이 글은 혼자 공부하는 컴퓨터 구조 + 운영체제 (저자 : 강민철)의 책과 유튜브 영상을 참고하여 개인적으로 정리하는 글임을 알립니다.
빠른 CPU를 만들려면 빠른 클럭 속도에 멀티코어, 멀티스레드를 지원하는 CPU를 만드는 것도 중요하지만 CPU를 놀지 않게하고 효율적으로 작동시키는 것도 중요하다.
CPU를 쉬지 않고 작동시키는 방법에는 명령어 병릴 처리기법이 있다.
명령어 병렬 처리기법에는 아래와 같은 종류가 있다.
- 명령어 파이프라이닝
- 슈퍼스칼라
- 비순차적 명령어 처리
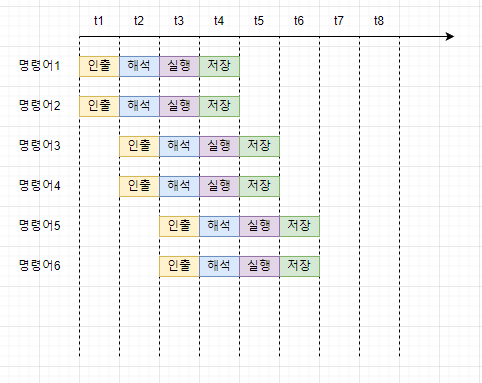
명령어 파이프라인
하나의 명령어가 처리되는 전체과정을 클럭단위로 나누어 보면 아래와 같다.
- 명령어 인출(Instruction Fetch)
- 명령어 해석 (Instruction Decode)
- 명렁어 실행 (Execute Instruction)
- 결과 저장 (Write Back)
여기서 중요한 점은 같은 단계가 겹치지않으면 CPU는 각 단계를 동시에 실행할 수 있다는 것이다.

위 그림과 같이 CPU는 한 명령어를 인출하는 동안에 다른 명령어를 실행할 수 있고, 한 명령어가 실행되는 동안에 연산 결과를 저장할 수 있다.
이처럼 공장 생산 라인과 같이 명령어들을 명령어 파이프라인에 넣고 동시에 처리하는 기법을 명령어 파이프라이닝이라고 한다.
파이프 라이닝은 높은 성능을 가져다 주지만, 특정 상황에는 성능 향상에 실패한다.
이러한 상황을 파이프라인 위험이라고 부른다. 파이프라인 위험의 종류는 아래와 같다.
- 데이터 위험
- 제어 위험
- 구조적 위험
데이터 위험
명령어 간 데이터 의존성에 의해 발생한다.
- 명령어 1 : R1 <- R2 + R3 // R2 레지스터 값과 R3 레지스터 값을 더한 값을 R1 레지스터에 저장
- 명령어 2 : R4 <- R1 + R5 // R1 레지스터 값과 R5 레지스터 값을 더한 값을 R4 레지스터에 저장
위와 같은 경우 명령어 1을 수행해야만 명령어 2를 수행할 수 있다.
따라서 명령어 2는 명령어 1의 데이터에 의존적이다.
이처럼 데이터 의존적인 두 명령어를 동시에 실행하려고하면 파이프라인이 제대로 작동하지 않는 것을 데이터 위험이라고 한다.
제어 위험
주로 분기 등으로 인한 프로그램 카운터의 갑작스러운 변화에 의해 발생한다.
기본적으로 프로그램 카운터는 현재 실행중인 명령어의 다음 주소로 갱신된다. 하지만 프로그램 실행 흐름이 바뀌어 명령어가 실행되면서 프로그램 카운터 값에 갑작스로운 변화가 생기면 명령어 파이프라인에 미리 가지고 와서 처리 중이었던 명령어는 쓸모가 없어진다.
예를 들어, 11번지, 12번지, 13번지 ... 순으로 명령어 파이프라인이 진행중이었는데 11번지 명령어 실행 도중 갑자기 60번지 명령어를 실행해야 한다면 12~59번지 명령어는 쓸모가 없어진다.
이를 제어 위험이라고 부른다.
이러한 제어 위험을 위해 사용하는 기술중에 분기 예측이 있다. 분기 예측은 프로그램이 어디로 분기할지 미리 예측한 후 그 주소를 인출하는 기술이다.
구조적 위험
명령어들을 겹쳐 실행하는 과정에서 서로 다른 명령어가 동시에 CPU내부에 있는 부품을 사용하려고 할 때 발생한다.
구조적 위험은 자원 위험이라고도 부른다.
슈퍼스칼라
단일 파이프라인 보다는 여러 개의 파이프 라인을 가지는 것이 유리하다.
CPU 내부에 여러 명령어 파이프 라인을 가진 구조를 "슈퍼스칼라" 라고 한다.
슈퍼 스칼라 구조로 명령어 처리가 가능한 CPU를 슈퍼스칼라 프로세서 또는 슈퍼스칼라 CPU라고 한다.
슈퍼 스칼라는 이론적으로 파이프라인 개수에 비례하여 처리 속도가 빨라진다.
하지만 파이프라인 위험 때문에 파이프라인 개수에 비례하여 빨라지진 않는다.
비순차적 명령어 처리
명령어들을 순차적으로 실행하지 않는 기법으로 데이터 의존성이 있는 데이터의 순서를 바꾸는 방법이다.
즉, 명령어 간 의존 관계가 없는 명령어 등을 먼저 실행 하는 것이다.
- M(100) <- 1 //메모리 주소 100에 1을 저장해라
- M(101) <- 2 //메모리 주소 101에 2를 저장해라
- M(102) <- M(100) + M(102) // 메모리 주소 102에 메모리 주소 100과 102를 더한 값을 저장해라
- M(103) <- 1 //메모리 주소 103에 1을 저장해라
- M(104) <- 2 //메모리 주소 104에 2를 저장해라
여기서 M(102) <- M(100) + M(102)는 데이터 의존성이 있다.
이러한 명령어를 뒤로 보내버린다.
- M(100) <- 1 //메모리 주소 100에 1을 저장해라
- M(101) <- 2 //메모리 주소 101에 2를 저장해라
- M(103) <- 1 //메모리 주소 103에 1을 저장해라
- M(104) <- 2 //메모리 주소 104에 2를 저장해라
- M(102) <- M(100) + M(102) // 메모리 주소 102에 메모리 주소 100과 102를 더한 값을 저장해라
이렇게 바꾸면 파이프라인의 중단이 사라지게 되어 CPU의 성능 향상에 도움이 된다.
'컴퓨터 구조 & 운영체제 > 컴퓨터 구조' 카테고리의 다른 글
| [컴퓨터 구조] RAM의 특징과 종류 (1) | 2023.05.10 |
|---|---|
| [컴퓨터 구조] CISC와 RISC (0) | 2023.04.12 |
| [컴퓨터 구조] 빠른 CPU를 위한 설계 기법 (0) | 2023.04.10 |
| [컴퓨터 구조] 명령어 사이클과 인터럽트 (0) | 2023.04.09 |
| [컴퓨터 구조] 레지스터 (0) | 2023.03.31 |

댓글