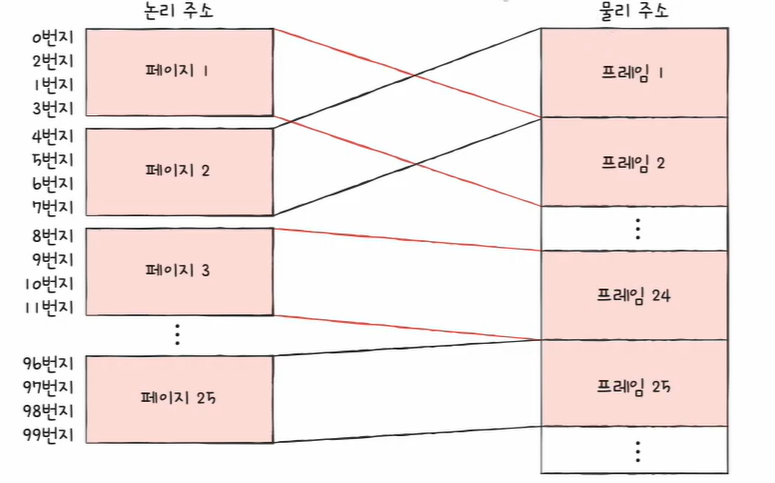
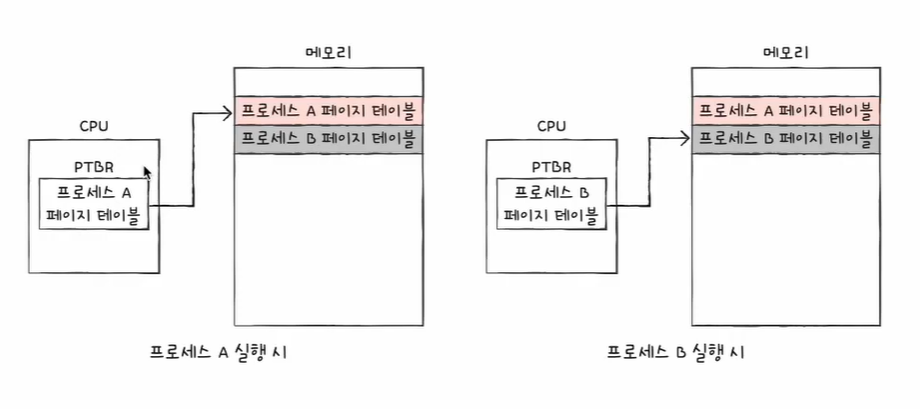
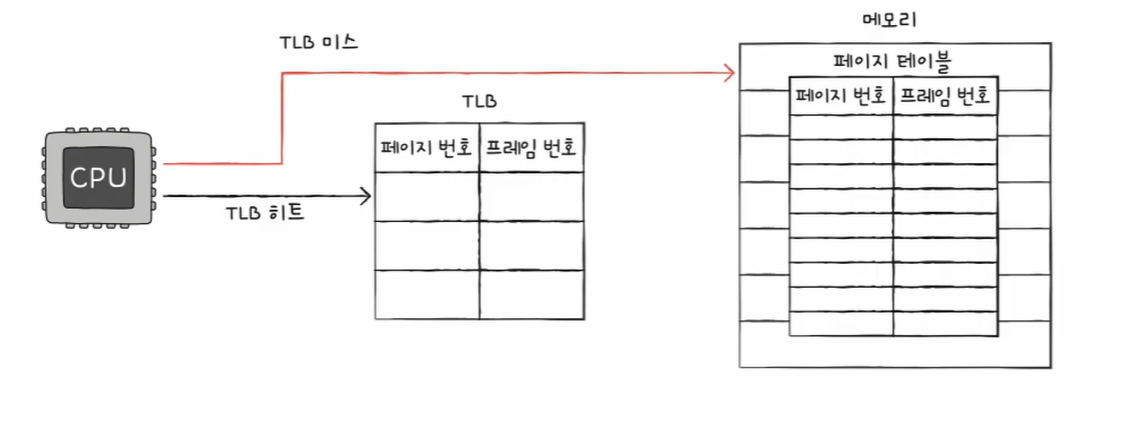
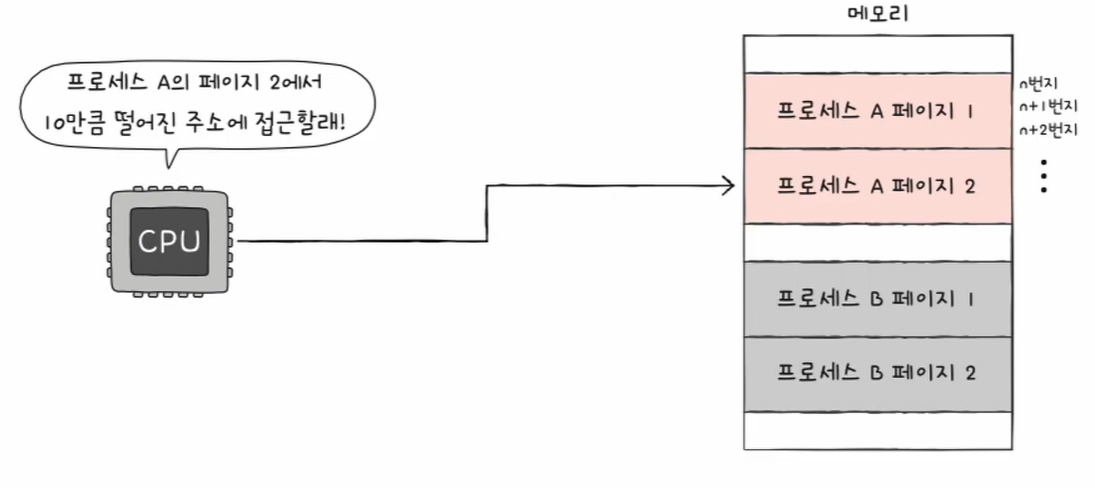
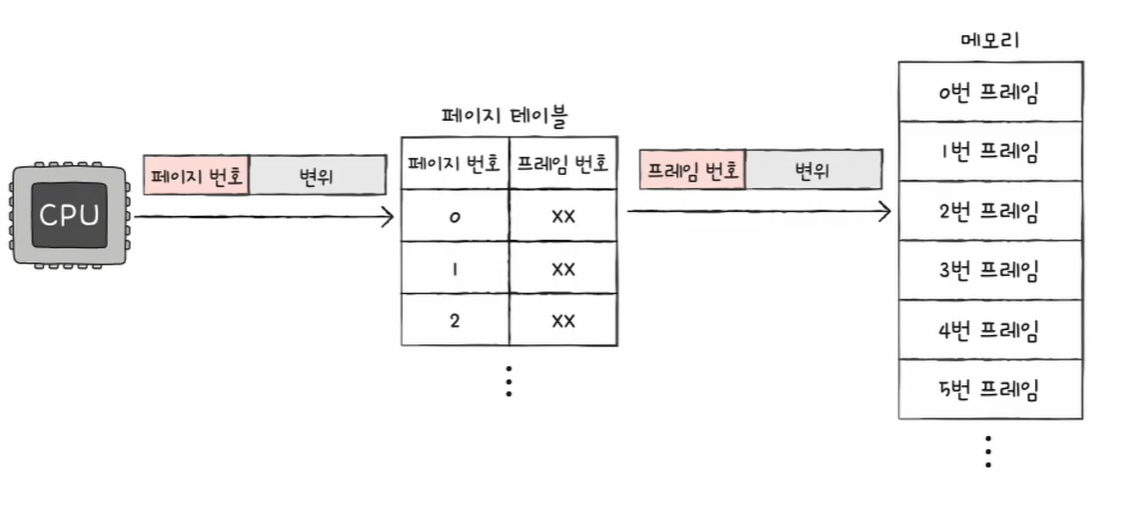
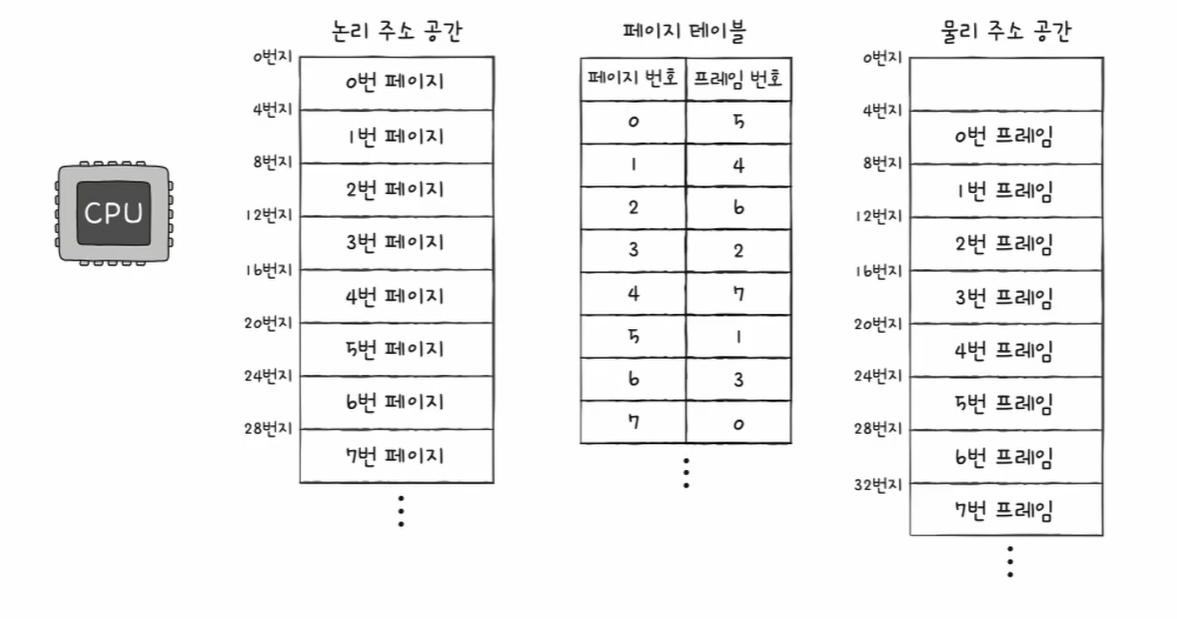
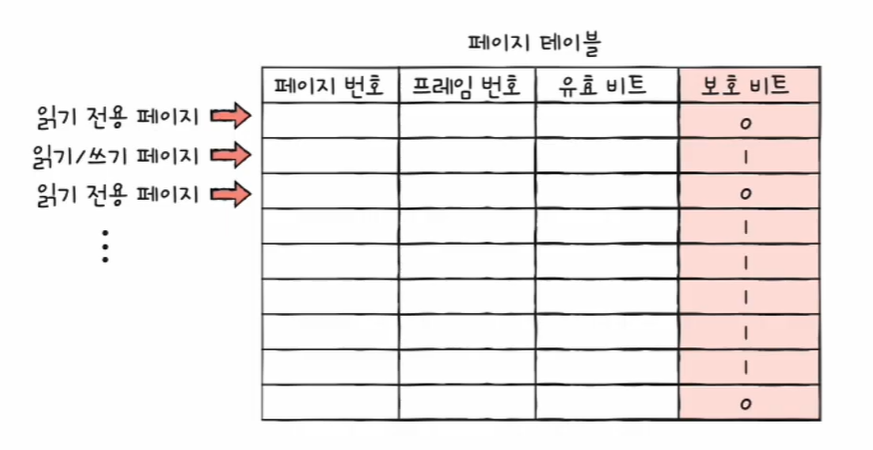
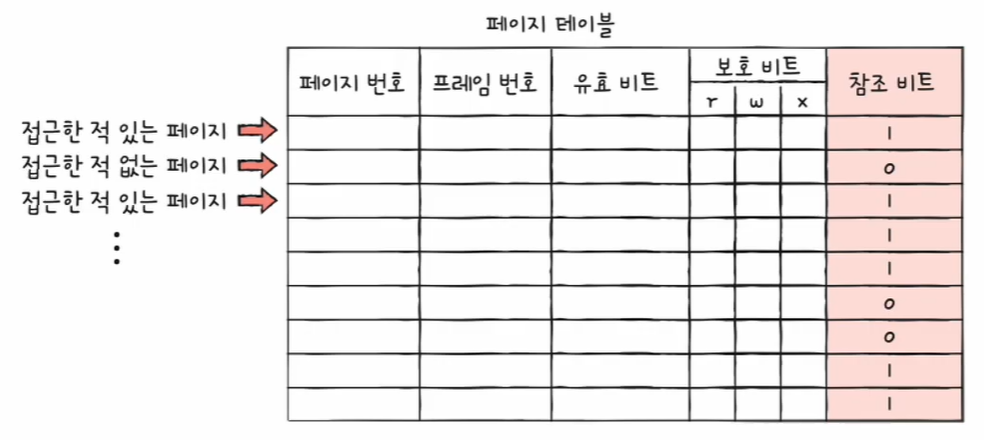
이 글은 혼자 공부하는 컴퓨터 구조 + 운영체제 (저자 : 강민철)의 책과 유튜브 영상을 참고하여 개인적으로 정리하는 글임을 알립니다.
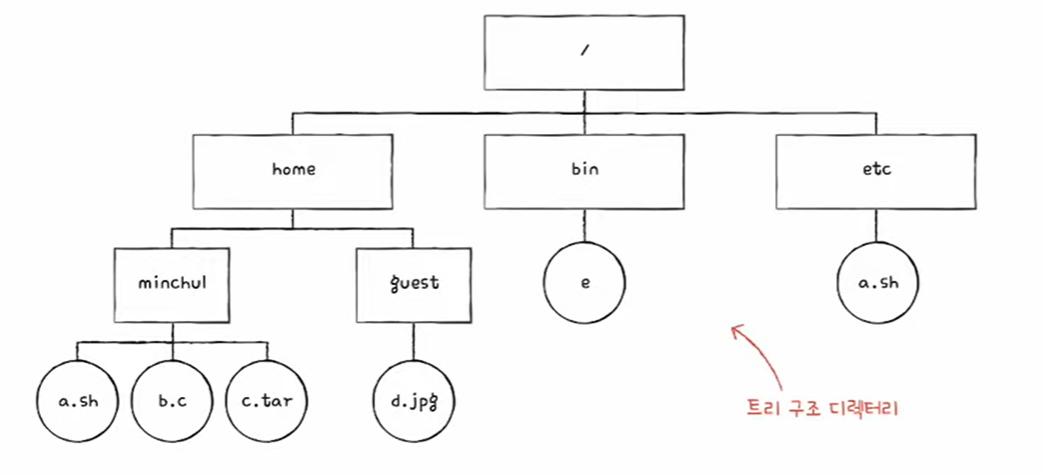
파티셔닝(partitioning)과 포매팅(formatting)
- 파티셔닝(파티션을 나누는 작업) : 저장 장치의 논리적인 영역을 구획하는 작업
- 파티션 : 파티셔닝 작업을 통해 나누어진 하나의 영역
- 포매팅 : 포맷을 하는 작업, 어떤 종류의 파일 시스템을 사용할지 결정하고 새로운 데이터를 쓸 준비를 하는 작업
포맷(포매팅)의 종류
저수준 포매팅 : 저장 장치를 생성할 당시 공장에서 수행되는 물리적인 포매팅
논리적 포매팅 : 파일 시스템을 생성하는 포매팅
이 글에서 포매팅은 논리적 포매팅을 뜻한다.
파일 할당 방법
- 포매팅까지 끝난 하드 디스크에 파일을 저장하기
- 운영체제는 파일/디렉터리를 블록 단위로 읽고 쓴다.(즉, 하나의 파일이 보조기억장치에 저장될 때에는 여러 블록에 걸쳐 저장된다.)

파일을 보조기억장치에 할당하는 방법에는 크게 연속 할당과 불연속 할당이 있고, 불연속 할당에는 크게 연결 할당과 색인 할당이 있다.
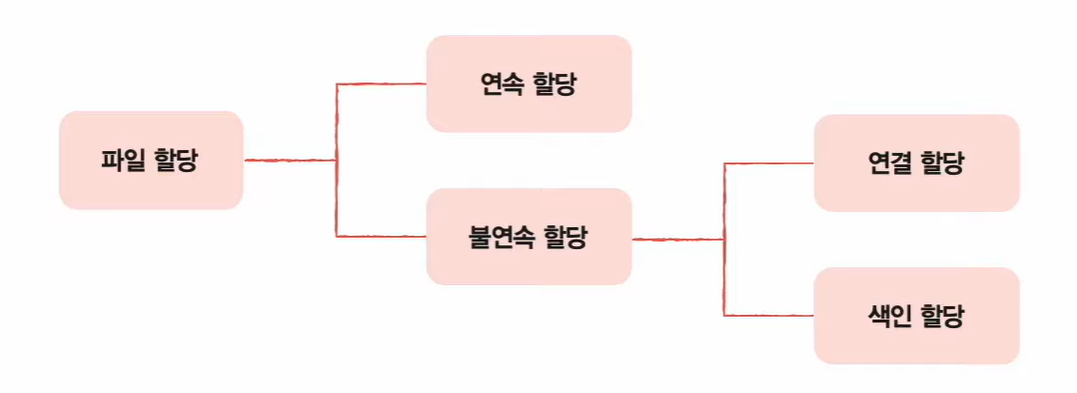
연속 할당과 불연속 할당
연속 할당보다는 불연속 할당을 많이 사용한다.
연속 할당(contiguous allocation)
- 이름 그대로 보조기억장치 내 연속적인 블록에 파일 할당
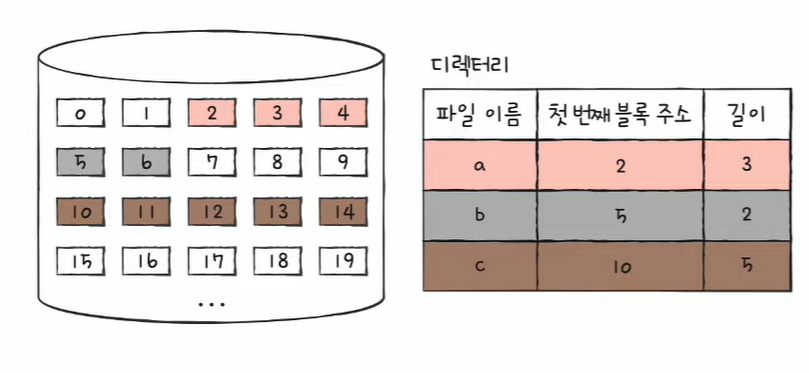
- 연속된 파일에 접근하기 위해 파일의 첫 번째 블록 주소와 블록 단위의 길이만 알면 된다.
- 디렉터리 엔트리 : 파일 이름 & 첫 번째 블록 주소 & 블록 단위 길이 명시
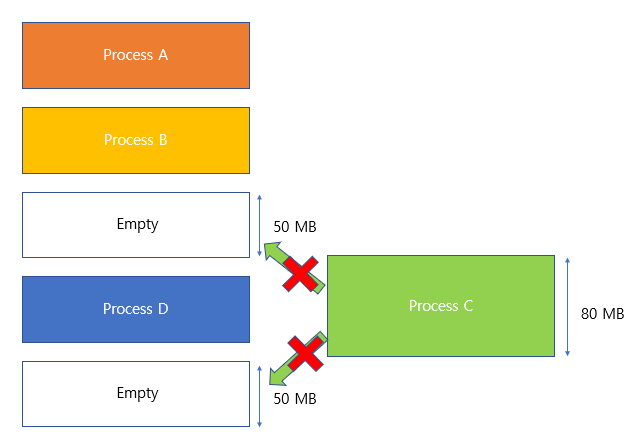
- 구현이 단순하지만 외부 단편화를 야기할 수 있다.
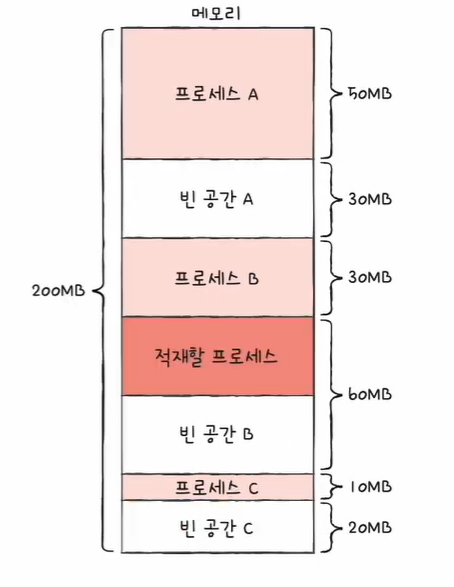
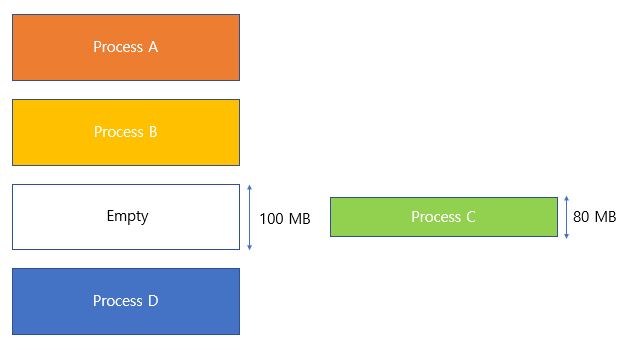
연속 할당 외부 단편화 예시

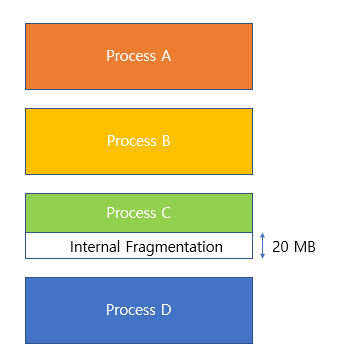
이 상황에서 파일 D와 F가 삭제되었다면,

잔여블록은 11개이지만, 가장 큰 빈 블록이 6개이므로 블록 7개 이상 사용하는 파일을 할당할 수 없다.
불연속 할당
연결 할당(linked allocation)
- 각 블록의 일부에 다음 블록의 주소를 저장하여 각 블록이 다음 블록을 가리키는 형태로 할당
- 파일을 이루는 데이터 블록을 연결 리스트로 관리
- 불연속 할당의 일종이기 때문에, 파일이 여러 블록에 흩어져 저장되어도 무방하다
- 디렉터리 엔트리 : 파일이름 & 첫 번째 블록 주소 & 블록 단위의 길이
- 단점 : 반드시 첫 번째 블록부터 하나씩 읽어 들여야 함, 오류 발생 시 오류가 발생한 블록 이후 블록은 접근이 어렵다.

디렉터리 엔트리에 첫 번째 블록 주소와 마지막 블록 주소를 기록할 수도 있다.
색인 할당(indexed allocation)
- 파일의 모든 블록 주소를 색인 블록이라는 하나의 블록(색인 블록)에 모아 관리하는 방식
- 파일 내 임의의 위치에 접근하기 용이
- 디렉터리 엔트리 : 파일 이름 & 색인 블록 주소

FAT과 유닉스 파일 시스템
FAT 파일 시스템
- 연결 할당 기반 파일 시스템
- 연결 할당의 단점을 보안
- 각 블록에 포함된 다음 블록 주소를 한 곳에 모아 테이블(FAT:File Allocation Table)로 관리

위 그림에서 블록의 주소는 4 -> 8 -> 3 -> 5로 연결되어 있음을 알 수 있다.
FAT 파일 시스템
-USB 메모리, SD 카드와 같은 저용량 저장 장치용 파일 시스템으로 많이 사용
-FAT12 ,FAT16, FAT32가 있으며 FAT 뒤에 오는 숫자는 블록을 표현하는 비트 수를 의미
-윈도우에서 블록이라는 용어 대신 클러스터라는 용어를 사용한다.
- FAT 영역에 FAT가 먼저 저장됨
- 뒤이어 루트 디렉터리 영역
- 다음에 서브 디렉터리와 파일들을 위한 영역

FAT가 메모리에 캐시
FAT는 파티션의 시작 부분에 있지만, 실행하는 도중 FAT가 메모리에 캐시 될 수 있다.
FAT가 메모리에 적재된 채 실행되면 기존 연결 할당보다 다음 블록을 찾는 속도가 매우 빨라지고, 결과적으로 연결 할당 방식보다 임의 접근에도 유리해진다.
FAT 파일 시스템의 디렉터리 엔트리

속성 항목은 해당 파일이 읽기 전용 파일인지, 숨김 파일인지, 시스템 파일인지, 일반 파일인지, 디렉터리인지 등을 식별하기 위한 항목
FAT 파일 시스템에서 파일을 읽는 과정
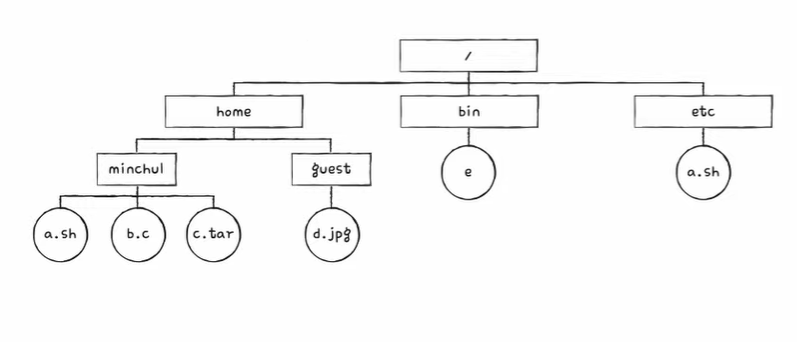

\home\minchul\a.sh에 접근하는 과정
- home 디렉터리는 3번 블록에 있다.
- minchul 디렉터리는 15번 블록에 있다.
- a.sh 파일의 첫 번째 블록 주소가 9번 블록이라는 것을 알 수 있다.
- a.sh 파일은 9->8->11->13번 블록 순서로 저장되어 있다.
유닉스 파일 시스템
- 색인 할당 기반 파일 시스템
- 유닉스에서 색인 블록을 i-node(index-node)라고 부른다.
- i-node에는 파일 속성 정보와 열다섯 개의 블록 주소가 저장될 수 있다.
- 디렉터리 엔트리는 i-node와 파일 이름으로 구성된다.
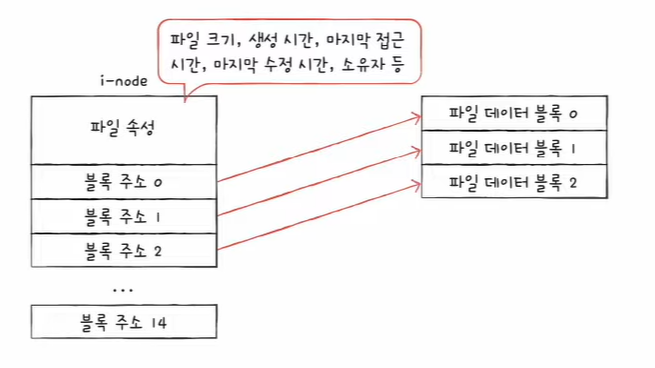
블록 주소 중 12개에는 직접 블록 주소 저장
- 직접 블록 : 파일 데이터가 저장된 블록
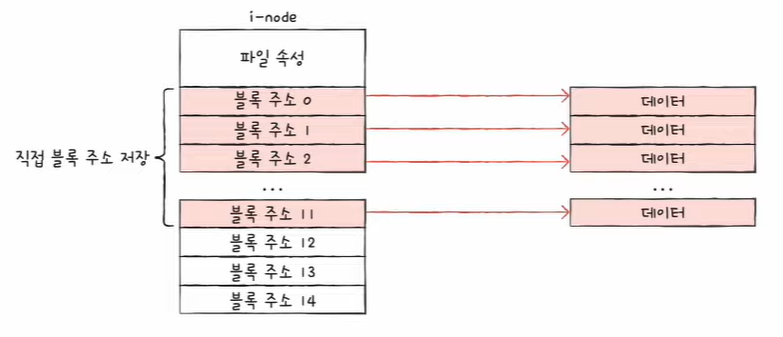
파일 크기가 크다면 13번째 주소에 단일 간접 블록 주소 저장
- 단일 간접 블록 : 파일 데이터를 저장한 블록 주소가 저장된 블록

충분하지 않다면 14번째 주소에 이중 간접 블록 주소 저장
- 이중 간접 블록 : 단일 간접 블록들의 주소를 저장하는 블록
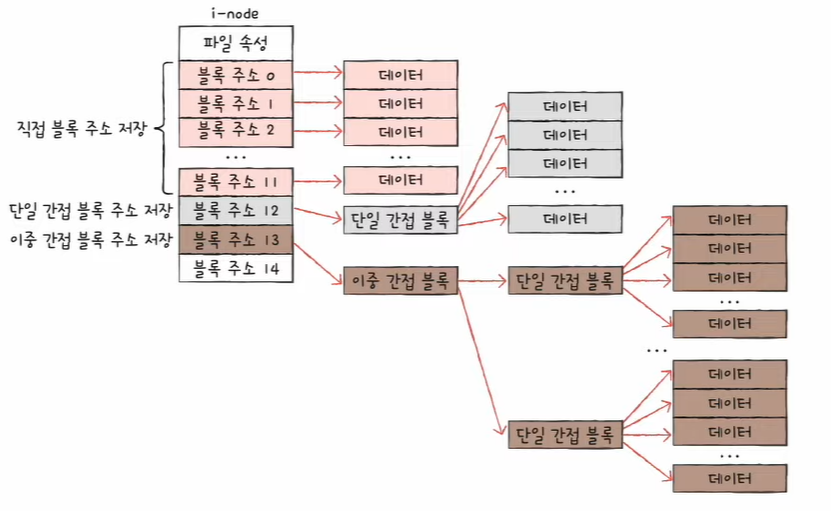
아직도 충분하지 않다면 15번째 주소에 삼중 간접 블록 주소 저장
- 삼중 간접 블록 주소 : 이중 간접 블록들의 주소를 저장하는 블록

유닉스 파일 시스템의 디렉터리 엔트리
- 디렉터리 엔트리는 i-node가 파일 시스템의 핵심이다.

유닉스 파일 시스템에서 파일을 읽는 과정
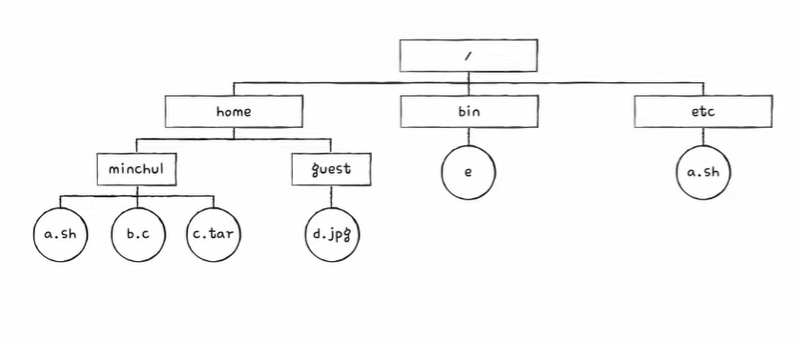
\home\minchul\a.sh에 접근하는 과정
- 파일에 접근하기 위해 파일 시스템은 우선 루트 디렉터리 위치부터 찾는다
- 루트 디렉터리 위치는 루트 디렉터리의 i-node를 보면 알 수 있다.
- 유닉스 파일 시스템은 루트 디렉터리의 i-node를 항상 기억하고 있다.
- 아래의 그림은 2번 i-node가 루트 디렉터리의 i-node라고 가정
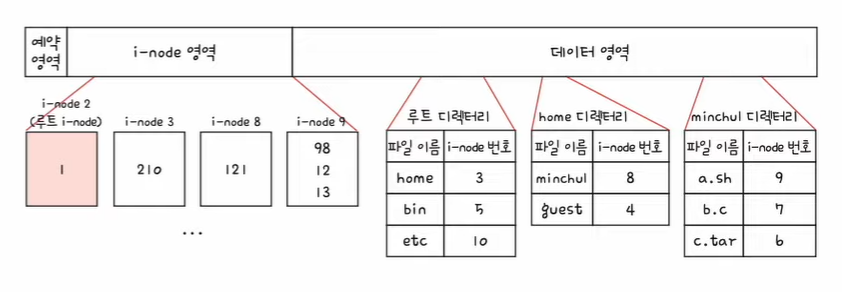
1. 2번 i-node에 접근하여 루트 디렉터리의 위치를 파악, 루트 디렉터리는 1번 블록에 있다.
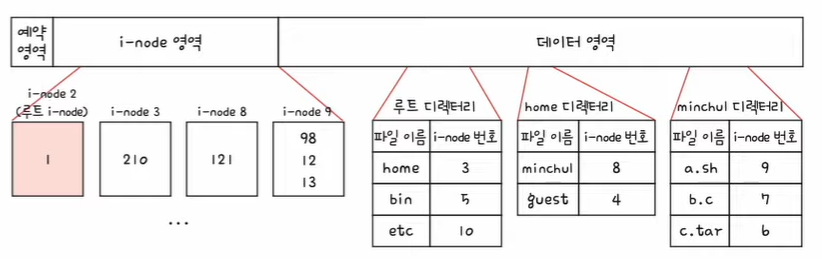
2. 루트 디렉터리 안에 home 디렉터리의 i-node는 3번 i-node이다.
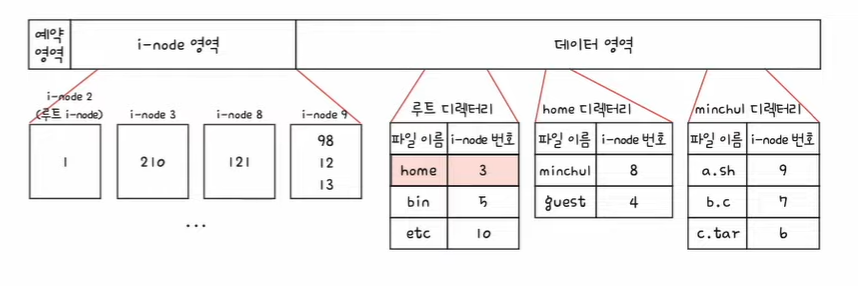
3. 3번 i-node에 접근하여 home 디렉터리 위치를 파악한다. home 디렉터리는 210번 블록에 있다.
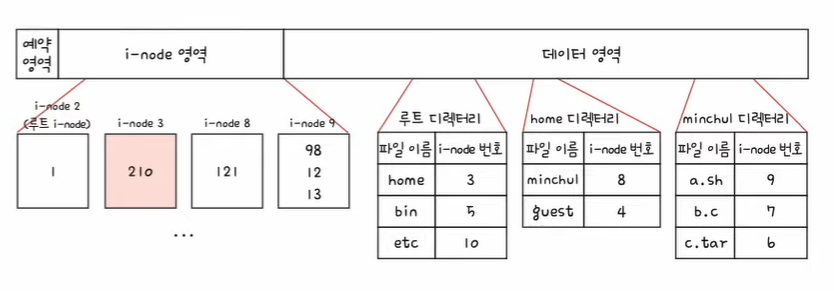
4. 210번 블록을 읽으면 home 디렉터리 내용을 알 수 있다. minchul 디렉터리의 i-node는 8번이다.
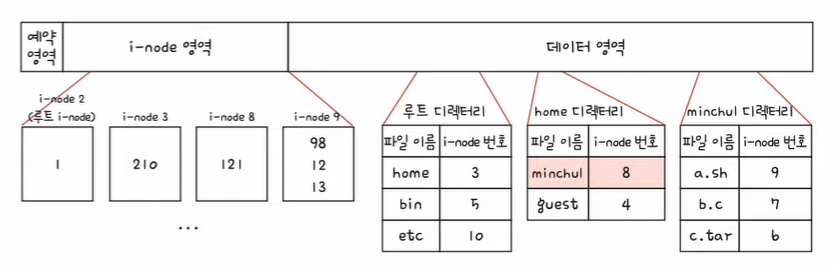
5. 8번 i-node에 접근하여 minchul 디렉터리의 위치를 파악한다. minchul 디렉터리는 121번 블록에 있다.
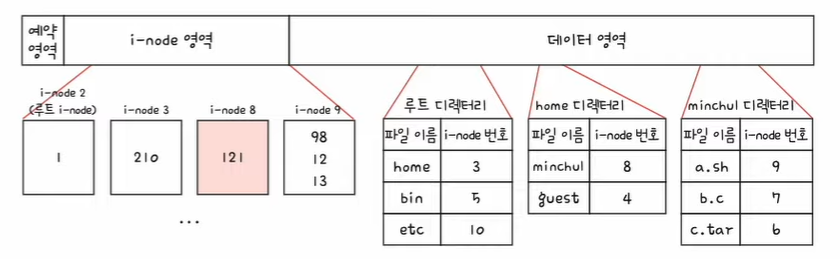
6. 121번 블록을 읽으면 minchul 디렉터리의 내용을 알 수 있다. 파일 a.sh의 i-node 번은 9번이다.
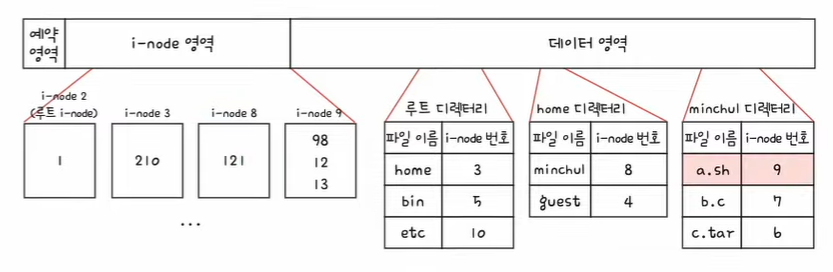
7. 9번 i-node에 접근하여 파일 a.sh의 위치를 파악한다. a.sh 파일은 98, 12, 13번 블록에 있다.
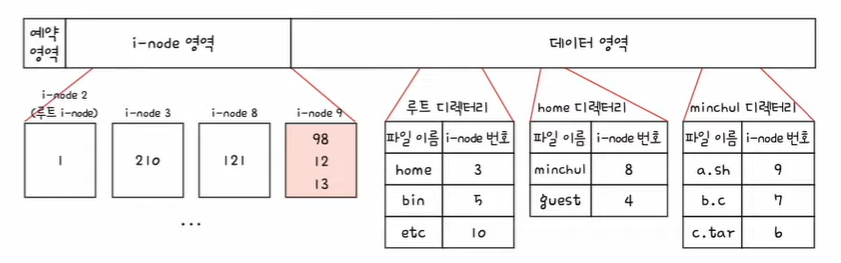
8. \home\minchul\a.sh를 읽기 위해 98->12->13번 블록에 접근하면 된다.
'컴퓨터 구조 & 운영체제 > 운영체제' 카테고리의 다른 글
| [운영체제] 파일과 디렉터리 (0) | 2023.07.10 |
|---|---|
| [운영체제] 페이징의 쓰기 시 복사와 계층적 페이징 (0) | 2023.07.09 |
| [운영체제] 페이지 교체와 프레임 할당 (0) | 2023.07.08 |
| [운영체제] 페이징을 통한 가상 메모리 관리 (0) | 2023.07.07 |
| [운영체제] 연속 메모리 할당 (0) | 2023.07.06 |