집계 함수
여러 행에 대해 하나의 결과를 출력하는 그룹 함수를 이용하여 여러가지 집계 연산을 수행
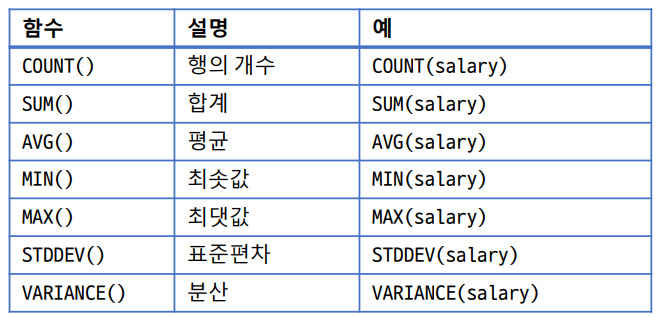
COUNT()
열의 행 개수를 구하는 함수
--salary 컬럼의 행의 개수를 모두 추출(null이 아닌거)
SELECT COUNT(salary) FROM employees;
--manager_id 컬럼의 행의 개수를 모두 추출(null이 아닌거)
SELECT COUNT(manager_id) FROM employees;
--commission_pct 행의 값의 개수를 모두 추출(null이 아닌거)
SELECT COUNT(commission_pct) FROM employees;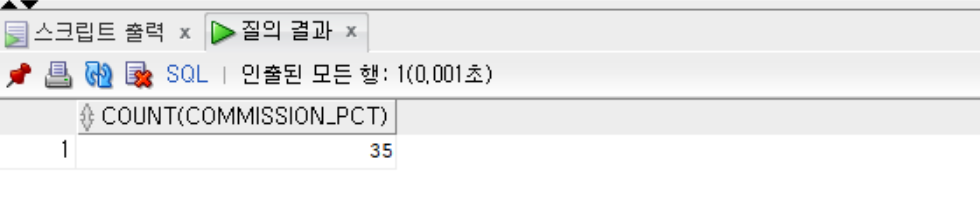
--모든 행의 개수를 추출
SELECT COUNT(*) FROM employees;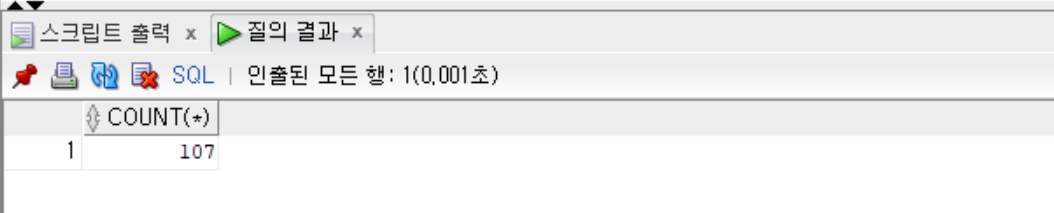
SUM() / AVG()
열의 합계를 구하는 SUM() 함수, 열의 평균을 구하는 AVG() 함수
--salary의 합계, 평균
SELECT SUM(salary), AVG(salary) FROM employees;
--salary의 평균
SELECT SUM(salary) / COUNT(salary) FROM employees;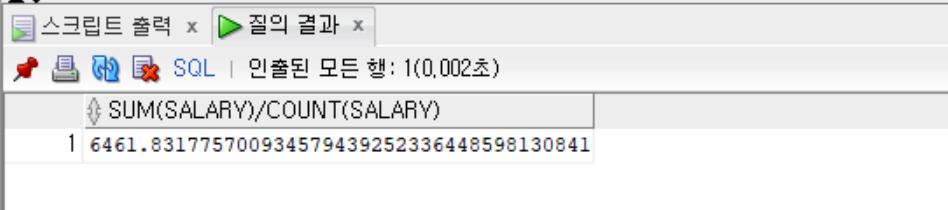
-- salary 값을 first_name의 순서대로 더하는 것으로, 각 행에서 이전 행까지의 모든 값을 누적하여 합산
SELECT first_name, salary,
SUM(salary) OVER (ORDER BY first_name)
FROM employees;
MIN() / MAX()
열의 최솟값을 구하는 MIN() 함수, 열의 최댓값을 구하는 MAX() 함수
--first_name과 salary를 그룹으로 묶고, 그룹별로 first_name과 salary를 first_name순으로 정렬하여 출력
SELECT first_name, salary FROM employees
GROUP BY first_name, salary ORDER BY first_name;
--salary의 최솟값과 최댓값을 출력
SELECT MIN(salary), MAX(salary) FROM employees;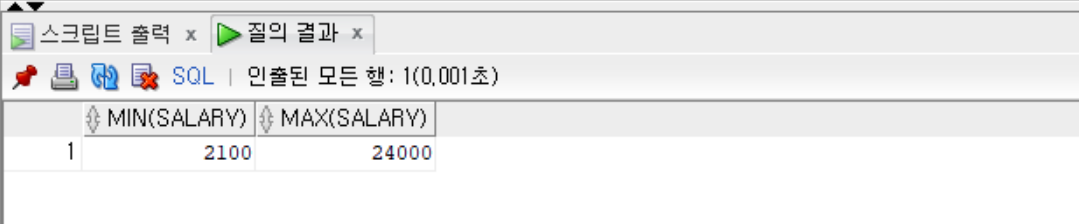
--first_name의 최솟값과 최댓값을 출력(이름순의 최솟값과 최댓값)
SELECT MIN(first_name), MAX(first_name) FROM employees;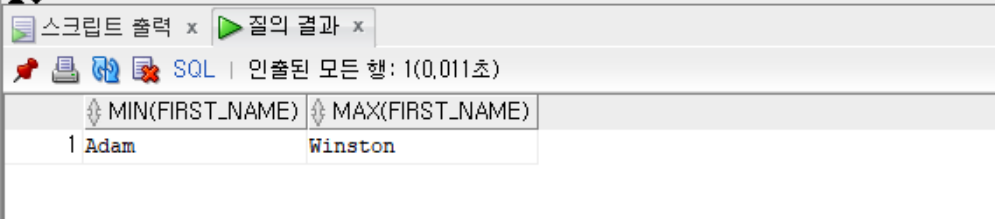
STDDEV() / VARIANCE()
표준편차를 구하는 STDDEV() 함수, 분산을 구하는 VARIANCE() 함수
--salary의 표준편차, 분산을 출력
SELECT STDDEV(salary), VARIANCE(salary) FROM employees;
--department_id가 50이고, first_name, salary, salary의 분산을 first_name순으로 정렬하여 출력
SELECT first_name, salary,
STDDEV(salary) OVER (ORDER BY first_name)
FROM employees
WHERE department_id = 50;
GROUP BY
지정한 열의 데이터 값을 기준으로 그룹화하여 집계 함수 적용
GROUP BY 동작 순서
- 테이블에서 WHERE 조건식에 맞는 데이터 값만 구분
- 지정한 열 기준으로 같은 데이터 값으로 그룹화
- 지정한 열들의 그룹화된 집계 결과 출력
GROUP BY 절 특징
- WHERE 절은 그룹화 되기 전에 조건식 적용
- GROUP BY 절 사용시 SELECT 절에 지정된 기준 열을 지정
- SELECT 절에 그룹 함수 없이도 GROUP BY 절 사용 가능
--job_id로 그룹을 묶고, 그룹별로 job_id와 salary의 합계와 평균을 출력
SELECT job_id, SUM(salary), AVG(salary)
FROM employees
GROUP BY job_id;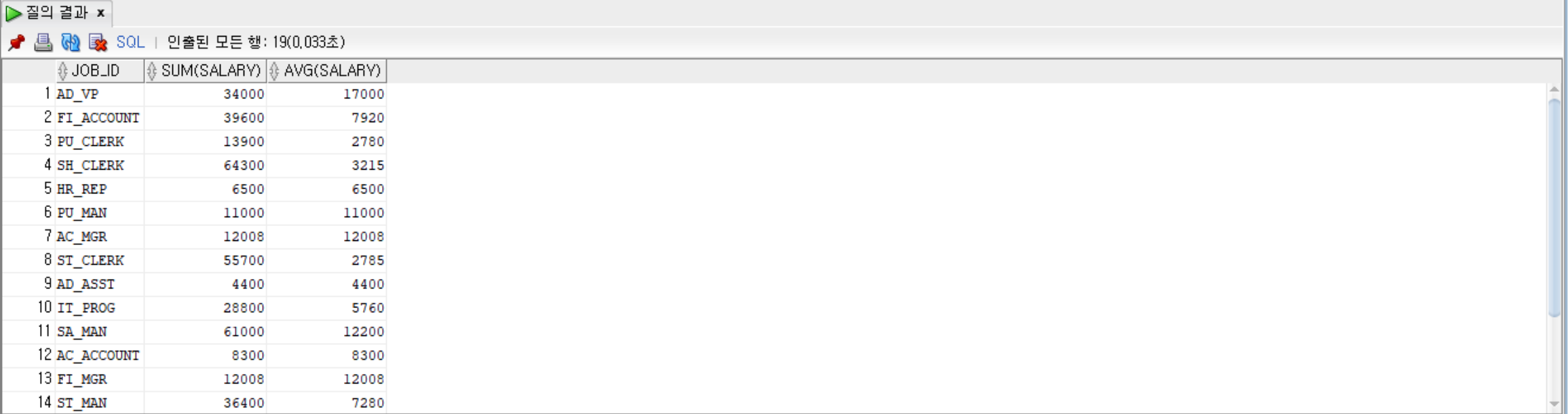
--job_id로 그룹을 묶고,department_id가 50인 것만 ,그룹별로 job_id와 salary의 합계와 평균을 출력
SELECT job_id, SUM(salary), AVG(salary)
FROM employees
WHERE department_id = 50
GROUP BY job_id;
--department_id로 묶고, 그룹별로 department_id, salary의 최솟값과, 최댓값 출력
SELECT department_id, MIN(salary), MAX(salary)
FROM employees
GROUP BY department_id;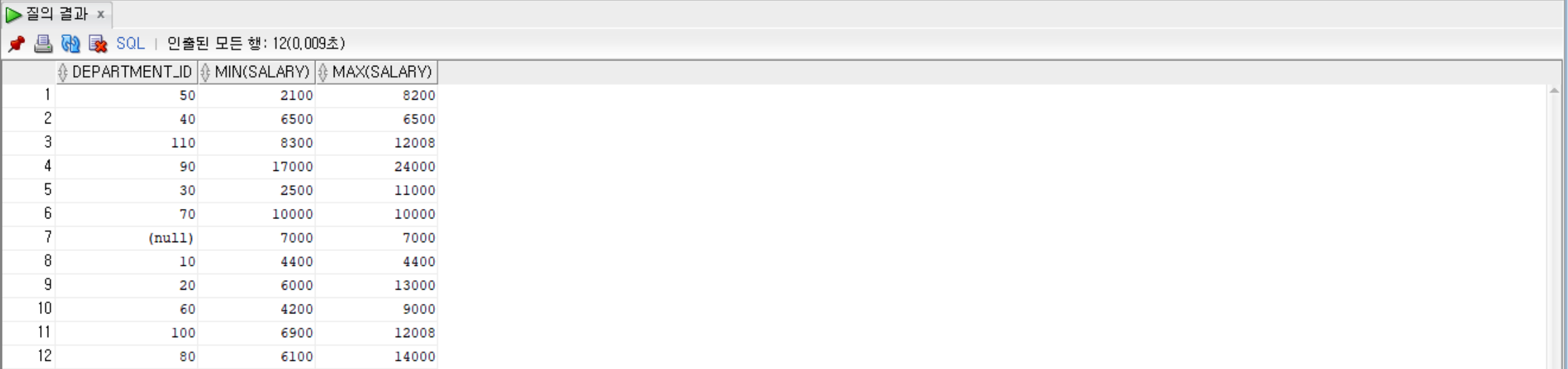
--department_id로 묶고, hire_date가 2007년 01월 01일 이후인 사람만, 그룹별로 department_id, salary의 최솟값과, 최댓값 출력
SELECT department_id, MIN(salary), MAX(salary)
FROM employees
WHERE hire_date > '20070101'
GROUP BY department_id;
--country_id로 묶고, country_id순으로 정렬하고, 그룹별로 country_id와 country_id컬럼의 열의 개수를 출력
SELECT country_id, COUNT(country_id)
FROM locations
GROUP BY country_id
ORDER BY country_id;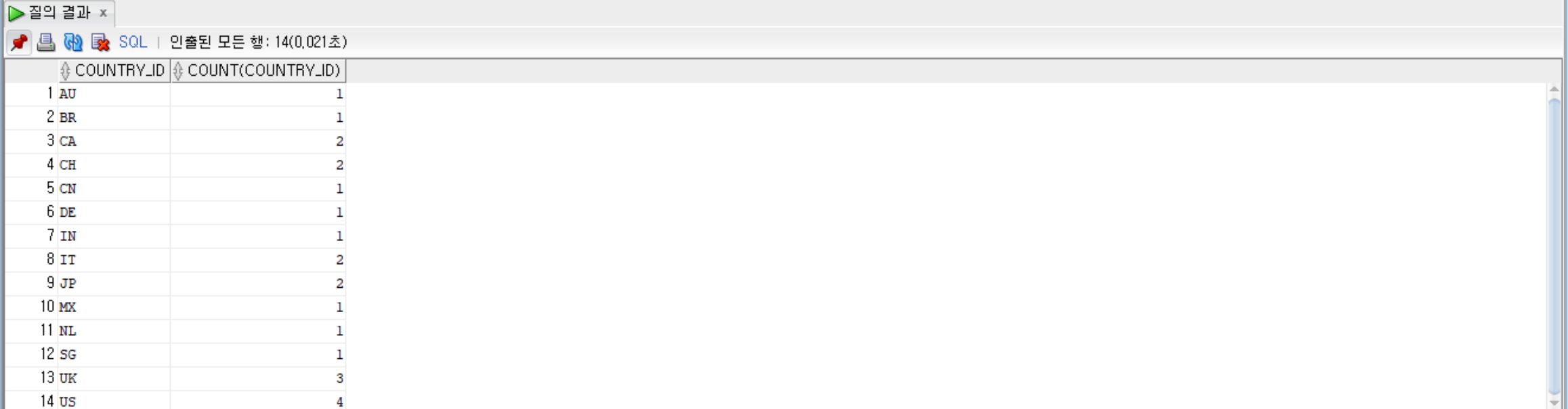
다중 GROUP BY 절
--job_id, department_id로 묶고, department_id가 50~100 사이만, job_id를 기준으로 정렬하고, 그룹별로 job_id, department_id, salary의 합계, 평균 출력
SELECT job_id, department_id, SUM(salary), AVG(salary)
FROM employees
WHERE department_id BETWEEN 50 AND 100
GROUP BY job_id, department_id
ORDER BY job_id;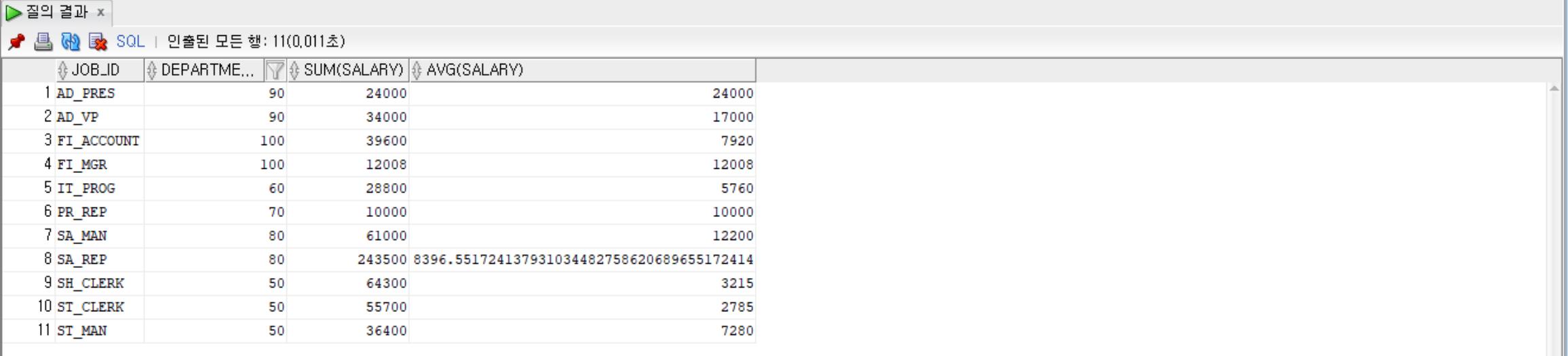
SELECT department_id, manager_id, SUM(salary), AVG(salary)
FROM employees
WHERE department_id = 50
GROUP BY department_id, manager_id
ORDER BY manager_id;
--manager_id, department_id, job_id로 묶고, manager_id가 100또는 101인 것만, manager_id와 department_id 기준으로 정렬하고
--그룹별로 manager_id, department_id, job_id, salary의 합계, 최솟값, 최댓값 출력
SELECT manager_id, department_id, job_id, SUM(salary), MIN(salary), MAX(salary)
FROM employees
WHERE manager_id IN (100, 101)
GROUP BY manager_id, department_id, job_id
ORDER BY manager_id, department_id;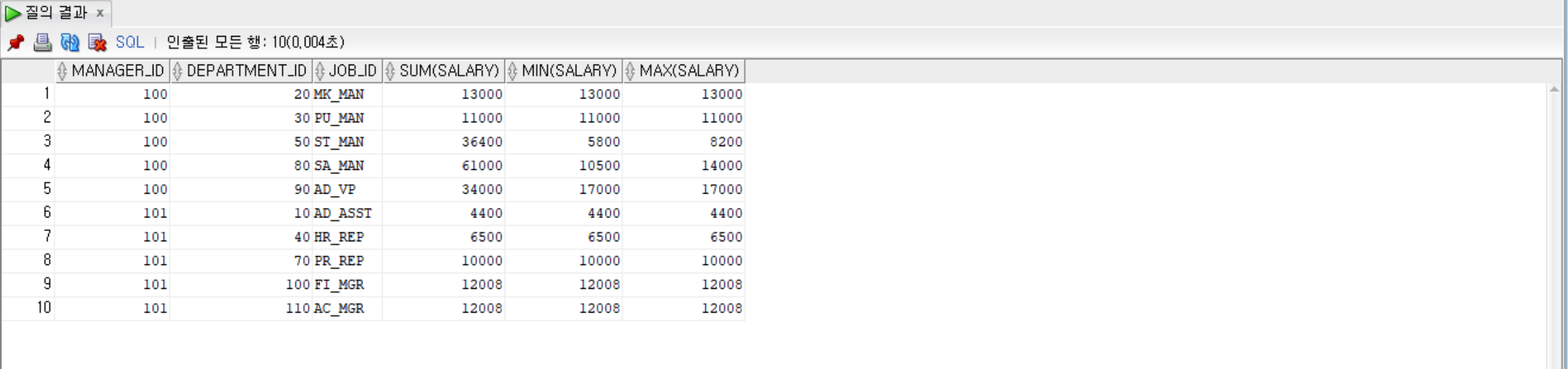
HAVING 절
WHERE 절에서는 그룹 함수를 사용할 수 없음
그룹화된 집계 결과에 조건식을 적용할 때 HAVING 절 사용
--job_id로 묶고, salary의 평균이 10000초과인 것만, 그룹별로 job_id, salary 합계, 평균 출력
SELECT job_id, SUM(salary), AVG(salary)
FROM employees
GROUP BY job_id
HAVING AVG(salary) > 10000;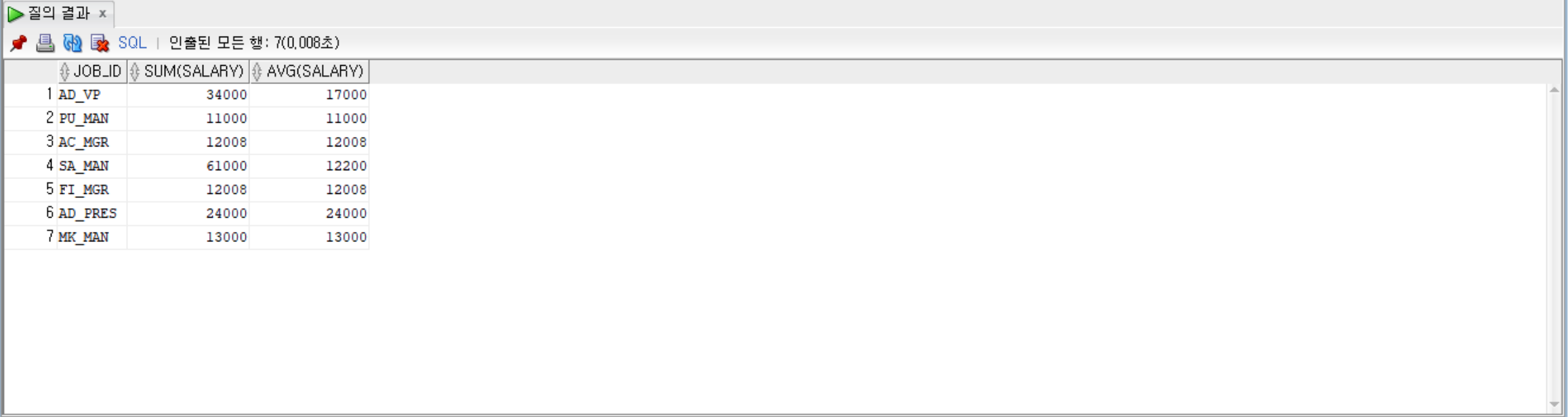
--department_id로 묶고, salary의 최댓값이 7000초과인 것만, 그룹별로 department_id, salary의 최솟값, 최댓값 출력
SELECT department_id, MIN(salary), MAX(salary)
FROM employees
GROUP BY department_id
HAVING MAX(salary) > 7000;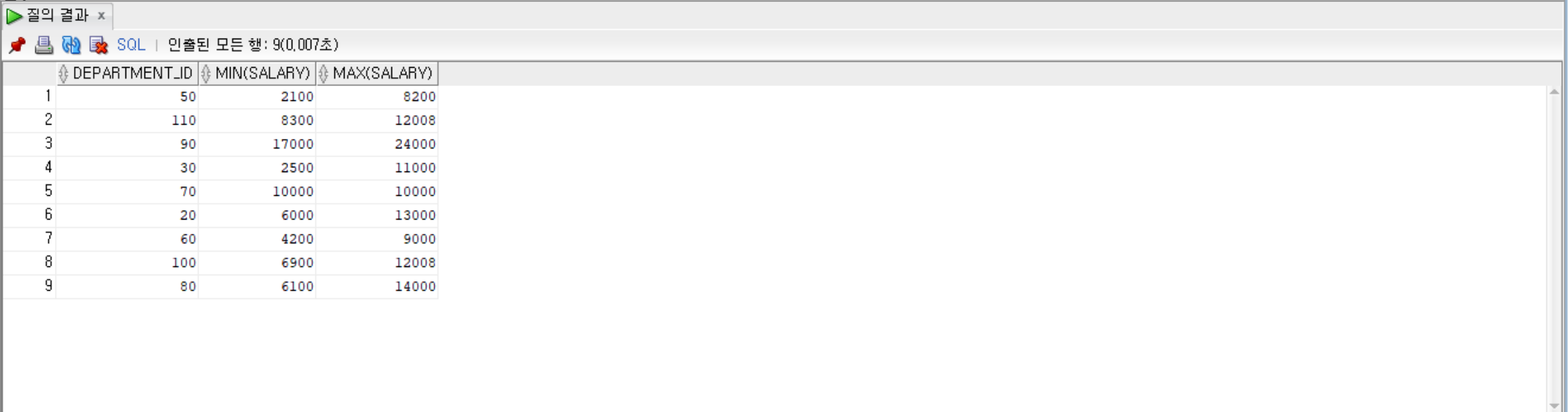
--country_id로 묶고, country_id의 개수가 2초과인 것만, country_id기준으로 정렬하고,
--그룹별로country_id, country_id의 개수 출력
SELECT country_id, COUNT(country_id)
FROM locations
GROUP BY country_id
HAVING COUNT(country_id) > 2
ORDER BY country_id;
--job_id, department_id로 묶고, department_id가 50~100사이 것만, salary평균이 9000이상인 것만
--job_id를 기준으로 정렬해서 그룹별로 job_id, department_id, salary의 합계, 평균 출력
SELECT job_id, department_id, SUM(salary), AVG(salary)
FROM employees
WHERE department_id BETWEEN 50 AND 100
GROUP BY job_id, department_id
HAVING AVG(salary) > 9000
ORDER BY job_id;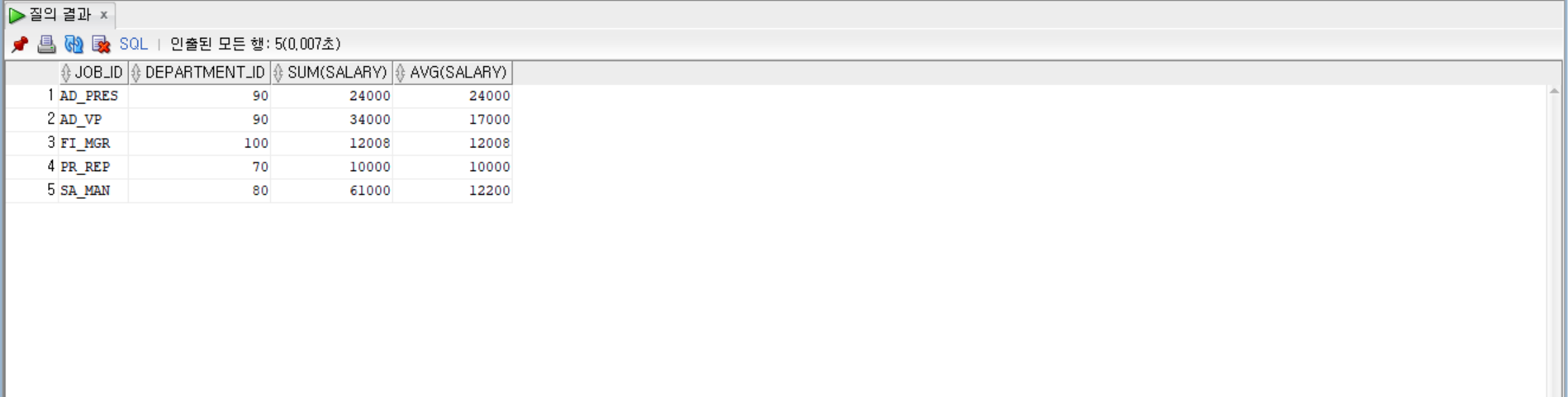
--manager_id, department_id, job_id로 묶고, manager_id가 100 또는 101인 것만
--salary가 10000과 40000 사이의 것만, manager_id, department_id 기준으로 정렬
--그룹별로 manager_id, department_id, job_id, salary의 합계, 최솟값, 최댓값을 출력
SELECT manager_id, department_id, job_id, SUM(salary), MIN(salary), MAX(salary)
FROM employees
WHERE manager_id IN (100, 101)
GROUP BY manager_id, department_id, job_id
HAVING SUM(salary) BETWEEN 10000 AND 40000
ORDER BY manager_id, department_id;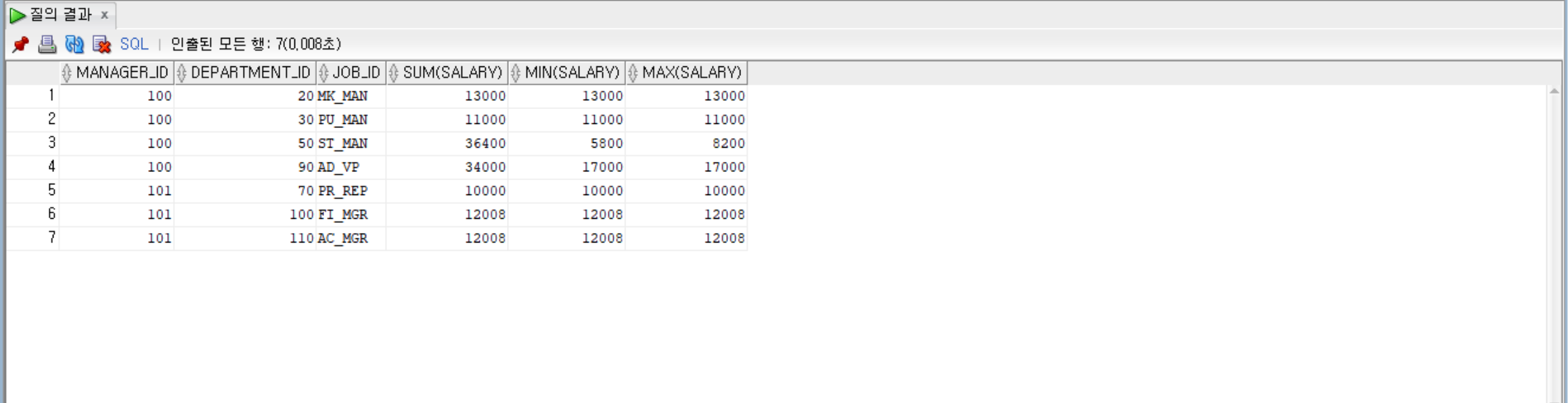
연습 문제
--employees 테이블에서 salary가 8000이상인 직원의 수를 조회
SELECT COUNT(salary) FROM employees WHERE salary > 8000;
--employees 테이블에서 hire_date가 2007년 1월 1일 이후인 직원의 수를 조회
SELECT COUNT(hire_date) FROM employees WHERE hire_Date > '20070101';
--jobs 테이블에서 max_salary 값의 합계와 평균을 조회
SELECT MAX(max_salary), AVG(max_salary) FROM jobs;
--employees 테이블에서 job_id가 ‘IT_PROG’인 직원의 salary 합계와 평균을 조회
SELECT SUM(salary), AVG(salary)
FROM employees
WHERE job_id = 'IT_PROG';
--employees 테이블에서 department_id가 50과 80 사이인 직원의 first_name, salary,
--그리고 commission_pct의 평균값을 first_name 정렬 기준으로 조회 (null 값은 0으로 출력)
SELECT first_name, salary, AVG(NVL(commission_pct, 0)) OVER (ORDER BY first_name)
FROM employees
WHERE department_id BETWEEN 50 AND 100;
--jobs 테이블에서 max_salary 값의 최솟값과 max_salary 값의 최댓값을 조회
SELECT min(max_salary), MAX(max_salary) FROM jobs;
--jobs 테이블에서 job_title이 ‘Programmer’인 직업의 max_salary 값의 최솟값과 max_salary 값의 최댓값을 조회
SELECT MIN(max_salary), MAX(max_salary)
FROM jobs
WHERE job_title = 'Programmer';
--employees 테이블에서 department_id가 50인 데이터의 hire_date 최소값과 최댓값 조회
SELECT MIN(hire_date), MAX(hire_date)
FROM employees
WHERE department_id = 50;
--employees 테이블에서 department_id가 100인 데이터의 first_name, salary,
--그리고 salary의 분산값을 hire_date 정렬 기준으로 조회
SELECT first_name, salary, VARIANCE(salary) OVER (ORDER BY hire_date)
FROM employees
WHERE department_id = 100;
--employees 테이블에서 hire_date 값이
--2004년 1월 1일부터 2006년 12월 31일 사이의 데이터를 job_id 기준으로
--그룹화한 뒤에 job_id와 salary 최솟값과 최대값을 조회
SELECT job_id, MIN(salary), MAX(salary)
FROM employees
WHERE hire_date BETWEEN '20040101' AND '20061231'
GROUP BY job_id;
--employees 테이블에서 department_id 가 50과 80인 데이터를
--department_id와 job_id 기준으로 그룹화한 뒤에 department_id와
--job_id, salary 합계, 최솟값, 최대값을 job_id 기준으로 정렬하여 조회
SELECT department_id, job_id, SUM(salary), MIN(salary), MAX(salary)
FROM employees
WHERE department_id IN (50, 80)
GROUP BY department_id, job_id
ORDER BY job_id;
--employees 테이블에서 department_id와 job_id 기준으로 그룹화한
--뒤에 salary 평균값이 12000 이상인 데이터만 department_id와
--job_id, salary 최솟값, 최대값, 평균을 department_id 기준으로 정렬하여 조회
SELECT department_id, job_id, MIN(salary), MAX(salary), AVG(salary)
FROM employees
GROUP BY department_id, job_id
HAVING AVG(salary) > 12000
ORDER BY department_id;

댓글