이 게시글은 이것이 자바다(저자 : 신용권, 임경균)의 책과 동영상 강의를 참고하여 개인적으로 정리하는 글임을 알립니다.
요소 정렬
정렬은 요소를 오름차순 또는 내림차순으로 정렬하는 중간 처리 기능이다.
요소를 정렬하는 메소드는 아래와 같다.
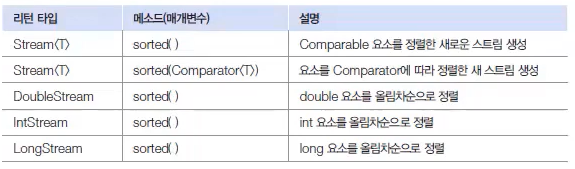
Comparable 구현 객체의 정렬
스트림의 요소가 객체일 경우 객체가 Comparable을 구현하고 있어야만 sorted() 메소드를 사용하여 정렬할 수 있다.
만약 내림차순으로 정렬하고 싶다면 Comparator.reverseOrder() 메소드가 리턴하는 Comparator를 매개값으로 제공하면 된다.
아래의 더보기를 누르면 예제 코드를 볼 수 있다.
Student.java
public class Student implements Comparable<Student> { //Comparable 구현 클래스
private String name;
private int score;
public Student(String name, int score) {
this.name = name;
this.score = score;
}
public String getName() { return name; }
public int getScore() { return score; }
@Override
public int compareTo(Student o) { //Comparable 인터페이스 메소드 구현
return Integer.compare(score, o.score);
}
}
SortingExample.java
import java.util.ArrayList;
import java.util.Comparator;
import java.util.List;
public class SortingExample {
public static void main(String[] args) {
//List 컬렉션 생성
List<Student> studentList = new ArrayList<>();
studentList.add(new Student("홍길동", 30));
studentList.add(new Student("신용권", 10));
studentList.add(new Student("유미선", 20));
//점수를 기준으로 오름차순으로 정렬한 새 스트림 얻기
studentList.stream()
.sorted( )
.forEach(s -> System.out.println(s.getName() + ": " + s.getScore()));
System.out.println();
//점수를 기준으로 내림차순으로 정렬한 새 스트림 얻기
studentList.stream()
.sorted(Comparator.reverseOrder())
.forEach(s -> System.out.println(s.getName() + ": " + s.getScore()));
}
}
/*
신용권: 10
유미선: 20
홍길동: 30
홍길동: 30
유미선: 20
신용권: 10
*/
Comparator를 이용한 정렬
요소 객체가 Comparable을 구현하고 있지 않다면, 비교자를 제공하면 요소를 정렬시킬 수 있다.
비교자는 Comparator 인터페이스를 구현한 객체를 말하는데, 명시적인 클래스로 구현할 수도 있지만 간단하게 람다식으로 작성할 수도 있다.
sorted((o1, o2) -> { ... })중괄호 안에는 o1이 o2보다 작으면 음수, 같으면 0, 크면 양수를 리턴하도록 작성하면 된다.
아래의 더보기를 누르면 예제 코드를 볼 수 있다.
Student.java
public class Student {
private String name;
private int score;
public Student(String name, int score) {
this.name = name;
this.score = score;
}
public String getName() { return name; }
public int getScore() { return score; }
}
SortingExample.java
import java.util.ArrayList;
import java.util.List;
public class SortingExample {
public static void main(String[] args) {
//List 컬렉션 생성
List<Student> studentList = new ArrayList<>();
studentList.add(new Student("홍길동", 30));
studentList.add(new Student("신용권", 10));
studentList.add(new Student("유미선", 20));
//점수를 기준으로 오름차순으로 정렬한 새 스트림 얻기
studentList.stream()
.sorted((s1, s2) -> Integer.compare(s1.getScore(), s2.getScore()))
.forEach(s -> System.out.println(s.getName() + ": " + s.getScore()));
System.out.println();
//점수를 기준으로 내림차순으로 정렬한 새 스트림 얻기
//매개값을 반대로 주면 내림차순 정렬
studentList.stream()
.sorted((s1, s2) -> Integer.compare(s2.getScore(), s1.getScore()))
.forEach(s -> System.out.println(s.getName() + ": " + s.getScore()));
}
}
/*
신용권: 10
유미선: 20
홍길동: 30
홍길동: 30
유미선: 20
신용권: 10
*/
요소를 하나씩 처리(루핑)
루핑은 스트림에서 요소를 하나씩 반복해서 가져와 처리하는 것을 말한다.
루핑 메소드에는 peek()와 forEach()가 있다.

peek()와 forEach()는 동일하게 요소를 루핑 하지만 peek()은 중간 처리 메소드이고, forEach()는 최종 처리 메소드이다.
따라서 peek()은 최종 처리가 뒤에 붙지 않으면 동작하지 않는다.
매개타입 Consumer는 함수형 인터페이스로, 아래와 같은 종류가 있다.

모든 Consumer는 매개값을 처리(소비)하는 accept() 메소드를 가지고 있다.
Consumer<? super T>를 람다식으로 표현하면 아래와 같다.
T -> {...}
또는
T -> 실행문;
아래의 더보기를 누르면 예제 코드를 볼 수 있다.
LoopingExample.java
import java.util.Arrays;
public class LoopingExample {
public static void main(String[] args) {
int[] intArr = { 1, 2, 3, 4, 5 };
//잘못 작성한 경우
Arrays.stream(intArr)
.filter(a -> a%2==0)
.peek(n -> System.out.println(n)); //최종 처리가 없으므로 동작하지 않음
//중간 처리 메소드 peek()을 이용해서 반복 처리
int total = Arrays.stream(intArr)
.filter(a -> a%2==0)
.peek(n -> System.out.println(n)) //동작함
.sum(); //최종 처리
System.out.println("총합: " + total + "\n");
//최종 처리 메소드 forEach()를 이용해서 반복 처리
Arrays.stream(intArr)
.filter(a -> a%2==0)
.forEach(n -> System.out.println(n)); //최종 처리이므로 동작함
}
}
/*
2
4
총합: 6
2
4
*/
요소 조건 만족 여부(매칭)
매칭은 요소들이 특정 조건에 만족하는지 여부를 조사하는 최종 처리 기능이다.
매칭과 관련된 메소드는 아래와 같다.
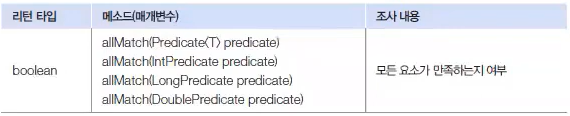
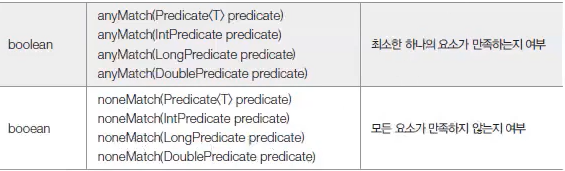
allMatch(), anyMatch(), noneMatch() 메소드는 매개값으로 주어진 Predicate가 리턴하는 값에 따라 true 또는 false 를 리턴한다.
아래의 더보기를 누르면 예제 코드를 볼 수 있다.
MatchingExample.java
import java.util.Arrays;
public class MatchingExample {
public static void main(String[] args) {
int[] intArr = { 2, 4 ,6 };
boolean result = Arrays.stream(intArr)
.allMatch(a -> a%2==0);
System.out.println("모두 2의 배수인가? " + result);
result = Arrays.stream(intArr)
.anyMatch(a -> a%3==0);
System.out.println("하나라도 3의 배수가 있는가? " + result);
result = Arrays.stream(intArr)
.noneMatch(a -> a%3==0);
System.out.println("3의 배수가 없는가? " + result);
}
}
/*
모두 2의 배수인가? true
하나라도 3의 배수가 있는가? true
3의 배수가 없는가? false
*/
요소 기본 집계
집계는 최종 처리 기능으로 요소들을 처리해서 카운팅, 합계, 평균값, 최대값, 최소값등과 같이 하나의 값으로 산출하는 것을 말한다.
즉, 대량의 데이터를 가공해서 하나의 값으로 축소하는 리덕션(Reduction)이라고 볼 수 있다.
스트림이 제공하는 기본 집계
스트림은 카운팅, 최대, 최소, 평균, 합계 등을 처리하는 아래와 같은 최종 처리 메소드를 제공한다.

집계 메소드가 리턴하는 OptionalXXX는 Optional, OptionalDouble, OptionalInt, OptionalLong 클래스를 말한다.
이들은 최종값을 저장하는 객체로 get(), getAsDouble(), getAsIntI(), getAsLong()을 호출하면 최종값을 얻을 수 있다.
아래의 더보기를 누르면 예제 코드를 볼 수 있다.
AggregateExample.java
import java.util.Arrays;
public class AggregateExample {
public static void main(String[] args) {
//정수 배열
int[] arr = {1, 2, 3, 4, 5};
//카운팅
long count = Arrays.stream(arr)
.filter(n -> n%2==0)
.count();
System.out.println("2의 배수 개수: " + count);
//총합
long sum = Arrays.stream(arr)
.filter(n -> n%2==0)
.sum();
System.out.println("2의 배수의 합: " + sum);
//평균
double avg = Arrays.stream(arr)
.filter(n -> n%2==0)
.average()
.getAsDouble();
System.out.println("2의 배수의 평균: " + avg);
//최대값
int max = Arrays.stream(arr)
.filter(n -> n%2==0)
.max()
.getAsInt();
System.out.println("최대값: " + max);
//최소값
int min = Arrays.stream(arr)
.filter(n -> n%2==0)
.min()
.getAsInt();
System.out.println("최소값: " + min);
//첫 번째 요소
int first = Arrays.stream(arr)
.filter(n -> n%3==0)
.findFirst()
.getAsInt();
System.out.println("첫 번째 3의 배수: " + first);
}
}
/*
2의 배수 개수: 2
2의 배수의 합: 6
2의 배수의 평균: 3.0
최대값: 4
최소값: 2
첫 번째 3의 배수: 3
*/
Optional 클래스
Optional, OptionalDouble, OptionalInt, OptionalLong 클래스는 단순히 집계값만 저장하는 것이 아니다.
집계값이 존재하지 않을 경우 디폴트 값을 설정하거나 집계값을 처리하는 Consumer를 등록할 수 있다.
아래는 Optional 클래스가 제공하는 메소드이다.

컬렉션의 요소는 동적으로 추가되는 경우가 많다.
만약 컬렉션에서 요소가 존재하지 않으면 집계 값을 산출할 수 없으므로 예외가 발생한다.
하지만 위 표에 있는 메소드를 이용하면 예외 발생을 막을 수 있다.
예를 들어 평균을 구하는 average를 최종 처리에서 사용할 경우, 아래와 같이 3가지 방법으로 요소(집계값)가 없는 경우를 대비할 수 있다.
1. isPresent() 메소드가 true를 리턴할 때만 집계값을 얻는다.
OptionalDouble optional = list.stream()
.mapToInt(Integer :: intValue)
.average();
if(optional.isPresent()) {
System.out.println("방법1_평균: " + optional.getAsDouble());
} else {
System.out.println("방법1_평균: 0.0");
}
2. orElse() 메소드로 집계값이 없을 경우를 대비해서 디폴트 값을 정해놓는다.
double avg = list.stream()
.mapToInt(Integer :: intValue)
.average()
.orElse(0.0);
System.out.println("방법2_평균: " + avg);
3. ifPresent() 메소드로 집계값이 있을 경우에만 동작하는 Consumer 람다식을 제공한다.
stream
.average()
.ifPresent(a -> System.out.println("방법3_평균: " + a));
//집계값이 없다면 average() 메소드를 실행하지 않음
아래의 더보기를 누르면 예제 코드를 볼 수 있다.
OptionalExample.java
import java.util.ArrayList;
import java.util.List;
import java.util.OptionalDouble;
public class OptionalExample {
public static void main(String[] args) {
List<Integer> list = new ArrayList< >();
/*//예외 발생(java.util.NoSuchElementException)
double avg = list.stream()
.mapToInt(Integer :: intValue)
.average()
.getAsDouble();
*/
//방법1
OptionalDouble optional = list.stream()
.mapToInt(Integer :: intValue)
.average();
if(optional.isPresent()) {
System.out.println("방법1_평균: " + optional.getAsDouble());
} else {
System.out.println("방법1_평균: 0.0");
}
//방법2
double avg = list.stream()
.mapToInt(Integer :: intValue)
.average()
.orElse(0.0);
System.out.println("방법2_평균: " + avg);
//방법3
list.stream()
.mapToInt(Integer :: intValue)
.average()
.ifPresent(a -> System.out.println("방법3_평균: " + a));
}
}
/*
방법1_평균: 0.0
방법2_평균: 0.0
*/
요소 커스텀 집계
스트림은 기본 집계 메소드 외에 다양한 집계 결과물을 만들 수 있도록 reduce() 메소드도 제공한다.

매개값은 BinaryOperator는 함수형 인터페이스이다.
BinaryOperator는 두 개의 매개값을 받아 하나의 값을 리턴하는 apply() 메소드를 가지고 있기 때문에 람다식을 작성할 수 있다.
스트림 요소 중 두 개를 받아서 모든 객체를 차례대로 처리한다.
reduce() 는 스트림에 요소가 없을 경우 예외가 발생하지만, identity 매개값이 주어지면 이 값을 디폴트 값으로 리턴한다.
identity 매개값을 넣어주면 해당 타입을 리턴하기 때문에, get() 관련 메소드를 따로 호출할 필요가 없다.
아래의 더보기를 누르면 예제 코드를 볼 수 있다.
Student.java
public class Student {
private String name;
private int score;
public Student(String name, int score) {
this.name = name;
this.score = score;
}
public String getName() { return name; }
public int getScore() { return score; }
}
ReductionExample.java
import java.util.Arrays;
import java.util.List;
public class ReductionExample {
public static void main(String[] args) {
List<Student> studentList = Arrays.asList(
new Student("홍길동", 92),
new Student("신용권", 95),
new Student("감자바", 88)
);
//방법1
int sum1 = studentList.stream()
.mapToInt(Student :: getScore)
.sum();
//방법2
int sum2 = studentList.stream()
.map(Student :: getScore)
.reduce(0, (a, b) -> a+b);
System.out.println("sum1: " + sum1);
System.out.println("sum2: " + sum2);
}
}
/*
sum1: 275
sum2: 275
*/
요소 수집
스트림은 요소들을 필터링 또는 매핑한 후 요소들을 수집하는 최종 처리 메소드인 collect()를 제공한다.
이 메소드를 이용하면 필요한 요소만 컬렉션에 담을 수 있고, 요소들을 그룹핑한 후에 집계도 할 수 있다.
필터링한 요소 수집
Stream의 collect(Collector<T, A, R> collector) 메소드는 필터링 또는 매핑된 요소들을 새로운 컬렉션에 수집하고, 이 컬렉션을 리턴한다.
매개값인 Collector는 어떤 요소를 어떤 컬렉션에 수집할 것인지를 결정한다.
| 리턴 타입 | 메소드(매개변수) | 인터페이스 |
| R | collect(Collector<T, A, R> collector) | Stream |
타입 파라미터
- T : 요소
- A : accumulator (누적기)
- R : 요소가 저장될 컬렉션
풀어서 해석하면 T 요소를 A 누적기가 R에 저장한다는 의미이다.
List, Set, Map 등이 R에 들어가면 별도의 A를 제공할 필요가 없다.
Collector의 구현 객체는 아래와 같이 Collectors 클래스의 정적 메소드로 얻을 수 있다.

아래는 Student 스트림에서 남학생만 필터링해서 별도의 List로 생성하는 코드이다.
List<Student> maleList = totalList.stream()
.filter(s->s.getSex().equals("남"))
.toList();
아래는 Student 스트림에서 이름을 키로, 점수를 값으로 갖는 Map 컬렉션을 생성하는 코드이다.
Map<String, Integer> map = totalList.stream()
.collect(
Collectors.toMap(
s -> s.getName(), //Student 객체에서 키가 될 부분 리턴
s -> s.getScore() //Student 객체에서 값이 될 부분 리턴
)
);
Java 16부터는 좀 더 편리하게 요소 스트림에서 List 컬렉션을 얻을 수 있다.
스트림에서 바로 toList() 메소드를 아래와 같이 사용하면 된다.
List<Student> maleList = totalList.stream()
.filter(s->s.getSex().equals("남"))
.toList();
아래의 더보기를 누르면 예제 코드를 볼 수 있다.
Student.java
public class Student {
private String name;
private String sex;
private int score;
public Student(String name, String sex, int score) {
this.name = name;
this.sex = sex;
this.score = score;
}
public String getName() { return name; }
public String getSex() { return sex; }
public int getScore() { return score; }
}
CollectExample.java
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
import java.util.stream.Collectors;
public class CollectExample {
public static void main(String[] args) {
List<Student> totalList = new ArrayList< >();
totalList.add(new Student("홍길동", "남", 92));
totalList.add(new Student("김수영", "여", 87));
totalList.add(new Student("감자바", "남", 95));
totalList.add(new Student("오해영", "여", 93));
//남학생만 묶어 List 생성
/*List<Student> maleList = totalList.stream()
.filter(s->s.getSex().equals("남"))
.collect(Collectors.toList());*/
List<Student> maleList = totalList.stream()
.filter(s->s.getSex().equals("남"))
.toList();
maleList.stream()
.forEach(s -> System.out.println(s.getName()));
System.out.println();
//학생 이름을 키, 학생의 점수를 값으로 갖는 Map 생성
Map<String, Integer> map = totalList.stream()
.collect(
Collectors.toMap(
s -> s.getName(), //Student 객체에서 키가 될 부분 리턴
s -> s.getScore() //Student 객체에서 값이 될 부분 리턴
)
);
System.out.println(map);
}
}
/*
홍길동
감자바
{오해영=93, 홍길동=92, 감자바=95, 김수영=87}
*/
요소 그룹핑
Collect() 메소드는 단순히 요소를 수집하는 기능 이외에 컬렉션의 요소들을 그룹핑해서 Map 객체를 생성하는 기능도 제공한다.
Collectors.groupingBy() 메소드에서 얻은 Collector를 collect() 메소드를 호출할 때 제공하면 된다.
| 리턴 타입 | 메소드 |
| Collector<T, ?, Map<K, List<T>>> | groupingBy(Function<T, K> classifier) |
groupingBy()는 Function을 이용해서 T, K로 매핑하고, K를 키로해서 List<T>를 값으로 갖는 Map 컬렉션을 생성한다.
아래는 남과 여를 키로 설정하고 List<Student>를 값으로 갖는 Map을 생성하는 코드이다.
Map<String, List<Student>> map = totalList.stream()
.collect(
Collectors.groupingBy( s -> s.getSex() ) //그룹핑 키 리턴
);
아래의 더보기를 누르면 예제 코드를 볼 수 있다.
Student.java
public class Student {
private String name;
private String sex;
private int score;
public Student(String name, String sex, int score) {
this.name = name;
this.sex = sex;
this.score = score;
}
public String getName() { return name; }
public String getSex() { return sex; }
public int getScore() { return score; }
}
CollectExample.java
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
import java.util.stream.Collectors;
public class CollectExample {
public static void main(String[] args) {
List<Student> totalList = new ArrayList< >();
totalList.add(new Student("홍길동", "남", 92));
totalList.add(new Student("김수영", "여", 87));
totalList.add(new Student("감자바", "남", 95));
totalList.add(new Student("오해영", "여", 93));
Map<String, List<Student>> map = totalList.stream()
.collect(
Collectors.groupingBy(s -> s.getSex())
);
List<Student> maleList = map.get("남");
maleList.stream().forEach(s -> System.out.println(s.getName()));
System.out.println();
List<Student> femaleList = map.get("여");
femaleList.stream().forEach(s -> System.out.println(s.getName()));
}
}
/*
홍길동
감자바
김수영
오해영
*/
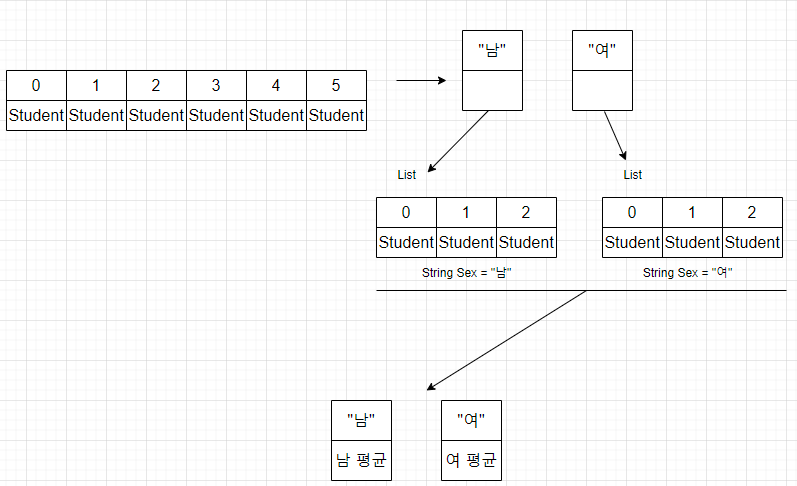
Collectors.groupingBy() 메소드는 그룹핑 후 매핑 및 집계 (평균, 카운팅, 연결, 최대, 최소, 합계)를 수행할 수 있도록 두 번째 매개값인 Collector를 가질 수 있다.
아래는 두 번째 매개값으로 사용될 Collector를 얻을 수 있는 Collectors의 정적 메소드이다.

아래는 학생들을 성별로 그룹핑하고 각각의 평균 점수를 구해서 Map으로 얻는 코드이다.
Map<String, Double> map = totalList.stream()
.collect(
Collectors.groupingBy(
s -> s.getSex(),
Collectors.averagingDouble(s->s.getScore())
)
);
아래의 더보기를 누르면 예제 코드를 볼 수 있다.
Student.java
public class Student {
private String name;
private String sex;
private int score;
public Student(String name, String sex, int score) {
this.name = name;
this.sex = sex;
this.score = score;
}
public String getName() { return name; }
public String getSex() { return sex; }
public int getScore() { return score; }
}
CollectExample.java
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
import java.util.stream.Collectors;
public class CollectExample {
public static void main(String[] args) {
List<Student> totalList = new ArrayList<>();
totalList.add(new Student("홍길동", "남", 92));
totalList.add(new Student("김수영", "여", 87));
totalList.add(new Student("감자바", "남", 95));
totalList.add(new Student("오해영", "여", 93));
Map<String, Double> map = totalList.stream()
.collect(
Collectors.groupingBy(
s -> s.getSex(),
Collectors.averagingDouble(s->s.getScore())
)
);
System.out.println(map);
}
}
/*
{남=93.5, 여=90.0}
*/
요소 병렬 처리
요소 병렬 처리란 멀티 코어 CPU 환경에서 전체 요소를 분할해서 각각의 코어가 병렬적으로 처리하는 것을 말한다.
요소 병렬 처리의 목적은 작업 처리 시간을 줄이는 것에 있다.
자바는 요소 병렬 처리를 위해 병렬 스트림을 제공한다.
동시성과 병렬성
멀티 스레드는 동시성 또는 병렬성으로 실행된다.
- 동시성 : 멀티 작업을 위해 멀티 스레드가 하나의 코어에서 번갈아 가며 실행
- 병렬성 : 멀티 작업을 위해 멀티 코어를 각각 이용해서 병렬로 실행
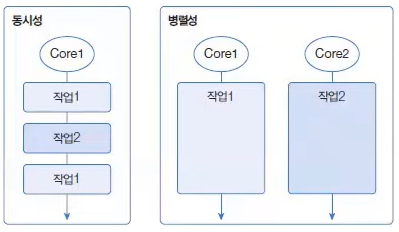
동시성은 한 시점에 하나의 작업만 실행한다.
병렬성은 한 시점에 여러 개의 작업을 병렬로 실행하기 때문에 동시성보다는 좋은 성능을 낸다.
병렬성은 아래와 같이 두 가지로 나뉜다.
- 데이터 병렬성
- 작업 병렬성
데이터 병렬성
데이터 병렬성은 전체 데이터를 분할해서 서브 데이터셋으로 만들고 이 서브 데이터셋들을 병렬 처리해서 작업을 빨리 끝내는 것을 말한다.
서브 데이터셋은 멀티 코어의 수만큼 쪼개어 각각의 데이터들을 분리된 스레드에서 병렬처리 한다.
자바 병렬 스트림은 데이터 병렬성을 구현한 것이다.
작업 병렬성
작업 병렬성은 서로 다른 작업을 병렬 처리하는 것을 말한다.
작업 병렬성의 대표적인 예는 서버 프로그램이다.
서버는 각각의 클라이언트에서 요청한 내용을 개별 스레드에서 병렬로 처리한다.
포크조인 프레임워크
자바 병렬 스트림은 요소들을 병렬처리하기 위해 포크 조인 프레임워크를 사용한다.
포크조인 프레임워크는 포크 단계에서 전체 요소들을 서브 요소셋으로 분할하고, 각각의 서브 요소셋을 멀티 코어에서 병렬로 처리한다.
조인 단계에서는 서브 결과를 결합해서 최종 결과를 만들어낸다.
예를 들어 쿼드 코어 CPU에서 병렬 스트림으로 요소들을 처리할 경우 먼저 포크 단계에서 스트림의 전체 요소들을 4개의 서브 요소셋으로 분할한다.
그리고 각각의 서브 요소셋을 개별 코어에서 처리하고, 조인 단계에서는 3번의 결합 과정을 거쳐 최종 결과를 산출한다.

병렬 처리 스트림은 포크 단계에서 요소를 순서대로 분할하지 않는다.
이해하기 쉽도록 위 그림에서는 앞에서부터 차례대로 4등분 했지만, 내부적으로 요소들을 나누는 알고리즘이 있다.
포크조인 프레임워크는 병렬 처리를 위해 스레드풀을 사용한다. 각각의 코어에서 서브 요소셋을 처리하는 것은 작업 스레드가 해야 하므로 스레드 관리가 필요하다.
포크조인 프레임워크는 ExecutorService의 구현 객체인 ForkJoinPool을 사용해서 작업 스레드를 관리한다.

병렬 스트림 사용
자바 병렬 스트림을 이용할 경우에는 백그라운드에서 포크조인 프레임워크가 사용되기 때문에 개발자는 매우 쉽게 병렬 처리를 할 수 있다.
병렬 스트림은 아래의 두 가지 메소드로 얻을 수 있다.

parallelStream() 메소드는 컬렉션(List, Set)으로부터 병렬 스트림을 바로 리턴한다.
parallel()메소드는 기존 스트림을 병렬 처리 스트림으로 변환한다.
아래의 예제는 1억개의 점수에 대한 평균을 얻을 때 일반 스트림과 병렬 스트림의 처리 시간을 측정한 예제이다.
더보기를 누르면 볼 수 있다.
ParallelExample.java
import java.util.ArrayList;
import java.util.List;
import java.util.Random;
import java.util.stream.Stream;
public class ParallelExample {
public static void main(String[] args) {
Random random = new Random();
List<Integer> scores = new ArrayList< >();
for(int i=0; i<100000000; i++) {
scores.add(random.nextInt(101));
}
double avg = 0.0;
long startTime = 0;
long endTime = 0;
long time = 0;
Stream<Integer> stream = scores.stream();
startTime = System.nanoTime();
avg = stream
.mapToInt(i -> i.intValue())
.average()
.getAsDouble();
endTime = System.nanoTime();
time = endTime - startTime;
System.out.println("avg: " + avg + ", 일반 스트림 처리 시간: " + time + "ns");
Stream<Integer> parallelStream = scores.parallelStream();
startTime = System.nanoTime();
avg = parallelStream
.mapToInt(i -> i.intValue())
.average()
.getAsDouble();
endTime = System.nanoTime();
time = endTime - startTime;
System.out.println("avg: " + avg + ", 병렬 스트림 처리 시간: " + time + "ns");
}
}
/*
avg: 49.99819842, 일반 스트림 처리 시간: 82815600ns
avg: 49.99819842, 병렬 스트림 처리 시간: 45988500ns
*/
병렬 처리 성능
병령 처리가 순차 처리보다 항상 실행 성능이 좋지는 않다.
병렬 처리에 영향을 미치는 아래의 3가지 요인을 잘 살펴보아야 한다.
요소의 수와 요소당 처리 시간
- 컬렉션에 전체 요소의 수가 적고 요소당 처리 시간이 짧으면 일반 스트림이 병렬 스트림보다 빠를 수 있다.
- 병렬 처리는 포크 및 조인 단계가 있고, 스레드 풀을 생성하는 추가적인 시간이 발생하기 때문이다.
스트림 소스의 종류
- ArrayList와 배열은 인덱스로 요소를 관리하기 때문에 포크 단계에서 요소를 쉽게 분리할 수 있어 병렬 처리 시간이 절약된다.
- 반면에 HashSet, TreeSet은 요소 분리가 쉽지 않고, LinkedList 또한 링크를 따라가야 하므로 요소 분리가 쉽지 않다.
- 따라서 이 소스들은 상대적으로 병렬 처리가 늦다.
코어의 수
- CPU의 코어의 수가 많으면 많을수록 병렬 스트림의 성능은 좋아진다.
- 하지만 코어의 수가 적을 경우에는 일반 스트림이 더 빠를 수 있다.
- 병렬 스트림은 스레드 수가 증가하여 동시성이 많이 일어나므로 오히려 느려진다.
'Java Category > Java' 카테고리의 다른 글
| [Java] 보조 스트림(문자 변환, 성능 향상, 기본 타입, 프린트, 객체) (0) | 2023.08.09 |
|---|---|
| [Java] 바이트 & 문자 입출력 스트림 (0) | 2023.08.08 |
| [Java] 스트림(스트림 개념, 스트림 얻기, 필터링, 매핑) (0) | 2023.08.06 |
| [Java] 람다식 (0) | 2023.08.05 |
| [Java] 컬렉션 프레임워크(LIFO & FIFO, 동기화된 컬렉션, 수정할 수 없는 컬렉션) (0) | 2023.08.04 |

댓글