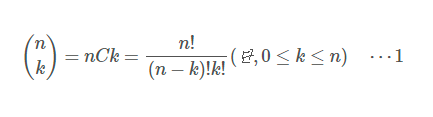이 게시글은 이것이 자바다(저자 : 신용권, 임경균)의 책과 동영상 강의를 참고하여 개인적으로 정리하는 글임을 알립니다.
람다식의 개념
자바는 함수형 프로그래밍을 위해 Java 8부터 람다식을 지원한다.
자바는 객체지향 프로그래밍 언어로써 객체가 없이 함수가 존재할 수 없다.
클래스 내부에 무조건 함수가 있어야 하기 때문에 자바에서는 함수를 함수라 부르지 않고 메소드라고 부른다.
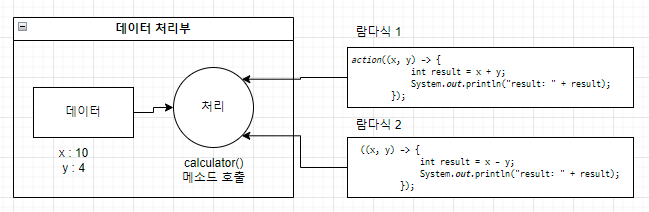
함수형 프로그래밍 함수형 프로그래밍이란 함수를 정의하고 이 함수를 데이터 처리부로 보내 데이터를 처리하는 기법을 가진다. 데이터 처리부는 데이터만 가지고 있을 뿐, 처리 방법이 정해져 있지 않아 외부에서 제공된 함수에 의존한다. 즉, 함수에 어떤 처리코드가 적혀있느냐에 따라 해당 데이터를 가지고 발생하는 실행결과가 달라질 수 있다는 뜻이다.
자바는 람다식을 익명 구현 객체로 변환한다.
아래와 같은 인터페이스가 정의 되었다고 하자.
@FunctionalInterface
public interface Calculable {
//추상 메소드
void calculate(int x, int y);
}
람다식은 인터페이스의 익명 구현 객체이므로 인터페이스 타입의 매개 변수에 대입될 수 있다.
public static void action(Calculable calculable) {
//데이터
int x = 10;
int y = 4;
//데이터 처리
calculable.calculate(x, y);
}
action() 메소드를 호출할 때 매개값으로 아래와 같이 람다식을 제공할 수 있다.
action((x, y) -> {
int result = x - y;
System.out.println("result: " + result);
});
action() 메소드는 제공된 람다식을 이용해서 내부 데이터를 처리하는 처리부 역할을 한다.
해당 메소드에 어떤 람다식을 이용해서 데이터를 처리하느냐에 따라서 결과는 달라지게 된다.
데이터는 똑같고 어떤 람다식을 대입하느냐에 따라 처리 결과가 달라진다.
참고사항 -인터페이스의 익명 구현 객체를 람다식으로 표현하려면 인터페이스의 추상 메소드가 단 하나여야 한다. -인터페이스가 단 하나의 추상 메소드를 가질 때, 이를 함수형 인터페이스라고 한다. -인터페이스가 함수형 인터페이스임을 보장하기 위해서는 @FunctionalInterface 어노테이션을 붙이면 된다.
@FunctionalInterface
public interface Calculable {
//추상 메소드
void calculate(int x, int y);
}
LambdaExample.java
public class LambdaExample {
public static void main(String[] args) {
action((x, y) -> {
int result = x + y;
System.out.println("result: " + result);
});
action((x, y) -> {
int result = x - y;
System.out.println("result: " + result);
});
}
public static void action(Calculable calculable) {
//데이터
int x = 10;
int y = 4;
//데이터 처리
calculable.calculate(x, y);
}
}
/*
result: 14
result: 6
*/
매개변수가 없는 람다식
아래의 코드들은 매개변수가 없는 람다식 예제이다.
Workable.java
@FunctionalInterface
public interface Workable {
void work();
}
Person.java
public class Person {
public void action(Workable workable) {
workable.work();
}
}
LambdaExample.java
public class LambdaExample {
public static void main(String[] args) {
Person person = new Person();
//실행문이 두 개 이상인 경우 중괄호 필요
person.action(() -> {
System.out.println("출근을 합니다.");
System.out.println("프로그래밍을 합니다.");
});
//실행문이 한 개일 경우 중괄호 생략 가능
person.action(() -> System.out.println("퇴근합니다."));
}
}
/*
출근을 합니다.
프로그래밍을 합니다.
퇴근합니다.
*/
아래의 코드들은 익명 구현 객체를 람다식으로 대체해 버튼의 클릭 이벤트를 처리하는 예제이다.
Button.java
public class Button {
//정적 중첩 인터페이스
@FunctionalInterface
public static interface ClickListener {
//추상 메소드
void onClick();
}
//필드
private ClickListener clickListener;
//메소드
public void setClickListener(ClickListener clickListener) {
this.clickListener = clickListener;
}
public void click() {
this.clickListener.onClick();
}
}
ButtonExample.java
public class ButtonExample {
public static void main(String[] args) {
//Ok 버튼 객체 생성
Button btnOk = new Button();
//Ok 버튼 객체에 람다식(ClickListener 익명 구현 객체) 주입
btnOk.setClickListener(() -> {
System.out.println("Ok 버튼을 클릭했습니다.");
});
//Ok 버튼 클릭하기
btnOk.click();
//Cancel 버튼 객체 생성
Button btnCancel = new Button();
//Cancel 버튼 객체에 람다식(ClickListener 익명 구현 객체) 주입
btnCancel.setClickListener(() -> {
System.out.println("Cancel 버튼을 클릭했습니다.");
});
//Cancel 버튼 클릭하기
btnCancel.click();
}
}
/*
Ok 버튼을 클릭했습니다.
Cancel 버튼을 클릭했습니다.
*/
매개변수가 있는 람다식
함수형 인터페이스의 추상 메소드에 매개변수가 있을 경우 람다식은 아래와 같이 작성할 수 있다.
매개변수를 선언할 때 타입은 생략할 수 있고, 구체적인 타입 대신에 var를 사용할 수도 있다.
@FunctionalInterface
public interface Speakable {
void speak(String content);
}
Person.java
public class Person {
public void action1(Workable workable) {
workable.work("홍길동", "프로그래밍");
}
public void action2(Speakable speakable) {
speakable.speak("안녕하세요");
}
}
LambdaExample.java
public class LambdaExample {
public static void main(String[] args) {
Person person = new Person();
//매개변수가 두 개일 경우
person.action1((name, job) -> {
System.out.print(name + "이 ");
System.out.println(job + "을 합니다.");
});
person.action1((name, job) -> System.out.println(name + "이 " + job + "을 하지 않습니다."));
//매개변수가 한 개일 경우
person.action2(word -> {
System.out.print("\"" + word + "\"");
System.out.println("라고 말합니다.");
});
person.action2(word -> System.out.println("\"" + word + "\"라고 외칩니다."));
}
}
/*
홍길동이 프로그래밍을 합니다.
홍길동이 프로그래밍을 하지 않습니다.
"안녕하세요"라고 말합니다.
"안녕하세요"라고 외칩니다.
*/
리턴값이 있는 람다식
함수형 인터페이스의 추상 메소드에 리턴값이 있을 경우 람다식은 아래와 같이 작성할 수 있다.
public class Person {
public void action(Calcuable calcuable) {
double result = calcuable.calc(10, 4);
System.out.println("결과: " + result);
}
}
public class Computer {
public static double staticMethod(double x, double y) {
return x + y;
}
public double instanceMethod(double x, double y) {
return x * y;
}
}
MethodReferenceExample.java
public class MethodReferenceExample {
public static void main(String[] args) {
Person person = new Person();
//정적 메소드일 경우
//람다식
//person.action((x, y) -> Computer.staticMethod(x, y));
//메소드 참조
person.action(Computer :: staticMethod);
//인스턴스 메소드일 경우
Computer com = new Computer();
//람다식
//person.action((x, y) -> com.instanceMethod(x, y));
//메소드 참조
person.action(com :: instanceMethod);
}
}
/*
결과: 14.0
결과: 40.0
*/
매개변수의 위치를 바꿔야할 경우 메소드 참조를 사용할 수 없다.
매개변수의 메소드 참조
아래와 같이 람다식에서 제공되는 a 매개변수의 메소드를 호출해서 b 매개변수를 매개값으로 사용하는 경우도 있다.
(a, b) -> { a.instanceMethod(b); }
이를 메소드 참조로 표현하면 아래와 같다.
작성 방법은 정적 메소드 참조와 동일하지만, a의 인스턴스 메소드가 사용된다는 점에서 다르다.
@FunctionalInterface
public interface Comparable {
int compare(String a, String b);
}
public class Person {
public void ordering(Comparable comparable) {
String a = "홍길동";
String b = "김길동";
int result = comparable.compare(a, b);
if(result < 0) {
System.out.println(a + "은 " + b + "보다 앞에 옵니다.");
} else if(result == 0) {
System.out.println(a + "은 " + b + "과 같습니다.");
} else {
System.out.println(a + "은 " + b + "보다 뒤에 옵니다.");
}
}
}
MethodReferenceExample.java
public class MethodReferenceExample {
public static void main(String[] args) {
Person person = new Person();
person.ordering((a, b) -> {
return a.compareToIgnoreCase(b);
});
person.ordering((a, b) -> a.compareToIgnoreCase(b));
person.ordering(String :: compareToIgnoreCase); //매개변수의 메소드 참조
//위 세개의 코드 모두 같은 기능을 동작하는 코드
}
}
/*
홍길동은 김길동보다 뒤에 옵니다.
홍길동은 김길동보다 뒤에 옵니다.
홍길동은 김길동보다 뒤에 옵니다.
*/
a.compareToIgnoreCase(b) 위 메소드는 String 클래스의 인스턴스 메소드이며, 리턴값은 a 문자열이 b 문자열보다 크면 양의 정수, 같으면 0, 작으면 의 정수 (대소문자 고려사항 무시)이다.
생성자 참조
생성자를 참조한다는 것은 객체를 생성하는 것을 의미한다.
람다식이 단순히 객체를 생성하고 리턴하도록 구성된다면 람다식을 생성자 참조로 대치할 수 있다.
아래의 코드에서 람다식은 단순히 객체를 생성한 후 리턴만 한다.
(a, b) -> {return new 클래스(a,b);}
이것을 생성자 참조로 표현하면 아래와 같다.
클래스 :: new
생성자가 오버로딩되어 여러 개가 있을 경우, 컴파일러는 함수형 인터페이스의 추상 메소드와 동일한 매개변수 타입과 개수를 가지고 있는 생성자를 찾아 실행한다. 만약 해당 생성자가 존재하지 않으면 컴파일 오류가 발생한다.
Creatable1.java
@FunctionalInterface
public interface Creatable1 {
public Member create(String id);
}
Creatable2.java
@FunctionalInterface
public interface Creatable2 {
public Member create(String id, String name);
}
Member.java
public class Member {
private String id;
private String name;
public Member(String id) {
this.id = id;
System.out.println("Member(String id)");
}
public Member(String id, String name) {
this.id = id;
this.name = name;
System.out.println("Member(String id, String name)");
}
@Override
public String toString() {
String info = "{ id: " + id + ", name: " + name + " }";
return info;
}
}
Person.java
public class Person {
public Member getMember1(Creatable1 creatable) {
String id = "winter";
Member member = creatable.create(id);
return member;
}
public Member getMember2(Creatable2 creatable) {
String id = "winter";
String name = "한겨울";
Member member = creatable.create(id, name);
return member;
}
}
ConstructorReferenceExample.java
public class ConstructorReferenceExample {
public static void main(String[] args) {
Person person = new Person();
//---------------------------------------------------------
Member m1 = person.getMember1((id)->{
Member m = new Member(id);
return m;
});
m1 = person.getMember1((id)->{
return new Member(id);
});
m1 = person.getMember1((id)-> new Member(id));
m1 = person.getMember1( Member :: new );
System.out.println(m1);
System.out.println();
//위 코드는 모두 같은 결과를 내는 코드이다.
//---------------------------------------------------------
Member m2 = person.getMember2((id, name)->{
Member m = new Member(id, name);
return m;
});
m2 = person.getMember2((id, name)->{
return new Member(id, name);
});
m2 = person.getMember2((id, name)-> new Member(id, name));
m2 = person.getMember2( Member :: new );
System.out.println(m2);
//위 코드는 모두 같은 결과를 내는 코드이다.
}
}
/*
Member(String id)
Member(String id)
Member(String id)
Member(String id)
{ id: winter, name: null }
Member(String id, String name)
Member(String id, String name)
Member(String id, String name)
Member(String id, String name)
{ id: winter, name: 한겨울 }
*/
import java.util.ArrayList;
import java.util.LinkedList;
import java.util.List;
public class LinkedListExample {
public static void main(String[] args) {
//ArrayList 컬렉션 객체 생성
List<String> list1 = new ArrayList<String>();
//LinkedList 컬렉션 객체 생성
List<String> list2 = new LinkedList<String>();
//시작 시간과 끝 시간을 저장할 변수 선언
long startTime;
long endTime;
//ArrayList 컬렉션에 저장하는 시간 측정
startTime = System.nanoTime();
for(int i=0; i<10000; i++) {
list1.add(0, String.valueOf(i));
}
endTime = System.nanoTime();
System.out.printf("%-17s %8d ns \n", "ArrayList 걸린 시간: ", (endTime-startTime) );
//LinkedList 컬렉션에 저장하는 시간 측정
startTime = System.nanoTime();
for(int i=0; i<10000; i++) {
list2.add(0, String.valueOf(i));
}
endTime = System.nanoTime();
System.out.printf("%-17s %8d ns \n", "LinkedList 걸린 시간: ", (endTime-startTime) );
}
}
/*
ArrayList 걸린 시간: 5813200 ns
LinkedList 걸린 시간: 880900 ns
*/
Set 컬렉션
Set 컬렉션은 저장 순서가 유지되지 않는다.
또한 객체를 중복해서 저장할 수 없고, 하나의 null만 저장할 수 있다.
Set 컬렉션은 수학의 집합에 비유될 수 있다.
집합은 순서와 상관없고 중복이 허용되지 않기 때문이다.
Set 컬렉션에는 HashSet, LinkedHashSet, TreeSet 등이 있는데, Set 컬렉션에서 공통적으로 사용 가능한 Set 인터페이스의 메소드는 아래 표와 같다.
LinkedHashSet : 요소의 저장 순서를 유지하지 않는다. TreeSet : 요소를 정렬된 순서로 유지한다.
기능
메소드
설명
객체 추가
boolean add(E e)
주어진 객체를 성공적으로 저장하면 true를 리턴하고 중복 객체면 false를 리턴
객체 검색
boolean contains(Object o)
주어진 객체가 저장되어 있는지 여부
isEmpty()
컬렉션이 비어 있는지 조사
Iterator<E> iterator()
저장된 객체를 한 번씩 가져오는 반복자 리턴
int size()
저장되어 있는 전체 객체 수 리턴
객체 삭제
void clear()
저장된 모든 객체를 삭제
boolean remove(Object o)
주어진 객체를 삭제
Iterator<E> iterator() 이 메소드는 Interface Iterable<E>의 추상 메소드이다. Iterable을 한국어로 번역하면 '반복할 수 있는'이다. 향상된 for문에서 선언할 수 있는 객체는 이 인터페이스를 구현한 객체만 올 수 있다. iterator() 메소드를 호출하면 해당 객체의 참조를 Iterator 타입으로 가져온다.
HashSet
Set 컬렉션 중에서 가장 많이 사용되는 것이 HashSet이다.
아래는 HashSet 컬렉션을 생성하는 방법이다.
Set<E> set = new HashSet<E>();
Set<E> set = new HashSet<>();
Set set new Hashset();
HashSet은 동일한 객체는 중복 저장하지 않는다.
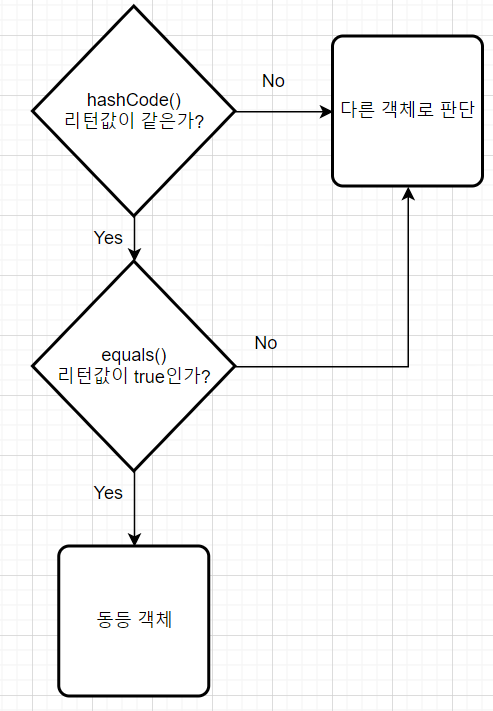
여기서 동일한 객체란 동등 객체를 말한다. HashSet은 다른 객체라도 HashCode() 메소드의 리턴값이 같고, equals() 메소드가 true를 리턴하면 동일한 객체라고 판단하고 중복 저장하지 않는다.
import java.util.*;
public class HashSetExample {
public static void main(String[] args) {
//HashSet 컬렉션 생성
Set<String> set = new HashSet<String>();
//객체 저장
set.add("Java");
set.add("JDBC");
set.add("Servlet/JSP");
set.add("Java"); //<-- 중복 객체이므로 저장하지 않음
set.add("iBATIS");
//저장된 객체 수 출력
int size = set.size();
System.out.println("총 객체 수: " + size);
}
}
/*
총 객체 수: 4
*/
public class Member {
public String name;
public int age;
public Member(String name, int age) {
this.name = name;
this.age = age;
}
//hashCode 재정의
@Override
public int hashCode() {
return name.hashCode() + age;
}
//equals 재정의
@Override
public boolean equals(Object obj) {
if(obj instanceof Member target) {
return target.name.equals(name) && (target.age==age) ;
} else {
return false;
}
}
}
HashSetExample.java
import java.util.*;
public class HashSetExample {
public static void main(String[] args) {
//HashSet 컬렉션 생성
Set<Member> set = new HashSet<Member>();
//Member 객체 저장
set.add(new Member("홍길동", 30));
set.add(new Member("홍길동", 30));
//저장된 객체 수 출력
System.out.println("총 객체 수 : " + set.size());
}
}
/*
총 객체 수 : 1
*/
Set 컬렉션은 인덱스로 객체를 검색해서 가져오는 메소드가 없다.
대신 객체를 한 개씩 반복해서 가져와야 하는데, 두 가지 방법이 있다.
1. for 문을 이용하는 방법
for문에서 HashSet 객체를 직접적으로 추가 및 삭제를 하면 안 된다.
Set<E> set = new HashSet<E>();
for(E e : set)
{
for(String element : set)
{
if(element.equals("JSP"))
{
set.remove(element);
}
}
}
위 코드에서 set의 객체의 개수가 4개라고 하면, 처음에 for문은 반복하는 횟수가 4번으로 정해져 있다. 하지만 중간에 remove나 add 메소드로 인해서 set 객체의 개수가 감소 또는 증가하면 4번 반복을 돌아야하는데 객체의 수가 4개 미만 또는 초과이므로 for문은 오류를 내뿜는다. 따라서 직접적인 add나 remove 메소드 호출은 지양해야 한다.
추가 또는 삭제를 하려면 iterator() 메소드로 반복자를 얻어서 작업을 하는 것이 안전하다.
2. iterator() 메소드로 반복자를 얻어 객체를 하나씩 가져오기
Set<E> set = new HashSet<E>();
Iterator<E> iterator = set.iterator();
iterator는 Set 컬렉션의 객체를 가져오거나 제거하기 위해 아래의 메소드를 제공한다.
리턴 타입
메소드명
설명
boolean
hasNext()
가져올 객체가 있으면 true를 리턴하고 없으면 false를 리턴
E
next()
컬렉션에서 하나의 객체를 가져온다.
void
remove()
next()로 가져온 객체를 Set 컬렉션에서 제거한다.
사용 방법은 아래와 같다.
while(iterator.hasNext()) {
E e = iterator.next();
}
hasNext() 메소드로 가져올 객체가 있는지 먼저 확인하고, true를 리턴할 때만 next() 메소드로 객체를 가져온다.
만약, next()로 가져온 객체를 컬렉션에서 제거하고 싶다면 remove() 메소드를 사용한다.
HashSet 추가, 삭제, 제거 예제
import java.util.*;
public class HashSetExample {
public static void main(String[] args) {
//HashSet 컬렉션 생성
Set<String> set = new HashSet<String>();
//객체 추가
set.add("Java");
set.add("JDBC");
set.add("JSP");
set.add("Spring");
//객체를 하나씩 가져와서 처리
Iterator<String> iterator = set.iterator();
while(iterator.hasNext()) {
//객체를 하나 가져오기
String element = iterator.next();
System.out.println( element);
if(element.equals("JSP")) {
//가져온 객체를 컬렉션에서 제거
iterator.remove();
}
}
System.out.println();
//객체 제거
set.remove("JDBC");
//객체를 하나씩 가져와서 처리
for(String element : set) {
System.out.println(element);
}
}
}
/*
Java
JSP
JDBC
Spring
Java
Spring
*/
Map 컬렉션
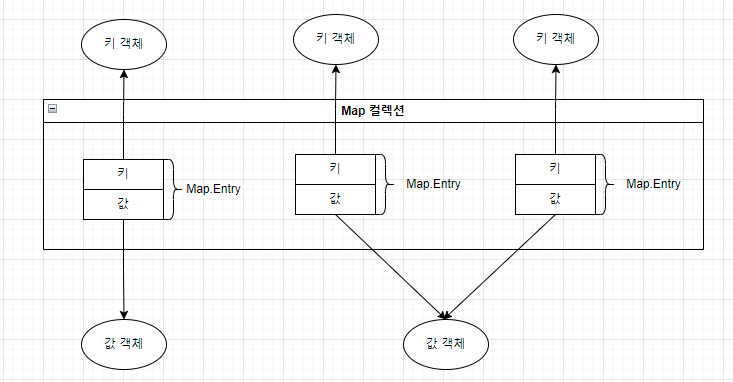
Map 컬렉션은 키(key)와 값(value)으로 구성된 엔트리(entry) 객체를 저장한다.
여기서 키와 값은 모두 객체이다.
키는 중복저장할 수 없지만, 값은 중복 저장할 수 있다.
기존에 저장된 키와 동일한 키로 값을 저장하면 기존의 값은 없어지고 새로운 값으로 바뀌게 된다.
Map 컬렉션에는 HashMap, HashTable, LinkedHash, Properties, TreeMap 등이 있다.
Map 컬렉션에서 공통적으로 사용 가능한 Map 인터페이스 메소드는 아래와 같다.
기능
메소드
설명
객체 추가
V put(K key, V value)
주어진 키와 값을 추가, 저장이 되면 값을 리턴
객체 검색
boolean containsKey(Object key)
주어진 키가 있는지 여부
boolean containsValue(object value)
주어진 값이 있는지 여부
Set<Map.Entry<K, V>> entrySet()
키와 값의 쌍으로 구성된 모든 Map.Entry 객체를 Set에 담아서 리턴
V get(Object key)
주어진 키의 값을 리턴
boolean isEmpty()
컬렉션이 비어있는지 여부
Set<K> keySet()
모든 키를 Set 객체에 담아서 리턴
int size()
저장된 키의 총 수를 리턴
Collection<V> values()
저장된 모든 값 Collection에 담아서 리턴
객체 삭제
void clear()
모든 Map.Entry(키와 값)를 삭제
V remove(Object key)
주어진 키와 일치하는 Map.Entry 삭제, 삭제가 되면 값을 리턴
위 표에서 K와 V는 타입 파라미터이고, K는 키 타입, V는 값 타입을 말한다.
HashMap
HashMap은 키로 사용할 객체가 hashCode() 메소드의 리턴값이 같고 equals() 메소드가 true를 리턴할 경우, 동일 키로 보고 중복 저장을 허용하지 않는다.
아래는 HashMap 컬렉션을 생성하는 방법이다. K와 V는 각각 키와 값의 타입을 지정할 수 있는 타입 파라미터이다.
public class Person implements Comparable<Person> {
public String name;
public int age;
public Person(String name, int age) {
this.name = name;
this.age = age;
}
@Override
public int compareTo(Person o) {
if(age<o.age) return -1;
else if(age == o.age) return 0;
else return 1;
}
}
ComparableExample.java
import java.util.TreeSet;
public class ComparableExample {
public static void main(String[] args) {
//TreeSet 컬렉션 생성
TreeSet<Person> treeSet = new TreeSet<Person>();
//객체 저장
treeSet.add(new Person("홍길동", 45));
treeSet.add(new Person("감자바", 25));
treeSet.add(new Person("박지원", 31));
//객체를 하나씩 가져오기
for(Person person : treeSet) {
System.out.println(person.name + ":" + person.age);
}
}
}
/*
감자바:25
박지원:31
홍길동:45
*/
Comparator
비교 기능이 있는 Comparable 구현 객체를 TreeSet에 저장하거나 TreeMap의 키로 저장하는 것이 원칙이다
하지만 비교 기능이 없는 Comparable 비구현 객체를 저장하고 싶다면 TreeSet과 TreeMap을 생성할 때 비교자(Comparator)를 아래와 같이 제공하면 된다.
TreeSet<K, V> treeSet = new TreeMap<E>(new ComparatorImpl());
TreeMap<K, V> treeMap = new TreeMap<K, V>(new ComparatorImpl());
비교자는 Comparator 인터페이스를 구현한 객체를 말하는데, Comparator 인터페이스에는 compare() 메소드가 정의되어 있다.
비교자는 이 메소드를 재정의해서 비교 결과를 정수 값으로 리턴하면 된다.
리턴 타입
메소드
설명
int
compare(T o1, T o2)
o1과 o2가 동등하다면 0을 리턴 o1이 o2 앞에 오게 하려면 음수를 리턴 o1이 o2 뒤에 오게 하려면 양수를 리턴
아래는 Comparable을 구현하고 있지 않은 사용자 정의 객체를 TreeSet에 저장하는 예제이다.
이 게시글은 이것이 자바다(저자 : 신용권, 임경균)의 책과 동영상 강의를 참고하여 개인적으로 정리하는 글임을 알립니다.
데몬 스레드(Daemon Thread)
데몬 스레드는 주 스레드의 작업을 돕는 보조적인 역할을 수행하는 스레드이다.
주 스레드가 종료되면 데몬 스레드도 따라서 자동으로 종료된다.
스레드를 데몬으로 만들기 위해서는 주 스레드가 데몬이 될 스레드의 setDaemon(true)를 호출하면 된다.
주 스레드와 메인 스레드는 같을 수도 있고 다를 수도 있다. 메인 스레드에서, 다른 스레드를 데몬 스레드로 설정했다면 메인 스레드는 주 스레드가 된다. 하지만 메인 스레드가 아닌 A 스레드에서, B 스레드를 데몬 스레드로 설정했다면 B 스레드 관점에서는 A 스레드가 주 스레드가 된다.
아래의 코드에서는 메인 스레드에서 또 다른 스레드를 데몬 스레드로 설정했기 때문에 메인 스레드가 주 스레드가 된다.
public class Main {
public static void main(String[] args) {
XXXThread thread = new XXXThread();
thread.setDaemon(true);
thread.start();
}
}
따라서 메인 스레드가 종료되면 데몬 스레드도 종료된다.
아래의 예제는 메인 스레드에서 자동 저장 스레드를 데몬 스레드로 설정한다.
메인 스레드가 종료되면 자동 저장 스레드도 종료되는 것을 보여준다.
AutoSaveThread.java
public class AutoSaveThread extends Thread {
public void save() {
System.out.println("작업 내용을 저장함.");
}
@Override
public void run() {
while(true) {
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
break;
}
save();
}
}
}
DaemonExample.java
public class DaemonExample {
public static void main(String[] args) {
AutoSaveThread autoSaveThread = new AutoSaveThread();
autoSaveThread.setDaemon(true);
autoSaveThread.start();
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
}
System.out.println("메인 스레드 종료");
}
}
/*
작업 내용을 저장함.
작업 내용을 저장함.
메인 스레드 종료
*/
스레드풀(ThreadPool)
무분별하게 스레드를 늘리면 CPU 사용량이 증가하고 메모리 사용량이 늘어난다.
이에 따라 애플리케이션의 성능 또한 급격히 저하된다.
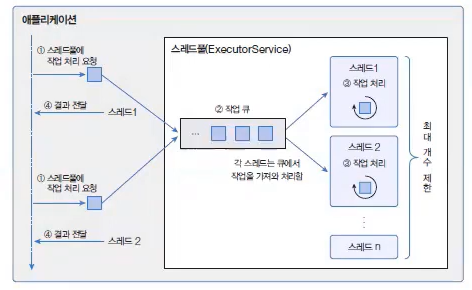
이렇게 병렬 작업 증가로 인한 스레드의 폭증을 막으려면 스레드풀을 사용하는 것이 좋다.
스레드 풀은 작업 처리에 사용되는 스레드를 제한된 개수만큼 정해놓는다.
이후 작업들은 작업 큐(Queue)에 들어가게 된다.
작업 큐에 있는 작업들은 스레드가 하나씩 맡아서 처리한다.
예를 들어 작업이 20개 있고 최대 스레드 수가 5개라고 하면, 작업 1, 2, 3, 4, 5가 각각 스레드 1, 2, 3, 4, 5에 배정되고 스레드 1에 배정된 작업 1이 끝나면 스레드 1에 작업 6이 배정된다. 스레드 2에 배정된 작업 2가 끝나면 스레드 2에 작업 7이 배정된다. 이렇게 최대 스레드 수는 5개로 제한하고 먼저 작업이 끝나는 스레드에 작업 큐에 있는 다음 작업을 처리하도록 맡기는 것이다.
이렇게 하면 작업량이 증가해도 스레드의 개수가 늘어나지 않아 성능 저하가 발생하지 않는다.
출처 : 이것이 자바다 유튜브 동영상 강의
스레드풀 생성
자바는 스레드풀을 생성하고 사용할 수 있도록 java.util.concurrent 패키지에서 ExecutorService 인터페이스와 Executors 클래스를 제공하고 있다.
Executors의 아래의 두 정적 메소드를 사용하면 간단하게 스레드풀인 ExecutorsService 구현 객체를 만들 수 있다.
메소드명(매개변수)
초기 수
코어 수
최대 수
newCachedThreadPool()
0
0
int 범위 최대 값(이론상)
newFixedThreadPool(int n)
0
생성된 수
n
초기 수 : 스레드풀이 생성될 때 기본적으로 생성되는 스레드 수
코어 수 : 스레드가 증가된 후 사용되지 않는 스레드를 제거할 때 최소한 풀에서 유지하는 스레드 수
최대 수 : 증가되는 스레드의 한도 수
newCachedThreadPool()
newCachedThreadPool()로 생성된 스레드풀의 초기 수와 코어 수는 0개이고, 작업 개수가 많아지면 새 스레드를 생성시켜 작업을 한다.
이 메소드는 스레드 최대 수를 정하지 않는다. 따라서 이론상 int 범위 최대 값인 약 21억 개의 스레드가 생성될 수 있다.
스레드풀 종료 newCachedThreadPool()와 달리 newFixedThreadPool(int n)은 스레드가 아무 작업을 하지 않아도 스레드는 제거가 되지 않는다
사용자 정의 스레드풀
위 두 메소드를 사용하지 않고 직접 ThreadPoolExecutor로 스레드풀을 생성할 수도 있다.
아래의 예시는 초기 수 0개, 코어 수 3개, 최대 수 100개인 스레드풀을 생성하는 코드이다.
스레드가 120초 동안 놀고 있을 경우 해당 스레드를 풀에서 제거한다.
ExecutorService threadPool = new ThreadPoolExecutor(
3, // 코어 스레드 개수
100, // 최대 스레드 개수
120L, // 최대 놀 수 있는 시간 (이 시간 넘으면 스레드 풀에서 쫓겨 남.)
TimeUnit.SECONDS, // 놀 수 있는 시간 단위
new SynchronousQueue<Runnable>() // 작업 큐
);
스레드풀 종료
스레드풀의 스레드는 기본적으로 데몬 스레드가 아니기 때문에 main 스레드가 종료되더라도 작업을 처리하기 위해 계속 실행 상태로 남아 있다.
스레드풀의 모든 스레드를 종료하려면 ExecutorService의 다음 두 메소드 중 하나를 실행해야 한다.
리턴 타입
메소드명(매개변수)
설명
void
shutdown()
현재 처리 중인 작업뿐만 아니라 작업 큐에 대기하고 있는 모든 작업을 처리한 뒤에 스레드풀을 종료시킨다.
List(Runnable)
shutdownNow()
현재 작업 처리 중인 스레드를 interrupt해서 작업을 중지시키고 스레드풀을 종료시킨다. 또한 작업 큐에 있는 미처리된 작업을 리턴한다.
shutdown() : 남아있는 작업을 마무리하고 스레드풀을 종료할 때
shutdownNow() : 남아있는 작업과 상관없이 강제 종료를 할 때
아래의 예제는 최대 5개의 스레드로 운영되는 스레드풀을 생성하고 종료한다.
ExecutorServiceExample.java
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class ExecutorServiceExample {
public static void main(String[] args) {
//스레드풀 생성
ExecutorService executorService = Executors.newFixedThreadPool(5);
//작업 생성과 처리 요청
//스레드풀 종료
executorService.shutdownNow();
}
}
작업 생성과 처리 요청
작업 생성
하나의 작업은 Runnable 또는 Callable 구현 객체로 표현한다.
Runnable : 작업 처리 완료 후 리턴값 없음
Callable : 작업 처리 완료 후 리턴값 있음
각각 run() 메소드와 call() 메소드를 호출시켜서 작업을 생성한다.
Runnable 익명 구현 객체
new Runnable(){
@Override
public void run(){
//스레드가 처리할 작업 내용
}
}
Callable 익명 구현 객체
new Callable<T>(){
@Override
public T call() throws Exception {
//스레드가 처리할 작업 내용
return T;
}
}
call() 의 리턴 타입은 Callable <T>에서 지정한 T 타입 파라미터와 동일한 타입이어야 한다.(제네릭 개념)
작업 처리 요청
작업 처리 요청이란 ExcutorService의 작업 큐에 Runnable 또는 Callable 객체를 넣는 행위를 말한다.
작업 처리 요청을 위해 ExecutorService는 아래의 두 가지 메소드를 제공한다.
리턴 타입
메소드명(매개변수)
설명
void
execute(Runnable command)
-Runnable을 작업 큐에 저장 -작업 처리 결과를 리턴하지 않음
Future<T>
submit(Callable<T> task)
-Callable을 작업 큐에 저장 -작업 처리 결과를 얻을 수 있도록 Future를 리턴
Runnable 또는 Callable 객체가 ExecutorService의 작업 큐에 들어간다.
ExecutorService는 들어온 객체를 처리할 스레드가 있는지 보고, 없다면 스레드를 새로 생성시킨다.
스레드는 작업 큐에서 Runnable 또는 Callable 객체를 꺼내와 run() 또는 call() 메소드를 실행하면서 작업을 처리한다. 즉, 작업 처리 요청을 한 뒤, 작업을 생성하고 작업을 처리한다.
아래의 예제에 대한 설명
이메일을 보내는 작업으로, 1000개의 Runnable을 생성한 다음 execute() 메소드로 작업 큐에 넣는다.
ExcutorService는 최대 5개 스레드로 작업 큐에서 Runnable을 하나씩 꺼낸다.
꺼낸 Runnable 객체의 run() 메소드를 실행하면서 작업을 처리한다.
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class RunnableExecuteExample {
public static void main(String[] args) {
//1000개의 메일 생성
String[][] mails = new String[1000][3];
for(int i=0; i<mails.length; i++) {
mails[i][0] = "admin@my.com";
mails[i][1] = "member"+i+"@my.com";
mails[i][2] = "신상품 입고";
}
//ExecutorService 생성
ExecutorService executorService = Executors.newFixedThreadPool(5);
//이메일을 보내는 작업 생성 및 처리 요청
for(int i=0; i<1000; i++) {
final int idx = i;
executorService.execute(new Runnable() {
@Override
public void run() {
Thread thread = Thread.currentThread();
String from = mails[idx][0];
String to = mails[idx][1];
String content = mails[idx][2];
System.out.println("[" + thread.getName() + "] " + from + " ==> " + to + ": " + content);
}
});
}
//ExecutorService 종료
executorService.shutdown();
}
}
/*
....
....
....
[pool-1-thread-4] admin@my.com ==> member987@my.com: 신상품 입고
[pool-1-thread-4] admin@my.com ==> member988@my.com: 신상품 입고
[pool-1-thread-4] admin@my.com ==> member989@my.com: 신상품 입고
[pool-1-thread-5] admin@my.com ==> member974@my.com: 신상품 입고
[pool-1-thread-5] admin@my.com ==> member991@my.com: 신상품 입고
[pool-1-thread-4] admin@my.com ==> member990@my.com: 신상품 입고
[pool-1-thread-4] admin@my.com ==> member993@my.com: 신상품 입고
[pool-1-thread-3] admin@my.com ==> member984@my.com: 신상품 입고
[pool-1-thread-3] admin@my.com ==> member995@my.com: 신상품 입고
[pool-1-thread-3] admin@my.com ==> member996@my.com: 신상품 입고
[pool-1-thread-2] admin@my.com ==> member983@my.com: 신상품 입고
[pool-1-thread-2] admin@my.com ==> member998@my.com: 신상품 입고
[pool-1-thread-1] admin@my.com ==> member981@my.com: 신상품 입고
[pool-1-thread-2] admin@my.com ==> member999@my.com: 신상품 입고
[pool-1-thread-3] admin@my.com ==> member997@my.com: 신상품 입고
[pool-1-thread-4] admin@my.com ==> member994@my.com: 신상품 입고
[pool-1-thread-5] admin@my.com ==> member992@my.com: 신상품 입고
*/
//이메일을 보내는 작업 생성 및 처리 요청에서의 final int executorService.execute에 Runnable 인터페이스의 구현 객체를 대입해야 한다. 위 예제에서는 익명 구현 객체를 대입한다. 따라서 로컬 변수를 로컬 클래스에서 사용할 때 제한이 있다.
아래의 예제에 대한 설명
자연수 덧셈을 하는 작업으로 100개의 Callable을 생성하고 submit() 메소드로 작업 큐에 넣는다.
ExecutorService는 최대 5개 스레드로 작업 큐에서 Callable 객체를 하나씩 꺼낸다.
꺼낸 객체의 call() 메소드를 실행하면서 작업을 처리한다.
Future의 get() 메소드는 작업이 끝날 때까지 기다렸다가 call() 메소드가 리턴한 값을 리턴한다.
import java.util.concurrent.Callable;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.Future;
public class CallableSubmitExample {
public static void main(String[] args) {
//ExecutorService 생성
ExecutorService executorService = Executors.newFixedThreadPool(5);
//계산 작업 생성 및 처리 요청
for(int i=1; i<=100; i++) {
final int idx = i;
Future<Integer> future = executorService.submit(new Callable<Integer>() {
@Override
public Integer call() throws Exception {
int sum = 0;
for(int i=1; i<=idx; i++) {
sum += i;
}
Thread thread = Thread.currentThread();
System.out.println("[" + thread.getName() + "] 1~" + idx + " 합 계산");
return sum;
}
});
try {
int result = future.get();
System.out.println("\t리턴값: " + result);
} catch (Exception e) {
e.printStackTrace();
}
}
//ExecutorService 종료
executorService.shutdown();
}
}
/*
...
...
...
[pool-1-thread-2] 1~92 합 계산
리턴값: 4278
[pool-1-thread-3] 1~93 합 계산
리턴값: 4371
[pool-1-thread-4] 1~94 합 계산
리턴값: 4465
[pool-1-thread-5] 1~95 합 계산
리턴값: 4560
[pool-1-thread-1] 1~96 합 계산
리턴값: 4656
[pool-1-thread-2] 1~97 합 계산
리턴값: 4753
[pool-1-thread-3] 1~98 합 계산
리턴값: 4851
[pool-1-thread-4] 1~99 합 계산
리턴값: 4950
[pool-1-thread-5] 1~100 합 계산
리턴값: 5050
*/
하나의 프로세스가 두 가지 이상의 작업을 처리할 수 있는 이유는 멀티 스레드가 있기 때문이다.
프로세스의 모든 스레드가 종료가 되어야 프로세스가 종료된다.
하나의 스레드에서 예외가 발생하면 모든 스레드가 종료되어 결국 프로세스도 종료되므로 예외 처리에 만전을 기해야 한다.
메인 스레드 모든 자바 프로그램은 메인 스레드가 main() 메소드를 실행하면서 시작된다. 메인 스레드는 main() 메소드의 첫 코드부터 순차적으로 실행하고, main() 메소드의 마지막 코드를 실행하거나 return문을 만나면 실행을 종료한다.
메인 스레드는 필요에 따라 추가 작업 스레드들을 만들어서 실행시킬 수 있다. 멀티 스레드에서는 실행 중인 스레드가 하나라도 있다면 프로세스는 종료되지 않는다. 즉, 메인 스레드가 작업 스레드보다 먼저 종료되더라도 작업 스레드가 하나라도 실행 중이라면 프로세스는 종료되지 않는다.
한 프로세스에 하나의 JVM이 실행된다. 여러 자바 프로세스가 실행중이라면 여러 JVM이 있는 것이다.
스레드 생성
중요한 점은 아래의 방법 중에 어떤 방법을 사용해서 생성을 하든 상관이 없지만, 작업 스레드를 실행하려면 스레드 객체의 start() 메소드를 호출해야 한다.
Runnable 구현 객체를 만들어서 생성
Runnable 구현 클래스 작성
작업 스레드 객체를 직접 생성하려면, java.lang 패키지에 있는 Thread 클래스로부터 작업 스레드 객체를 생성하면 된다.
객체를 생성할 때에는 Runnable 구현 객체를 매개값으로 갖는 생성자를 호출해야 한다.
Runnable 인터페이스 스레드가 작업을 실행할 때 사용하는 인터페이스이다. Runnable에는 run() 메소드가 정의되어 있는데, 구현 클래스는 run()을 오버라이딩해서 스레드가 실행할 코드를 가지고 있어야 한다.
Runnable 구현 클래스는 작업 내용을 정의한 것이므로, 스레드에게 전달해야 한다.
Runnable 구현 객체를 생성한 후 Thread 생성자 매개값으로 Runnable 객체를 전달하면 된다.
Task.java
public class Task implements Runnable{
@Override
public void run() {
//실행할 코드 작성
}
}
Main.java
public class Main {
public static void main(String[] args) {
Runnable task = new Task();
Task task2 = new Task();
Thread thread = new Thread(task);
Thread thread2 = new Thread(task2);
thread.start();
thread2.start();
}
}
Runnable 익명 구현 객체로 생성
아래와 같이 익명 구현 객체를 생성하여 매개값으로 사용할 수도 있다.
public class Main {
public static void main(String[] args) {
Thread thread = new Thread(new Runnable() { //익명 구현 객체
@Override
public void run() {
//실행할 코드 작성
}
});
thread.start();
}
}
Thread 자식 클래스로 생성
명시적인 자식 클래스 정의 후 생성
작업 스레드 객체를 생성하는 또 다른 방법은 Thread의 자식 객체로 만드는 것이다.
Thread 클래스를 상속한 다음 run() 메소드를 오버라이딩해서 스레드가 실행할 코드를 작성하고 객체를 생성하면 된다.
Task.java
public class Task extends Thread{
@Override
public void run() {
//실행할 코드 작성
}
}
Main.java
public class Main {
public static void main(String[] args) {
//방법1
Thread thread = new Thread(new Task());
thread.start();
//방법2
Task task = new Task();
Thread thread2 = new Thread(task);
thread2.start();
//방법3
Task task2 = new Task();
task2.start();
}
}
Thread 익명 자식 객체로 생성
명시적인 자식 클래스를 정의하지 않고, 아래와 같이 Thread 익명 자식 객체를 사용할 수도 있다.
public class Main {
public static void main(String[] args) {
Thread thread = new Thread() {
@Override
public void run() {
//실행할 코드 작성
}
};
thread.start();
}
}
스레드 이름
메인 스레드는 main이라는 이름을 가진다.
작업 스레드는 자동적으로 Thread-n이라는 이름을 가진다.
다른 이름으로 설정하고 싶다면 Thread 클래스의 setName() 메소드를 사용하면 된다.
당연히 스레드를 실행하기 전에 스레드 이름을 바꿔야 한다.
thread.setName("스레드 이름");
어떤 스레드가 실행하고 있는지 확인하려면 정적 메소드인 CurrentThread()로 스레드 객체의 참조를 얻은 다음 getName() 메소드로 스레드의 이름을 얻고 출력해 보면 된다.
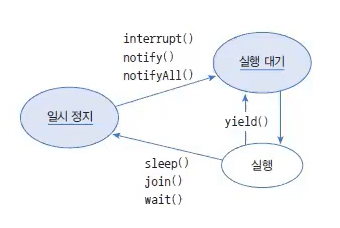
스레드 객체를 생성(NEW)하고, start() 메소드를 호출하면 곧바로 스레드가 실행되는 것이 아니라 실행 대기 상태(RUNNABLE)가 된다.
실행 대기하는 스레드는 CPU 스케쥴링에 따라 CPU를 점유하고 run() 메소드를 실행한다. 이때를 실행(RUNNING) 상태라고 한다.
실행 스레드는 run() 메소드를 모두 실행하기 전에 스케줄링에 의해 다시 실행 대기 상태로 돌아갈 수 있다. 그리고 다른 스레드가 실행 상태가 된다.
이렇게 스레드는 실행 대기 상태와 실행 상태를 번갈아 가면서 자신의 run() 메소드를 조금씩 실행한다.
실행 상태에서 run() 메소드가 종료되면 더 이상 실행할 코드가 없기 때문에 스레드의 실행은 멈추게 된다. 이 상태를 종료 상태(TERMINATED)라고 한다.
출처 : 이것은 자바다 유튜브 동영상 강의
위 개념은 운영체제 CPU 스케줄링의 개념이다.
아래는 일시 정지로 가기 위한 메소드와 다시 실행 대기 상태로 가기 위한 메소드를 보여준다.
구분
메소드
설명
일시 정지로 보냄
sleep(long millis)
주어진 시간 동안 스레드를 일시 정지 상태로 만든다. 주어진 시간이 지나면 자동적으로 실행 대기 상태가 된다.
join()
join() 메소드를 호출한 스레드는 일시 정지 상태가 된다. 실행 대기 상태가 되려면, join() 메소드를 가진 스레드가 종료되어야 한다.
wait()
동기화 블록 내에서 스레드를 일시 정지 상태로 만든다
일시 정지에서 벗어남
interrupt()
일시 정지 상태일 경우, interruptedException을 발생시켜 실행 대기 상태 또는 종료 상태로 만든다.
notify() notifyAll()
wait() 메소드로 인해 일시 정지 상태인 스레드를 실행 대기 상태로 만든다.
실행 대기로 보냄
yield()
실행 상태에서 다른 스레드에게 실행을 양보하고 실행 대기 상태가 된다.
위 표에서 wait()과 notify(), notifyAll()은 Object 클래스의 메소드이고 그 외는 Thread 클래스의 메소드이다.
Object 클래스의 메소드들은 스레드 동기화에서 다룬다.
주어진 시간 동안 일시 정지
실행 중인 스레드를 일정 시간 멈추게 하고 싶다면 Thread 클래스의 정적 메소드인 sleep()을 이용하면 된다.
매개값에는 얼마 동안 일시 정지 상태로 있을 것인지 밀리세컨드(1/1000초) 단위로 시간을 주면 된다.
일시 정지 상태에서는 InterruptedException이 발생할 수 있기 때문에 sleep() 메소드는 예외 처리가 필요하다.
try {
Thread.sleep(3000); //3초간 일시 정지
} catch(InterruptedException e) {}
다른 스레드의 종료를 기다림
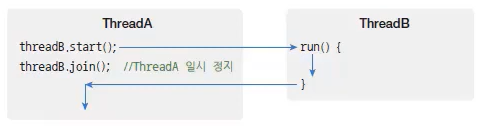
스레드는 다른 스레드와 독립적으로 실행하지만 다른 스레드가 종료될 때까지 기다렸다가 실행을 해야 하는 경우도 있다.
이를 위해 스레드는 join() 메소드를 제공한다.
아래의 그림에서 ThreadA가 ThreadB의 join() 메소드를 호출하면 ThreadA는 ThreadB가 종료할 때까지 일시 정지 상태가 된다.
ThreadB의 run() 메소드가 종료되고 나서야 비로소 ThreadA는 일시 정지에서 풀려 다음 코드를 실행한다.
일시 정지 상태에서는 InterruptedException이 발생할 수 있기 때문에 join() 메소드는 예외 처리가 필요하다.
SumThread.java
public class SumThread extends Thread {
private long sum;
public long getSum() {
return sum;
}
public void setSum(long sum) {
this.sum = sum;
}
@Override
public void run() {
for(int i=1; i<=100; i++) {
sum+=i;
}
}
}
JoinExample.java
public class JoinExample {
public static void main(String[] args) {
SumThread sumThread = new SumThread();
sumThread.start();
try {
sumThread.join();
} catch (InterruptedException e) {
}
System.out.println("1~100 합: " + sumThread.getSum());
}
}
join() 메소드를 호출하지 않으면 1~100의 합인 5050이 아니라 더 작은 값이 나올 수도 있다.
다른 스레드에게 실행 양보
스레드가 원하는 상태가 아니라면 다른 스레드에게 실행을 양보하고 자신은 실행 대기 상태로 가게 할 수도 있다.
이런 기능을 위해 Thread는 yield() 메소드를 제공한다.
yield()를 호출한 스레드는 실행 대기 상태로 돌아가고, 다른 스레드가 실행 상태가 된다.
아래 예제에서는 처음 5초 동안은 ThreadA의 work 필드의 값이 false이기 때문에 실행 대기상태가 된다.
5초 이후에는 work 필드의 값이 true로 바뀌어서 출력문이 계속 실행된다.
다시 5초 이후에는 work 필드의 값이 false로 바뀌어서 다시 실행 대기상태가 된다.
WorkThread.java
public class WorkThread extends Thread {
//필드
public boolean work = false;
//생성자
public WorkThread(String name) {
setName(name);
}
//메소드
@Override
public void run() {
while(true) {
if(work) {
System.out.println(getName() + ": 작업처리");
} else {
Thread.yield();
}
}
}
}
YieldExample.java
public class YieldExample {
public static void main(String[] args) {
WorkThread workThreadA = new WorkThread("workThreadA");
workThreadA.start();
try { Thread.sleep(5000); } catch (InterruptedException e) {}
workThreadA.work = true;
try { Thread.sleep(10000); } catch (InterruptedException e) {}
workThreadA.work = false;
}
}
스레드 동기화
동기화 메소드와 블록
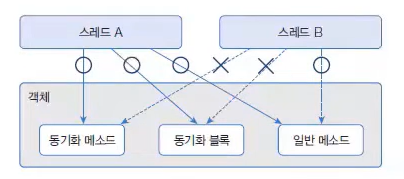
스레드 A가 공유 자원(객체)을 사용 중인데 다른 스레드인 스레드 B가 접근하려고 하면 스레드 A가 사용 중인 객체를 다른 스레드가 변경할 수 없도록 하려면 스레드 작업이 끝날 때까지 객체에 잠금을 걸면 된다.
이를 위해 자바는 동기화 메소드와 블록을 제공한다.
공유 객체의 동기화 메소드는 하나의 스레드만 사용할 수 있다.
공유 객체의 동기화 블록은 하나의 스레드만 사용할 수 있다.
공유 객체의 일반 메소드는 모든 스레드가 사용할 수 있다.
출처 : 이것은 자바다 유튜브 동영상 강의
동기화 메소드는 다음과 같이 synchronized 키워드를 붙이면 된다.
synchronized 키워드는 인스턴스와 정적 메소드 어디든 붙일 수 있다.
public synchronized void method(){
//단 하나의 스레드만 실행하는 영역
}
스레드가 동기화 메소드를 실행하는 즉시 객체는 잠금이 일어나고, 메소드 실행이 끝나면 잠금이 풀린다.
메소드 전체가 아닌 일부 영역을 실행할 때만 객체 잠금을 걸고 싶다면 다음과 같이 동기화 블록을 만들면 된다.
public void method(){
//여러 스레드가 실행할 수 있는 영역
synchronized(공유 객체){
//단 하나의 스레드만 실행하는 영역
}
//여러 스레드가 실행할 수 있는 영역
}
아래의 예제에서 공유 객체는 Calculator이다.
Calculator의 setMemory1()는 동기화 메소드이다.
Calculator의 setMemory2()는 동기화 블록을 포함하는 메소드이다.
setMemory1()과 setMemory2()는 하나의 스레드만 실행이 가능한 메소드가 된다.
두 메소드는 동일하게 매개값을 memory 필드에 값을 저장을 하고 2초간 일시 정지 후 memory 필드의 값을 출력한다.
두 개의 스레드가 공유 객체의 memory 값을 바꾼다.
Calculator.java
public class Calculator {
private int memory;
public int getMemory() {
return memory;
}
public synchronized void setMemory1(int memory) {
this.memory = memory;
try {
Thread.sleep(2000);
} catch(InterruptedException e) {}
System.out.println(Thread.currentThread().getName() + ": " + this.memory);
}
public void setMemory2(int memory) {
synchronized(this) {
this.memory = memory;
try {
Thread.sleep(2000);
} catch(InterruptedException e) {}
System.out.println(Thread.currentThread().getName() + ": " + this.memory);
}
}
}
User1Thread.java
public class User1Thread extends Thread {
private Calculator calculator;
public User1Thread() {
setName("User1Thread");
}
public void setCalculator(Calculator calculator) {
this.calculator = calculator;
}
@Override
public void run() {
calculator.setMemory1(100);
}
}
User2Thread.java
public class User2Thread extends Thread {
private Calculator calculator;
public User2Thread() {
setName("User2Thread");
}
public void setCalculator(Calculator calculator) {
this.calculator = calculator;
}
@Override
public void run() {
calculator.setMemory2(50);
}
}
SynchronizedExample.java
public class SynchronizedExample {
public static void main(String[] args) {
Calculator calculator = new Calculator();
User1Thread user1Thread = new User1Thread();
user1Thread.setCalculator(calculator);
user1Thread.start();
User2Thread user2Thread = new User2Thread();
user2Thread.setCalculator(calculator);
user2Thread.start();
}
}
/*
User1Thread: 100
User2Thread: 50
*/
wait()과 notify()를 이용한 스레드 제어
경우에 따라서는 두 개의 스레드를 교대로 번갈아 가며 실행할 때도 있다.
정확한 교대 작업이 필요할 경우, 자신의 작업이 끝나면 상대방 스레드를 일시 정지 상태에서 풀어주고 자신은 일시 정지 상태로 만들면 된다.
이 방법의 핵심은 공유 객체에 있다.
공유 객체는 두 스레드가 작업할 내용을 각각 동기화 메소드로 정해 놓는다.
한 스레드가 작업을 완료하면 notify() 메소드를 호출해서 일시 정지 상태에 있는 다른 스레드를 실행 대기 상태로 만든다.
자신은 두 번 작업을 하지 않도록 wait() 메소드를 호출하여 일시 정지 상태로 만든다.
출처 : 이것은 자바다 유튜브 동영상 강의
notify()는 wait() 에 의해 일시 정지된 스레드 중 한 개를 실행 대기 상태로 만들고, notifyAll()은 wait()에 의해 일시 정지된 모든 스레드를 실행 대기 상태로 만든다.
주의할 점은 이 두 메소드는 동기화 메소드 또는 동기화 블록 내에서만 사용할 수 있다는 것이다.
아래의 예제는 공유 객체인 WorkObject에 동기화 메소드인 ThreadA와 ThreadB가 각 methodA와 methodB를 호출한다.
WorkObject.java
public class WorkObject {
public synchronized void methodA() {
Thread thread = Thread.currentThread();
System.out.println(thread.getName() + ": methodA 작업 실행");
notify();
try {
wait();
} catch (InterruptedException e) {
}
}
public synchronized void methodB() {
Thread thread = Thread.currentThread();
System.out.println(thread.getName() + ": methodB 작업 실행");
notify();
try {
wait();
} catch (InterruptedException e) {
}
}
}
ThreadA.java
public class ThreadA extends Thread {
private WorkObject workObject;
public ThreadA(WorkObject workObject) {
setName("ThreadA");
this.workObject = workObject;
}
@Override
public void run() {
for(int i=0; i<10; i++) {
workObject.methodA();
}
}
}
ThreadB.java
public class ThreadB extends Thread {
private WorkObject workObject;
public ThreadB(WorkObject workObject) {
setName("ThreadB");
this.workObject = workObject;
}
@Override
public void run() {
for(int i=0; i<10; i++) {
workObject.methodB();
}
}
}
WaitNotifyExample.java
public class WaitNotifyExample {
public static void main(String[] args) {
WorkObject workObject = new WorkObject();
ThreadA threadA = new ThreadA(workObject);
ThreadB threadB = new ThreadB(workObject);
threadA.start();
threadB.start();
}
}
/*
ThreadA: methodA 작업 실행
ThreadB: methodB 작업 실행
ThreadA: methodA 작업 실행
ThreadB: methodB 작업 실행
ThreadA: methodA 작업 실행
ThreadB: methodB 작업 실행
ThreadA: methodA 작업 실행
ThreadB: methodB 작업 실행
ThreadA: methodA 작업 실행
ThreadB: methodB 작업 실행
ThreadA: methodA 작업 실행
ThreadB: methodB 작업 실행
ThreadA: methodA 작업 실행
ThreadB: methodB 작업 실행
ThreadA: methodA 작업 실행
ThreadB: methodB 작업 실행
ThreadA: methodA 작업 실행
ThreadB: methodB 작업 실행
ThreadA: methodA 작업 실행
ThreadB: methodB 작업 실행
*/
스레드 안전 종료
스레드는 자신의 run() 메소드가 모두 실행되면 자동적으로 종료되지만, 경우에 따라서는 실행 중인 스레드를 즉시 종료할 필요가 있다.
스레드를 강제 종료시키기 위해 Thread는 stop() 메소드를 제공하고 있으나 이 메소드는 사용하지 않는 것을 추천한다.
스레드를 갑자기 종료하게 되면 사용 중이던 리소스들이 불안전한 상태로 남겨지기 때문이다.
스레드를 안전하게 종료하는 방법은 리소스들을 정리하고 run() 메소드를 빨리 종료하는 것이다.
이를 위해 아래의 두 가지 방법을 사용한다.
조건 이용
interrupt() 메소드 이용
조건 이용
스레드가 while 문으로 반복 실행할 경우, 조건을 이용해서 run() 메소드의 종료를 유도한다.
public class XXXThread extends Thread {
private boolean stop;
public void setStop(boolean stop) {
this.stop = stop;
}
@Override
public void run() {
while(!stop) {
System.out.println("실행 중");
}
System.out.println("리소스 정리");
System.out.println("실행 종료");
}
}
interrupt() 메소드 이용
일시 정지를 이용한 방법
interrupt() 메소드는 스레드가 일시 정지 상태에 있을 때 InterruptedException 예외를 발생시키는 역할을 한다.
이것을 이용하면 예외 처리를 통해 run() 메소드를 정상 종료시킬 수 있다.
public void run() {
try {
while(true) {
//...
Thread.sleep(1); //일시 정지
}
} catch(InterruptedException e) {
}
//스레드가 사용한 리소스 정리
}
즉, 이 방법은 스레드가 일시 정지 상태에 있을 때만 가능하다.
일시 정지 상태일 때 처리하는 InterruptedException 예외 처리를 이용한 방법이기 때문이다.
PrintThread.java
public class PrintThread extends Thread {
public void run() {
try {
while(true) {
System.out.println("실행 중");
Thread.sleep(1);
}
} catch(InterruptedException e) {
}
System.out.println("리소스 정리");
System.out.println("실행 종료");
}
}
InterruptExample.java
public class InterruptExample {
public static void main(String[] args) {
Thread thread = new PrintThread();
thread.start();
try {
Thread.sleep(100); //메인 스레드를 일시정지. 작업 스레드를 멈추는게 아님
} catch (InterruptedException e) {
}
thread.interrupt(); //작업 스레드 인터럽트
}
}
/*
실행 중
실행 중
실행 중
실행 중
실행 중
실행 중
실행 중
실행 중
실행 중
리소스 정리
실행 종료
*/
일시 정지를 이용하지 않는 방법
Thread의 interrupted()와 isInterrupt() 메소드는 interrupt() 메소드 호출 여부를 리턴한다.
interrupted() : 정적 메소드 -> 객체 생성 없이 사용 가능
isInterrupt() : 인스턴스 메소드 -> 객체를 생성해야 사용 가능
이 방법은 위 메소드를 이용하여 interrupt() 메소드 호출 여부를 확인하고 호출되었다면, while 블록을 빠져나가 리소스 정리를 하고 스레드를 종료하게끔 유도한다.
PrintThread.java
public class PrintThread extends Thread{
public void run() {
while(true){
System.out.println("실행 중");
if(Thread.interrupted()) { //interrupt() 메소드가 호출되었는지 확인
break; //interrupt() 메소드가 호출되었다면 while문 탈출
}
}
System.out.println("리소스 정리");
System.out.println("실행 종료");
}
}
Main.java
public class Main {
public static void main(String[] args) {
Thread thread = new PrintThread();
thread.start();
try {
Thread.sleep(1); //메인 스레드를 일시정지, 작업 스레드를 일시 정지 하는것이 아님
}catch (InterruptedException e) {
}
thread.interrupt(); //작업 스레드 인터럽트
}
}
/*
실행 중
실행 중
실행 중
실행 중
실행 중
실행 중
실행 중
실행 중
실행 중
실행 중
실행 중
실행 중
실행 중
실행 중
실행 중
실행 중
실행 중
실행 중
실행 중
실행 중
실행 중
실행 중
실행 중
실행 중
실행 중
실행 중
실행 중
실행 중
실행 중
실행 중
실행 중
실행 중
리소스 정리
실행 종료
*/
이 게시글은 이것이 자바다(저자 : 신용권, 임경균)의 책과 동영상 강의를 참고하여 개인적으로 정리하는 글임을 알립니다.
제네릭의 개념
제네릭이란 결정되지 않은 타입을 파라미터로 처리하고 실제 사용할 때 파라미터를 구체적인 타입으로 대체시기는 기능이다.
아래의 코드는 Box 클래스에서 결정되지 않은 content의 타입을 T라는 타입 파라미터로 정의한 것이다.
public class Box <T>{
public T content;
}
<T>는 T가 타입 파라미터임을 뜻하는 기호로, 타입이 필요한 자리에 T를 사용할 수 있음을 알려주는 역할을 한다.
Box 클래스는 T가 무엇인지 모르지만, Box 객체가 생성될 시점에 다른 타입으로 대체된다는 것을 알고 있다.
Box의 내용물로 String 타입을 저장하고 싶으면 아래와 같이 코드를 작성하면 된다.
Box<String> box = new Box<String>();
box.content = "안녕하세요";
String con = box.content;
Box의 내용물로 int 타입을 저장하고 싶으면 아래와 같이 코드를 작성하면 된다.
Box<Integer> box = new Box<Integer>();
box.content = 100; //자동 박싱
int con = box.content;
<T>에서 타입 파라미터로 쓰이는 T는 A부터 Z까지 어떤 알파벳을 써도 상관이 없다.
또한 주의할 점은 타입 파라미터를 대체하는 타입은 클래스 및 인터페이스이다.
아래와 같이 변수를 선언할 때와 동일한 타입으로 호출하고 싶다면 생성자 호출시 생성자에는 타입명을 명시하지 않아도 된다.
Box<Integer> box = new Box<>();
제네릭 타입
public class 클래스명<A, B, ...>{}
public interface 인터페이스명<A, B, ...>{}
제네릭 타입 : 결정되지 않은 타입을 파라미터로 가지는 클래스와 인터페이스
선언부에 <> 부호가 붙고 그 사이에 타입 파라미터들이 위치
타입 파라미터 : 일반적으로 대문자 알파벳 한 글자로 표현
외부에서 제네릭 타입을 사용하려면 타입 파라미터에 구체적인 타입을 지정해야 함
외부에서 제네릭 타입을 지정하지 않으면 암묵적으로 Object 객체가 사용된다.
타입 파라미터 타입 파라미터는 기본적으로 Object 타입으로 간주되므로 Object가 가지고 있는 메소드를 호출할 수 있다. 예를 들어, 타입 파라미터는 Object의 equals() 메소드를 호출할 수 있고, 타입 파라미터로 대입된 객체가 equals() 메소드가 재정의 되어 있다면 재정의된 equals() 메소드가 호출된다.
제네릭 타입 클래스
Product.java
//제네릭 타입
public class Product<K, M> {
//필드
private K kind;
private M model;
//메소드
public K getKind() { return this.kind; }
public M getModel() { return this.model; }
public void setKind(K kind) { this.kind = kind; }
public void setModel(M model) { this.model = model; }
}
GenericExample.java
public class GenericExample {
public static void main(String[] args) {
//K는 Tv로 대체, M은 String으로 대체
Product<Tv, String> product1 = new Product<>();
//Setter 매개값은 반드시 Tv와 String을 제공
product1.setKind(new Tv());
product1.setModel("스마트Tv");
//Getter 리턴값은 Tv와 String이 됨
Tv tv = product1.getKind();
String tvModel = product1.getModel();
//------------------------------------------------------------------------
//K는 Car로 대체, M은 String으로 대체
Product<Car, String> product2 = new Product<>();
//Setter 매개값은 반드시 Car와 String을 제공
product2.setKind(new Car());
product2.setModel("SUV자동차");
//Getter 리턴값은 Car와 String이 됨
Car car = product2.getKind();
String carModel = product2.getModel();
}
}
제네릭 타입 인터페이스
제네릭 타입 인터페이스 선언
public interface Rentable<P> {
P rent();
}
public class Home {
public void turnOnLight() {
System.out.println("전등을 켭니다.");
}
}
public class Car {
public void run() {
System.out.println("자동차가 달립니다.");
}
}
아래의 HomeAgency와 CarAgency는 Rentable의 타입 파라미터를 Home과 Car로 대체해서 구현하는 방법을 보여준다.
public class HomeAgency implements Rentable<Home> {
@Override
public Home rent() {
return new Home();
}
}
public class CarAgency implements Rentable<Car>{
@Override
public Car rent() {
return new Car();
}
}
public class GenericExample {
public static void main(String[] args) {
HomeAgency homeAgency = new HomeAgency();
Home home = homeAgency.rent();
home.turnOnLight();
CarAgency carAgency = new CarAgency();
Car car = carAgency.rent();
car.run();
}
}
/*
전등을 켭니다.
자동차가 달립니다.
*/
위에 예제의 실행 내용과 같이
HomeAgency와 CarAgency를 생성하면 각 Home 객체와 Car 객체가 리턴되고, 각 메소드를 호출할 수 있다.
제네릭 메소드
제네릭 메소드 : 타입 파라미터를 가지고 있는 메소드
타입 파라미터가 메소드 선언부에 정의
타입 파라미터, 리턴타입, 메소드명(매개변수) 순으로 선언한다
타입 파라미터는 메소드로 들어온 매개값이 어떤 타입이냐에 따라 컴파일 과정에서 구체적인 타입으로 대체된다.
아래의 boxing() 메소드는 타입 파라미터로 <T>를 정의하고 매개 변수 타입과 리턴 타입에서 T를 사용한다.
정확한 리턴 타입은 T를 내용물로 갖는 Box 객체이다.
public <T> Box<T> boxing(T t){...}
Box.java
public class Box<T> {
//필드
private T t;
//Getter 메소드
public T get() {
return t;
}
//Setter 메소드
public void set(T t) {
this.t = t;
}
}
GenericExample.java
public class GenericExample {
//제네릭 메소드
public static <T> Box<T> boxing(T t) {
Box<T> box = new Box<T>();
box.set(t);
return box;
}
public static void main(String[] args) {
//제네릭 메소드 호출
Box<Integer> box1 = boxing(100);
int intValue = box1.get();
System.out.println(intValue);
//제네릭 메소드 호출
Box<String> box2 = boxing("홍길동");
String strValue = box2.get();
System.out.println(strValue);
}
}
/*
100
홍길동
*/
제한된 타입 파라미터
제한된 타입 파라미터 : 모든 타입으로 대체할 수 없고, 특정 타입과 자식 또는 구현 관계에 있는 타입만 대체할 수 있는 타입 파라미터
예를 들어 숫자를 연산하는 제네릭 메소드는 대체 타입으로 Number 또는 자식 클래스(Byte, Short, Integer, Long, Double)로 제한
상위 타입은 클래스뿐만 아니라 인터페이스도 가능(인터페이스라고 해서 implements 를 사용하지 않음)
public class GenericExample {
//제한된 타입 파라미터를 갖는 제네릭 메소드
public static <T extends Number> boolean compare(T t1, T t2) {
//T의 타입을 출력
System.out.println("compare(" + t1.getClass().getSimpleName() + ", " +
t2.getClass().getSimpleName() + ")"); //리플렉션
//Number의 메소드 사용
double v1 = t1.doubleValue(); //Number의 메소드 사용
double v2 = t2.doubleValue(); //Number의 메소드 사용
return (v1 == v2);
}
public static void main(String[] args) {
//제네릭 메소드 호출
boolean result1 = compare(10, 20);
System.out.println(result1);
System.out.println();
//제네릭 메소드 호출
boolean result2 = compare(4.5, 4.5);
System.out.println(result2);
}
}
/*
compare(Integer, Integer)
false
compare(Double, Double)
true
*/
와일드카드 타입 파라미터
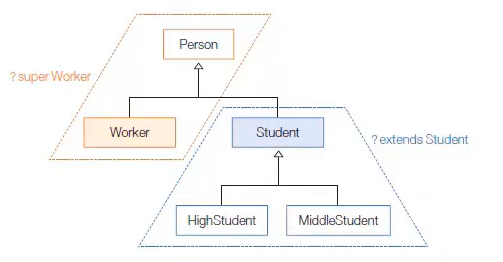
출처 : 이것이 자바다 유튜브 영상
위와 같은 상속 관계가 있다고 가정해 보자.
Student와 자식 클래스인 HighStudent, middleStudent만 타입 파라미터의 대체 타입으로 가능하도록 하고 싶다면 아래와 같이 선언하면 된다.
리턴타입 메소드명(제네릭타입<? extends Student> 변수) {}
반대로 Worker와 부모 클래스인 Person만 가능하도록 매개변수를 아래와 같이 선언할 수 있다.
리턴타입 메소드명(제네릭타입<? super Worker> 변수) {}
아래와 같이 어떤 타입이든 가능하도록 매개변수를 선언할 수도 있다.
리턴타입 메소드명(제네릭타입<?> 변수) {}
아래의 예제에 대한 설명
registerCourse1()은 모든 사람이 들을 수 있는 과정을 등록한다.
registerCourse2()는 학생만 들을 수 있는 과정을 등록한다.
registerCourse3() 은 직장인과 일반인만 들을 수 있는 과정을 등록한다.
Person.java
public class Person {
}
class Worker extends Person {
}
class Student extends Person {
}
class HighStudent extends Student {
}
class MiddleStudent extends Student{
}
Applicant.java
public class Applicant<T> {
public T kind;
public Applicant(T kind) {
this.kind = kind;
}
}
Course.java
public class Course {
//모든 사람이면 등록 가능
public static void registerCourse1(Applicant<?> applicant) {
System.out.println(applicant.kind.getClass().getSimpleName() +
"이(가) Course1을 등록함");
}
//학생만 등록 가능
public static void registerCourse2(Applicant<? extends Student> applicant) {
System.out.println(applicant.kind.getClass().getSimpleName() +
"이(가) Course2를 등록함");
}
//직장인 및 일반인만 등록 가능
public static void registerCourse3(Applicant<? super Worker> applicant) {
System.out.println(applicant.kind.getClass().getSimpleName() +
"이(가) Course3을 등록함");
}
}
import java.util.Scanner;
public class Main {
public static void main(String[] args) throws Exception{
Scanner sc = new Scanner(System.in);
int N = sc.nextInt();
int K = sc.nextInt();
System.out.print(factorial(N) / (factorial(N-K)*factorial(K)));
}
static int factorial(int n)
{
long count = 1;
if(n == 0) return (int)count;
else
{
for(int i = 1; i <= n; ++i) count *= i;
return (int)count;
}
}
}
이 게시글은 이것이 자바다(저자 : 신용권, 임경균)의 책과 동영상 강의를 참고하여 개인적으로 정리하는 글임을 알립니다.
math 클래스의 random() 메소드 이용
0.0과 1.0 사이(0.0 포함, 1.0 미포함) 범위에 속하는 하나의 double 타입의 값을 리턴
double v11 = Math.random(); //0.47464615326686044
1부터 n까지 랜덤 수를 뽑는 코드는 아래와 같다.
int num = (int) (Math.random()*n) + 1;
아래의 예제는 1~45의 랜덤 숫자 중 6개 뽑는 예제이다.
public class Main {
public static void main(String[] args) {
for(int i = 0; i < 6; ++i)
{
int num = (int) (Math.random()*45) + 1;
System.out.print(num + " ");
}
}
}
/*
38 45 9 7 40 37
*/
java.util.random 클래스 이용
객체 생성
설명
Random()
현재 시간을 이용해서 종자값을 자동 설정
Random(long seed)
주어진 종자값을 사용
종자값(seed)이란 난수를 만드는 알고리즘에 사용되는 값으로, 종자값이 같으면 같은 난수를 얻는다. 종자값이 다른데 같은 난수를 얻는 확률은 매우 드물다.
아래의 표는 Random 클래스가 제공하는 메소드이다.
리턴값
메소드
설명
boolean
nextBoolean()
boolean 타입의 난수를 리턴
double
nextDouble()
double 타입의 난수를 리턴(0.0 <= ~ < 1.0)
int
nextInt()
int 타입의 난수를 리턴(-2^32 <= ~ <= 2^32 -1)
int
nextInt(int n)
int 타입의 난수를 리턴(0 <= ~ < n)
진짜 난수, 의사 난수 로또에서 번호가 적힌 공을 하나하나 꺼내 당첨 번호를 결정하는 것과 같은 것이 '진짜 난수'를 생성하는 과정이다. 의사 난수는 실제와 비슷하다는 뜻이다. 컴퓨터가 생성하는 난수는 진짜 난수가 아니라 의사 난수이다.
그럼 Random 클래스가 생성하는 난수는 뭔데? 컴퓨터 과학에서 난수는 보통 특정 입력값이나 컴퓨터 환경에 따라 무작위로 선택한 것처럼 보이는 난수를 생성한다. Random 클래스에서는 48비트의 seed를 사용하고, 이 seed는 선형 합동법이라는 계산법에 의해 특정 수(난수)로 바뀐다. seed의 값과 컴퓨터 환경이 같다면 그 결과값은 항상 같다. 따라서 seed를 매번 바꿔줘야한다. seed를 매번 다르게 하기 위해 현재 시간을 이용하는 것이 일반적이다. 현재 시간은 매 순간 바뀌므로 이전에 발생한 의사 난수를 다시 생성하지는 않는다. ex) seed 가 1인 경우 : 항상 1 -> 105 -> 999 -> 1002 ... 의 순서로 숫자를 생성 ex) seed 가 2인 경우 : 항상 2 -> 892 -> 7291 -> 10123 ... 의 순서로 숫자를 생성
이는 C언어에서도 마찬가지이다. 아래의 코드는 비주얼스튜디오 환경에서 C++로 작성된 코드이다.
#include<iostream>
using namespace std;
void main()
{
int num = rand();
int num2 = rand();
cout << num << ", " << num2 << endl;
}
위 코드로 몇 번이고 계속 실행을 해도 같은 수만 출력이 된다.
아래의 코드는 랜덤으로 로또 번호를 선택하고, 랜덤으로 당첨번호를 추출한다. 이후 두 로또번호가 일치하는지 확인한다.
로또는 1~45 범위의 정수 숫자만 선택할 수 있으므로 nextInt(45) + 1 연산식을 사용한다