import java.util.ArrayList;
import java.util.LinkedList;
import java.util.List;
public class LinkedListExample {
public static void main(String[] args) {
//ArrayList 컬렉션 객체 생성
List<String> list1 = new ArrayList<String>();
//LinkedList 컬렉션 객체 생성
List<String> list2 = new LinkedList<String>();
//시작 시간과 끝 시간을 저장할 변수 선언
long startTime;
long endTime;
//ArrayList 컬렉션에 저장하는 시간 측정
startTime = System.nanoTime();
for(int i=0; i<10000; i++) {
list1.add(0, String.valueOf(i));
}
endTime = System.nanoTime();
System.out.printf("%-17s %8d ns \n", "ArrayList 걸린 시간: ", (endTime-startTime) );
//LinkedList 컬렉션에 저장하는 시간 측정
startTime = System.nanoTime();
for(int i=0; i<10000; i++) {
list2.add(0, String.valueOf(i));
}
endTime = System.nanoTime();
System.out.printf("%-17s %8d ns \n", "LinkedList 걸린 시간: ", (endTime-startTime) );
}
}
/*
ArrayList 걸린 시간: 5813200 ns
LinkedList 걸린 시간: 880900 ns
*/
Set 컬렉션
Set 컬렉션은 저장 순서가 유지되지 않는다.
또한 객체를 중복해서 저장할 수 없고, 하나의 null만 저장할 수 있다.
Set 컬렉션은 수학의 집합에 비유될 수 있다.
집합은 순서와 상관없고 중복이 허용되지 않기 때문이다.
Set 컬렉션에는 HashSet, LinkedHashSet, TreeSet 등이 있는데, Set 컬렉션에서 공통적으로 사용 가능한 Set 인터페이스의 메소드는 아래 표와 같다.
기능
메소드
설명
객체 추가
boolean add(E e)
주어진 객체를 성공적으로 저장하면 true를 리턴하고 중복 객체면 false를 리턴
객체 검색
boolean contains(Object o)
주어진 객체가 저장되어 있는지 여부
isEmpty()
컬렉션이 비어 있는지 조사
Iterator<E> iterator()
저장된 객체를 한 번씩 가져오는 반복자 리턴
int size()
저장되어 있는 전체 객체 수 리턴
객체 삭제
void clear()
저장된 모든 객체를 삭제
boolean remove(Object o)
주어진 객체를 삭제
Iterator<E> iterator() 이 메소드는 Interface Iterable<E>의 추상 메소드이다. Iterable을 한국어로 번역하면 '반복할 수 있는'이다. 향상된 for문에서 선언할 수 있는 객체는 이 인터페이스를 구현한 객체만 올 수 있다. iterator() 메소드를 호출하면 해당 객체의 참조를 Iterator 타입으로 가져온다.
HashSet
Set 컬렉션 중에서 가장 많이 사용되는 것이 HashSet이다.
아래는 HashSet 컬렉션을 생성하는 방법이다.
Set<E> set = new HashSet<E>();
Set<E> set = new HashSet<>();
Set set new Hashset();
HashSet은 동일한 객체는 중복 저장하지 않는다.
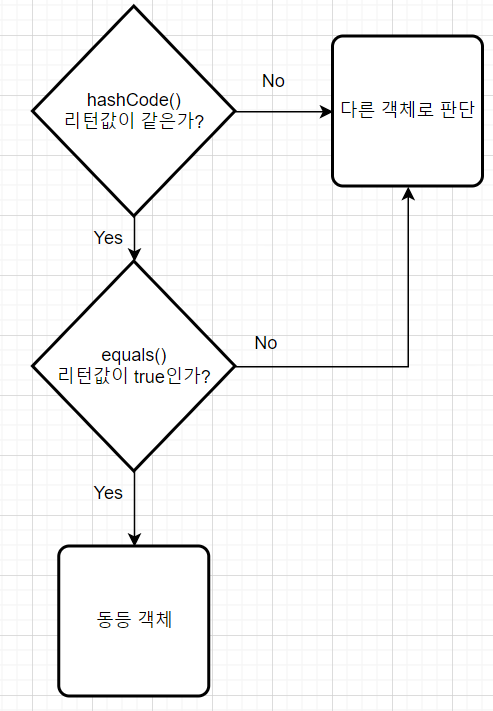
여기서 동일한 객체란 동등 객체를 말한다. HashSet은 다른 객체라도 HashCode() 메소드의 리턴값이 같고, equals() 메소드가 true를 리턴하면 동일한 객체라고 판단하고 중복 저장하지 않는다.
import java.util.*;
public class HashSetExample {
public static void main(String[] args) {
//HashSet 컬렉션 생성
Set<String> set = new HashSet<String>();
//객체 저장
set.add("Java");
set.add("JDBC");
set.add("Servlet/JSP");
set.add("Java"); //<-- 중복 객체이므로 저장하지 않음
set.add("iBATIS");
//저장된 객체 수 출력
int size = set.size();
System.out.println("총 객체 수: " + size);
}
}
/*
총 객체 수: 4
*/
public class Member {
public String name;
public int age;
public Member(String name, int age) {
this.name = name;
this.age = age;
}
//hashCode 재정의
@Override
public int hashCode() {
return name.hashCode() + age;
}
//equals 재정의
@Override
public boolean equals(Object obj) {
if(obj instanceof Member target) {
return target.name.equals(name) && (target.age==age) ;
} else {
return false;
}
}
}
HashSetExample.java
import java.util.*;
public class HashSetExample {
public static void main(String[] args) {
//HashSet 컬렉션 생성
Set<Member> set = new HashSet<Member>();
//Member 객체 저장
set.add(new Member("홍길동", 30));
set.add(new Member("홍길동", 30));
//저장된 객체 수 출력
System.out.println("총 객체 수 : " + set.size());
}
}
/*
총 객체 수 : 1
*/
Set 컬렉션은 인덱스로 객체를 검색해서 가져오는 메소드가 없다.
대신 객체를 한 개씩 반복해서 가져와야 하는데, 두 가지 방법이 있다.
1. for 문을 이용하는 방법
Set<E> set = new HashSet<E>();
for(E e : set) {
}
for문에서 HashSet 객체를 직접적으로 추가 및 삭제를 하면 안 된다.
for(String element : set) {
if(element.equals("JSP")) {
set.remove(element);
}
}
위 코드에서 set의 객체의 개수가 4개라고 하면, 처음에 for문은 반복하는 횟수가 4번으로 정해져 있다. 하지만 중간에 remove나 add 메소드로 인해서 set 객체의 개수가 감소 또는 증가하면 4번 반복을 돌아야하는데 객체의 수가 4개 미만 또는 초과이므로 for문은 오류를 내뿜는다. 따라서 직접적인 add나 remove 메소드 호출은 지양해야 한다.
추가 또는 삭제를 하려면 iterator() 메소드로 반복자를 얻어서 작업을 하는 것이 안전하다.
2. iterator() 메소드로 반복자를 얻어 객체를 하나씩 가져오기
Set<E> set = new HashSet<E>();
Iterator<E> iterator = set.iterator();
iterator는 Set 컬렉션의 객체를 가져오거나 제거하기 위해 아래의 메소드를 제공한다.
리턴 타입
메소드명
설명
boolean
hasNext()
가져올 객체가 있으면 true를 리턴하고 없으면 false를 리턴
E
next()
컬렉션에서 하나의 객체를 가져온다.
void
remove()
next()로 가져온 객체를 Set 컬렉션에서 제거한다.
사용 방법은 아래와 같다.
while(iterator.hasNext()) {
E e = iterator.next();
}
hasNext() 메소드로 가져올 객체가 있는지 먼저 확인하고, true를 리턴할 때만 next() 메소드로 객체를 가져온다.
만약, next()로 가져온 객체를 컬렉션에서 제거하고 싶다면 remove() 메소드를 사용한다.
HashSet 추가, 삭제, 제거 예제
import java.util.*;
public class HashSetExample {
public static void main(String[] args) {
//HashSet 컬렉션 생성
Set<String> set = new HashSet<String>();
//객체 추가
set.add("Java");
set.add("JDBC");
set.add("JSP");
set.add("Spring");
//객체를 하나씩 가져와서 처리
Iterator<String> iterator = set.iterator();
while(iterator.hasNext()) {
//객체를 하나 가져오기
String element = iterator.next();
System.out.println( element);
if(element.equals("JSP")) {
//가져온 객체를 컬렉션에서 제거
iterator.remove();
}
}
System.out.println();
//객체 제거
set.remove("JDBC");
//객체를 하나씩 가져와서 처리
for(String element : set) {
System.out.println(element);
}
}
}
/*
Java
JSP
JDBC
Spring
Java
Spring
*/
Map 컬렉션
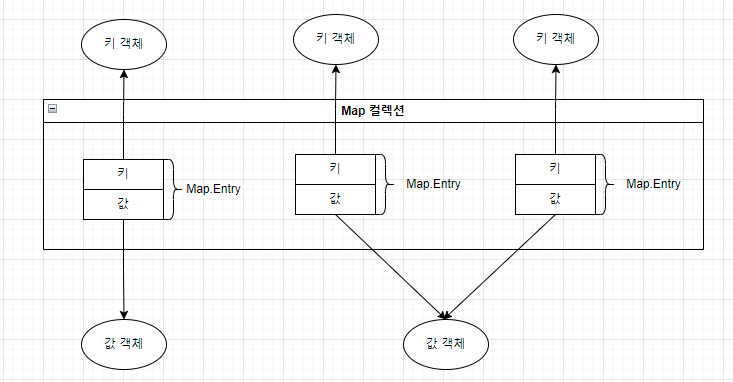
Map 컬렉션은 키(key)와 값(value)으로 구성된 엔트리(entry) 객체를 저장한다.
여기서 키와 값은 모두 객체이다.
키는 중복저장할 수 없지만, 값은 중복 저장할 수 있다.
기존에 저장된 키와 동일한 키로 값을 저장하면 기존의 값은 없어지고 새로운 값으로 바뀌게 된다.
Map 컬렉션에는 HashMap, HashTable, LinkedHash, Properties, TreeMap 등이 있다.
Map 컬렉션에서 공통적으로 사용 가능한 Map 인터페이스 메소드는 아래와 같다.
기능
메소드
설명
객체 추가
V put(K key, V value)
주어진 키와 값을 추가, 저장이 되면 값을 리턴
객체 검색
boolean containsKey(Object key)
주어진 키가 있는지 여부
boolean containsValue(object value)
주어진 값이 있는지 여부
Set<Map.Entry<K, V>> entrySet()
키와 값의 쌍으로 구성된 모든 Map.Entry 객체를 Set에 담아서 리턴
V get(Object key)
주어진 키의 값을 리턴
boolean isEmpty()
컬렉션이 비어있는지 여부
Set<K> keySet()
모든 키를 Set 객체에 담아서 리턴
int size()
저장된 키의 총 수를 리턴
Collection<V> values()
저장된 모든 값 Collection에 담아서 리턴
객체 삭제
void clear()
모든 Map.Entry(키와 값)를 삭제
V remove(Object key)
주어진 키와 일치하는 Map.Entry 삭제, 삭제가 되면 값을 리턴
위 표에서 K와 V는 타입 파라미터이고, K는 키 타입, V는 값 타입을 말한다.
HashMap
HashMap은 키로 사용할 객체가 hashCode() 메소드의 리턴값이 같고 equals() 메소드가 true를 리턴할 경우, 동일 키로 보고 중복 저장을 허용하지 않는다.
아래는 HashMap 컬렉션을 생성하는 방법이다. K와 V는 각각 키와 값의 타입을 지정할 수 있는 타입 파라미터이다.
public class Person implements Comparable<Person> {
public String name;
public int age;
public Person(String name, int age) {
this.name = name;
this.age = age;
}
@Override
public int compareTo(Person o) {
if(age<o.age) return -1;
else if(age == o.age) return 0;
else return 1;
}
}
ComparableExample.java
import java.util.TreeSet;
public class ComparableExample {
public static void main(String[] args) {
//TreeSet 컬렉션 생성
TreeSet<Person> treeSet = new TreeSet<Person>();
//객체 저장
treeSet.add(new Person("홍길동", 45));
treeSet.add(new Person("감자바", 25));
treeSet.add(new Person("박지원", 31));
//객체를 하나씩 가져오기
for(Person person : treeSet) {
System.out.println(person.name + ":" + person.age);
}
}
}
/*
감자바:25
박지원:31
홍길동:45
*/
Comparator
비교 기능이 있는 Comparable 구현 객체를 TreeSet에 저장하거나 TreeMap의 키로 저장하는 것이 원칙이다
하지만 비교 기능이 없는 Comparable 비구현 객체를 저장하고 싶다면 TreeSet과 TreeMap을 생성할 때 비교자(Comparator)를 아래와 같이 제공하면 된다.
TreeSet<K, V> treeSet = new TreeMap<E>(new ComparatorImpl());
TreeMap<K, V> treeMap = new TreeMap<K, V>(new ComparatorImpl());
비교자는 Comparator 인터페이스를 구현한 객체를 말하는데, Comparator 인터페이스에는 compare() 메소드가 정의되어 있다.
비교자는 이 메소드를 재정의해서 비교 결과를 정수 값으로 리턴하면 된다.
리턴 타입
메소드
설명
int
compare(T o1, T o2)
o1과 o2가 동등하다면 0을 리턴 o1이 o2 앞에 오게 하려면 음수를 리턴 o1이 o2 뒤에 오게 하려면 양수를 리턴
아래는 Comparable을 구현하고 있지 않은 사용자 정의 객체를 TreeSet에 저장하는 예제이다.





댓글