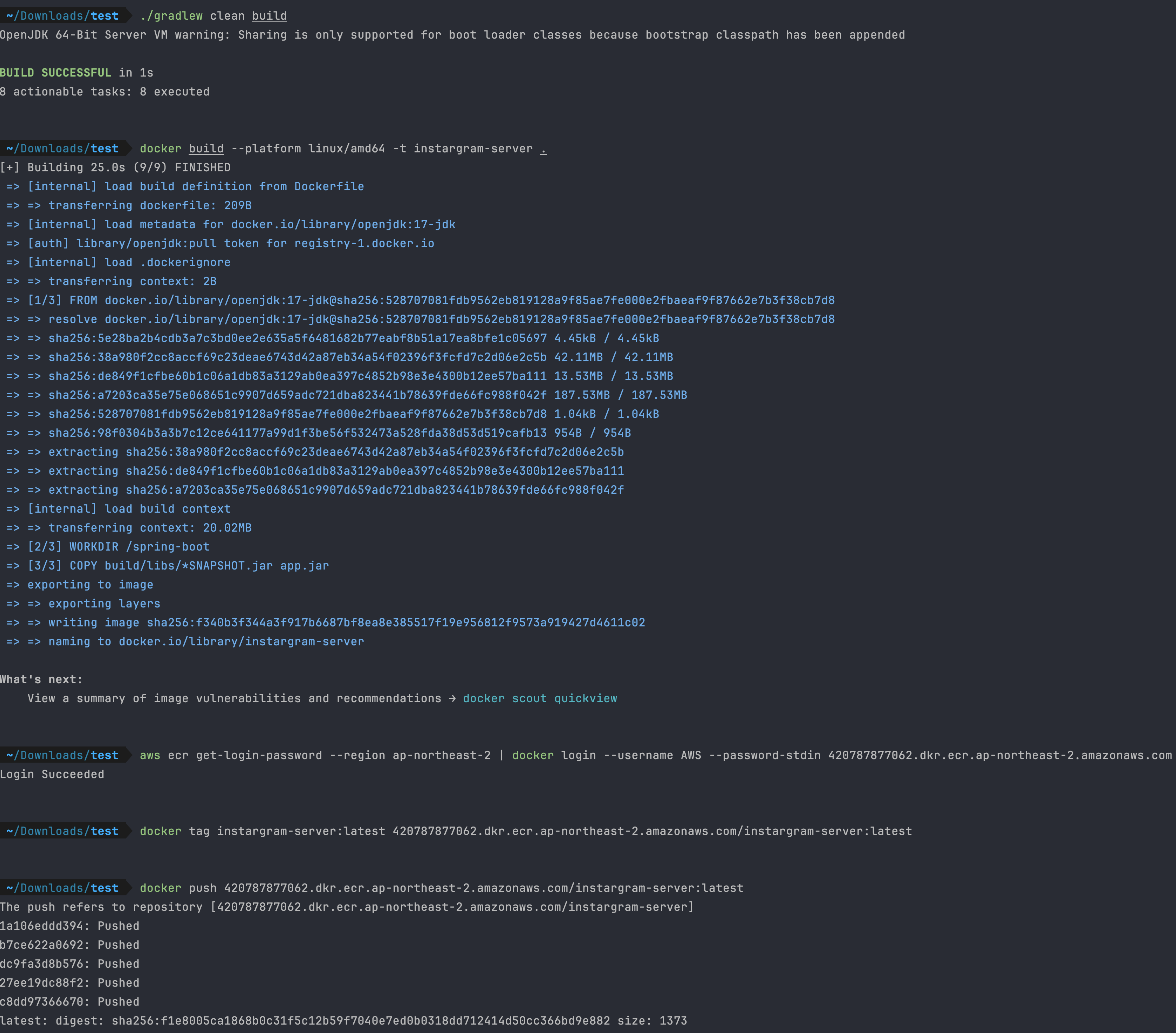
2. 스프링 부트 프로젝트 빌드
./gradlew clean build
3. DockerFile 이미지 빌드
docker build -t hello-server .
docker build
현재 디렉토리에 있는 Dockerfile을 기반으로 Docker 이미지를 빌드하는 명령어이다.
Dockerfile에 정의된 명령어들이 순서대로 실행되어 최종적으로 새로운 이미지가 만들어진다.
-t hello-server
빌드된 이미지를 태그하는 옵션이다. -t 옵션 뒤에 hello-server라는 이름을 이미지에 붙여준다.
즉, 빌드된 이미지는 hello-server라는 이름으로 저장되며, 이 이름을 사용해 나중에 컨테이너를 실행할 수 있다.
태그는 name:tag 형식으로 사용되며, 여기서는 tag 부분이 생략되어 latest로 기본 설정된다. 즉, 이 이미지는 hello-server:latest로 태그된다.
. (점)
• Docker 빌드 명령어에서 마지막에 오는 .은 Dockerfile을 포함한 컨텍스트의 경로를 나타낸다. • 여기서 .은 현재 디렉토리를 의미하며, 이 디렉토리에서 Dockerfile을 찾아 이미지를 빌드하게 된다.
결론적으로, 이 명령어는 현재 디렉토리에 있는 Dockerfile을 기반으로 Docker 이미지를 빌드하고, 해당 이미지를 hello-server라는 이름으로 태그한다.
이 글은 인프런의 MySQL 성능 최적화 입문/실전 (SQL 튜닝편) (박재성) 강의를 듣고 개인적으로 정리하는 글임을 알립니다.
유저 이름으로 특정 기간에 작성된 글 검색
기본 테이블 생성
DROP TABLE IF EXISTS posts;
DROP TABLE IF EXISTS users;
CREATE TABLE users (
id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(50) NOT NULL,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
CREATE TABLE posts (
id INT AUTO_INCREMENT PRIMARY KEY,
title VARCHAR(255) NOT NULL,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
user_id INT,
FOREIGN KEY (user_id) REFERENCES users(id)
);
더미 데이터 추가
-- 높은 재귀(반복) 횟수를 허용하도록 설정
-- (아래에서 생성할 더미 데이터의 개수와 맞춰서 작성하면 된다.)
SET SESSION cte_max_recursion_depth = 1000000;
-- users 테이블에 더미 데이터 삽입
INSERT INTO users (name, created_at)
WITH RECURSIVE cte (n) AS
(
SELECT 1
UNION ALL
SELECT n + 1 FROM cte WHERE n < 1000000 -- 생성하고 싶은 더미 데이터의 개수
)
SELECT
CONCAT('User', LPAD(n, 7, '0')) AS name, -- 'User' 다음에 7자리 숫자로 구성된 이름 생성
TIMESTAMP(DATE_SUB(NOW(), INTERVAL FLOOR(RAND() * 3650) DAY) + INTERVAL FLOOR(RAND() * 86400) SECOND) AS created_at -- 최근 10년 내의 임의의 날짜와 시간 생성
FROM cte;
-- posts 테이블에 더미 데이터 삽입
INSERT INTO posts (title, created_at, user_id)
WITH RECURSIVE cte (n) AS
(
SELECT 1
UNION ALL
SELECT n + 1 FROM cte WHERE n < 1000000 -- 생성하고 싶은 더미 데이터의 개수
)
SELECT
CONCAT('Post', LPAD(n, 7, '0')) AS name, -- 'User' 다음에 7자리 숫자로 구성된 이름 생성
TIMESTAMP(DATE_SUB(NOW(), INTERVAL FLOOR(RAND() * 3650) DAY) + INTERVAL FLOOR(RAND() * 86400) SECOND) AS created_at, -- 최근 10년 내의 임의의 날짜와 시간 생성
FLOOR(1 + RAND() * 50000) AS user_id -- 1부터 50000 사이의 난수로 급여 생성
FROM cte;
기존 SQL문 성능 측정
SELECT p.id, p.title, p.created_at
FROM posts p
JOIN users u ON p.user_id = u.id
WHERE u.name = 'User0000046'
AND p.created_at BETWEEN '2022-01-01' AND '2024-03-07';
약 150ms 정도의 시간이 소요
실행 계획 조회
EXPLAIN SELECT p.id, p.title, p.created_at
FROM posts p
JOIN users u ON p.user_id = u.id
WHERE u.name = 'User0000046'
AND p.created_at BETWEEN '2022-01-01' AND '2024-03-07';
풀 테이블 스캔을 하기 때문에 인덱스를 추가해야 한다.
인덱스를 추가할 수 있는 컬럼이 users.name과 posts.created_at이 있다.
일단 둘 다 인덱스로 추가해보자.
성능 개선을 위한 인덱스 생성
CREATE INDEX idx_name ON users (name);
CREATE INDEX idx_created_at ON posts (created_at);
옵티마이저는 posts.created_at 인덱스가 존재하는 걸 알지만 굳이 사용하지 않는 게 효율적이라고 판단했다.
그렇기 때문에 사용하지 않는 인덱스는 삭제해주자.
ALTER TABLE posts DROP INDEX idx_created_at;
다시 성능 측정
150ms에서 20ms로 성능이 많이 개선되었다.
특정 부서에서 최대 연봉을 가진 사용자들 조회
테이블 생성
DROP TABLE IF EXISTS posts;
DROP TABLE IF EXISTS users;
CREATE TABLE users (
id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(100),
department VARCHAR(100),
salary INT,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
더미 데이터 삽입
-- 높은 재귀(반복) 횟수를 허용하도록 설정
-- (아래에서 생성할 더미 데이터의 개수와 맞춰서 작성하면 된다.)
SET SESSION cte_max_recursion_depth = 1000000;
-- 더미 데이터 삽입 쿼리
INSERT INTO users (name, department, salary, created_at)
WITH RECURSIVE cte (n) AS
(
SELECT 1
UNION ALL
SELECT n + 1 FROM cte WHERE n < 1000000 -- 생성하고 싶은 더미 데이터의 개수
)
SELECT
CONCAT('User', LPAD(n, 7, '0')) AS name, -- 'User' 다음에 7자리 숫자로 구성된 이름 생성
CASE
WHEN n % 10 = 1 THEN 'Engineering'
WHEN n % 10 = 2 THEN 'Marketing'
WHEN n % 10 = 3 THEN 'Sales'
WHEN n % 10 = 4 THEN 'Finance'
WHEN n % 10 = 5 THEN 'HR'
WHEN n % 10 = 6 THEN 'Operations'
WHEN n % 10 = 7 THEN 'IT'
WHEN n % 10 = 8 THEN 'Customer Service'
WHEN n % 10 = 9 THEN 'Research and Development'
ELSE 'Product Management'
END AS department, -- 의미 있는 단어 조합으로 부서 이름 생성
FLOOR(1 + RAND() * 100000) AS salary, -- 1부터 100000 사이의 난수로 나이 생성
TIMESTAMP(DATE_SUB(NOW(), INTERVAL FLOOR(RAND() * 3650) DAY) + INTERVAL FLOOR(RAND() * 86400) SECOND) AS created_at -- 최근 10년 내의 임의의 날짜와 시간 생성
FROM cte;
기존 SQL문 성능 측정
SELECT *
FROM users
WHERE salary = (SELECT MAX(salary) FROM users)
AND department IN ('Sales', 'Marketing', 'IT');
약 280ms 정도 소요
실행 계획 조회
type이 ALL -> 풀 테이블 스캔
인덱스를 활용해서 풀 테이블 스캔을 하지 않도록 바꿔보자.
인덱스 생성
데이터 액세스 수를 크게 줄일 수 있는 컬럼은 중복 정도가 낮은 컬럼이다. 따라서 salary로 인덱스를 생성
CREATE INDEX idx_salary ON users (salary);
성능 측정
SELECT *
FROM users
WHERE salary = (SELECT MAX(salary) FROM users)
AND department IN ('Sales', 'Marketing', 'IT');
280ms에서 25ms 정도로 성능이 향상
실행 계획 조회
EXPLAIN SELECT *
FROM users
WHERE salary = (SELECT MAX(salary) FROM users)
AND department IN ('Sales', 'Marketing', 'IT');
인덱스를 활용해서 데이터를 액세스 했고, 액세스 수도 6개로 확 줄었다.
부서별 최대 연봉을 가진 사용자들 조회
테이블 생성
DROP TABLE IF EXISTS users;
CREATE TABLE users (
id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(100),
department VARCHAR(100),
salary INT,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
더미 데이터 생성
-- 높은 재귀(반복) 횟수를 허용하도록 설정
-- (아래에서 생성할 더미 데이터의 개수와 맞춰서 작성하면 된다.)
SET SESSION cte_max_recursion_depth = 1000000;
-- 더미 데이터 삽입 쿼리
INSERT INTO users (name, department, salary, created_at)
WITH RECURSIVE cte (n) AS
(
SELECT 1
UNION ALL
SELECT n + 1 FROM cte WHERE n < 1000000 -- 생성하고 싶은 더미 데이터의 개수
)
SELECT
CONCAT('User', LPAD(n, 7, '0')) AS name, -- 'User' 다음에 7자리 숫자로 구성된 이름 생성
CASE
WHEN n % 10 = 1 THEN 'Engineering'
WHEN n % 10 = 2 THEN 'Marketing'
WHEN n % 10 = 3 THEN 'Sales'
WHEN n % 10 = 4 THEN 'Finance'
WHEN n % 10 = 5 THEN 'HR'
WHEN n % 10 = 6 THEN 'Operations'
WHEN n % 10 = 7 THEN 'IT'
WHEN n % 10 = 8 THEN 'Customer Service'
WHEN n % 10 = 9 THEN 'Research and Development'
ELSE 'Product Management'
END AS department, -- 의미 있는 단어 조합으로 부서 이름 생성
FLOOR(1 + RAND() * 100000) AS salary, -- 1부터 100000 사이의 난수로 나이 생성
TIMESTAMP(DATE_SUB(NOW(), INTERVAL FLOOR(RAND() * 3650) DAY) + INTERVAL FLOOR(RAND() * 86400) SECOND) AS created_at -- 최근 10년 내의 임의의 날짜와 시간 생성
FROM cte;
SQL문 성능 체크
SELECT u.id, u.name, u.department, u.salary, u.created_at
FROM users u
JOIN (
SELECT department, MAX(salary) AS max_salary
FROM users
GROUP BY department
) d ON u.department = d.department AND u.salary = d.max_salary;
약 600ms 정도 걸린다.
실행계획 조회
EXPLAIN SELECT u.*
FROM users u
JOIN (
SELECT department, MAX(salary) AS max_salary
FROM users
GROUP BY department
) d ON u.department = d.department AND u.salary = d.max_salary;
JOIN 문 내부에 있는 서브쿼리를 실행시킬 때 풀 테이블 스캔이 이뤄어졌음을 알 수 있다.
성능 개선
GROUP BY department는 department를 기준으로 정렬을 시킨 뒤에 MAX(salary) 값을 구하게 된다. 이 때, MAX(salary)를 구하기 위해 이리저리 찾아다닐 수 밖에 없다.
이를 해결하기 위해 (department, salary)의 멀티 컬럼 인덱스가 있으면 department를 기준으로 정렬을 시키는 작업을 하지 않아도 되고, 심지어 MAX(salary)도 빠르게 찾을 수 있다. 멀티 컬럼 인덱스를 생성해보자.
CREATE INDEX idx_department_salary ON users (department, salary);
다시 성능 측정
SELECT u.*
FROM users u
JOIN (
SELECT department, MAX(salary) AS max_salary
FROM users
GROUP BY department
) d ON u.department = d.department AND u.salary = d.max_salary;
600ms에서 20ms로 30배 정도 성능이 향상됐다.
실행 계획을 조회
실행 계획을 조회해봐도 인덱스를 잘 활용해서 데이터를 찾고 있고, 접근한 rows 자체도 훨씬 적어졌다.
특정 유저의 2023년 주문 데이터 조회
테이블 생성
DROP TABLE IF EXISTS users;
DROP TABLE IF EXISTS orders;
CREATE TABLE users (
id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(100),
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
CREATE TABLE orders (
id INT AUTO_INCREMENT PRIMARY KEY,
ordered_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
user_id INT,
FOREIGN KEY (user_id) REFERENCES users(id)
);
더미 데이터 생성
-- 높은 재귀(반복) 횟수를 허용하도록 설정
-- (아래에서 생성할 더미 데이터의 개수와 맞춰서 작성하면 된다.)
SET SESSION cte_max_recursion_depth = 1000000;
-- users 테이블에 더미 데이터 삽입
INSERT INTO users (name, created_at)
WITH RECURSIVE cte (n) AS
(
SELECT 1
UNION ALL
SELECT n + 1 FROM cte WHERE n < 1000000 -- 생성하고 싶은 더미 데이터의 개수
)
SELECT
CONCAT('User', LPAD(n, 7, '0')) AS name, -- 'User' 다음에 7자리 숫자로 구성된 이름 생성
TIMESTAMP(DATE_SUB(NOW(), INTERVAL FLOOR(RAND() * 3650) DAY) + INTERVAL FLOOR(RAND() * 86400) SECOND) AS created_at -- 최근 10년 내의 임의의 날짜와 시간 생성
FROM cte;
-- orders 테이블에 더미 데이터 삽입
INSERT INTO orders (ordered_at, user_id)
WITH RECURSIVE cte (n) AS
(
SELECT 1
UNION ALL
SELECT n + 1 FROM cte WHERE n < 1000000 -- 생성하고 싶은 더미 데이터의 개수
)
SELECT
TIMESTAMP(DATE_SUB(NOW(), INTERVAL FLOOR(RAND() * 3650) DAY) + INTERVAL FLOOR(RAND() * 86400) SECOND) AS ordered_at, -- 최근 10년 내의 임의의 날짜와 시간 생성
FLOOR(1 + RAND() * 1000000) AS user_id -- 1부터 1000000 사이의 난수로 급여 생성
FROM cte;
기존 SQL문 성능 조회
SELECT *
FROM orders
WHERE YEAR(ordered_at) = 2023
ORDER BY ordered_at
LIMIT 30;
약 180ms 정도가 걸린다.
실행계획 조회
EXPLAIN SELECT *
FROM orders
WHERE YEAR(ordered_at) = 2023
ORDER BY ordered_at
LIMIT 30;
성능 개선
ordered_at에 인덱스를 추가하면 풀 테이블 스캔을 막을 수 있을 것 같다. 그래서 인덱스를 추가해보자.
CREATE INDEX idx_ordered_at ON orders (ordered_at);
700ms로 더 느려졌다.
실행계획을 살펴보면
인덱스 풀 스캔을 했다. 풀 테이블 스캔 대신에 인덱스 풀 스캔을 하면 더 빨라져야 한다. 또한 WHERE문으로 특정 범위의 데이터만 접근하면 인덱스 풀 스캔이 아니라 인덱스 레인지 스캔이 나와야한다.
문제는 인덱스의 컬럼을 가공해서 사용했기 때문이다.
그래서 인덱스를 제대로 활용 하지 못한 것이다. 인덱스의 컬럼을 가공하지 않게 SQL문을 다시 수정해보자.
성능 개선2
SELECT *
FROM orders
WHERE ordered_at >= '2023-01-01 00:00:00'
AND ordered_at < '2024-01-01 00:00:00'
ORDER BY ordered_at
LIMIT 30;
180ms에서 20ms로 9배 가량 성능을 향상시켰다.
실행 계획도 인덱스 레인지 스캔으로 바뀌었다.
2024년 1학기 평균 성적이 100점인 학생 조회
테이블 생성
DROP TABLE IF EXISTS scores;
DROP TABLE IF EXISTS subjects;
DROP TABLE IF EXISTS students;
CREATE TABLE students (
student_id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(100),
age INT
);
CREATE TABLE subjects (
subject_id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(100)
);
CREATE TABLE scores (
score_id INT AUTO_INCREMENT PRIMARY KEY,
student_id INT,
subject_id INT,
year INT,
semester INT,
score INT,
FOREIGN KEY (student_id) REFERENCES students(student_id),
FOREIGN KEY (subject_id) REFERENCES subjects(subject_id)
);
더미 데이터 생성
-- 높은 재귀(반복) 횟수를 허용하도록 설정
-- (아래에서 생성할 더미 데이터의 개수와 맞춰서 작성하면 된다.)
SET SESSION cte_max_recursion_depth = 1000000;
-- students 테이블에 더미 데이터 삽입
INSERT INTO students (name, age)
WITH RECURSIVE cte (n) AS
(
SELECT 1
UNION ALL
SELECT n + 1 FROM cte WHERE n < 1000000 -- 생성하고 싶은 더미 데이터의 개수
)
SELECT
CONCAT('Student', LPAD(n, 7, '0')) AS name, -- 'User' 다음에 7자리 숫자로 구성된 이름 생성
FLOOR(1 + RAND() * 100) AS age -- 1부터 100 사이의 랜덤한 점수 생성
FROM cte;
-- subjects 테이블에 과목 데이터 삽입
INSERT INTO subjects (name)
VALUES
('Mathematics'),
('English'),
('History'),
('Biology'),
('Chemistry'),
('Physics'),
('Computer Science'),
('Art'),
('Music'),
('Physical Education'),
('Geography'),
('Economics'),
('Psychology'),
('Philosophy'),
('Languages'),
('Engineering');
-- scores 테이블에 더미 데이터 삽입
INSERT INTO scores (student_id, subject_id, year, semester, score)
WITH RECURSIVE cte (n) AS
(
SELECT 1
UNION ALL
SELECT n + 1 FROM cte WHERE n < 1000000 -- 생성하고 싶은 더미 데이터의 개수
)
SELECT
FLOOR(1 + RAND() * 1000000) AS student_id, -- 1부터 1000000 사이의 난수로 학생 ID 생성
FLOOR(1 + RAND() * 16) AS subject_id, -- 1부터 16 사이의 난수로 과목 ID 생성
YEAR(NOW()) - FLOOR(RAND() * 5) AS year, -- 최근 5년 내의 임의의 연도 생성
FLOOR(1 + RAND() * 2) AS semester, -- 1 또는 2 중에서 랜덤하게 학기 생성
FLOOR(1 + RAND() * 100) AS score -- 1부터 100 사이의 랜덤한 점수 생성
FROM cte;
SQL문 성능 측정
SELECT
st.student_id,
st.name,
AVG(sc.score) AS average_score
FROM
students st
JOIN
scores sc ON st.student_id = sc.student_id
GROUP BY
st.student_id,
st.name,
sc.year,
sc.semester
HAVING
AVG(sc.score) = 100
AND sc.year = 2024
AND sc.semester = 1;
약 4000ms 정도의 시간이 걸린다.
성능 개선
HAVING절에 굳이 있지 않아도 될 조건이 HAVING 절에 포함되어 있다.
WHERE 문으로 옮길 수 있는 조건을 옮긴 뒤 성능을 다시 테스트
SELECT
st.student_id,
st.name,
AVG(sc.score) AS average_score
FROM
students st
JOIN
scores sc ON st.student_id = sc.student_id
WHERE
sc.year = 2024
AND sc.semester = 1
GROUP BY
st.student_id,
st.name
HAVING
AVG(sc.score) = 100;
WHERE문으로 옮길 수 있는 조건을 옮기면서, 불필요한 GROUP BY 컬럼을 삭제했다.
450ms 정도로 성능이 향상됐다.
좋아요 많은 순으로 게시글 조회
기본 테이블 생성
DROP TABLE IF EXISTS likes;
DROP TABLE IF EXISTS orders;
DROP TABLE IF EXISTS users;
DROP TABLE IF EXISTS posts;
CREATE TABLE posts (
id INT AUTO_INCREMENT PRIMARY KEY,
title VARCHAR(255) NOT NULL,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
CREATE TABLE users (
id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(50) NOT NULL,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
CREATE TABLE likes (
id INT AUTO_INCREMENT PRIMARY KEY,
post_id INT,
user_id INT,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
FOREIGN KEY (post_id) REFERENCES posts(id),
FOREIGN KEY (user_id) REFERENCES users(id)
);
더미 데이터 추가
-- 높은 재귀(반복) 횟수를 허용하도록 설정
-- (아래에서 생성할 더미 데이터의 개수와 맞춰서 작성하면 된다.)
SET SESSION cte_max_recursion_depth = 1000000;
-- posts 테이블에 더미 데이터 삽입
INSERT INTO posts (title, created_at)
WITH RECURSIVE cte (n) AS
(
SELECT 1
UNION ALL
SELECT n + 1 FROM cte WHERE n < 1000000 -- 생성하고 싶은 더미 데이터의 개수
)
SELECT
CONCAT('Post', LPAD(n, 7, '0')) AS name, -- 'User' 다음에 7자리 숫자로 구성된 이름 생성
TIMESTAMP(DATE_SUB(NOW(), INTERVAL FLOOR(RAND() * 3650) DAY) + INTERVAL FLOOR(RAND() * 86400) SECOND) AS created_at -- 최근 10년 내의 임의의 날짜와 시간 생성
FROM cte;
-- users 테이블에 더미 데이터 삽입
INSERT INTO users (name, created_at)
WITH RECURSIVE cte (n) AS
(
SELECT 1
UNION ALL
SELECT n + 1 FROM cte WHERE n < 1000000 -- 생성하고 싶은 더미 데이터의 개수
)
SELECT
CONCAT('User', LPAD(n, 7, '0')) AS name, -- 'User' 다음에 7자리 숫자로 구성된 이름 생성
TIMESTAMP(DATE_SUB(NOW(), INTERVAL FLOOR(RAND() * 3650) DAY) + INTERVAL FLOOR(RAND() * 86400) SECOND) AS created_at -- 최근 10년 내의 임의의 날짜와 시간 생성
FROM cte;
-- likes 테이블에 더미 데이터 삽입
INSERT INTO likes (post_id, user_id, created_at)
WITH RECURSIVE cte (n) AS
(
SELECT 1
UNION ALL
SELECT n + 1 FROM cte WHERE n < 1000000 -- 생성하고 싶은 더미 데이터의 개수
)
SELECT
FLOOR(1 + RAND() * 1000000) AS post_id, -- 1부터 1000000 사이의 난수로 급여 생성
FLOOR(1 + RAND() * 1000000) AS user_id, -- 1부터 1000000 사이의 난수로 급여 생성
TIMESTAMP(DATE_SUB(NOW(), INTERVAL FLOOR(RAND() * 3650) DAY) + INTERVAL FLOOR(RAND() * 86400) SECOND) AS created_at -- 최근 10년 내의 임의의 날짜와 시간 생성
FROM cte;
SQL 성능 측정
SELECT
p.id,
p.title,
p.created_at,
COUNT(l.id) AS like_count
FROM
posts p
INNER JOIN
likes l ON p.id = l.post_id
GROUP BY
p.id, p.title, p.created_at
ORDER BY
like_count DESC
LIMIT 30;
대략 2600ms 정도의 시간이 소요되고 있다.
실행 계획 조회
EXPLAIN SELECT
p.id,
p.title,
p.created_at,
COUNT(l.id) AS like_count
FROM
posts p
INNER JOIN
likes l ON p.id = l.post_id
GROUP BY
p.id, p.title, p.created_at
ORDER BY
like_count DESC
LIMIT 30;
실행 계획 세부 내용 조회
EXPLAIN ANALYZE SELECT
p.id,
p.title,
p.created_at,
COUNT(l.id) AS like_count
FROM
posts p
INNER JOIN
likes l ON p.id = l.post_id
GROUP BY
p.id, p.title, p.created_at
ORDER BY
like_count DESC
LIMIT 30;
-> Limit: 30 row(s) (actual time=2775..2775 rows=30 loops=1) -> Sort: like_count DESC, limit input to 30 row(s) per chunk (actual time=2775..2775 rows=30 loops=1) -> Table scan on <temporary> (actual time=2675..2745 rows=575582 loops=1) -> Aggregate using temporary table (actual time=2675..2675 rows=575582 loops=1) -> Nested loop inner join (cost=449599 rows=997632) (actual time=0.126..920 rows=1e+6 loops=1) -> Table scan on p (cost=100428 rows=997632) (actual time=0.0937..115 rows=1e+6 loops=1) -> Covering index lookup on l using post_id (post_id=p.id) (cost=0.25 rows=1) (actual time=602e-6..703e-6 rows=1 loops=1e+6)
세부 실행 계획을 보니 INNER JOIN과 GROUP BY(Aggreagte using temporary table)에 시간을 많이 사용했다.
이 이유를 추측하면 INNER JOIN, GROUP BY를 수행할 때 풀 테이블 스캔으로 조회한 데이터 100만개를 가지고 처리를 해서 오래 걸렸다고 추측할 수 있다.
성능 개선
SELECT p.*, l.like_count
FROM posts p
INNER JOIN
(SELECT post_id, count(post_id) AS like_count FROM likes l
GROUP BY l.post_id
ORDER BY like_count DESC
LIMIT 30) l
ON p.id = l.post_id;
먼저 likes 테이블에서 post_id를 기준으로 GROUP BY를 수행하여 각 게시물에 대한 좋아요 수를 집계한다. 이때 GROUP BY는 post_id만을 사용하므로, 인덱스를 활용하여 효율적으로 조회할 수 있다. 즉, 테이블의 모든 데이터를 읽지 않고, 인덱스만으로도 필요한 정보를 얻을 수 있기 때문에 성능이 더 빠르다. 이것을 커버링 인덱스라고 한다.
그런 다음, 좋아요 수가 많은 30개의 post_id를 찾은 후, 이를 posts 테이블과 INNER JOIN을 통해 결합한다. 이 과정에서 미리 필터링된 30개의 행만을 사용하여 INNER JOIN을 수행하므로 데이터 액세스가 훨씬 줄어들어 성능이 최적화된다.
성능도 2500ms에서 170ms로 아주 많이 개선되었다.
성능 개선 후 실행 계획
EXPLAIN SELECT p.*, l.like_count
FROM posts p
INNER JOIN
(SELECT post_id, count(post_id) AS like_count FROM likes l
GROUP BY l.post_id
ORDER BY like_count DESC
LIMIT 30) l
ON p.id = l.post_id;
풀 테이블 스캔으로 액세스한 데이터의 수가 30으로 줄었다. 그리고 l이라는 테이블에서 인덱스 풀 스캔을 했음을 알 수 있다.
즉, 대부분의 데이터를 원래 풀 테이블 스캔을 하던 걸 풀 인덱스 스캔으로 고친 것이다.
실행 계획 세부 내용 조회
EXPLAIN ANALYZE SELECT p.*, l.like_count
FROM posts p
INNER JOIN
(SELECT post_id, count(post_id) AS like_count FROM likes l
GROUP BY l.post_id
ORDER BY like_count DESC
LIMIT 30) l
ON p.id = l.post_id;
-> Nested loop inner join (cost=20.5 rows=30) (actual time=227..227 rows=30 loops=1) -> Filter: (l.post_id is not null) (cost=0.196..5.88 rows=30) (actual time=227..227 rows=30 loops=1) -> Table scan on l (cost=2.5..2.5 rows=0) (actual time=227..227 rows=30 loops=1) -> Materialize (cost=0..0 rows=0) (actual time=227..227 rows=30 loops=1) -> Limit: 30 row(s) (actual time=227..227 rows=30 loops=1) -> Sort: like_count DESC, limit input to 30 row(s) per chunk (actual time=227..227 rows=30 loops=1) -> Stream results (cost=200702 rows=573484) (actual time=0.0883..199 rows=575582 loops=1) -> Group aggregate: count(l.post_id) (cost=200702 rows=573484) (actual time=0.0837..163 rows=575582 loops=1) -> Covering index scan on l using idx_post_id (cost=100912 rows=997899) (actual time=0.074..101 rows=1e+6 loops=1) -> Single-row index lookup on p using PRIMARY (id=l.post_id) (cost=0.392 rows=1) (actual time=0.0019..0.00192 rows=1 loops=30)
실제 커버링 인덱스를 활용했음을 알 수 있다. 그리고 풀 테이블 스캔의 데이터보다 훨씬 크기가 작은 커버링 인덱스만을 활용해서 GROUP BY를 실행하니 훨씬 속도가 빠른 걸 알 수 있다.
이 알고리즘 문제는 인프런의 자바(Java) 알고리즘 문제풀이 입문: 코딩테스트 대비 (김태원)의 문제입니다.
문제 설명
코드
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.Arrays;
import java.util.StringTokenizer;
public class sec06_09 {
public static int count(int[] arr, int mid)
{
int count = 1;
int sum = 0;
for(int i = 0; i < arr.length; ++i)
{
if(sum + arr[i] > mid)
{
++count;
sum = arr[i];
}
else sum += arr[i];
}
return count;
}
public static int solution(int[] arr, int N, int M)
{
int lPtr = Arrays.stream(arr).max().getAsInt(); // 배열의 최대값
int rPtr = Arrays.stream(arr).sum(); // 배열의 총합
int answer = 0;
while(lPtr <= rPtr)
{
int mid = (lPtr + rPtr) / 2;
if(count(arr, mid) <= M)
{
answer = mid; // 가능한 답을 저장하고, 더 작은 값으로 탐색
rPtr = mid - 1;
}
else lPtr = mid + 1; // 중간값이 작아서 구간 수가 M보다 많다면, 더 큰 값 탐색
}
return answer;
}
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
StringTokenizer st = new StringTokenizer(br.readLine());
int N = Integer.parseInt(st.nextToken());
int M = Integer.parseInt(st.nextToken());
st = new StringTokenizer(br.readLine());
int[] arr = new int[N];
for (int i = 0; i < N; i++) arr[i] = Integer.parseInt(st.nextToken());
System.out.println(solution(arr, N , M));
}
}
설명
count 메서드는 주어진 배열을 특정 값(mid)보다 큰 구간 합이 없도록 나누었을 때, 몇 개의 구간이 필요한지 계산하는 역할을 한다. 배열을 순차적으로 더해 가다가 구간 합이 mid를 넘으면 새로운 구간을 시작하고, 구간의 수를 하나 증가시킨다.
solution 메서드는 이진 탐색을 사용하여 구간의 최대 합이 최소가 되도록 mid 값을 조정하는 역할을 한다. mid 값을 배열의 최대값과 총합 사이에서 탐색하며, count 메서드로 구간의 수를 계산해가면서 적절한 mid 값을 찾아낸다.