이 글은 혼자 공부하는 컴퓨터 구조 + 운영체제 (저자 : 강민철)의 책과 유튜브 영상을 참고하여 개인적으로 정리하는 글임을 알립니다.
CPU의 성능을 높이기 위해서 아래 3개의 방법을 생각해 볼 수 있다.
클럭 신호를 빠르게 하는 방법
코어 수를 늘리는 방법
스레드의 수를 늘리는 방법
클럭
컴퓨터 부품들은 클럭 신호에 맞춰 움직인다.
CPU는 명령어 사이클에 따라 명령어들을 실행한다.
클럭 신호가 빠르게 반복되면 CPU를 비롯한 컴퓨터 부품들은 그만큼 빠른 박자에 맞춰 움직이게 된다.
실제로 클럭 속도가 높은 CPU는 일반적으로 성능이 좋다.
CPU는 매번 일정한 클럭 속도가 아니라 고성능을 요구하는 순간에는 빠르고, 그렇지 않을 때는 느리게 작동한다. 최대 클럭 속도를 강제로 더 끌어올릴 수 있는데, 이런 기법을 오버클럭킹이라고 한다.
하지만 클럭 속도를 끝도 없이 늘린다고해서 무조건 CPU의 성능이 좋아지는 것은 아니다.
그렇게 하면 CPU의 발열 문제가 심각해지기 때문이다.
코어와 멀티코어
CPU는 명령어를 실행하는 부품이다.
많은 전공 서적들의 전통적인 관점에서 명령어를 실행하는 부품은 원칙적으로 하나만 존재했다. 하지만 현대에는 CPU 내부에 명령어를 실행하는 부품을 얼마든지 만들 수 있게 되었다.
CPU의 정의로 알고 있던 "명령어를 실행하는 부품"은 오늘날 코어라는 용어로 사용된다.
현대의 CPU는 명령어를 실행하는 부품을 여러개 포함하는 부품으로 명칭의 범위가 확장되었다.
https://velog.io/@mrcocoball
코어를 여러 개 포함하고 있는 CPU를 멀티코어CPU 또는 멀티코어 프로레서라고 부른다.
당연히 처리 속도는 단일 코어보다 멀티코어가 더 빠르다.
하지만 코어의 수를 n개 늘린다고 해서 CPU의 연산속도가 n배 늘어나지 않는다.
이는 4인분의 요리를 100명의 요리사가 만든다고 생각하면 편하다.
중요한 것은 코어마다 처리할 명령어들을 얼마나 적절하게 분배하느냐 이다.
스레드와 멀티 스레드
스레드의 사전적 의미는 실행 흐름의 단위이다.
스레드는 하드웨어적 스레드와, 소프트웨어적 스레드로 나뉜다.
하드웨어적 스레드 : 하나의 코어가 동시에 처리하는 명령어 단위
소프트웨어적 스레드 : 하나의 프로그램에서 독립적으로 실행되는 단위
하드웨어적 스레드
스레드를 하드웨어적으로 정의하면 "하나의 코어가 동시에 처리하는 명령어 단위"를 의미한다.
CPU에서 사용하는 스레드라는 용어는 보통 하드웨어적 스레드를 의미한다.
1코어 1스레드는 명령어를 실행하는 부품이 하나있고, 한 번에 하나씩 명령어를 실행하는 CPU를 의미한다.
2코어 4스레드는 명령어를 실행하는 부품이 두 개있고, 한 번에 네 개의 명령어를 실행하는 CPU를 의미한다.
한 코어로 여러 명령어를 실행하는 CPU를 멀티 프로세서 또는 멀티스레드 CPU라고 한다.
소프트웨어적 스레드
스레드를 소프트웨어적으로 정의하면 "하나의 프로그램에서 독립적으로 실행되는 단위"를 의미한다.
프로그래밍 언어나 운영체제를 공부할 때 접하는 스레드는 보통 소프트웨어적으로 정의된 스레드를 의미한다.
하나의 프로그램은 실행되는 과정에서 한 부분만 실행될 수도 있지만, 프로그램의 여러 부분이 동시에 실행될 수도 있다.
메모리에서의 싱글 스레드와 멀티 스레드를 도식화하면 아래와 같다.
https://velog.io/@mrcocoball
한 번에 하나의 명령어를 처리하는 1코어 1스레드 CPU도 소프트웨어적 스레드를 수십개 실행할 수 있다.
이는 하드웨어적 관점의 스레드 하나가 소프트웨어적 스레드 여러개를 엄청나게 빠른속도로 번갈아가면서 하기때문이다.
이러한 엄청난 속도로 번갈아가면서 작업을 하면 일반적인 사람은 동시에 작업을 처리한다고 느끼게된다.
멀티스레드 프로세서
용어의 혼동을 방지하기 위해 이제부터 소프트웨어적으로 정의된 스레드는 "스레드", CPU에서 사용되는 스레드는 '하드웨어 스레드'라고 하겠다.
멀티스레드 프로세서는 하나의 코어로 여러 명령어를 동시에 처리하는 CPU이다.
이 프로세서의 핵심은 레지스터이다.
하나의 프로세서로 여러 명령어를 동시에 처리하도록 만들려면 프로그램 카운터, 스택 포인터, 데이터 버퍼 레지스터 등 하나의 명령어를 처리하기 위해 꼭 필요한 레지스터들을 여러개 가지고 있으면 된다.
하나의 명령어를 실행하기 위해 꼭 필요한 레지스터들을 편의상 레지스터 세트라고 한다면, 레지스터 세트가 한 개인 CPU는 한 개의 명령어를 처리하기 위한 정보들을 기억할 뿐이지만, 레지스터 세트가 두 개인 CPU는 두 개의 명령어를 처리하기 위한 정보들을 기억할 수 있다.
따라서 ALU와 제어장치가 두 개의 레지스터 세트에 저장된 명령어를 해석하고 실행하면 하나의 코어에서 두 개의 명령어가 동시에 실행된다
하드웨어 스레드를 이용해 하나의 코어로도 여러 명령어를 동시에 처리할 수 있다고 했는데, 메모리 속 프로그램 입장에서 봤을 때 하드웨어 스레드는 마치 한 번에 하나의 명령어를 처리하는 CPU나 다름이 없다. (여러개의 스레드를 번갈아가면서 하는 것이기 때문)
2코어 4스레드 CPU는 한 번에 4개의 명령어를 처리할 수 있는데, 프로그램 입장에서는 하나의 명령어를 처리하는 CPU가 4개 있는 것처럼 보인다.(한 개의 하드웨어 스레드가 2개의 스레드를 처리할 수 있기 때문(2 X 2 = 4))
#include<iostream>
using namespace std;
int main()
{
int L, A, B, C, D, tmp1, tmp2;
cin >> L >> A >> B >> C >> D;
if (A % C != 0) tmp1 = (A / C) + 1;
else tmp1 = A / C;
if (B % D != 0) tmp2 = (B / D) + 1;
else tmp2 = B / D;
if (tmp1 > tmp2) cout << L - tmp1;
else cout << L - tmp2;
}
이 글은 혼자 공부하는 컴퓨터 구조 + 운영체제 (저자 : 강민철)의 책과 유튜브 영상을 참고하여 개인적으로 정리하는 글임을 알립니다.
CPU는 명령어를 처리하는 과정에는 정해진 흐름이 있고, CPU는 그 흐름을 반복하여 명령어들을 처리해 나간다.
명령어를 정형화된 흐름으로 처리하는 것을 명령어 사이클이라고 한다.
CPU는 명령어 사이클을 통해 작업을 처리해 나가는데, 이 흐름을 끊어지게 하는 상황이 발생하는데 이것을 인터럽트라고 한다.
명령어 사이클
CPU가 메모리에 저장된 명령어 하나를 실행한다고 하면, 가장 먼저 해야 할 일은 명령어를 CPU로 가져와야 한다.
명령어를 가져왔으면 명령어를 실행해야 한다. 이것을 실행 사이클이라고 한다.
인출 사이클 : 메모리에 있는 명령어를 가져오는 단계
실행 사이클 : CPU로 가져온 명령어를 실행하는 단계
프로그램을 이루는 수많은 명령어는 일반적으로 인출과 실행 사이클을 반복하며 실행된다.
하지만 모든 명령어가 이렇게 간단하게 실행되는 것은 아니다.
CPU가 메모리에서 한 번에 명령어를 가져올 수도 있지만, 간접 주소 지정 방식과 같은 경우로 메모리에 명령어가 저장되어 있다면 한 번 더 메모리 접근을 해야 한다. 이를 간접 사이클이라고 한다.
간접 사이클 : 메모리 접근이 더 필요한 단계
명령어 사이클은 또 하나 고려해야 하는 것이 있다. 그것은 인터럽트 사이클이다.
인터럽트는 말그대로 방해이다. 즉, CPU의 작업을 방해하는 것이다.
인터럽트는 CPU가 꼭 주목해야할 때, CPU가 빨리 처리해야할 다른 작업이 생겼을 때 발생한다.
CPU는 인터럽트를 처리하고 작업을 다시 할지, 인터럽트를 무시하고 작업을 먼저 처리할지 결정하게 된다. 이러한 경우를 인터럽트 사이클이라고 한다.
인터럽트 사이클 : 인터럽트를 처리하는 단계
지금까지의 명령어 사이클을 도식화하면 아래와 같다.
https://velog.io/@mrcocoball
인터럽트
인터럽트는 CPU가 수행중인 작업을 방해하는 신호이다.
인터럽트는 동기 인터럽트와 비동기 인터럽트로 나뉜다.
동기 인터럽트 (예외)
비동기 인터럽트 (하드웨어 인터럽트)
동기 인터럽트
CPU에 의해 발생하는 인터럽트로 CPU가 명령어들을 수행하다가 예상치 못한 상황에 마주쳤을 때 발생하는 인터럽트이다.
프로그래밍상의 오류와 같은 예외적인 상황에 마주쳤을 때 발생하는 인터럽트가 동기인터럽트이다.
이러한 점으로 동기 인터럽트는 예외라고 부른다.
비동기 인터럽트
주로 하드웨어에서 발생하는 인터럽트로 입출력 장치가 CPU가 내린 명령들이 어떻게 처리되었다고 알려주는 신호이다.
예를 들어, CPU가 프린터기에 문서를 출력하라고 명령했다면, 프린터기는 출력을 완료하면 CPU에 비동기 인터럽트를 보낸다.
비동기 인터럽트가 없다면, CPU는 자신이 내린 명령들이 처리가 되었는지 수시로 확인해야 한다. 이러한 수고를 덜어주는 것이 비동기 인터럽트이다.
비동기 인터럽트는 막을 수 있는 인터럽트와 막을 수 없는 인터럽트로 나뉜다.
막을 수 없는 인터럽트 : 반드시 가장 먼저 처리해야하는 인터럽트 (하드웨어 고장, 정전 등)
막을 수 있는 인터럽트 : 나중에 처리해도 되는 인터럽트
인터럽트는 CPU의 흐름을 끊는 것이기 때문에 CPU에게 지금 흐름을 끊어도 되는지 물어보게 된다. 이를 인터럽트 요청신호라고 한다.
CPU가 인터럽트 요청을 수용하기 위해서는 플래그 레지스터의 인터럽트 플래그가 활성화되어 있어야 한다.
인터럽트 플래그가 비활성화되어 있으면 해당 인터럽트 처리는 무시한다.
반대로 인터럽트 플래그가 활성화 되어있으면 인터럽트를 처리하게 된다.
하지만 인터럽트 플래그가 비활성화 되어있더라도 막을 수 없는 인터럽트는 무시할 수 없기 때문에 이를 CPU는 가장 먼저 처리하게 된다.
동기 인터럽트(예외)의 종류 예외가 발생하면 CPU는 하던 일을 중단하고 해당 예외를 처리한다. 예외를 처리하고 나면 다시 원래 하던 작업을 재개한다. 여기서 원래 작업으로 돌아왔을 때, 수행할 명령어의 시점과 위치에 따라 예외의 종류가 달라진다.
폴트(fault) : 예외를 처리한 직후 예외가 발생한 명령어부터 실행을 재개 트랩(trap) : 예외 처리 직후 예외가 발생한 명령어의 다음 명령어부터 실행을 재개 (디버깅 시 사용) 중단(abort) : CPU가 실행 중인 프로그램을 강제로 중단시킬 수 밖에 없는 심각한 오류를 발견했을 때 발생하는 예외 소프트웨어 인터럽트(software interrupt) : 시스템 호출이 발생했을 때 나타나는 예외
비동기 인터럽트 처리 과정
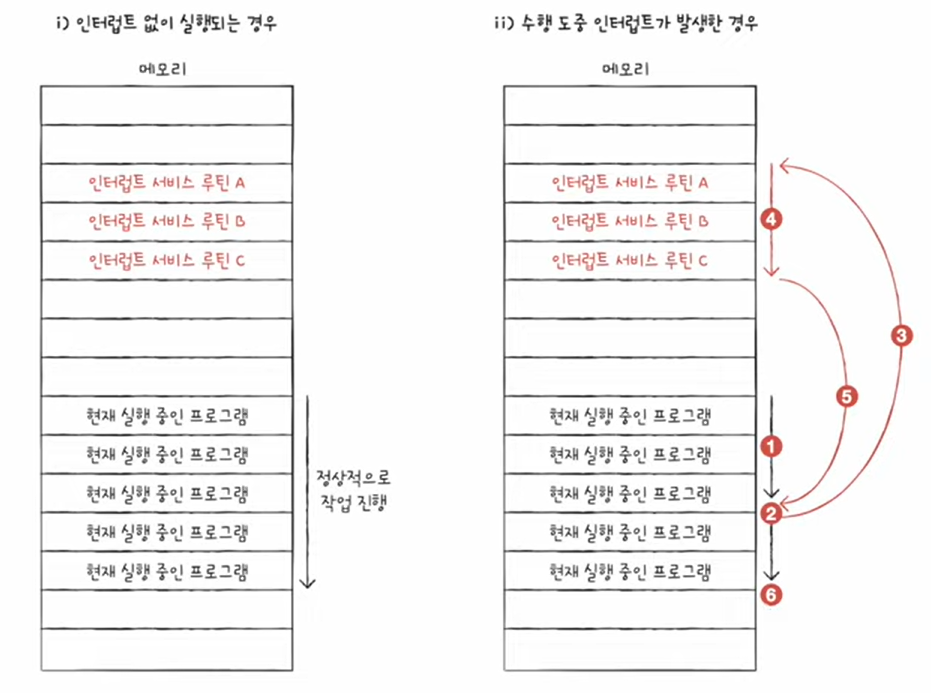
CPU가 인터럽트 요청을 받아들이기로 했다면 CPU는 인터럽트 서비스 루틴(인터럽트 핸들러)이라는 프로그램을 실행한다.
인터럽트 서비스 루틴 : 어떤 장치가 어떤 인터럽트를 보냈을 때 행동 방침
CPU가 인터럽트를 처리한다는 말은 인터럽트 서비스 루틴을 실행하고, 원래 수행하던 작업으로 돌아온다는 뜻이다.
CPU는 각기 다른 인터럽트 서비스 루틴을 구분할 수 있어야 한다. 이를 위해 CPU는 인터럽트 벡터를 사용한다.
인터럽트 벡터 : CPU가 인터럽트 서비스 루틴을 식별하기 위한 정보(인터럽트 서비스 루틴의 메모리 시작 주소)
CPU는 하드웨어 인터럽트 요청을 보낸 대상으로부터 데이터 버스를 통해 인터럽트 벡터를 전달받는다.
인터럽트 서비스 루틴도 다른 프로그램과 마찬가지로 명령어와 데이터로 이루어져 있다. 그렇기에 인터럽트 서비스 루틴도 프로그램 카운터를 비롯한 레지스터들을 사용하며 실행된다.