이 글은 누구나 자료 구조와 알고리즘(저자 : 제이 웬그로우)의 내용을 개인적으로 정리하는 글임을 알립니다.
배열의 크기와 인덱스
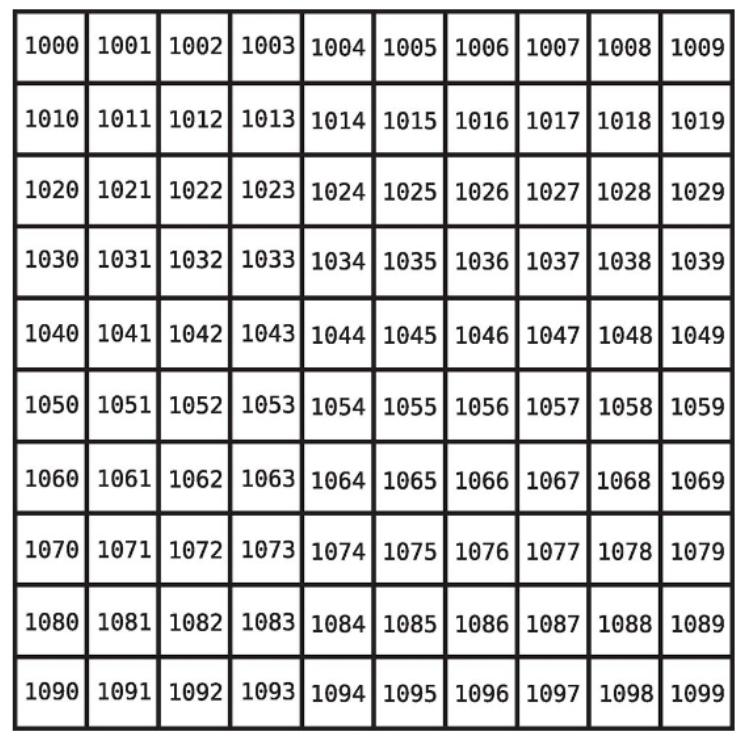
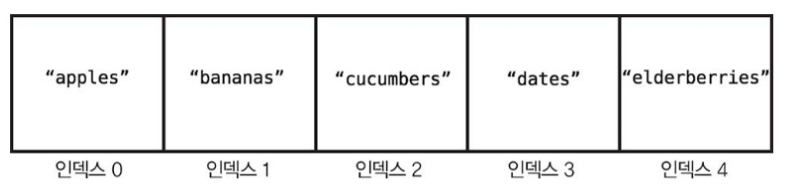
배열의 크기 : 배열에 데이터 원소가 얼마나 들어있는지를 나타낸다. 위 그림에서 배열의 크기는 5이다.
배열의 인덱스 : 특정 데이터가 배열의 어디에 있는지 알려주는 숫자다.
자료구조 연산
대부분의 자료 구조는 네 가지 기본 방법을 사용하며 이를 연산이라 부른다.
연산은 아래와 같다.
읽기
검색
삽입
삭제
연산의 속도 측정
연산이 얼마나 '빠른가'를 측정 할 때는 순수하게 시간 관점에서 연산이 빠른가가 아니라,
얼마나 많은 단계가 필요한지를 논해야 한다.
왜 코드의 속도를 시간으로 측정하지 않을까? 누구도 어떤 연산이, 정확히 몇초가 걸린다고 단정할 수 없기 때문이다. 같은 연산도 어떤 컴퓨터에서는 1초가 걸리고, 구형 하드웨어에서는 더 오래걸릴 수 있기 때문이다. 슈퍼 컴퓨터는 훨씬 빠를 수도 있다. 시간은 실행하는 하듸웨어에 따라 항상 바뀌므로 시간을 기준으로 속도를 측정하면 신뢰할 수 없다.
연산의 속도를 측정할 때 얼마나 많은 단계(step)가 필요한가를 따져볼 수 있다.
같은 작업을 처리하는데, A 알고리즘은 5단계가 필요하고, B 알고리즘은 500단계가 필요하면, 모든 하드웨어에서 연산 A가 연산 B보다 항상 빠를 거라고 가정할 수 있다.
결국 단계 수 측정이 연산 속도를 분석하는 핵심 비결이다.
읽기
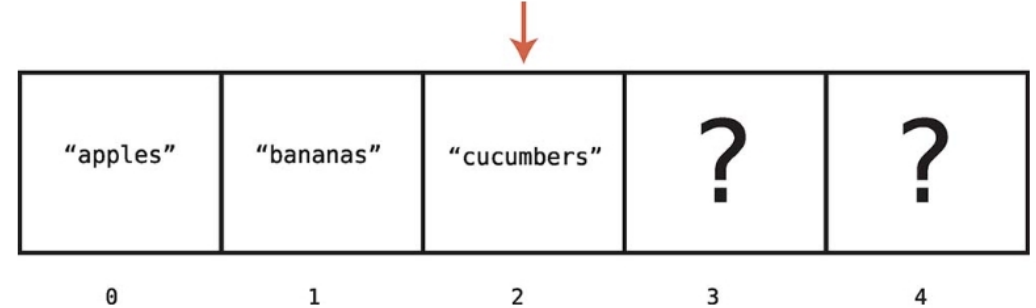
읽기는 배열 내 특정 인덱스에 어떤 값이 들어있는지 찾아보는 것이다.
컴퓨터는 딱 한 단계로 배열에서 읽을 수 있다.
위 배열에서 인덱스 2를 찾아본다면 컴퓨터는 인덱스 2로가서 cucumbers라는 값이 있다고 알려줄 것이다.
컴퓨터의 메모리는 어떻게 단 한 단계로 배열의 인덱스를 찾아볼 수 있는가? 컴퓨터의 메모리는 셀로 구성된 거대한 컬렉션이라 할 수 있다. 어떤 셀은 비어 있고, 어떤 셀에는 데이터가 들어있다. 예를 들어 원소 다섯 개를 넣을 배열을 생성하면 컴퓨터는 한 줄에서 5개의 빈 셀 그룹을 찾아 사용자가 사용할 배열로 지정한다. 컴퓨터 메모리 내에 각 셀에는 특정 주소가 있다. 각 셀의 메모리 주소는 앞 셀의 주소에서 1씩 증가한다. -컴퓨터는 모든 메모리 주소에 한 번에 갈 수있다.(특정 메모리의 값을 조사 요청을 받으면 검색 과정 없이 바로 간다) -컴퓨터는 배열을 할당할 때 어떤 메모리 주소에서 시작하는지도 기록해 둔다. 위와 같은 점들이 컴퓨터가 배열의 첫 번째 값을 어떻게 한 번에 찾아내는지 설명한다.
컴퓨터에 인덱스 3에 있는 값을 읽으라고 명령하면 컴퓨터는 아래와 같은 과정을 밟는다. 1. 배열의 인덱스는 0부터 시작하며 인덱스 0의 메모리 주소는 1010이다. 2. 인덱스 3은 인덱스 0부터 정확히 세 슬롯 뒤에 있다. 3. 따라서 인덱스 3을 찾으려면 1010 + 3인 1013 메모리 주소로 간다.
인덱스 3의 메모리 주소가 1013임을 알아낸 컴퓨터는 바로 접근해서 "dates"라는 값을 찾을 수 있다.
검색
검색은 배열에 특정 값이 있는지 알아본 후, 있다면 어떤 인덱스에 있는지 찾는 것이다.
읽기는 컴퓨터에 인덱스를 제공하고 그 인덱스에 들어있는 값을 반환하라고 요청
검색은 컴퓨터에 값을 제공하고 그 값이 들어 있는 인덱스를 반환하라고 요청
읽기와 검색은 비슷해 보이지만 효율성 측면에서 매우 큰 차이를 보인다.
검색은 컴퓨터가 특정 값으로 바로 갈 수 없으니 오래 걸린다.
왜냐하면, 컴퓨터는 모든 메모리 주소에 한 번에 접근하지만 각 메모리 주소에 어떤 값이 있는지 바로 알지 못하기 때문이다.
배열에서 어떤 원소를 찾으려면 컴퓨터는 각 셀을 한 번에 하나씩 조사하는 방법밖에 없다.
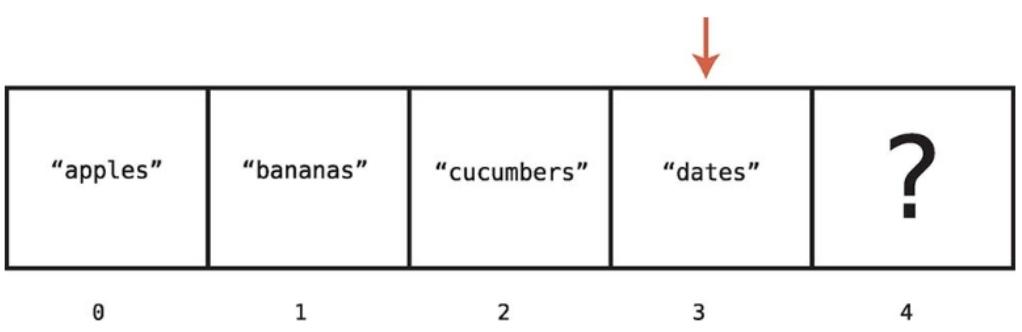
아래의 그림은 'dates'를 찾는 과정이다.
dates를 찾았고, 인덱스 3에 있음을 알았다.
찾고 있던 값을 발견했으니 컴퓨터는 배열의 다음 셀로 이동해서 검색할 필요가 없다.
컴퓨터는 찾으려던 값을 발견할 때까지 4개의 셀을 확인하므로 이 연산에는 총 4단계가 걸렸다고 할 수 있다.
컴퓨터가 한 번에 한 셀씩 확인하는 방법을 선형 검색이라고 부른다.
N칸의 배열에서의 선형 검색을 수행하는데 필요한 최대 단계수는 N개이다.
크기가 5인 배열에서 선형 검색을 수행하는데 필요한 최대 단계수는 5개
크기가 100인 배열에서 선형 검색을 수행하는데 필요한 최대 단계수는 100개
삽입
배열에 새 데이터를 삽입하는 연산은 배열의 어디에 데이터를 삽입하는가에 따라 효율성이 다르다.
맨 끝에 데이터 삽입
배열의 맨 끝에 데이터를 추가하는 것은 딱 한 단계만 필요하다.
문제점 하나 애초에 컴퓨터는 배열에 5개의 메모리 셀을 할당했고 6번째 원소를 추가하려면 이 배열에 셀을 추가로 할당해야 할 수 있다.
많은 프로그래밍 언어가 내부에서 자동으로 처리하지만 언어마다 방식이 다르다.
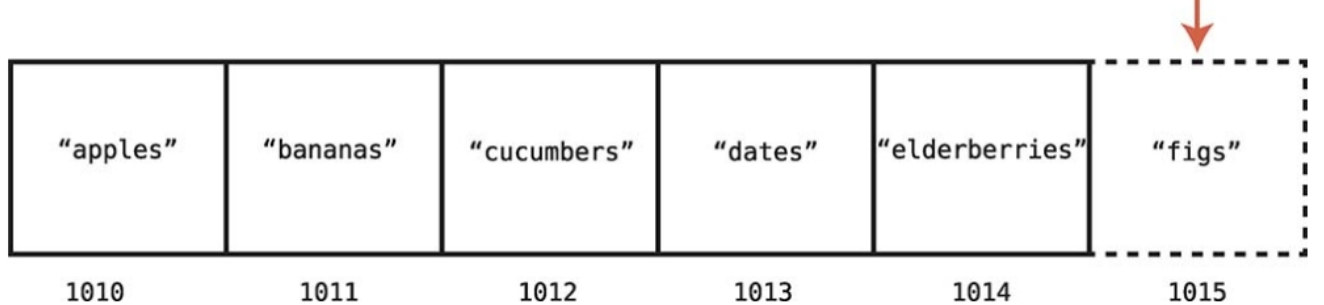
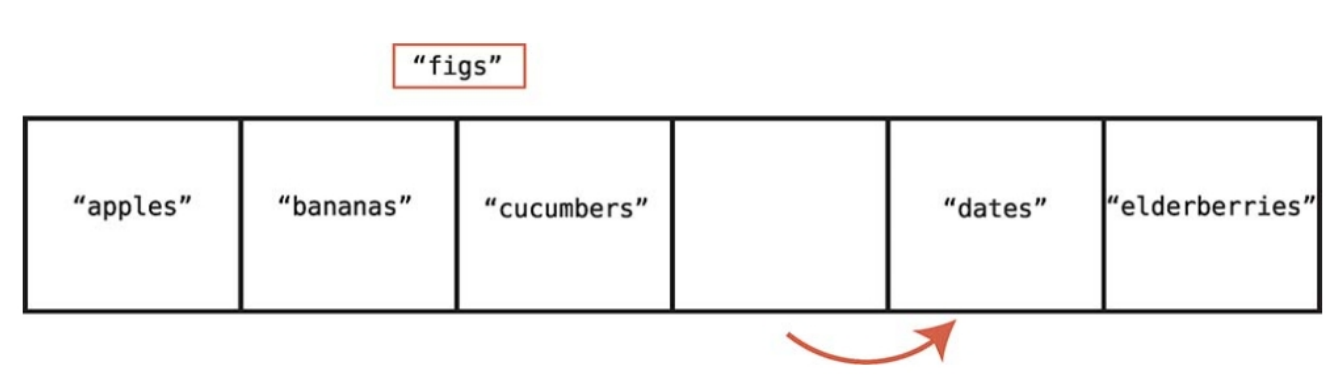
중간에 삽입
데이터를 중간에 삽입하면 삽입할 공간을 만들기 위해 많은 데이터 조각을 이동시켜야 하므로 단계가 늘어난다.
1단계2단계3단계4단계
"figs" 가 들어가려는 자리 뒤에 3개가 있었고, 마지막에 데이터를 삽입하는 단계 1을 합해서 4단계가 걸렸다(3+1)
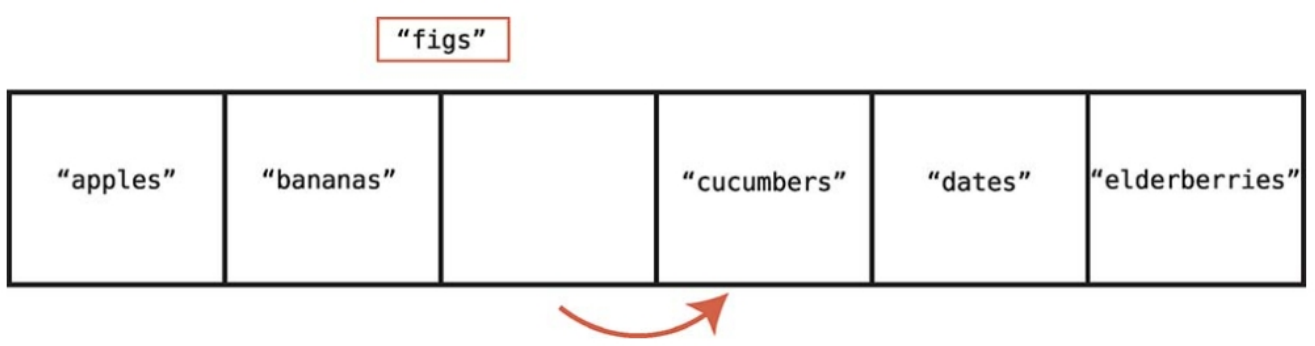
맨앞에 삽입
배열 삽입에서 최악의 시나리오, 즉 삽입에 가장 많은 단계가 걸리는 시나리오는 데이터를 배열의 맨 앞에 삽입할 때다.
배열의 앞에 삽입하면 배열 내 모든 값을 한 셀씩 오른쪽으로 옮겨야 하기 때문이다.
N개의 원소를 포함하는 배열에서 최악의 시나리오일 때 삽입에는 N+1단계가 걸린다.
N개의 모든 원소를 뒤로 밀어버린다.
데이터를 맨 앞에 삽입한다.
삭제
삭제는 특정 인덱스의 값을 제거하는 과정이다.
인덱스 2의 값을 삭제해보자.
원소 삭제에서 최악의 시나리오는 배열의 첫 번째 원소를 삭제하는 것이다.
원소 5개를 포함하는 배열이면 1단계는 첫 번째 원소 삭제에, 4단계는 남아 있는 원소 4개를 이동하는데 쓰인다.
따라서 원소 N개를 가지는 배열에서 삭제에 필요한 최대 단계 수는 N단계라고 할 수 있다.
집합 배열
집합은 중복 값을 허용하지 않는 자료구조다.
집합의 종류는 다양하지만 여기서는 배열 기반 집합을 다룬다.
일반 배열과 집합 배열의 차이점은 집합은 중복 값의 삽입을 절대 허용하지 않는다는 점이다.
예를 들어 ["a", "b", "c"]라는 집합에 b를 추가하려고 하면 b가 이미 있으므로 삽입을 허용하지 않는다.
집합 배열의 읽기 : 컴퓨터는 특정 인덱스에 들어 있는 값을 한 단계 만에 찾는다.
집합 배열의 검색 : 집합에서 어떤 값을 찾는 데 최대 N단계가 걸린다.
집합 배열의 삭제 : 집합에서 어떤 값을 삭제하고 배열을 옮겨 빈공간을 메꾸는 데 최대 N단계가 걸린다.
이렇게 집합과 집합 배열은 읽기, 검색, 삭제는 모두 동일한 단계 수를 가진다.
하지만 삽입만큼은 배열과 배열 집합은 다르다.
배열에서 최선의 시나리오였던 맨 끝에 삽입하는 경우 한 단계만에 값을 끝에 삽입했다.
하지만 집합 배열에서는 먼저 이 값이 이미 집합에 들어 있는지 결정해야 한다.
중복 데이터를 막는 게 집합의 역할이기 때문이다.
중복 데이터 삽입을 막기위해 삽입하려는 값이 집합에 이미 있는지부터 먼저 검색해야 한다.
집합에 새 값이 없을 때에만 컴퓨터는 삽입을 허용한다.
따라서 모든 삽입에는 검색이 우선이다.
모든 원소를 검색해야하므로 N단계가 소요되고, 삽입까지 총 N+1 단계가 소요된다.
값을 집합의 맨 앞에 삽입하는 최악의 시나리오일 때 컴퓨터는 셀 N개를 검색해서 집합이 그 값을 포함하지 않음을 확인한 후, 또 다른 N단계로 모든 데이터를 오른쪽으로 옮겨야 하며, 마지막 단계에서 새 값을 삽입해야한다.















댓글