@Component
클래스를 스프링 빈으로 등록하기 위한 일반적인 스테레오타입 어노테이션. 스프링이 관리하는 컴포넌트임을 나타낸다.
@Component 어노테이션은 @Repository, @Service, @Controller와 같은 더 구체적인 스테레오타입 어노테이션의 기반으로 작용한다.
이들은 각각 데이터 접근 계층, 비즈니스 로직 계층, 프레젠테이션 계층의 클래스를 나타내는 데 사용되며, @Component의 특수한 형태로 볼 수 있다.
이 구체적인 어노테이션들을 사용함으로써, 개발자는 애플리케이션의 다양한 부분을 더 명확하게 구분할 수 있고, 스프링은 특정 역할을 가진 컴포넌트를 적절히 처리할 수 있다.
@ComponentScan
스프링이 @Component 어노테이션이 붙은 클래스를 찾아 빈으로 등록할 때 검색할 패키지 범위를 지정한다.
이 어노테이션은 @Component 뿐만 아니라, @Repository, @Service, @Controller와 같은 어노테이션이 붙은 클래스를 대상으로 한다.
@ComponentScan은 보통 스프링의 설정 정보를 담고 있는 클래스에 선언된다. 이 어노테이션은 basePackages 속성을 통해 스캔할 패키지의 범위를 지정할 수 있다. 지정하지 않을 경우, @ComponentScan이 선언된 클래스의 패키지가 기본 스캔 위치가 된다.
@Configuration
@ComponentScan(basePackages = "com.example.project")
public class AppConfig {
// 추가적인 빈 설정이나 구성 정보...
}
@Bean
개발자가 직접 제어할 수 없는 외부 라이브러리들을 포함하여, 개발자가 직접 생성과 구성을 관리하고 싶은 객체를 스프링의 의존성 주입 컨테이너에 빈(bean)으로 등록하고자 할 때 사용된다.
이 어노테이션은 메소드 레벨에서 사용되며, 해당 메소드가 반환하는 객체를 스프링 애플리케이션 컨텍스트의 관리 대상인 빈으로 등록한다.
@Bean 어노테이션이 붙은 메소드는 보통 @Configuration 어노테이션이 선언된 클래스 내에 위치한다.
이 메소드는 스프링 컨테이너가 관리할 객체의 인스턴스를 생성하고 초기화하는 로직을 담는다.
스프링은 이 메소드를 호출하고, 반환된 객체를 애플리케이션 컨텍스트에 빈으로 등록한다.
@Qualifier
자동 의존성 주입(Autowired) 과정 중에, 동일한 타입의 빈이 여러 개 있을 때, 주입할 빈을 구체적으로 지정하는 데 사용된다.
즉, @Autowired와 함께 사용되어, 스프링이 자동으로 의존성을 주입할 때 어떤 빈을 선택해야 하는지를 명확하게 해준다.
스프링에서 동일한 인터페이스를 구현한 여러 빈이 있고, 특정 빈을 주입받고 싶은 경우, @Qualifier 어노테이션을 사용하여 빈의 이름을 지정할 수 있다.
@Component
public class MyService {
private final MyRepository myRepository;
@Autowired
public MyService(@Qualifier("specificRepository") MyRepository myRepository) {
this.myRepository = myRepository;
}
}
위 예시에서, MyRepository 인터페이스를 구현한 여러 빈 중에서 specificRepository라는 이름의 빈을 MyService에 주입하고자 할 때, @Qualifier("specificRepository")를 사용한다.
주요 기능
- 의존성 주입의 명확성: @Autowired만 사용할 때보다 더 명확하게 특정 빈을 지정할 수 있게 해줌으로써, 의도치 않은 빈의 주입을 방지한다.
- 유연한 구성: 애플리케이션의 구성을 더 유연하게 만들어, 같은 타입의 빈이 여러 개 있어도 각 상황에 맞게 적절한 빈을 선택하여 사용할 수 있다.
주의사항
- 빈 이름의 일치: @Qualifier 어노테이션에 지정된 이름은 스프링 컨테이너에서 관리되는 빈의 이름과 정확히 일치해야 한다.
- 문서화와 유지보수: @Qualifier를 사용할 때는 왜 특정 빈을 선택했는지, 그리고 해당 빈이 어떤 역할을 하는지에 대한 문서화가 중요하다. 이는 코드의 가독성을 높이고, 유지보수를 용이하게 한다.
@Primary
@Primary 어노테이션은 스프링 프레임워크에서 자동 의존성 주입 과정 중 동일한 타입의 빈이 여러 개 있을 때, 기본으로 사용될 빈을 지정하는 데 사용된다.
이 어노테이션은 특정 상황이나 조건 없이 일반적으로 우선적으로 사용되어야 하는 빈을 스프링 컨테이너에 알린다.
@Primary는 @Autowired와 같은 자동 주입 설정과 함께 사용될 때 특히 유용하다.
@Component
public class PrimaryRepository implements MyRepository {
// 구현체
}
@Component
@Primary
public class SecondaryRepository implements MyRepository {
// 구현체
}
위 예시에서 MyRepository 인터페이스를 구현하는 두 개의 구현체가 있고, SecondaryRepository에 @Primary 어노테이션을 붙여 이를 기본 구현체로 지정했다.
이제 MyRepository 타입의 빈을 주입받아야 하는 경우, 스프링은 @Primary가 붙은 SecondaryRepository를 우선적으로 사용한다.
주요 기능
- 기본 빈 지정: 동일 타입의 여러 빈 중에서 기본으로 사용될 빈을 명시적으로 지정한다.
- 자동 주입 간소화: @Autowired 사용 시 @Qualifier 없이도 명확하게 주입할 빈을 결정할 수 있게 해, 의존성 주입 과정을 간소화한다.
- 설정의 유연성 증가: 애플리케이션의 다양한 구성 요소 간의 결합도를 낮추고, 설정의 유연성을 증가시킨다.
주의사항
- 명확한 사용 목적: @Primary 어노테이션은 여러 빈 중에서 기본 빈을 선택할 명확한 이유가 있을 때 사용해야 한다. 무분별한 사용은 의존성 주입 과정의 명확성을 해칠 수 있다.
- @Qualifier와의 관계: @Primary로 지정된 빈이 있어도, @Qualifier 어노테이션을 사용하여 특정 빈을 명시적으로 지정할 수 있다. @Qualifier가 있을 경우, @Primary보다 우선시된다.
@PostConstruct
@PostConstruct 어노테이션은 스프링 프레임워크에서 빈의 초기화 작업을 수행하기 위해 사용된다.
이 어노테이션이 붙은 메서드는 빈의 생성자 호출 이후, 의존성 주입이 완료되고 나서 바로 실행된다.
@PostConstruct를 사용하면 개발자는 빈이 완전히 생성되었을 때 필요한 초기화 작업을 안전하게 수행할 수 있으며, 이는 리소스 생성, 데이터 사전 로딩, 설정 검증 등 다양한 목적으로 활용될 수 있다.
@Component
public class MyBean {
@PostConstruct
public void init() {
// 초기화 로직 수행
}
}
위 예시에서 MyBean 클래스는 스프링 관리 빈으로 선언되어 있고, init 메서드에는 @PostConstruct 어노테이션이 붙어 있다. 스프링 컨테이너는 MyBean 인스턴스를 생성하고 의존성 주입을 완료한 후 init 메서드를 자동으로 호출하여 초기화 작업을 수행한다.
주요 기능
- 안전한 초기화: 의존성 주입이 완료된 후 초기화 로직을 실행함으로써, 모든 의존성이 제대로 설정된 상태에서 안전하게 리소스를 할당하거나 초기화 로직을 수행할 수 있다.
- 코드 정리: 초기화 로직을 생성자나 설정 메서드에 분산하지 않고, @PostConstruct 어노테이션이 붙은 메서드에 집중함으로써 코드를 더 깔끔하고 관리하기 쉽게 만든다.
- 자동 호출 보장: 스프링 컨테이너는 @PostConstruct 어노테이션이 붙은 메서드를 빈의 생명주기에 맞춰 자동으로 호출하므로, 개발자는 명시적으로 초기화 메서드를 호출할 필요가 없다.
주의사항
- 실행 시점: @PostConstruct 어노테이션이 붙은 메서드는 빈이 생성되고 의존성 주입이 완료된 직후 단 한 번만 호출된다. 따라서 메서드 내에서는 빈의 상태를 변경하는 등의 초기화 작업만 수행해야 한다.
- 메서드 제한: @PostConstruct 어노테이션은 하나의 클래스에 하나의 메서드에만 적용할 수 있다. 또한, 이 메서드는 파라미터를 가질 수 없으며, void를 반환 타입으로 가져야 한다.
- 자바 표준: @PostConstruct 어노테이션은 자바 EE에서 정의된 표준이며, 스프링뿐만 아니라 다른 자바 EE 호환 컨테이너에서도 사용될 수 있다.
@PreDestroy
@PreDestroy 어노테이션은 스프링 프레임워크에서 빈의 생명주기가 끝나기 직전, 즉 빈이 소멸되기 전에 실행되어야 하는 메소드에 사용된다.
이 어노테이션을 사용함으로써, 개발자는 빈이 제거되기 전에 필요한 정리 작업을 안전하게 수행할 수 있으며, 이는 리소스 해제, 연결 닫기, 임시 파일 삭제 등 다양한 목적으로 활용될 수 있다.
@Component
public class MyBean {
@PreDestroy
public void destroy() {
// 정리 로직 수행
}
}
위 예시에서 MyBean 클래스는 스프링 관리 빈으로 선언되어 있고, destroy 메서드에는 @PreDestroy 어노테이션이 붙어 있다. 스프링 컨테이너는 MyBean 인스턴스를 소멸하기 직전에 destroy 메서드를 자동으로 호출하여 정리 작업을 수행한다.
주요 기능
- 안전한 자원 해제: 빈이 소멸되기 전에 필요한 자원 해제 및 정리 작업을 수행할 수 있어, 메모리 누수나 리소스 낭비를 방지한다.
- 코드 정리: 정리 작업을 생성자나 다른 메서드에 분산하지 않고, @PreDestroy 어노테이션이 붙은 메서드에 집중함으로써 코드를 더 깔끔하고 관리하기 쉽게 만든다.
- 자동 호출 보장: 스프링 컨테이너는 @PreDestroy 어노테이션이 붙은 메서드를 빈의 생명주기에 맞춰 자동으로 호출하므로, 개발자는 명시적으로 정리 메서드를 호출할 필요가 없다.
주의사항
- 실행 시점: @PreDestroy 어노테이션이 붙은 메서드는 빈이 소멸되기 직전에 단 한 번만 호출된다. 따라서 메서드 내에서는 리소스 해제나 정리 작업만 수행해야 한다.
- 메서드 제한: @PreDestroy 어노테이션은 하나의 클래스에 하나의 메서드에만 적용할 수 있다. 또한, 이 메서드는 파라미터를 가질 수 없으며, void를 반환 타입으로 가져야 한다.
- 자바 표준: @PreDestroy 어노테이션은 자바 EE에서 정의된 표준이며, 스프링뿐만 아니라 다른 자바 EE 호환 컨테이너에서도 사용될 수 있다.
@Scope
@Scope 어노테이션은 스프링 프레임워크에서 빈의 스코프(생명주기 범위)를 지정할 때 사용된다.
스프링 빈의 스코프는 해당 빈이 어떻게 생성되고, 어떤 범위 내에서 존재하는지를 결정한다.
기본적으로 스프링 빈은 싱글톤 스코프를 가지지만, @Scope 어노테이션을 사용하여 빈의 스코프를 변경할 수 있다.
스코프 종류
- 싱글톤(Singleton): 기본 스코프. 스프링 컨테이너당 빈 인스턴스가 하나만 생성된다.
- 프로토타입(Prototype): 빈을 요청할 때마다 새로운 인스턴스가 생성된다.
- 요청(Request): HTTP 요청당 하나의 빈 인스턴스가 생성된다. 주로 웹 애플리케이션에서 사용된다.
- 세션(Session): HTTP 세션당 하나의 빈 인스턴스가 생성된다. 주로 웹 애플리케이션에서 사용된다.
@Component
@Scope("prototype")
public class MyPrototypeBean {
// 클래스 정의
}
위 예시에서 MyPrototypeBean 클래스는 @Scope("prototype") 어노테이션을 사용하여 프로토타입 스코프로 지정되었다. 이는 MyPrototypeBean 타입의 빈을 요청할 때마다 새로운 인스턴스가 생성됨을 의미한다.
주요 기능
- 빈의 생명주기 관리: @Scope 어노테이션을 통해 개발자는 빈의 생명주기를 원하는 방식으로 관리할 수 있다.
- 성능 최적화: 애플리케이션의 특정 부분에서만 필요한 빈의 경우, 적절한 스코프를 설정함으로써 리소스 사용을 최적화할 수 있다.
- 웹 애플리케이션 컨텍스트: 요청 및 세션 스코프는 웹 애플리케이션에서 사용자의 상태를 관리하는 데 유용하게 사용된다.
주의사항
- 의존성 주입: 프로토타입 스코프의 빈을 싱글톤 빈에 주입할 때는 프로토타입 빈의 새 인스턴스가 매번 생성되지 않는다는 점을 유의해야 한다. 이 경우 스프링의 ObjectFactory나 Provider를 사용하여 해결할 수 있다.
- 리소스 관리: 요청, 세션 스코프 빈은 해당 HTTP 요청이나 세션이 끝날 때까지만 존재하므로, 이들 스코프의 빈을 사용할 때는 리소스 해제 관련 로직을 적절히 관리해야 한다.
@Configuration
해당 클래스가 스프링의 설정 정보를 담고 있음을 나타내며, @Bean 어노테이션을 통해 빈을 정의할 수 있다.
@Configuration 소스코드를 열어보면 @Component 애노테이션이 붙어있다.
이 어노테이션은 해당 클래스가 스프링의 애플리케이션 컨텍스트에 대한 빈 정의와 서비스 구성을 포함하고 있음을 나타낸다.
@Configuration으로 선언된 클래스 내부에서 @Bean 어노테이션을 사용한 메소드를 통해 스프링 컨테이너가 관리할 빈 객체들을 정의하고 등록한다.
@Configuration
public class AppConfig {
@Bean
public MyBean myBean() {
return new MyBean();
}
}
위의 예시에서 AppConfig 클래스는 @Configuration 어노테이션으로 마킹되어 있으며, 이는 스프링에게 이 클래스가 애플리케이션의 구성 정보를 담고 있음을 알린다.
@Bean 어노테이션을 사용한 myBean 메소드는 MyBean 타입의 객체를 스프링 컨테이너에 빈으로 등록하도록 한다.
주요 기능
- 빈 정의: 애플리케이션에서 사용될 빈 객체들을 정의하고, 스프링 컨테이너에 등록한다.
- 의존성 주입 구성: @Bean 어노테이션을 사용한 메소드를 통해 의존성 주입을 위한 빈 객체들을 생성하고, 이들 사이의 관계를 정의한다.
- 애플리케이션 설정: 데이터베이스 연결, 프로퍼티 파일 설정, MVC 구성 등 애플리케이션 전반에 걸친 다양한 설정 정보를 제공한다.
주의사항
- 싱글톤 보장: @Configuration으로 마킹된 클래스 내부에서 @Bean 어노테이션으로 정의된 메소드가 반환하는 객체는 기본적으로 싱글톤으로 관리된다. 스프링은 이 메소드들을 특별하게 처리하여, 같은 빈 요청에 대해 항상 같은 인스턴스를 반환한다.
- CGLIB 프록시: @Configuration 클래스는 스프링에 의해 CGLIB를 사용하여 프록시되어, 빈 메소드 간의 호출이 싱글톤을 보장하도록 처리된다.
- 구성 클래스의 위치: @ComponentScan 어노테이션과 함께 사용될 때, @Configuration 클래스의 위치가 기준이 되어 스캔 범위를 정의한다.
@Autowired
의존성 주입을 위해 사용되며, 스프링이 자동으로 의존 객체를 연결해준다.
이 어노테이션은 스프링 컨테이너에 의해 관리되는 빈(bean) 사이의 의존 관계를 자동으로 연결해 준다.
@Autowired는 생성자, 필드, 세터 메서드에 적용할 수 있으며, 스프링은 이 어노테이션이 붙은 대상에 해당하는 타입의 빈을 찾아서 자동으로 주입한다.
생성자 주입
@Component
public class MyComponent {
private MyDependency myDependency;
@Autowired
public MyComponent(MyDependency myDependency) {
this.myDependency = myDependency;
}
}
생성자 주입은 생성자에 @Autowired를 사용하여 의존 객체를 주입받는 방식이다.
스프링 4.3 이후부터는 생성자가 하나만 있을 경우 @Autowired 어노테이션 생략이 가능하다. 변경 불가능한 의존성을 선호하거나 필수 의존성을 명시적으로 표현하고 싶을 때 권장된다.
@Controller
웹 요청을 처리하는 컨트롤러 클래스임을 나타내는 어노테이션. 일반적으로 MVC 패턴의 컨트롤러 역할을 한다.
이 어노테이션이 붙은 클래스는 웹 요청을 처리하는 핸들러로서 작동하며, 스프링 MVC의 디스패처 서블릿(DispatcherServlet)에 의해 관리된다.
@Controller는 사용자의 요청을 받아 처리한 후, 그 결과를 뷰에 전달하는 역할을 담당한다.
@Controller
public class MyController {
@RequestMapping("/greeting")
public String greeting(Model model) {
model.addAttribute("message", "Hello, World!");
return "greeting"; // 뷰 이름 반환
}
}
위 예시에서 MyController 클래스는 @Controller 어노테이션으로 선언되어 있으며, /greeting 경로로 들어오는 요청을 처리하는 메서드를 포함하고 있다.
@RequestMapping 어노테이션은 요청을 해당 메서드에 매핑한다.
메서드는 모델 객체에 메시지를 추가한 후, 뷰 이름을 반환한다. 스프링은 이 뷰 이름을 사용하여 응답을 생성한다.
주요 기능
- 요청 매핑: @RequestMapping 및 HTTP 메서드를 처리하는 @GetMapping, @PostMapping 등의 어노테이션과 함께 사용하여, 특정 URL 요청을 메서드에 매핑한다.
- 데이터 모델과의 상호작용: 요청 처리 과정에서 생성된 데이터를 뷰에 전달하기 위해 Model 객체를 사용한다.
- 뷰 선택: 처리 메서드는 뷰의 이름을 문자열 형태로 반환하며, 스프링 MVC는 이를 사용하여 최종 응답 페이지를 생성한다.
주의사항
- 뷰 기술 선택: 스프링 MVC는 JSP, Thymeleaf, FreeMarker 등 다양한 뷰 기술을 지원한다. 컨트롤러가 반환하는 뷰 이름에 해당하는 뷰 템플릿 파일이 존재해야 한다.
- 응답 바디 직접 반환: @ResponseBody 어노테이션을 메서드에 추가하면, 메서드가 반환하는 값은 뷰를 통해 렌더링되는 것이 아니라, HTTP 응답 본문으로 직접 전송된다. 이는 REST API를 구현할 때 유용하다.
- REST 컨트롤러: RESTful 웹 서비스를 구현하는 경우, @RestController 어노테이션을 사용할 수 있다. 이는 @Controller와 @ResponseBody를 합친 효과를 가진다.
@RestController
컨트롤러 클래스에 붙는 어노테이션이다. 이 어노테이션은 @Controller와 @ResponseBody 어노테이션의 조합으로 볼 수 있으며, 컨트롤러에서 반환하는 데이터가 직접 응답 본문에 쓰여지도록 한다.
즉, 모든 핸들러 메서드에서 @ResponseBody를 붙일 필요 없이 HTTP 응답 본문에 객체를 직접 매핑할 수 있게 해준다.
이 어노테이션을 사용한 클래스는 HTTP 요청을 처리하는 핸들러 메소드를 포함하며, 각 메소드는 특정 HTTP 요청(예: GET, POST, DELETE 등)에 매핑된다.
@RestController는 @Controller 와 유사하지만, 차이점은 @RestController 로 지정된 컨트롤러의 메소드가 기본적으로 HTTP 응답 본문(Body)에 직접 데이터를 작성한다는 점이다.이는@ResponseBody 어노테이션을 모든 핸들러 메소드에 적용한 것과 같은 효과를 가진다.
@Controller 는 반환 값이 String 이면 뷰 이름으로 인식된다.
그래서 뷰를 찾고 뷰가 랜더링 된다. @RestController 는 반환 값으로 뷰를 찾는 것이 아니라, HTTP 메시지 바디에 바로 입력한다.
@RestController
public class MyRestController {
@GetMapping("/users")
public List<User> getAllUsers() {
// 사용자 목록 반환
}
@PostMapping("/users")
public User createUser(@RequestBody User user) {
// 새로운 사용자 생성 및 반환
}
}
이 예시에서, @RestController 어노테이션이 적용된 MyRestController 클래스는 두 개의 메서드를 포함하고 있다.
@GetMapping 어노테이션을 사용한 getAllUsers 메서드는 사용자 목록을 반환하고, @PostMapping 어노테이션을 사용한 createUser 메서드는 요청 본문에서 받은 User 객체를 생성하고 반환한다.
이때, @RequestBody 어노테이션은 요청 본문의 데이터를 User 객체로 변환하는 데 사용된다.
주요 기능
- 간편한 RESTful API 개발: JSON이나 XML 등의 응답을 생성하는 RESTful 서비스를 쉽게 개발할 수 있다.
- 응답 본문 직접 매핑: 컨트롤러 메서드가 반환하는 객체는 자동으로 응답 본문으로 변환되어 클라이언트에게 전송된다.
- @ResponseBody 불필요: 컨트롤러 내의 모든 메서드에 대해 자동으로 @ResponseBody가 적용된다고 볼 수 있다.
주의사항
- 뷰 템플릿 사용 불가: @RestController 어노테이션이 적용된 컨트롤러에서는 뷰 템플릿을 반환할 수 없다. 모든 응답은 데이터(예: JSON, XML) 형태로 직접 클라이언트에게 전송된다.
- 적절한 HTTP 메시지 변환기 필요: 객체를 JSON이나 XML로 변환하기 위해서는 Jackson 2, JAXB 같은 HTTP 메시지 변환기가 필요하며, 이는 스프링 부트에서 자동으로 구성된다.
- 예외 처리: REST 컨트롤러에서 발생하는 예외를 적절히 처리하기 위해 @ExceptionHandler 어노테이션을 사용하는 예외 처리 메서드를 정의할 수 있다.
@Service
비즈니스 로직을 처리하는 서비스 계층의 클래스임을 나타낸다. @Component와 유사하지만, 의미적인 구분을 위해 사용된다.
이 어노테이션은 해당 클래스가 비즈니스 로직을 담당하는 서비스 레이어의 컴포넌트임을 스프링 컨테이너에게 알린다. @Service로 선언된 클래스는 스프링이 자동으로 빈으로 등록하고 관리하게 되며, 이를 통해 다른 컴포넌트들과의 의존성 주입을 쉽게 할 수 있다.
@Service
public class MyService {
public String provideService() {
return "Service provided";
}
}
위 예시에서 MyService 클래스는 @Service 어노테이션을 사용하여 서비스 계층의 컴포넌트로 선언되었다.
이 클래스 내에서 비즈니스 로직을 구현하며, 스프링 컨테이너는 이 클래스의 인스턴스를 자동으로 빈으로 등록하고 관리한다.
주요 기능
- 비즈니스 로직 구현: 애플리케이션의 핵심 비즈니스 로직을 구현하고, 데이터 접근 계층과 프레젠테이션 계층 사이의 조정자 역할을 한다.
- 트랜잭션 관리: 스프링의 선언적 트랜잭션 관리를 활용하여, 데이터베이스 트랜잭션을 처리한다.
- 의존성 주입: @Autowired 어노테이션과 같은 메커니즘을 통해, 다른 빈들(예: DAO)과의 의존성을 자동으로 주입받는다.
@Repository
데이터 접근 계층(DAO)의 클래스임을 나타내며, 예외 변환 기능을 제공한다.
이 어노테이션은 해당 클래스가 데이터 저장소와의 통신을 담당하는 컴포넌트임을 스프링 컨테이너에게 알린다.
@Repository로 선언된 클래스는 스프링이 자동으로 빈으로 등록하고 관리하며, 데이터 액세스 예외를 스프링의 데이터 접근 예외로 변환하는 기능을 제공한다.
@Repository
public class UserRepository {
// 데이터베이스와의 통신 로직 구현
}
위 예시에서 UserRepository 클래스는 데이터베이스와의 통신을 담당한다.
@Repository 어노테이션은 이 클래스가 데이터 접근 계층의 컴포넌트임을 나타내며, 스프링 컨테이너는 이를 자동으로 인식하여 빈으로 등록한다.
주요 기능
- 데이터 저장소 통신: 데이터베이스, 파일 시스템, 외부 서비스 등 다양한 데이터 저장소와의 통신 로직을 구현한다.
- 예외 변환: 데이터 접근 계층에서 발생할 수 있는 예외를 스프링의 DataAccessException으로 변환한다. 이는 데이터 접근 기술(예: JDBC, JPA, Hibernate)에 관계없이 일관된 예외 처리를 가능하게 한다.
- 자동 빈 등록: 스프링의 클래스 패스 스캐닝을 통해 자동으로 빈으로 등록되어 관리된다.
@ResponseBody
컨트롤러의 핸들러 메소드가 HTTP 응답 본문(Body)에 직접 내용을 작성할 수 있도록 지정한다.
이 어노테이션은 @Controller 어노테이션이 적용된 클래스 내의 메소드에 사용될 때 유용하며, @RestController 어노테이션과는 달리, @Controller 어노테이션과 함께 사용되어야 한다.
@RestController 어노테이션은 기본적으로 모든 메소드에 @ResponseBody 를 적용한 것과 같은 효과를 제공한다.
이 어노테이션을 메서드에 적용하면, 스프링은 해당 메서드의 반환값을 HTTP 응답 데이터로 변환하고, 클라이언트에게 직접 전송한다.
@ResponseBody는 RESTful 웹 서비스를 구현할 때 자주 사용되며, JSON이나 XML과 같은 형식으로 데이터를 클라이언트에 전달하는 데 유용하다.
@Controller
public class MyController {
@GetMapping("/message")
@ResponseBody
public String getMessage() {
return "Hello, World!";
}
}
위 예시에서 getMessage 메서드는 @ResponseBody 어노테이션이 적용되어 있으며, 이 메서드의 반환값인 "Hello, World!" 문자열이 HTTP 응답의 본문으로 직접 전송된다.
주요 기능
- 데이터 변환: @ResponseBody 어노테이션을 사용하면, 스프링의 Message Converter 가 작동하여 메서드의 반환 타입을 적절한 형식(JSON, XML 등)으로 변환한다.
- REST API 구현: RESTful 서비스에서 클라이언트에게 데이터를 JSON이나 XML 형식으로 직접 반환하는 데 필수적이다.
- 응답 커스터마이징: HTTP 응답 본문을 직접 제어할 수 있어, 응답 데이터의 형식이나 구조를 자유롭게 정의할 수 있다.
@RequestBody
@RequestBody 어노테이션은 HTTP 요청의 본문(body)을 자바 객체로 매핑할 때 사용된다.
컨트롤러 메서드의 파라미터에 이 어노테이션을 적용함으로써, 클라이언트로부터 받은 JSON, XML 등의 데이터를 자바 객체로 변환하여 사용할 수 있다.
이 과정은 스프링의 HttpMessageConverter 인터페이스에 의해 자동으로 처리된다.
@ResponseBody
public String requestBodyStringV4(@RequestBody String messageBody) {
log.info("messageBody={}", messageBody);
return "ok";
}
@ResponseBody
public String requestBodyJsonV3(@RequestBody HelloData data) {
log.info("username={}, age={}", data.getUsername(), data.getAge());
return "ok";
}
@ResponseBody
public HelloData requestBodyJsonV5(@RequestBody HelloData data) {
log.info("username={}, age={}", data.getUsername(), data.getAge());
return data; //JSON
}
주요 기능
- 데이터 변환: HTTP 요청 본문에 포함된 데이터를 자바 객체로 변환한다. 이는 주로 JSON이나 XML 형식의 데이터 처리에 사용된다.
- REST API 구현: RESTful 서비스를 구현할 때 클라이언트로부터 데이터를 받아 처리하는 경우에 필수적으로 사용된다.
- 유효성 검사: 변환된 객체에 스프링의 유효성 검사(Validation)를 적용할 수 있다. 이를 위해 @Valid 또는 @Validated 어노테이션과 함께 사용될 수 있다.
@RequestBody 를 사용하면 HTTP 메시지 바디 정보를 편리하게 조회할 수 있다.
헤더 정보가 필요하다면 HttpEntity 를 사용하거나 @RequestHeader 를 사용하면 된다.
이렇게 메시지 바디를 직접 조회하는 기능은 요청 파라미터를 조회하는 @RequestParam , @ModelAttribute 와 는 전혀 관계가 없다.
@ResponseBody와 @RequestBody
@ResponseBody 어노테이션은 컨트롤러 메소드에서 반환하는 값을 HTTP 응답 본문으로 직접 전달하는 데 사용된다.
이 어노테이션이 붙어 있으면, 메소드의 반환 데이터가 응답 본문에 바로 쓰이게 되며, 스프링의 MessageConverter를 통해 클라이언트가 요구하는 형식(JSON, XML 등)으로 자동으로 변환된다.
이는 주로 RESTful 웹 서비스에서 클라이언트에게 데이터를 직접 반환할 때 활용된다.
@RequestBody 어노테이션은 HTTP 요청 본문에서 데이터를 읽어와 메소드의 파라미터로 바인딩할 때 사용된다.
클라이언트가 보낸 요청 본문의 내용을 자바 객체로 변환하여 컨트롤러 메소드의 인자로 전달하게 된다.
이 과정에서도 스프링의 MessageConverter가 자동으로 해당 작업을 수행한다.
@RequestBody는 주로 클라이언트가 서버에 데이터를 전송할 때, 예를 들어 JSON이나 XML 형태의 데이터를 받아 처리할 때 사용된다.
간단히 말해, @ResponseBody는 서버에서 클라이언트로 데이터를 보낼 때 사용되며, @RequestBody는 클라이언트에서 서버로 데이터를 전송할 때 사용된다.
@GetMapping, @PostMapping, @PutMapping, @PatchMapping, @DeleteMapping
HTTP 요청 메서드에 따른 매핑을 지정할 때 사용한다. 각각 GET, POST, PUT, PATCH, DELETE 요청을 처리한다.
Content-Type, consume
HTTP 요청의 Content-Type 헤더를 기반으로 미디어 타입으로 매핑한다.
만약 맞지 않으면 HTTP 415 상태코드(Unsupported Media Type)을 반환한다.
Content-Type은 HTTP 요청 헤더에 포함되어, 클라이언트가 서버로 전송하는 데이터의 미디어 타입을 지정한다. 예를 들어, 클라이언트가 JSON 형식의 데이터를 보낼 경우 Content-Type: application/json으로 설정한다.
consume 속성은 스프링 컨트롤러의 메서드가 처리할 수 있는 요청의 Content-Type을 지정한다. 이 속성을 사용함으로써 특정 메서드가 특정 타입의 데이터만을 처리하도록 제한할 수 있다.
@PostMapping(value = "/mapping-consume", consumes = "application/json")
public String mappingConsumes() {
log.info("mappingConsumes");
return "ok";
}
이 속성을 사용하면 특정 타입의 데이터를 (서버의 입장에서)소비하는 요청만을 해당 컨트롤러 메소드에서 처리하도록 제한할 수 있다.
예를 들어, consumes = "application/json"이라고 지정하면, 해당 컨트롤러 메소드는 Content-Type 헤더가 application/json인 요청만을 처리한다.
Accept, produce
HTTP 요청의 Accept 헤더를 기반으로 미디어 타입으로 매핑한다.
만약 맞지 않으면 HTTP 406 상태코드(Not Acceptable)을 반환한다.
Accept 헤더는 클라이언트가 서버로부터 받을 수 있는 응답 데이터의 타입을 서버에 알린다. 클라이언트가 JSON 형식의 응답을 기대할 때는 Accept: application/json을 사용한다.
produce 속성은 컨트롤러 메서드가 클라이언트에게 반환할 데이터의 Content-Type을 지정한다. 이를 통해 해당 메서드가 생성하는 응답의 타입을 명시적으로 정의할 수 있다.
@PostMapping(value = "/mapping-produce", produces = "text/html")
public String mappingProduces() {
log.info("mappingProduces");
return "ok";
}
이 속성을 통해 클라이언트가 Accept 헤더를 통해 요청한 타입과 일치하는 응답 타입만을 반환하도록 제한할 수 있다.
예를 들어, produces = "text/html"이라고 지정하면, 해당 컨트롤러 메소드는 클라이언트에게 text/html 형식의 데이터를 반환한다.
@RequestParam
HTTP 요청 파라미터를 메서드 파라미터로 전달받을 때 사용한다.
int, String 등 기본 타입일 때 사용한다.
@RequestMapping("/request-param-v2")
public String requestParamV2(@RequestParam("username") String memberName, @RequestParam("age") int memberAge){
log.info("username={}, age={}", memberName, memberAge);
return "ok";
}
HTTP 파라미터 이름이 변수 이름과 같으면 아래와 같이 축약시킬 수 있다.
public String requestParamV3(
@RequestParam String username,
@RequestParam int age) {
log.info("username={}, age={}", username, age);
return "ok";
}
required 속성 값을 지정할 수 있는데, 기본값은 true이며, 해당 파라미터가 필수인지 여부를 설정해준다.
false로 바꾸면 해당 파라미터는 필수값이 아니다.
?username= 와 같이 파라미터 이름만 있고 값이 없는 경우 빈문자로 통과된다는 점을 주의해야 한다.
public String requestParamRequired(
@RequestParam(required = true) String username,
@RequestParam(required = false) Integer age) {
log.info("username={}, age={}", username, age);
return "ok";
}
파라미터에 값이 없는 경우 defaultValue 를 사용하면 기본 값을 적용할 수 있다.
이를 적용하면 이미 기본 값이 있기 때문에 required=true 는 의미가 없다.
defaultValue 는 파라미터 이름만 있고 값이 없는 경우에도 설정한 기본 값이 적용된다.
public String requestParamDefault(
@RequestParam(required = true, defaultValue = "guest") String username,
@RequestParam(required = false, defaultValue = "-1") int age) {
log.info("username={}, age={}", username, age);
return "ok";
}
@ModelAttribute
스프링 MVC에서 컨트롤러 메서드의 파라미터가 모델 객체에 자동으로 바인딩되도록 하거나, 모델 객체를 뷰에 전달하기 위해 사용된다.
HTTP 요청 파라미터를 @ModelAttribute 어노테이션이 붙은 메서드 파라미터나 모델 객체의 필드와 자동으로 매칭하여 바인딩한다.
이때, 폼에서 전송된 데이터의 이름과 객체의 필드 이름이 일치해야 한다.
예를 들어, 사용자가 입력 폼에서 name, email 등의 필드를 채워서 전송하면, 스프링 MVC는 이 정보를 User 객체의 name, email 필드에 매핑하여 저장한다.
String, int , Integer 같은 단순 타입 = @RequestParam
나머지 = @ModelAttribute (argument resolver 로 지정해둔 타입 외)
이 어노테이션은 두 가지 주요 용도로 활용된다
- 메서드 파라미터에 사용: 컨트롤러 메서드의 파라미터에 @ModelAttribute를 사용하면, HTTP 요청 파라미터가 해당 파라미터의 객체에 자동으로 바인딩된다. 이는 주로 폼 데이터를 받아 모델 객체를 생성하거나 업데이트할 때 사용된다.
- 메서드 레벨에 사용: @ModelAttribute 어노테이션을 메서드 레벨에 사용하면, 해당 메서드가 반환하는 객체가 모델에 추가된다. 이 객체는 뷰에서 사용할 수 있으며, 모든 요청에 대해 모델 데이터를 사전에 설정하는 데 유용하다.
메서드 파라미터에 사용하는 예시
import lombok.Data;
@Data
public class HelloData {
private String username;
private int age;
}
@ModelAttribute 를 사용하면 HelloData 객체가 생성되고, 요청 파라미터의 값도 모두 들어가진다.
public String modelAttributeV1(@ModelAttribute HelloData helloData) {
log.info("username={}, age={}", helloData.getUsername(), helloData.getAge());
return "ok";
}
스프링MVC는 @ModelAttribute 가 있으면 다음을 실행한다.
-객체를 생성한다.
-요청 파라미터의 이름으로 객체의 프로퍼티를 찾는다.
-해당 프로퍼티의 setter를 호출해서 파라미터의 값을 입력(바인딩) 한다.
@PostMapping("/add")
public String addItemV2(@ModelAttribute("item") Item item, Model model) { // -> 모델(Model)에 @ModelAttribute 로 지정한 객체를 자동으로 넣어준다.
model.addAttribute("item", item); //자동 추가, 생략 가능
return "basic/item";
}
- 데이터 바인딩: 사용자가 폼을 통해 전송한 데이터는 Item 객체의 필드와 자동으로 매칭되어 바인딩된다. 이때 폼 필드의 이름과 Item 클래스의 필드 이름이 일치해야 한다.
- 모델에 객체 추가: @ModelAttribute("item") 어노테이션은 Item 객체를 "item"이라는 이름으로 모델에 자동으로 추가하도록 지시한다. 따라서, model.addAttribute("item", item); 코드는 스프링이 자동으로 처리하기 때문에 생략이 가능하다.
- 뷰 선택 및 렌더링: 메서드가 반환하는 "basic/item" 문자열은 뷰의 이름이다. 스프링 MVC는 이 정보를 바탕으로 적절한 뷰 템플릿을 찾고, 모델에 추가된 데이터를 사용하여 HTML 페이지를 생성한다.
@PostMapping("/add")
public String addItemV2(@ModelAttribute Item item, Model model) {
return "basic/item";
}
- Model model 파라미터를 명시적으로 사용하지 않아도, @ModelAttribute로 지정된 Item 객체는 뷰로 전달될 모델에 자동으로 추가된다.
- @ModelAttribute 의 이름을 생략하면 모델에 저장될 때 클래스명을 사용한다. 이때 클래스의 첫글자만 소문자로 변경해서 등록한다.
@ModelAttribute 클래스명 모델에 자동 추가되는 이름
- Item -> item
- HelloWorld -> helloWorld
@PostMapping("/add")
public String addItemV2(Item item) {
return "basic/item";
}
최종적으로는 @ModelAttribute도 생략이 가능하다.
이때도 모델에 저장될 때 클래스명을 사용한다. 클래스의 첫글자만 소문자로 변경해서 등록한다.
메서드 레벨에 사용하는 예시
@ModelAttribute("regions")
public Map<String, String> regions() {
Map<String, String> regions = new LinkedHashMap<>(); regions.put("SEOUL", "서울");
regions.put("BUSAN", "부산");
regions.put("JEJU", "제주");
return regions;
}
@ModelAttribute("allUsers")
public List<User> populateUsers() {
return userService.findAllUsers();
}
@ModelAttribute 를 컨트롤러 클래스에서 별도의 메서드에 붙이면 해당 컨트롤러를 요청할 때 populateUsers() 에서 반환한 값이 자동으로 "allUsers"라는 이름으로 모델에 담기게 된다.
주요 기능
- 자동 데이터 바인딩: 폼 데이터와 같은 HTTP 요청 파라미터를 자동으로 자바 객체에 매핑한다.
- 모델 데이터 추가: 컨트롤러 메서드가 반환하는 객체를 모델에 추가하여 뷰에서 사용할 수 있게 한다.
주의사항
- 바인딩 에러 처리: @ModelAttribute로 데이터 바인딩 시, 바인딩 에러가 발생할 수 있다. 이를 처리하기 위해 BindingResult 파라미터를 추가할 수 있다.
- 명시적 모델 속성 이름: @ModelAttribute 어노테이션에 속성 이름을 명시적으로 지정하지 않으면, 파라미터 타입의 이름을 기반으로 한 기본 이름이 사용된다. 때로는 이 이름을 직접 지정하는 것이 더 명확할 수 있다.
@RequestParam과 @ModelAttribute
@RequestParam과 @ModelAttribute 어노테이션은 스프링 MVC에서 컨트롤러 메서드의 파라미터를 HTTP 요청과 매핑할 때 사용되며, 각각의 용도와 사용 방식이 다르다.
@RequestParam
@RequestParam은 HTTP 요청 파라미터를 컨트롤러 메서드의 파라미터에 바인딩할 때 사용된다. 주로 쿼리 파라미터나 폼 데이터에서 단일 값을 가져올 때 활용된다. 이 어노테이션은 필수 여부, 기본값 등을 설정할 수 있다.
@ModelAttribute
@ModelAttribute는 요청 파라미터를 객체에 바인딩하는 데 사용된다. 폼 데이터와 같이 여러 필드를 가진 복잡한 객체를 채울 때 주로 사용된다. 이 어노테이션은 요청 파라미터를 객체의 필드와 자동으로 매핑하여 객체를 생성하거나 업데이트한다.
주요 차이점
- 용도: @RequestParam은 주로 단일 파라미터 값을 처리할 때 사용되며, @ModelAttribute는 여러 필드를 가진 객체를 매핑할 때 사용된다.
- 복잡성: @RequestParam은 단순한 값이나 배열 등을 처리하는 데 적합하고, @ModelAttribute는 복잡한 객체를 다루는 데 적합하다.
- 사용 시나리오: @RequestParam은 단일 파라미터의 처리, 선택적 파라미터, 기본값 지정 등에 유용하며, @ModelAttribute는 폼 제출과 같이 여러 데이터가 하나의 객체로 매핑되어야 할 때 유용하다.
@PathVariable
URL 경로에 있는 변수 값을 메서드 파라미터로 전달받을 때 사용한다.
@GetMapping("/mapping/{userId}")
public String mappingPath(@PathVariable("userId") String data) {
log.info("mappingPath userId={}", data);
return "ok";
}
/mapping/userA 이런 식으로 리소스 경로에 식별자를 넣는 스타일에서 사용하는 방식이다.
@RequestMapping 은 URL 경로를 템플릿화 할 수 있는데, @PathVariable 을 사용하면 매칭 되는 부분을 편리하게 조회할 수 있다.
@PathVariable 의 이름과 파라미터 이름이 같으면 아래와 같이 생략할 수 있다.
@GetMapping("/mapping/{userId}")
public String mappingPath(@PathVariable String userId) {
log.info("mappingPath userId={}", userId);
return "ok";
}
또한 PathVariable은 다중으로 사용이 가능하다.
@GetMapping("/mapping/users/{userId}/orders/{orderId}")
public String mappingPath(@PathVariable String userId, @PathVariable Long orderId) {
log.info("mappingPath userId={}, orderId={}", userId, orderId);
return "ok";
}
@CookieValues
@CookieValue(value = "myCookie", required = false) String cookie
- value: 추출하고자 하는 쿠키의 이름을 지정한다.
- required: 이 속성은 쿠키의 존재 여부가 필수인지 아닌지를 지정한다. 기본값은 true이며, 이 경우 지정한 이름의 쿠키가 요청에 없으면 예외가 발생한다. false로 설정하면, 지정한 이름의 쿠키가 없어도 예외가 발생하지 않으며, 대신 파라미터 값은 null이 된다.
@RequestHeader
@RequestHeader 어노테이션은 스프링 MVC에서 컨트롤러 메서드의 파라미터가 HTTP 요청 헤더를 매핑할 때 사용된다.
이 어노테이션을 사용하면 클라이언트가 보낸 HTTP 요청의 헤더 정보를 메서드의 파라미터로 직접 받을 수 있다.
@RequestHeader는 주로 세션 정보, 토큰, 요청의 메타데이터 등을 처리할 때 유용하다.
@GetMapping("/headerInfo")
public String getHeaderInfo(@RequestHeader("host") String host) {
return "Host : " + host;
}
위 예시는 클라이언트로부터 받은 요청 중 "host" 헤더의 값을 String 타입의 host 변수에 저장한다.
주요 기능
- 헤더 값 추출: 특정 HTTP 요청 헤더의 값을 메서드 파라미터로 직접 받아 처리할 수 있다.
- 필수 및 선택적 헤더 처리: required 속성을 통해 해당 헤더가 필수인지 선택적인지 지정할 수 있다. 기본값은 true로, 헤더가 반드시 존재해야 한다. false로 설정할 경우 헤더가 없어도 에러가 발생하지 않는다.
required: 이 속성은 해당 헤더가 반드시 필요한지를 지정한다. 기본값은 true로, 헤더가 요청에 없을 경우 예외가 발생한다. required 속성을 false로 설정하면, 헤더가 없어도 예외가 발생하지 않고, 파라미터 값은 null 또는 defaultValue로 설정된 값이 된다.
defaultValue: 헤더가 없을 때 사용할 기본값을 지정할 수 있다. required가 false로 설정되어 있고, 요청에 특정 헤더가 없을 경우 defaultValue로 지정된 값이 변수에 할당된다.
- 기본값 설정: defaultValue 속성을 사용하여 헤더가 없을 경우 사용할 기본값을 지정할 수 있다.
주의사항
- 다양한 헤더 타입 지원: @RequestHeader는 String, int, long 등 기본 자료형 뿐만 아니라 Date, Locale 등 특정 타입으로도 자동 변환을 지원한다.
- 필수 헤더 누락 처리: 필수 헤더(required=true)가 요청에 포함되지 않은 경우, 스프링 MVC는 MissingRequestHeaderException을 발생시킨다. 이는 적절한 예외 처리 로직을 통해 관리해야 한다.
- 리스트나 맵으로의 바인딩: 특정 헤더 값이 여러 개일 경우, List<String>이나 Map<String, String>과 같은 컬렉션 타입으로도 바인딩할 수 있다. 이를 통해 같은 이름을 가진 여러 헤더 값을 효과적으로 처리할 수 있다.
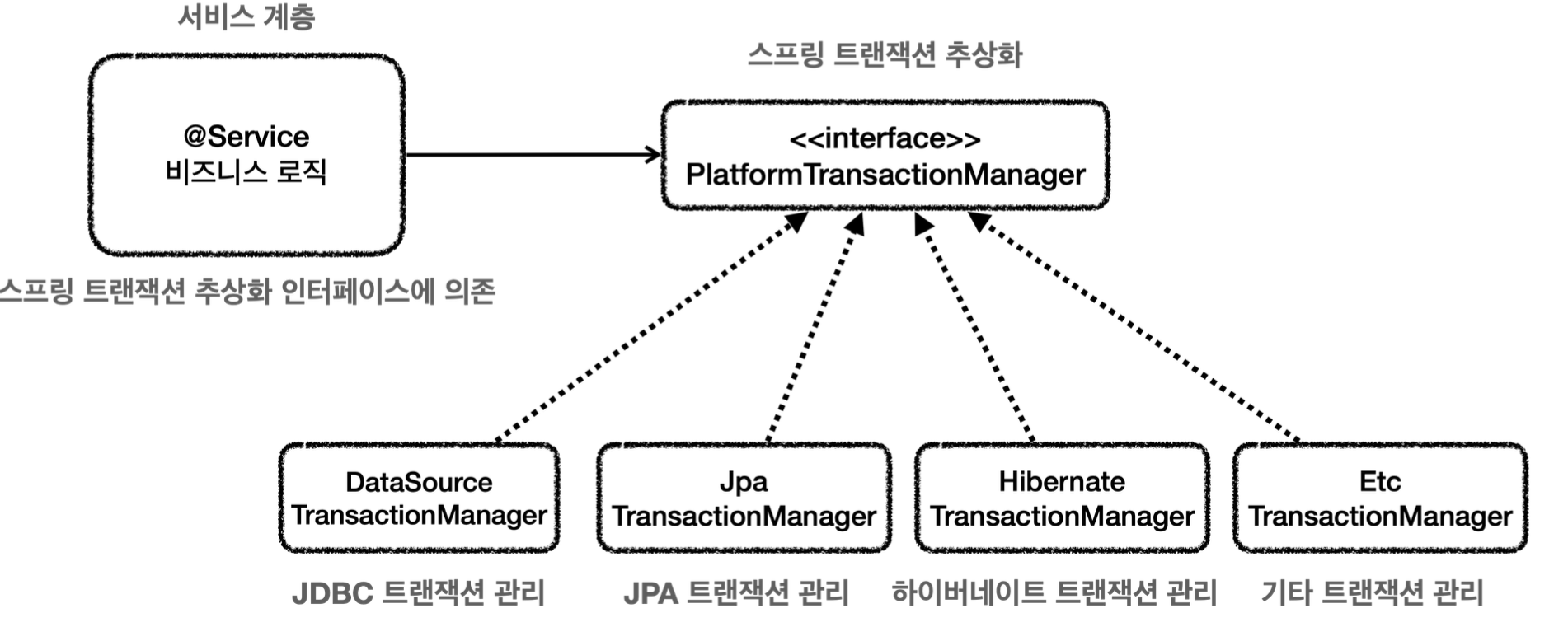
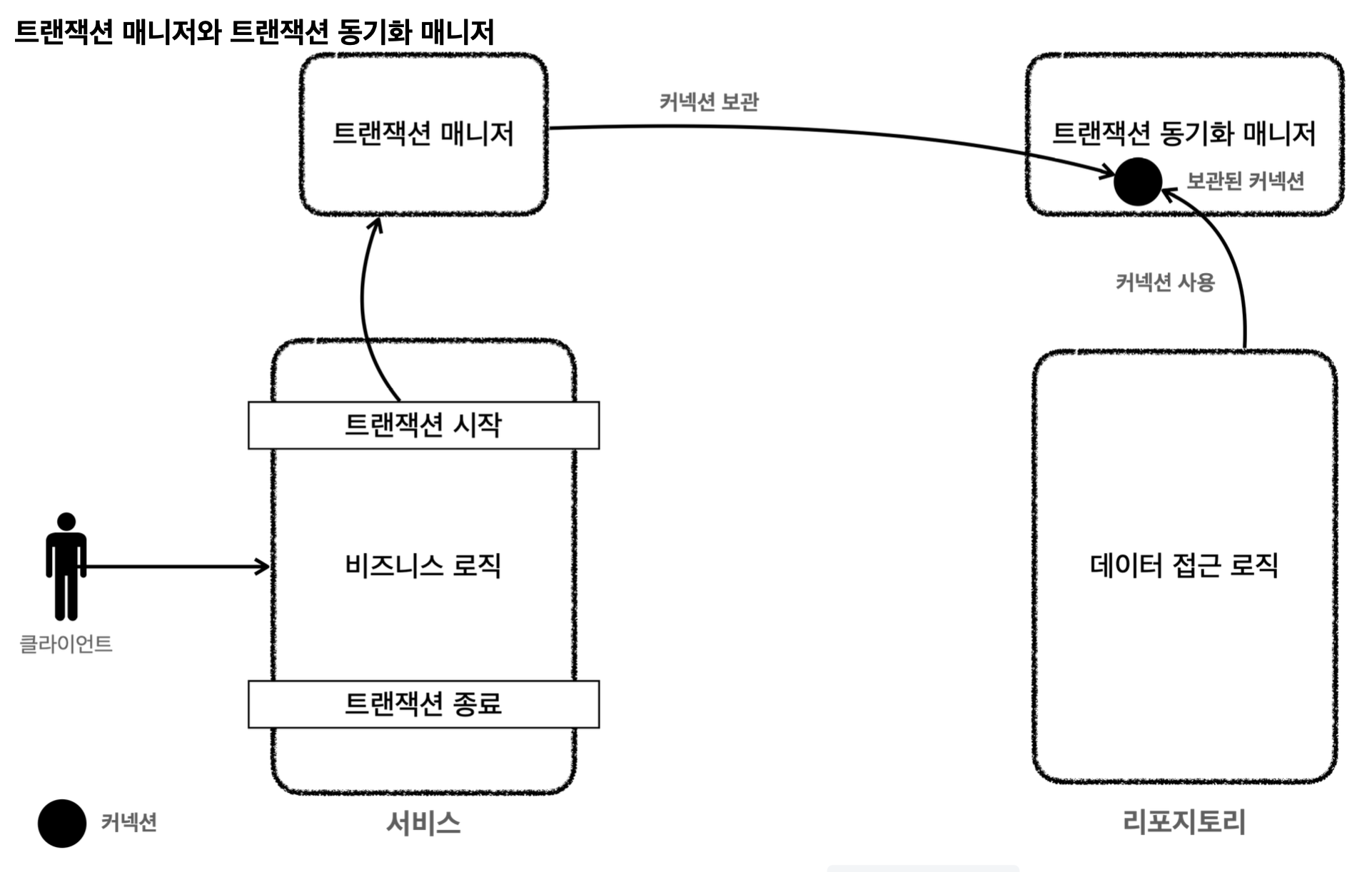
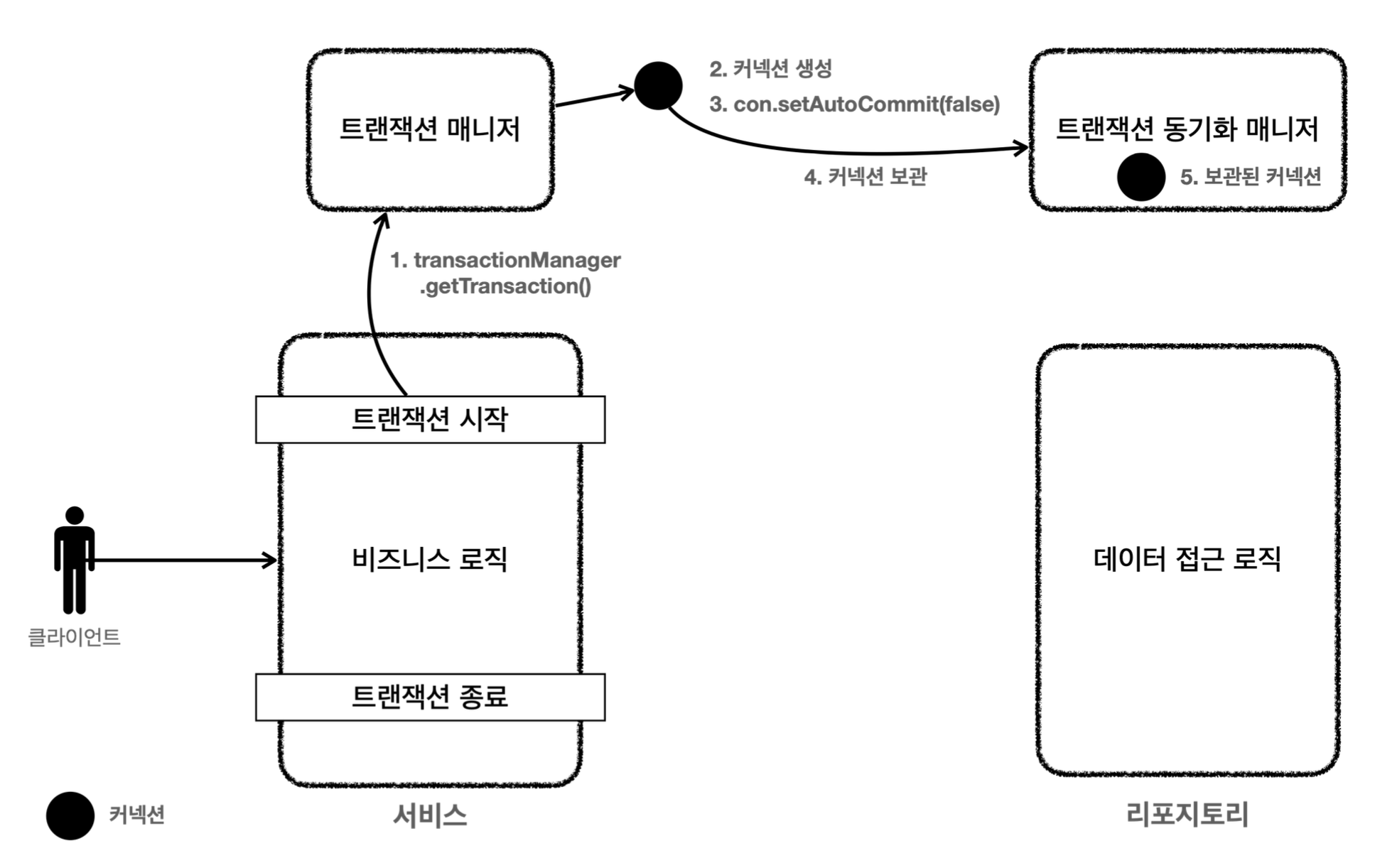
@Transactional
선언적 트랜잭션 관리를 위한 어노테이션이다.
이 어노테이션을 사용하면, 개발자는 메소드 레벨이나 클래스 레벨에서 트랜잭션의 경계를 선언적으로 지정할 수 있다.
스프링은 @Transactional이 적용된 메소드를 호출할 때 자동으로 트랜잭션을 시작하고, 메소드의 실행이 성공적으로 완료되면 트랜잭션을 커밋하며, 실행 중 예외가 발생하면 트랜잭션을 롤백한다.
@Transactional을 통해 스프링에서 제공하는 선언적 트랜잭션 관리를 효과적으로 활용할 수 있다. 이를 통해 애플리케이션의 데이터 일관성을 보장하고, 개발자가 복잡한 트랜잭션 관리 로직을 직접 작성하지 않아도 되는 편리함을 제공한다.
주요 기능 및 특징
- 트랜잭션의 자동 시작과 종료: @Transactional 어노테이션을 사용하면 트랜잭션이 자동으로 시작되고, 메소드 실행이 완료될 때 자동으로 커밋 또는 롤백된다.
- 트랜잭션 전파 설정: 트랜잭션의 전파 방식을 설정할 수 있다. 예를 들어, 이미 진행 중인 트랜잭션이 있을 때 새로운 트랜잭션을 시작할 것인지, 기존 트랜잭션에 참여할 것인지 등을 지정할 수 있다.
- 롤백 규칙 설정: 특정 예외가 발생했을 때 롤백을 수행할지 여부를 설정할 수 있다. 기본적으로 런타임 예외(RuntimeException)와 에러(Error)가 발생하면 롤백된다.
- 읽기 전용 설정: 트랜잭션을 읽기 전용으로 설정할 수 있다. 이는 트랜잭션 내에서 데이터를 변경하지 않고 오직 조회만 수행될 때 최적화를 위해 사용된다.
- 시간 제한 설정: 트랜잭션의 최대 수행 시간을 설정할 수 있다. 지정된 시간을 초과하면 트랜잭션이 자동으로 롤백된다.
클래스 레벨에 @Transactional을 붙일 때
해당 클래스의 모든 public 메소드 호출에 트랜잭션 관리가 적용된다.
클래스 레벨에서 @Transactional을 선언하면, 해당 클래스 내의 각 메소드는 별도의 @Transactional 선언이 없어도 기본적으로 선언된 트랜잭션 정책을 상속받는다.
클래스 전체에 걸쳐 일관된 트랜잭션 정책을 적용하고 싶을 때 유용하다.
특정 메소드에만 다른 트랜잭션 설정을 적용하고 싶다면, 해당 메소드에 별도의 @Transactional 어노테이션을 추가하여 클래스 레벨에서의 설정을 오버라이드할 수 있다.
메소드 레벨에 @Transactional을 붙일 때
특정 메소드 호출 시에만 트랜잭션 관리가 적용된다.
메소드 레벨에서의 선언을 통해 더 세밀한 트랜잭션 관리 정책을 구현할 수 있다. 예를 들어, 다른 트랜잭션 전파 옵션을 사용하거나, 특정 메소드에만 롤백 규칙을 다르게 적용할 수 있다.
클래스 내의 특정 메소드에만 트랜잭션을 적용하고 싶을 때, 또는 클래스 내 메소드 간에 다른 트랜잭션 설정이 필요할 때 적합하다.
클래스 레벨에 @Transactional을 선언하고, 특정 메소드에도 @Transactional을 선언하면 메소드 레벨의 어노테이션이 우선 적용된다. 즉, 메소드 레벨에서 세부적으로 트랜잭션 정책을 설정할 수 있다.
주의 사항
- @Transactional 어노테이션이 적용된 메소드는 프록시를 통해 호출될 때만 트랜잭션 관리가 적용된다. 즉, 같은 클래스 내의 메소드에서 @Transactional 메소드를 직접 호출할 경우 트랜잭션 관리가 적용되지 않을 수 있다.
- @Transactional 어노테이션을 사용할 때는 트랜잭션 관리자(예: PlatformTransactionManager 구현체)가 스프링 빈으로 등록되어 있어야 한다.
@SpringBootTest
스프링 부트 기반의 애플리케이션 테스트를 위해 사용되며, 전체 스프링 애플리케이션 컨텍스트를 로드하여 통합 테스트(Integration Test)를 수행할 수 있게 해준다. 이 어노테이션은 스프링 부트의 테스트 지원 기능의 일부로, 테스트 시 애플리케이션을 구성하는 모든 빈(Bean)들과 설정을 포함한 실행 환경을 제공한다.
또한 @Autowired 등을 통해 스프링 컨테이너가 관리하는 빈들을 사용할 수 있다.
주요 특징
- 전체 애플리케이션 컨텍스트 로드: @SpringBootTest 어노테이션을 사용한 테스트는 애플리케이션의 전체 스프링 컨텍스트를 로드한다. 이는 애플리케이션의 모든 부분이 실제와 같은 방식으로 작동하는 환경에서 테스트를 실행하고 싶을 때 유용하다.
- 플렉서블한 테스트 환경 설정: @SpringBootTest는 다양한 속성을 제공하여 테스트 실행 환경을 세밀하게 조정할 수 있다. 예를 들어, 특정 프로파일을 활성화하거나 애플리케이션의 구성 속성을 변경할 수 있다.
- 웹 환경 통합 테스트 지원: webEnvironment 속성을 통해 웹 애플리케이션의 테스트 환경을 설정할 수 있다. 예를 들어, 실제 서블릿 컨테이너를 실행하거나(Mock Servlet 환경), 완전히 모의된 웹 환경에서 테스트를 실행할 수 있다.
주의 사항
- @SpringBootTest를 사용하는 테스트는 전체 스프링 애플리케이션 컨텍스트를 로드하므로 실행 시간이 길어질 수 있다. 따라서 모든 테스트에 @SpringBootTest를 사용하기보다는 필요한 경우에만 사용하는 것이 좋다.
- 단위 테스트(Unit Test)와 통합 테스트(Integration Test)를 적절히 분리하여 테스트의 목적에 맞게 적용하는 것이 중요하다. 단위 테스트는 가능한 한 격리된 환경에서 빠르게 실행되어야 하며, 통합 테스트는 애플리케이션의 여러 부분이 함께 잘 작동하는지 검증하는 데 초점을 맞춰야 한다.
@TestConfiguration
스프링 부트에서 테스트 시 사용할 추가적인 설정을 정의할 때 사용된다.
이 어노테이션으로 표시된 클래스는 일반적인 @Configuration 클래스와 유사하지만, 주로 테스트 컨텍스트에서만 사용되는 특정 빈(bean) 설정을 제공하기 위해 사용된다.
@TestConfiguration을 사용하면 테스트 실행 시 필요한 컴포넌트나 설정을 별도로 정의하여, 테스트의 격리성과 명확성을 높일 수 있다.
주요 특징
- 테스트 전용 설정 제공: @TestConfiguration은 테스트 실행 시에만 적용되는 특별한 구성을 제공한다. 이를 통해 테스트에서 필요한 빈의 정의나 오버라이딩을 할 수 있다.
- 테스트 범위의 확장성: 일반적인 @Configuration과는 달리, @TestConfiguration으로 정의된 설정은 주로 테스트 범위 내에서만 적용된다. 이는 테스트 실행 시 테스트 환경을 보다 세밀하게 제어할 수 있게 해준다.
- 테스트 의존성 주입 가능: @TestConfiguration에서 정의된 빈은 테스트 클래스에서 @Autowired를 사용하여 주입받을 수 있다. 이는 테스트에 필요한 모의 객체(mock)나 테스트 전용 서비스 구현체 등을 쉽게 주입할 수 있도록 해준다.
@TestConfiguration을 사용하는 방법은 크게 두 가지가 있다.
내부 클래스로 정의하기: 테스트 클래스 내부에 @TestConfiguration을 사용하여 내부 클래스로 정의할 수 있다. 이 방법은 해당 테스트 클래스에서만 사용될 설정을 정의할 때 유용하다.
@SpringBootTest
public class MyServiceTest {
@TestConfiguration
static class MyServiceTestConfiguration {
@Bean
public MyService myService() {
return new MyServiceTestImpl();
}
}
@Autowired
private MyService myService;
// 테스트 로직
}
별도의 클래스로 정의하기: 테스트 전용 설정을 별도의 클래스로 정의하고, @Import 어노테이션을 사용하여 테스트 클래스에 적용할 수 있다. 여러 테스트에서 공통적으로 사용할 설정이 있을 때 적합한 방법이다.
@TestConfiguration
public class MyServiceTestConfiguration {
@Bean
public MyService myService() {
return new MyServiceTestImpl();
}
}
@SpringBootTest
@Import(MyServiceTestConfiguration.class)
public class MyServiceTest {
// 테스트 로직
}
주의 사항
- @TestConfiguration으로 정의된 빈은 기본적으로 테스트 컨텍스트에만 추가된다. 따라서 테스트 중에만 사용되며, 애플리케이션의 주 실행 컨텍스트에는 포함되지 않는다.
- 테스트가 다른 테스트에 영향을 주지 않도록, 테스트 전용 설정을 사용할 때는 격리성을 유지하는 것이 중요하다.
@BeforeEach
@BeforeEach 어노테이션은 JUnit 5에서 제공하는 테스트 라이프사이클 어노테이션 중 하나이다.
이 어노테이션이 붙은 메소드는 테스트 클래스 내의 각 테스트 메소드가 실행되기 전에 매번 호출된다.
@BeforeEach를 사용하면 테스트 실행 전에 필요한 사전 준비 작업을 자동으로 처리할 수 있어, 테스트 코드의 중복을 줄이고, 테스트의 독립성을 보장하는 데 도움이 된다.
사용 목적
- 테스트 환경 초기화: 테스트 실행 전에 특정 상태로 환경을 초기화해야 하는 경우, 예를 들어 데이터베이스 연결을 초기화하거나 테스트 데이터를 준비하는 등의 작업을 수행한다.
- 테스트 데이터 설정: 테스트 실행에 필요한 입력값이나 모의 객체(mock objects)를 설정한다.
공통 자원 할당: 여러 테스트에서 공통으로 사용될 객체나 자원을 생성하고 할당한다.
주의사항
- @BeforeEach 메소드는 테스트 메소드 실행 전에 매번 호출되므로, 테스트 간의 상태 간섭을 방지할 수 있다. 하지만, 테스트 각각에 대해 독립적으로 실행되어야 하는 초기화 코드만 포함시켜야 한다.
- 테스트 메소드 실행 전에만 수행되어야 할 작업이 아니라면, @BeforeEach가 아닌 다른 어노테이션을 고려해야 한다. 예를 들어, 모든 테스트 메소드 실행 후에 공통적으로 수행되어야 하는 작업은 @AfterEach를 사용해야 한다.
@AfterEach
@AfterEach 어노테이션은 JUnit 5에서 제공하는 테스트 라이프사이클 어노테이션 중 하나로, 각 테스트 메소드가 실행된 후에 매번 호출되는 메소드를 정의할 때 사용된다.
이를 통해 테스트 실행 후에 필요한 정리 작업을 자동으로 수행할 수 있어, 테스트 간의 독립성을 보장하고, 다음 테스트 실행에 영향을 주지 않는 깨끗한 상태를 유지할 수 있다.
사용 목적
- 리소스 해제: 테스트 실행 중에 할당된 리소스(예: 파일 핸들, 데이터베이스 연결 등)를 해제하거나 닫는 작업을 수행한다.
- 테스트 환경 정리: 테스트 실행으로 인해 변경된 외부 상태나 데이터베이스를 원래 상태로 복구한다.
- 테스트 후 검증: 테스트 실행 후 일부 후처리 검증 작업을 수행할 수도 있다.
주의사항
- @AfterEach 메소드는 테스트 메소드 실행 후에 항상 실행되므로, 테스트 간의 상태 간섭을 방지하는 데 중요한 역할을 한다. 하지만, 모든 테스트 후에 반드시 수행해야 할 작업만 이곳에 포함시켜야 한다.
- @AfterEach 메소드 내에서 발생하는 예외는 테스트의 실패 원인으로 간주될 수 있다. 따라서 리소스를 해제하는 등의 작업을 수행할 때는 예외 처리에 주의해야 한다.
- 테스트 클래스에 여러 @AfterEach 메소드가 있다면, 실행 순서를 보장하지 않는다. 필요한 경우 하나의 @AfterEach 메소드에서 모든 정리 작업을 순차적으로 호출하는 방법을 고려할 수 있다.
@Nullable
@Nullable 어노테이션은 Java나 Spring Framework 같은 프로그래밍 환경에서 사용되며, 어떤 필드, 메소드의 반환값, 또는 메소드의 매개변수가 null이 될 수 있음을 명시적으로 표시하는 데 사용된다. 이는 개발자들 사이의 명확한 의사소통을 촉진하고, 가능한 NullPointerException을 방지하는 데 도움을 준다.
메소드 반환값에 사용
메소드가 null을 반환할 수 있음을 명시적으로 표시하고 싶을 때, 반환 타입 앞에 @Nullable을 붙일 수 있다. 이는 해당 메소드를 사용하는 개발자에게 반환값을 처리할 때 null 검사를 수행해야 할 수도 있음을 알려준다.
@Nullable
public String findUsernameById(Long id) {
// 사용자 ID로 사용자 이름 조회
// 해당 ID의 사용자가 없는 경우 null 반환
}
메소드 매개변수에 사용
메소드의 매개변수가 null이 될 수 있음을 명시하고 싶을 때, 매개변수 선언 앞에 @Nullable을 붙일 수 있다. 이는 메소드 내부에서 해당 매개변수를 사용할 때 null 상태를 고려해야 함을 의미한다.
public void printUserInfo(@Nullable User user) {
if (user != null) {
// user 객체 사용
} else {
// user 객체가 null일 경우의 처리
}
}
필드에 사용
클래스의 필드가 null값을 가질 수 있음을 명시하고 싶을 때, 필드 선언 앞에 @Nullable을 사용할 수 있다. 이는 해당 필드를 사용하는 곳에서 null 검사를 수행할 필요가 있음을 알린다.
public class UserInfo {
@Nullable
private String nickname;
// nickname 필드는 null일 수 있음
}
@Nullable 어노테이션의 사용은 코드의 가독성을 향상시키고, 개발자가 의도치 않은 null 처리로 인한 오류를 줄이는 데 도움을 준다. 하지만, @Nullable을 사용할 때는 해당 값이 null일 경우에 대한 적절한 처리 로직을 구현하는 것이 중요하다.
@CookieValue
HTTP 요청에 포함된 쿠키 값을 메소드 파라미터로 바인딩하는 데 사용된다.
이 어노테이션을 사용함으로써, 개발자는 쿠키에서 데이터를 쉽게 추출하고 해당 데이터를 컨트롤러 메소드 내에서 사용할 수 있다. @CookieValue는 주로 사용자 세션 관리, 광고 추적, 사용자 설정 저장 등의 목적으로 쿠키를 사용할 때 유용하다.
기본 사용법
@CookieValue 어노테이션은 컨트롤러 메소드의 파라미터 앞에 선언한다.
쿠키 이름을 어노테이션의 값으로 지정하여, 해당 쿠키의 값을 메소드 파라미터에 자동으로 바인딩할 수 있다.
@GetMapping("/someEndpoint")
public String handleRequest(@CookieValue("cookieName") String cookieValue) {
// 여기서 cookieValue 파라미터는 "cookieName"이라는 이름의 쿠키 값으로 초기화된다.
return "쿠키 값은: " + cookieValue;
}
선택적 속성
@CookieValue 어노테이션은 몇 가지 선택적 속성을 제공한다
- value (또는 name): 바인딩할 쿠키의 이름을 지정한다.
- required: 이 속성이 true로 설정되어 있고 지정된 이름의 쿠키가 존재하지 않을 경우, 예외를 발생시킨다. 기본값은 true이지만, false로 설정하면 쿠키가 없는 경우 메소드 파라미터를 null 또는 Optional.empty()로 처리할 수 있다.
- defaultValue: 지정된 쿠키가 존재하지 않을 경우 사용할 기본값을 지정한다. 이 속성을 사용하면 required 속성이 자동으로 false가 된다.
@GetMapping("/example")
public String handleRequestWithDefault(@CookieValue(value = "cookieName", defaultValue = "defaultCookieValue") String cookieValue) {
// "cookieName" 쿠키가 없는 경우, "defaultCookieValue"가 파라미터 값으로 사용된다.
return "쿠키 값은: " + cookieValue;
}
주의 사항
@CookieValue를 사용할 때는 클라이언트 측에서 쿠키가 활성화되어 있고, 적절하게 설정되어 있어야 한다는 점을 고려해야 한다.
또한, 쿠키는 사용자의 브라우저에 저장되므로 민감한 정보를 쿠키에 저장하는 것은 피해야 한다.
필요한 경우 쿠키 값을 암호화하여 보안을 강화할 수 있다.
@SessionAttribute
스프링은 세션을 더 편리하게 사용할 수 있도록 @SessionAttribute 을 지원한다.
이미 로그인 된 사용자를 찾을 때는 다음과 같이 사용하면 된다.
@SessionAttribute(name = "loginMember", required = false) Member loginMember
이 기능은 세션을 생성하지 않는다.
이 어노테이션을 사용하면, 세션에서 직접 속성을 가져오거나 세션에 속성을 추가하는 복잡한 작업 없이, 세션에 저장된 데이터를 쉽게 사용할 수 있다.
@SessionAttribute는 주로 컨트롤러 클래스 레벨에 선언되며, 이 어노테이션으로 지정된 속성은 해당 컨트롤러의 모든 핸들러 메소드에서 접근할 수 있게 된다. 또한, 메소드 파라미터 레벨에서 사용될 수도 있어, 특정 핸들러 메소드에서만 세션 속성을 사용하고 싶을 때 유용하다.
클래스 레벨에서의 사용 예
@Controller
@SessionAttributes("user")
public class MyController {
@ModelAttribute("user")
public User createUserModel() {
return new User();
}
@GetMapping("/user/profile")
public String userProfile(Model model) {
// "user" 세션 속성 사용 가능
User user = (User) model.getAttribute("user");
return "userProfile";
}
}
메소드 파라미터 레벨에서의 사용 예
@GetMapping("/user/profile")
public String getUserProfile(@SessionAttribute("user") User user, Model model) {
// 메소드 파라미터로 "user" 세션 속성 직접 접근
return "userProfile";
}
@SessionAttribute로 지정된 세션 속성은 컨트롤러 내부에서 모델에 자동으로 추가되므로, 뷰 템플릿에서 해당 데이터를 사용할 수 있다.
이 어노테이션은 주로 읽기 전용 시나리오에서 사용될 것을 권장한다.
세션 데이터를 변경하고 싶다면, 직접 HttpSession을 사용하는 것이 좋다.
@SessionAttributes와 혼동하지 말아야 한다. @SessionAttributes는 모델 속성을 세션에 저장하기 위해 사용되며, 주로 폼 제출 과정에서 사용자의 입력 데이터를 임시로 저장하는 데 쓰인다.
반면, @SessionAttribute는 이미 세션에 저장된 속성에 접근하는 데 사용된다.
세션에서 직접 관리해야 하는 데이터가 아니라면, 가능한 한 세션 사용을 최소화하는 것이 좋다. 세션 데이터는 서버의 메모리를 사용하기 때문에, 과도한 사용은 애플리케이션의 성능에 부정적인 영향을 줄 수 있다.
TrackingModes
세션을 이용해 로그인을 하게되면 URL이 다음과 같이 jsessionid 를 포함하고 있는 것을 확인할 수 있다.
-http://localhost:8080/;jsessionid=F59911518B921DF62D09F0DF8F83F872
jsessionid가 노출되지 않도록 하기 위해서는 application.properties에 아래의 코드를 넣어주면 된다.
server.servlet.session.tracking-modes=cookie
@ControllerAdvice와 @RestControllerAdvice
Spring MVC에서 공통의 처리 로직(예외 처리, 데이터 바인딩, 모델 속성 추가 등)을 애플리케이션의 모든 컨트롤러 또는 REST 컨트롤러에 적용하기 위해 사용된다. 이 두 어노테이션은 기능적으로 유사하지만, 사용되는 컨텍스트에 따라 선택할 수 있다.
@ControllerAdvice는 예외 발생 시 에러 페이지로 이동하거나 특정 뷰를 반환하는 반면, @RestControllerAdvice는 예외 정보를 담은 JSON 객체를 HTTP 응답으로 반환한다. 따라서 개발하는 애플리케이션의 유형(웹 애플리케이션 vs RESTful API)에 맞추어 적절한 어노테이션을 선택하여 사용해야 한다.
@ControllerAdvice
@ControllerAdvice는 모든 @Controller에 대한 전역 설정을 제공한다. 이는 주로 웹 애플리케이션에서 HTML 뷰를 반환하는 컨트롤러에 적합하다.
예외 처리(@ExceptionHandler), 모델 속성 추가(@ModelAttribute), 바인딩 설정(@InitBinder)과 같은 공통 로직을 정의할 때 사용된다.
예외가 발생했을 때, 에러 페이지로 리다이렉트하거나, 특정 뷰를 반환하는 등의 처리를 할 때 적합하다.
@ControllerAdvice 에 대상을 지정하지 않으면 모든 컨트롤러에 적용된다. (글로벌 적용)
@ControllerAdvice 사용 예
@ControllerAdvice
public class GlobalExceptionHandler {
@ExceptionHandler(value = Exception.class)
public ModelAndView handleException(Exception ex) {
ModelAndView modelAndView = new ModelAndView("errorPage");
modelAndView.addObject("message", ex.getMessage());
return modelAndView;
}
}
@RestControllerAdvice
@RestControllerAdvice는 @ControllerAdvice에 추가적으로 @ResponseBody 어노테이션의 기능이 포함되어 있다. 즉, 이 어노테이션을 사용하면 반환되는 객체는 자동으로 JSON이나 XML과 같은 응답 본문으로 변환된다.
RESTful 웹 서비스를 개발할 때, JSON이나 XML로 데이터를 반환하는 @RestController에 대한 전역 설정을 제공하는 데 사용된다.
예외 처리를 통해 클라이언트에게 JSON 형식의 에러 응답을 보낼 때 유용하다.
@RestControllerAdvice 사용 예
@RestControllerAdvice
public class GlobalRestExceptionHandler {
@ExceptionHandler(value = Exception.class)
public ResponseEntity<Object> handleException(Exception ex) {
Map<String, Object> body = new HashMap<>();
body.put("message", "An error occurred");
return new ResponseEntity<>(body, HttpStatus.INTERNAL_SERVER_ERROR);
}
}
@Value
@Value는 스프링 프레임워크에서 사용되는 어노테이션으로, 필드, 메소드 매개변수, 또는 메소드(주로 설정 메소드)에 적용되어 값을 주입(inject)하는 데 사용된다. 이 어노테이션을 통해 리터럴 값, 표현식 결과, 또는 프로퍼티 파일과 같은 외부 설정 파일에 정의된 값을 주입받을 수 있다.
기본 사용법
리터럴 값 주입
@Value("Spring")
private String name;
이 경우, name 필드에 문자열 "Spring"이 주입된다.
프로퍼티 파일의 값 주입
application.properties 파일에 정의된 값을 사용하려면 ${property.name} 구문을 사용한다.
@Value("${app.name}")
private String appName;
이 경우, appName 필드에는 "SpringApp"이 주입된다.
주의사항
- 프로퍼티 미존재 시의 처리: 프로퍼티 값이 설정 파일에 없을 경우 기본 값을 지정할 수 있다. 예: @Value("${app.version:1.0}")
- 타입 변환: @Value는 자동으로 타입 변환을 수행한다. 예를 들어, 문자열을 정수나 불리언으로 변환할 수 있다.
- 표현식 한계: @Value로 복잡한 타입이나 구성을 주입하는 것은 권장되지 않는다. 이런 경우에는 @ConfigurationProperties를 사용하는 것이 더 적합할 수 있다.
@EventListener
@EventListener는 스프링 프레임워크에서 이벤트를 처리하는 메소드에 적용하는 어노테이션이다. 이 어노테이션을 사용하면 특정 이벤트가 발생했을 때 스프링 애플리케이션 컨텍스트가 자동으로 해당 메소드를 호출하도록 설정할 수 있다. @EventListener를 사용함으로써, 애플리케이션 내에서의 비동기적인 이벤트 기반 프로그래밍을 간결하고 직관적으로 구현할 수 있다.
@EventListener 어노테이션은 이벤트를 처리할 메소드에 붙여 사용한다.
@EventListener(ApplicationReadyEvent.class)
public void initData() {
log.info("test data init");
itemRepository.save(new Item("itemA", 10000, 10));
itemRepository.save(new Item("itemB", 20000, 20));
}
@EventListener(ApplicationReadyEvent.class) : 스프링 컨테이너가 완전히 초기화를 다 끝내고, 실행 준비가 되었을 때 발생하는 이벤트이다. 스프링이 이 시점에 해당 애노테이션이 붙은 initData() 메서드 를 호출해준다.
이 기능 대신 @PostConstruct 를 사용할 경우 AOP 같은 부분이 아직 다 처리되지 않은 시점에 호출될 수 있기 때문에, 간혹 문제가 발생할 수 있다. 예를 들어서 @Transactional 과 관련된 AOP가 적 용되지 않은 상태로 호출될 수 있다.
@EventListener(ApplicationReadyEvent.class) 는 AOP를 포함한 스프링 컨테이너가 완전히 초기화 된 이후에 호출되기 때문에 이런 문제가 발생하지 않는다.
@Import
@Import는 스프링 프레임워크에서 사용되는 어노테이션으로, 다른 설정 클래스들을 현재의 설정 클래스에 추가할 때 사용된다. 이 어노테이션을 사용하면 스프링 애플리케이션 컨텍스트에 빈(Bean) 설정을 집중시킬 수 있어, 애플리케이션의 구성을 더 명확하게 관리할 수 있다.
사용 방법
@Import 어노테이션은 주로 @Configuration 어노테이션이 붙은 클래스에 적용된다. 이를 통해, 하나의 설정 클래스에서 다른 설정 클래스들을 불러와서 그 설정들을 현재의 애플리케이션 컨텍스트에 합치는 것이 가능하다.
@Configuration
@Import({DataSourceConfig.class, SecurityConfig.class})
public class MainConfig {
// 기본 애플리케이션 설정
}
위의 예시에서 MainConfig 설정 클래스는 DataSourceConfig와 SecurityConfig 설정 클래스를 가져와서 사용한다. 이렇게 함으로써, MainConfig는 데이터 소스와 보안 설정을 포함한 전체 애플리케이션 설정의 중심점 역할을 한다.
주요 특징 및 이점
- 모듈화: @Import를 사용하면 애플리케이션의 구성을 여러 설정 파일로 나누어 모듈화할 수 있다. 이는 각 설정 파일이 특정 기능이나 구성 요소에 집중할 수 있게 해, 애플리케이션의 구조를 더 명확하고 관리하기 쉽게 만든다.
- 재사용성: 일반적인 구성 요소를 가진 설정 클래스를 만들고, 여러 애플리케이션 또는 애플리케이션의 다른 부분에서 재사용할 수 있다.
- 조건부 구성: @Conditional 어노테이션과 함께 사용하여 특정 조건에 따라 설정 클래스를 포함시키거나 제외시킬 수 있다.
사용 시 고려사항
- @Import는 주로 라이브러리의 설정 클래스나 애플리케이션 전반에 걸쳐 공통적으로 사용되는 설정 클래스를 추가할 때 유용하다. 그러나, 너무 많은 설정 클래스를 @Import로 가져오는 것은 관리하기 어렵게 만들 수 있으므로, 애플리케이션의 크기와 구조를 고려하여 적절히 사용해야 한다.
- @Import 어노테이션은 클래스 수준에서만 사용할 수 있다는 점을 기억해야 한다. 또한, 가져오는 설정 클래스들도 스프링 빈으로 등록되어야 한다는 점을 유의해야 한다.
@Profile
@Profile 어노테이션은 스프링 프레임워크에서 제공하는 기능으로, 특정 환경에서만 빈(Bean)을 등록하거나 활성화하고자 할 때 사용된다. 이를 통해 개발, 테스트, 프로덕션 등 다양한 환경에 맞는 구성을 쉽게 관리할 수 있다. @Profile 어노테이션을 사용하면 애플리케이션의 실행 환경에 따라 다른 빈 설정을 적용할 수 있어, 환경별로 다른 데이터베이스 설정, 다른 외부 서비스 연동 방식 등을 구성하는 데 유용하다.
사용 방법
@Profile 어노테이션은 @Component, @Service, @Repository, @Controller 등의 스테레오타입 어노테이션과 함께 사용되거나, @Configuration 클래스에 적용할 수 있다.
클래스 레벨에서 사용하는 경우
@Configuration
@Profile("development")
public class DevelopmentConfig {
// 개발 환경에서 사용할 빈 설정
}
메소드 레벨에서 사용하는 경우
@Configuration
public class ApplicationConfig {
@Bean
@Profile("production")
public DataSource dataSource() {
// 프로덕션 환경에서 사용할 데이터 소스 반환
return new ProductionDataSource();
}
}
활성화 방법
프로파일은 다양한 방식으로 활성화할 수 있다.
대표적으로스프링 부트의 application.properties 통해 설정할 수 있다.
application.properties
| spring.profiles.active=development |
주요 특징 및 이점
- 유연한 환경 구성: 다양한 환경에 맞는 구성을 한 곳에서 관리할 수 있어, 애플리케이션의 유연성이 증가한다.
- 환경별 분리: 개발, 테스트, 프로덕션 환경 등에서 다른 설정이나 빈을 사용해야 할 때 유용하다.
- 간결한 설정: 환경에 따라 다른 빈을 정의하고 선택할 수 있어, 조건별로 복잡한 구성 로직을 구현할 필요가 없다.
@Param
@Param 어노테이션은 Spring Data JPA에서 쿼리 메서드의 파라미터를 쿼리에 바인딩하는 데 사용된다. 이 어노테이션을 사용하면 메서드의 파라미터를 JPQL 혹은 SQL 쿼리 내에서 명시적으로 참조할 수 있다. @Param 어노테이션은 메서드 파라미터에 할당된 이름을 쿼리 내의 파라미터 이름과 매핑한다.
사용 예시
Spring Data JPA를 사용하여 사용자 이름과 이메일을 기준으로 사용자를 검색하는 기능을 구현한다고 가정해 보자. UserRepository 인터페이스에 새로운 쿼리 메서드를 추가할 때, @Param 어노테이션을 사용하여 쿼리의 파라미터를 명시적으로 정의할 수 있다.
public interface UserRepository extends JpaRepository<User, Long> {
@Query("SELECT u FROM User u WHERE u.name = :name AND u.email = :email")
List<User> findByNameAndEmail(@Param("name") String name, @Param("email") String email);
}
이 예시에서 @Query 어노테이션은 사용자 정의 쿼리를 나타내며, :name과 :email은 쿼리 내의 파라미터를 나타낸다. @Param 어노테이션은 메서드 파라미터(name과 email)가 쿼리의 파라미터(:name, :email)와 어떻게 매핑되는지 지정한다. 이렇게 함으로써, 메서드를 호출할 때 전달된 실제 파라미터 값이 쿼리에 바인딩된다.
@Query
어노테이션은 Spring Data JPA에서 사용자 정의 쿼리를 정의하는 데 사용된다. 이 어노테이션을 사용하면 개발자는 JPQL(Java Persistence Query Language) 또는 네이티브 SQL 쿼리를 직접 작성하여 Repository 메서드에 연결할 수 있다. @Query는 표준 CRUD 작업을 넘어서는 복잡한 조회나 연산을 필요로 할 때 유용하게 사용된다.
사용 예시
사용자 이름으로 사용자를 검색하는 쿼리를 정의하려고 한다. 이때, @Query 어노테이션을 사용하여 UserRepository 인터페이스에 메서드를 추가할 수 있다.
public interface UserRepository extends JpaRepository<User, Long> {
@Query("SELECT u FROM User u WHERE u.name = :name")
List<User> findByName(@Param("name") String name);
}
이 예시에서 @Query 어노테이션 내의 문자열은 JPQL 쿼리이며, :name은 쿼리의 파라미터를 나타낸다. @Param 어노테이션은 메서드의 name 파라미터가 쿼리의 :name 파라미터에 바인딩되도록 지정한다.
네이티브 쿼리 사용 예시
때때로, JPQL로 표현하기 어려운 데이터베이스 특정 기능을 사용해야 할 경우가 있다. 이런 경우에는 네이티브 SQL 쿼리를 사용할 수 있다.
public interface UserRepository extends JpaRepository<User, Long> {
@Query(value = "SELECT * FROM users WHERE name = :name", nativeQuery = true)
List<User> findByNameUsingNativeQuery(@Param("name") String name);
}
이 예시에서는 nativeQuery = true 속성을 통해 네이티브 SQL 쿼리를 사용하고 있음을 명시한다. 이렇게 하면, 직접 데이터베이스에 특화된 쿼리를 사용할 수 있다.
@PersistenceContext
EntityManager를 주입하기 위해 사용하는 어노테이션이다. 이 어노테이션을 사용하면 JPA의 영속성 컨텍스트와 연결된 EntityManager 인스턴스를 스프링이 자동으로 주입해준다.
EntityManager란?
EntityManager는 JPA에서 엔티티를 관리하는 주요 인터페이스로, 데이터베이스와의 CRUD(Create, Read, Update, Delete) 작업을 수행하는 데 사용된다.
EntityManager는 영속성 컨텍스트(Persistence Context)와 연결되어 있으며, 영속성 컨텍스트는 엔티티의 상태를 관리하고 데이터베이스와 동기화한다.
사용 방법
@PersistenceContext는 EntityManager를 주입하기 위한 어노테이션이다. 이 어노테이션을 사용하면 스프링 컨테이너가 EntityManager를 자동으로 주입해준다.
import jakarta.persistence.EntityManager;
import jakarta.persistence.PersistenceContext;
import org.springframework.stereotype.Repository;
@Repository
public class MemberRepository {
@PersistenceContext
private EntityManager em;
public Member find(Long id) {
return em.find(Member.class, id);
}
public void save(Member member) {
em.persist(member);
}
public void delete(Member member) {
em.remove(member);
}
}
위 예제에서 @PersistenceContext를 사용하여 EntityManager를 주입받고, 이를 이용해 Member 엔티티를 관리하는 메서드를 정의하고 있다.
@PersistenceContext와 트랜잭션
EntityManager는 일반적으로 트랜잭션 컨텍스트 내에서 사용된다. 스프링에서는 @Transactional 어노테이션을 사용하여 트랜잭션을 관리할 수 있다.
@Transactional이 적용된 메서드에서는 EntityManager를 통해 데이터베이스 작업이 수행되며, 작업이 끝나면 트랜잭션이 자동으로 커밋 또는 롤백된다.
import jakarta.persistence.EntityManager;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Repository;
@Repository
public class MemberRepository {
@Autowired
private EntityManager em;
public Member find(Long id) {
return em.find(Member.class, id);
}
public void save(Member member) {
em.persist(member);
}
}
대체 어노테이션 @Autowired
스프링 부트에서는 @Autowired를 사용하여 EntityManager를 주입받을 수도 있다. 이 경우, 스프링은 내부적으로 @PersistenceContext와 동일한 방식으로 EntityManager를 처리한다.
하지만, @PersistenceContext는 JPA 표준 어노테이션이므로, JPA 관련 클래스에서는 @PersistenceContext를 사용하는 것이 권장된다.
import jakarta.persistence.EntityManager;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Repository;
@Repository
public class MemberRepository {
@Autowired
private EntityManager em;
public Member find(Long id) {
return em.find(Member.class, id);
}
public void save(Member member) {
em.persist(member);
}
}
결론
- @PersistenceContext는 JPA에서 EntityManager를 주입받기 위한 표준적인 방법이다.
- 이 어노테이션을 통해 JPA의 영속성 컨텍스트와 연관된 EntityManager를 주입받아 데이터베이스 작업을 수행할 수 있다.
- 트랜잭션을 관리할 때는 @Transactional과 함께 사용하는 것이 일반적이다.