#include <iostream>
using namespace std;
int main() {
int sum = 0;
for (int i = 0; i < 5; i++) {
int n = 0;
cin >> n;
if (n <= 40) n = 40;
sum += n;
}
cout << sum / 5;
}
#include<iostream>
using namespace std;
int main()
{
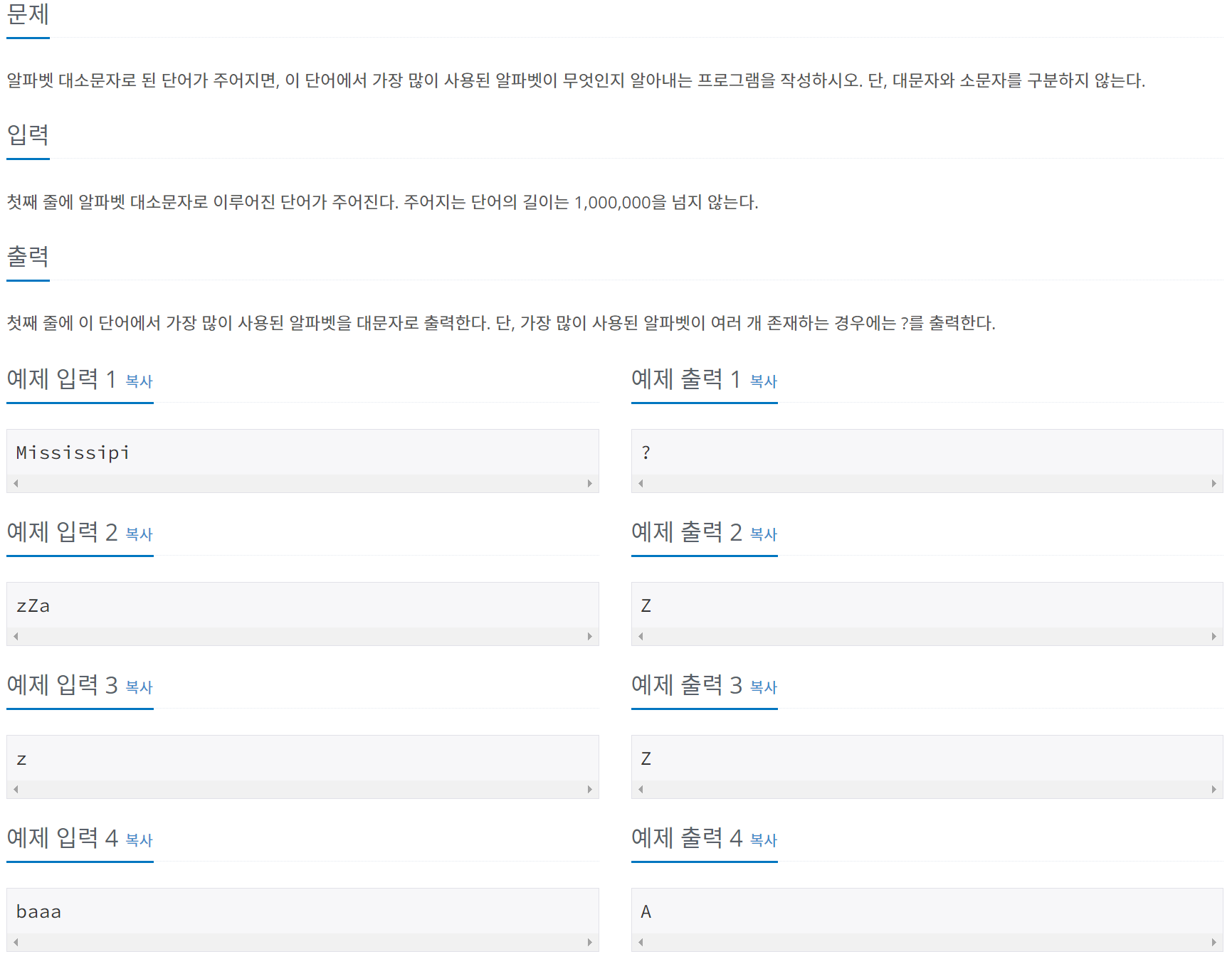
int arr[26] = { 0 }; int max = 0; int count = 0; int idx = 0;
string input;
cin >> input;
for (int i = 0; i < input.length(); ++i)
{
input[i] = toupper(input[i]); //모두 대문자로 변환
++arr[input[i] - 65]; //A-65는 0이고, Z-65는 25다
}
for (int i = 0; i < 26; ++i) if (arr[i] > max){ max = arr[i]; idx = i; } //가장 많이 사용된 알파벳 검사
for (int i = 0; i < 26; ++i) if (max == arr[i]) ++count; //가장 많이 사용된 알파벳이 몇개인지 검사
idx += 65; //idx + 65는 가장 많이 사용한 문자이다.
if (count > 1) //가장 많이 사용된 알파벳이 2개 이상이면 ? 출력
{
cout << "?";
return 0;
}
else cout << (char)idx;
}
이 글은 혼자 공부하는 컴퓨터 구조 + 운영체제 (저자 : 강민철)의 책과 유튜브 영상을 참고하여 개인적으로 정리하는 글임을 알립니다.
세상에는 수많은 CPU 제조사들이 있고, CPU마다 규격과 기능들이 모두 달라서 CPU가 이해하고 실행하는 명령어들은 모두 같지가 않다.
기본적인 명령어의 구조와 작동원리는 비슷하지만 명령어의 세세한 생김새, 주소 지정 방식등은 CPU마다 차이가 있다.
CPU가 이해할 수 있는 명령어들의 모음을 명령어 집합(Instruction Set) 또는 명령어 집합 구조(ISA : Instruction Set Architecture)라고 한다.
즉, CPU마다 ISA가 다르다는 것이다.
인텔의 노트북 CPU는 x86 또는 x86-64 ISA를 이해하고, 애플의 아이폰 CPU는 ARM ISA를 이해한다. 같은 소스코드로 만들어진 같은 프로그램이라 할지라도 ISA가 다르면 CPU가 이해할 수 있는 명령어도 어셈블리어도 달라진다. 따라서 같은 명령어라도 한쪽에선 정상작동하지만 다른 한쪽에선 정상작동이 안될 수 있다는 것이다.
여러 ISA중에서도 CPU의 성능을 향상시킬 수 있는 방법인 명령어 병렬 처리기법(명령어 파이프라인, 슈퍼스칼라, 비순차적 명령어)을 적용하기 유리한 ISA는 현대 ISA의 양대 산맥인 CISC와 RISC가 있다.
CISC(Complex Instruction Set Computer)
CISC는 다양하고 강력한 기능의 명령어 집합을 활용하기 때문에 명령어의 형태와 크기가 다양한 가변 길이 명령어를 사용한다.
이는 상대적으로 적은 수의 명령어로도 프로그램을 실행할 수 있다는 것이다.
이런 장점 때문에 메모리를 최대한 아끼며 개발해야했던 시절에는 인기가 많았지만, 활용하는 명령어가 복잡하고 다양한 기능을 제공하기 때문에 명령어의 크기와 실행되기까지의 시간이 일정하지 않다.
또한 복잡한 명령어 때문에 명령어 하나를 실행하는 데에 여러 클럭주기를 필요로 한다.
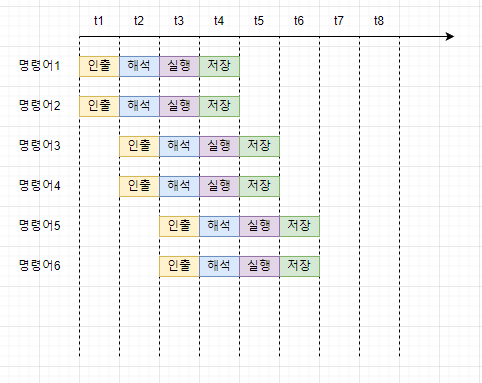
이는 명령어 파이프라이닝에 큰 어려움을 가져다 준다.
명령어 파이프라이닝이 비교적 힘들다는 것이 CISC의 가장 큰 약점이다.
추가적으로 CISC가 복잡하고 다양한 명령어를 사용할 수 있지만, 대다수의 복잡한 명령어는 사용 빈도가 낮기 때문에 CISC의 전체 명령어중 20%가 사용된 전체 명령어의 80%정도를 차지한다는 연구결과도 있다.
현대의 CISC 명령어 파이프라이닝은 현대 CPU에서는 놓쳐서는 안될 중요한 기술이기 때문에 CPU 내부에서 CISC의 명령어를 쪼개서 파이프라이닝을 가능하게 한다.
RISC(Reduced Instruction Set Computer)
CISC가 준 교훈은 아래와 같다.
원활한 파이프라이닝을 위해 명령어의 길이와 수행 시간이 짧고 규격화 되어 있어야 한다.
자주 쓰이는 명령어만 줄 곧 사용된다. 복잡한 기능을 지원하는 명령어 보다는 자주 쓰이고 기본적인 명령어를 작고 빠르게 만다는 것이 중요하다.
이런 원칙 하에 등장한 것이 RISC이다.
RISC는 CISC보다 명령어의 종류가 적고, 규격화된 명령어, 되도록 1클럭 내외로 실행되는 명령어를 지향한다.
즉, 짧고 규격화된 고정 길이 명령어를 사용한다.
이러한 점으로 인해 명령어 파이프라이닝에 최적화 되어있다.
추가적으로 메모리에 직접 접근하는 명령어를 load, store 두 개로 제한할 만큼 메모리 접근을 최소화하고 CISC보다 주소 지정 방식의 종류가 적다. 메모리 접근을 최소화 한 만큼 레지스터를 적극적으로 사용한다.
레지스터를 이용하는 연산이 비교적 많고, 범용 레지스터의 개수 또한 더 많다.
사용 가능한 명령어의 개수가 CISC보다 적기 때문에 더 많은 명령어로 프로그램을 작동시킨다.