이 글은 누구나 자료 구조와 알고리즘(저자 : 제이 웬그로우)의 내용을 개인적으로 정리하는 글임을 알립니다.
패스트푸드점에서 손님이 음식을 주문하는 프로그램을 작성 중이고, 음식마다 각각 가격이 있는 메뉴를 구현하고 있다고 상상해 보자.

메뉴 배열 안에 메뉴의 이름과 가격을 포함하는 배열이 또 있다고 가정하면, 메뉴 배열안에 있는 하위 배열을 찾는데 O(N)의 단계가 걸린다.
정렬된 배열이라면 이진탐색을 통해O(logN)이 걸린다.
하지만 해시 테이블을 사용하면 데이터를 O(1)만에 룩업할 수 있다.
해시 테이블
해시 테이블은 다양한 프로그래밍 언어에서 서로 다른 이름으로 불린다.
해시, 맵, 해시맵, 딕셔너리, 연관 배열 등의 이름을 갖는다.
대부분의 프로그래밍 언어는 해시 테이블(hash table)이라는 자료구조를 포함하며, 해시 테이블에는 빠른 읽기라는 놀랍고 엄청난 능력이 있다.
해시 테이블은 쌍으로 이뤄진 값들의 리스트다.

첫 번째 항목을 키라 부르고, 두 번째 항목을 값이라 부른다.
french fries가 키이고, 0.75가 값이다.
이렇게 해시 테이블로 구성되어 있다면 프랜치프라이가 가격이 얼마인지 딱 한 단계만에 알 수 있다.
해시 테이블의 값 룩업은 딱 한 단계만 걸리므로 평균적으로 효율성이 O(1)이다.
해시 함수로 해싱
비밀 코드를 만들고 해독한다고 가정해보자.
예를 들어 아래처럼 단순하게 글자와 숫자를 짝지을 수 있다.

위 코드에 따르면, ACE는 135로, CAB는 312로, DAB는 412로, BAD는 214로 변환된다.
- 문자를 가져와 숫자로 변환하는 과정을 해싱(hasing)이라 부른다.
- 글자를 특정 숫자로 변환하는데 사용한 코드를 해시 함수(hash function)라 부른다.
이 밖에도 해시 함수는 많다. 또 다른 해시 함수 예제는 각 문자에 해당하는 숫자를 가져와 모든 수를 합쳐 반환하는 것이다.
이렇게 하면 BAD는 아래와 같은 두 단계의 과정을 거쳐 숫자 7이 된다.
- 먼저 BAD를 214로 변환한다.
- 각 숫자를 가져와 합한다.
2 + 1 + 4 = 7
또 다른 해시 함수 예제는 문자에서 해당하는 모든 수를 곱해서 반환하는 것이다.
- BAD를 214로 변환한다.
- 각 숫자를 가져와 곱한다.
2 x 1 x 4 = 8
실제 쓰이는 해시 함수는 이보다 더 복잡하지만 이러한 "곱셈" 해시 함수를 사용하면 예제가 명확하고 간단해진다.
해시 함수가 유효하려면 딱 한 가지 기준을 충족해야 한다.
해시 함수는 동일한 문자열을 해시 함수에 적용할 때마다 항상 동일한 숫자로 변환해야 한다.
주어진 문자에 대해 반환하는 결과가 일관되지 않으면 그 해시함수는 유효하지 않다.
따라서 난수나 현재 시간을 계산에 넣어 사용하는 해시 함수는 유효하지 않다.
하지만 곱셈 해시 함수를 쓰면 BAD는 항상 8로 변환된다.
B는 항상 2고, A는 항상 1이고, D는 항상 4이기 때문이다.
따라서 2 x 1 x 4는 항상 8이다.
곱셈 해시 함수를 쓰면 DAB역시 BAD처럼 8로 변환된다는 것에 유의한다. 이로 인해 실제로 문제가 발생한다.
유의어 사전 만들기
사용자가 당신이 만든 사전에서 단어를 룩업하면 구식 유의어 사전 앱처럼 가능한 유의어를 모두 반환하는 대신 유의어를 딱 하나만 반환한다.
모든 단어에는 각각 연관된 동의어가 있으므로 동의어는 해시 테이블의 좋은 사용 사례다.
다음과 같이 해시테이블로 유의어 사전을 표현한다고 하자.

배열과 유사하게 해시 테이블은 내부적으로 데이터를 한 줄로 이뤄진 셀 묶음에 저장한다.
각 셀마다 주소가 있다.
예를 들면 아래와 같다.

첫 번째 항목을 해시 테이블에 추가하자

컴퓨터는 해시 테이블을 만들기 위해 키에 해시 함수를 적용한다.
BAD = 2 x 1 x 4 = 8
키("bad")는 8로 해싱되므로 컴퓨터는 값("evil")을 아래와 같이 셀 8에 넣는다.


다시 한번 컴퓨터는 키를 해싱한다.
CAB = 3 x 1 x 2 = 6
결괏값이 6이므로 컴퓨터는 값("taxi")를 셀 6에 저장한다.


ACE = 1 x 3 x 5 = 15
ACE는 15로 해싱되고 "star"는 셀 15로 들어간다.


해시 테이블 룩업
해시 테이블에서 항목을 룩업할 때는 키를 사용해 연관된 값을 찾는다.
키 bad의 값을 룩업하고 싶다고 하자.

bad의 값을 찾기 위해 컴퓨터는 간단히 두 단계를 실행한다.
- 컴퓨터는 룩업하고 있는 키를 해싱한다. BAD = 2 x 1 x 4 = 8
- 결과가 8이므로 셀 8을 찾아가서 저장된 값을 반환한다. 즉, evil을 반환한다.
해시 테이블에서 각 값의 위치는 키로 결정된다.
즉, 키 자체를 해싱해 키와 연관된 값이 놓여야 하는 인덱스를 계산한다.
키가 값의 위치를 결정하므로 이 원리를 사용하면 룩업이 아주 쉬워진다.
어떤 키가 있고 그 키의 값을 찾고 싶으면 키 자체로 값을 어디서 찾을 수 있는지 알 수 있다.
이제 왜 해시 테이블의 값 룩업이 전형적으로 O(1)인지 명확해졌다.
단방향 룩업
키를 사용해 값을 찾을 때만 O(1) 룩업이 가능하다.
거꾸로 값을 이용해 연관된 키를 찾을 때는 해시 테이블의 빠른 룩업 기능을 활용할 수 없다.
이는 키가 값의 위치를 결정한다는 해시 테이블의 대전제 때문이다.
하지만 이 전제는 한 방향으로만, 다시 말해 키를 사용해 값을 찾는 식으로만 동작한다.
세부적으로는 언어에 따라 다르지만 어떤 언어는 값 바로 옆에 키를 저장한다.
이렇게 저장하면 다음 절에서 다룰 충돌에서 매우 유용하다.
또한 각 키는 해시 테이블에 딱 하나 존재할 수 있으나 값은 여러 인스턴스가 존재할 수 있다.
처음에 살펴봤던 메뉴 예제를 떠올리면 같은 햄버거를 두 번 나열할 수 없다.
하지만 값은 여러 인스턴스가 존재할 수 있다.
즉 다른 햄버거라도 가격은 같을 수 있다.
대부분의 언어는 이미 존재하는 키에 키/값 쌍을 저장하려 하면 키는 그대로 두고 기존 값만 덮어쓴다.
충돌 해결
해시 테이블은 좋은 자료구조이지만 문제도 있다.
유의어 사전 예제를 살펴보자.
아래와 같은 항목을 예제의 유의어 사전에 추가하면 아래와 같은 일이 벌어진다.

DAB = 4 x 1 x 2 = 8
pat을 해시 테이블의 셀 8에 추가하려 한다.

셀 8에는 이미 값이 존재한다.
이미 채워진 셀에 데이터를 추가하는 것을 충돌이라 부른다.
다행히 이 문제를 해결하는 방법들이 있다.
충돌을 해결하는 고전적인 방법하나가 분리 연결법이다.
충돌이 발생했을 때 셀에 하나의 값을 넣는 대신 배열로의 참조를 넣는 방법이다.

이렇게 되어 있던 배열을 아래와 같이 바꾼다.
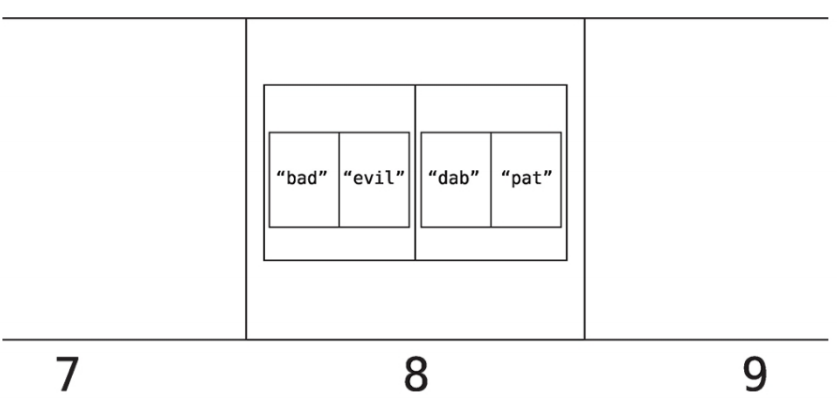
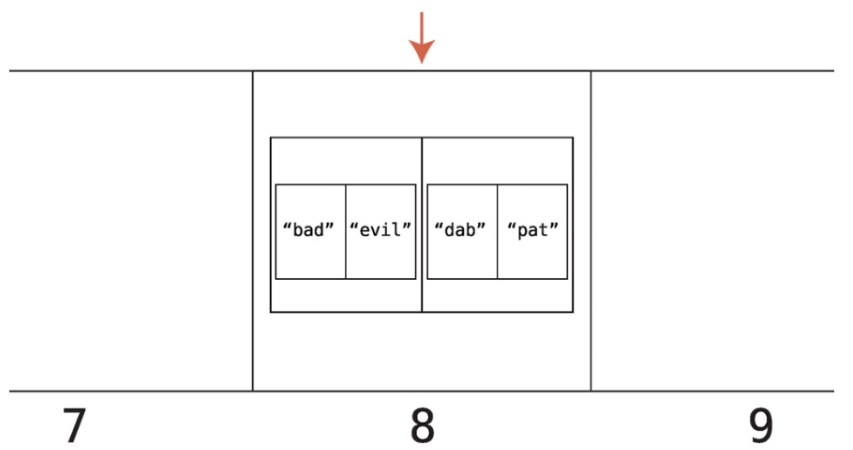
이렇게 바꿨을 때 해시 테이블 룩업은 thesaurus["dab"]을 룩업할 때 컴퓨터는 아래와 같은 단계를 거친다.
- DAB = 4 x 1 x 2 = 8
- 셀 8을 룩업 한다. 컴퓨터는 셀 8이 하나의 값이 아닌 배열들의 배열을 포함하고 있음을 알게 된다.
- 각 하위 배열의 인덱스를 찾아보며 룩업하고 있는 단어인 dab을 찾을 때까지 배열을 차례대로 검색한다.
일치하는 하위 배열의 인덱스 1에 있는 값을 반환한다.

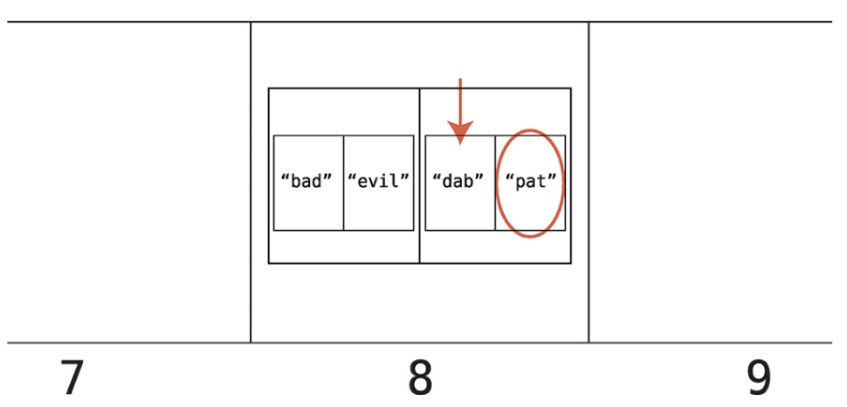
컴퓨터가 확인 중인 셀이 배열을 참조할 경우 다수의 값이 들어 있는 배열을 선형 검색해야 하므로 검색 단계가 더 걸린다.
만약 모든 데이터가 해시 테이블의 한 셀에 들어가게 된다면 해시 테이블은 배열보다 나을게 없다.
따라서 최악의 경우 해시 테이블 룩업 성능은 사실상 O(N)이다.
이렇기 때문에 해시 테이블에 충돌이 거의 없도록 O(N) 시간이 아닌 O(1) 시간 내에 일반적으로 룩업을 수행하도록 디자인해야 한다.
효율적인 해시 테이블 만들기
궁극적으로 해시 테이블은 아래 세 요인에 따라 효율성이 정해진다.
- 해시 테이블에 얼마나 많은 데이터를 저장하는가
- 해시 테이블에서 얼마나 많은 셀을 쓸 수 있는가
- 어떤 해시 함수를 사용하는가
처음 두 요인이 중요한 이유는 적은 셀에 많은 데이터를 저장하면 충돌이 많을 테고 해시 테이블의 효율성은 떨어진다.
세 번째 요인이 중요한 이유는

이러한 셀이 있다고 가정하면, 어떤 해시 함수를 사용하면 10에서 16 사이의 셀은 이용할 수 없다고 하면 셀의 낭비가 되고 낭비되는 만큼 효율이 저하된다.
따라서 좋은 해시 함수란 사용 가능한 모든 셀에 데이터를 분산시키는 함수이다.
데이터를 넓게 퍼뜨릴수록 충돌이 적다.
충돌 조정을 위해 컴퓨터 과학자는 해시테이블에 저장된 데이터가 7개면 셀은 10개여야 한다고 말한다.
데이터와 셀 간 이러한 비율을 부하율이라 부른다.
데이터를 더 추가하기 시작하면 새 데이터가 새로운 셀들에 균등하게 분산되도록 컴퓨터는 셀을 더 추가하고 해시 함수를 바꿔서 해시 테이블을 확장한다.
'자료구조 & 알고리즘 > 자료구조' 카테고리의 다른 글
| [자료구조] 그래프(Graph) (0) | 2023.12.16 |
|---|---|
| [Java] Heap(힙)과 Priority Queue(우선순위 큐) (0) | 2023.10.22 |
| [자료구조] 배열과 배열 기반의 집합 (1) | 2023.08.09 |
| [JAVA] 큐(Queue) / 링 버퍼(Ring Buffer) / 데크(Deque) (0) | 2023.01.29 |
| [JAVA] 스택(Stack) (0) | 2023.01.28 |

댓글