이 글은 인프런 김영한님의 Spring 강의를 바탕으로 개인적인 정리를 위해 작성한 글입니다.
타임리프(Thymeleaf)에서 템플릿 레이아웃은 웹 애플리케이션의 다양한 페이지에서 공통적으로 사용되는 레이아웃 구조를 재사용할 수 있도록 도와준다.
이를 통해 개발자는 중복 코드를 줄이고, 일관된 레이아웃을 유지할 수 있다.
예를 들어서 <head> 에 공통으로 사용하는 css , javascript 같은 정보들이 있는데, 이러한 공통 정보들을 한 곳 에 모아두고, 공통으로 사용하지만, 각 페이지마다 필요한 정보를 더 추가해서 사용하고 싶다면 다음과 같이 사용하면 된다.
컨트롤러
@GetMapping("/layout")
public String layout() {
return "template/layout/layoutMain";
}
base.html
<html xmlns:th="http://www.thymeleaf.org">
<!-- common_header 를 호출해서 이 페이지의 title 태그와 link 태그를 대체함 -->
<!-- title 과 links 는 단순 파라미터 이름 -->
<head th:fragment="common_header(title,links)">
<title th:replace="${title}">레이아웃 타이틀</title>
<!-- 공통 -->
<link rel="stylesheet" type="text/css" media="all" th:href="@{/css/awesomeapp.css}">
<link rel="shortcut icon" th:href="@{/images/favicon.ico}">
<script type="text/javascript" th:src="@{/sh/scripts/codebase.js}"></script>
<!-- 추가 -->
<th:block th:replace="${links}" />
</head>
layoutExtend.html
<!DOCTYPE html>
<html xmlns:th="http://www.thymeleaf.org">
<!-- base.html로 common_header 라는 이름으로 타이틀과 링크 태그를 파라미터로 넘김 -->
<!-- 타이틀 태그와 링크 태그를 파라미터로 넘길 수 있음 -->
<head th:replace="template/layout/base :: common_header(~{::title},~{::link})">
<title>메인 타이틀</title>
<link rel="stylesheet" th:href="@{/css/bootstrap.min.css}">
<link rel="stylesheet" th:href="@{/themes/smoothness/jquery-ui.css}">
</head>
<body> 메인 컨텐츠 </body>
</html>
common_header(~{::title},~{::link}) 이 부분이 핵심이다.
::title 은 현재 페이지의 title 태그들을 전달한다.
::link 는 현재 페이지의 link 태그들을 전달한다.
결과
<!DOCTYPE html>
<html>
<!-- base.html로 common_header 라는 이름으로 타이틀과 링크 태그를 파라미터로 넘김 -->
<!-- 타이틀 태그와 링크 태그를 파라미터로 넘길 수 있음 -->
<head>
<title>메인 타이틀</title>
<!-- 공통 -->
<link rel="stylesheet" type="text/css" media="all" href="/css/awesomeapp.css">
<link rel="shortcut icon" href="/images/favicon.ico">
<script type="text/javascript" src="/sh/scripts/codebase.js"></script>
<!-- 추가 -->
<link rel="stylesheet" href="/css/bootstrap.min.css"><link rel="stylesheet" href="/themes/smoothness/jquery-ui.css">
</head>
<body> 메인 컨텐츠 </body>
</html>
메인 타이틀이 전달한 부분으로 교체되었다.
공통 부분은 그대로 유지되고, 추가 부분에 전달한 <link> 들이 포함된 것을 확인할 수 있다.
<head> 정도에만 적용하는게 아니라 <html> 전체에 적용할 수도 있다.
컨트롤러
@GetMapping("/layoutExtend")
public String layoutExtends() {
return "template/layoutExtend/layoutExtendMain";
}
layoutFile.html
<!DOCTYPE html>
<!-- layout 을 호출해서 이 페이지의 title 태그와 div 태그를 대체함 -->
<!-- title->title, div->section 으로 대체 -->
<!-- title 과 content 는 단순 파라미터 이름 -->
<html th:fragment="layout (title, content)" xmlns:th="http://www.thymeleaf.org">
<head>
<title th:replace="${title}">레이아웃 타이틀</title>
</head>
<body>
<h1>레이아웃 H1</h1>
<div th:replace="${content}">
<p>레이아웃 컨텐츠</p>
</div>
<footer> 레이아웃 푸터 </footer>
</body>
</html>
layoutExtendMain.html
<!DOCTYPE html>
<!-- layoutFile.html로 layout 라는 이름으로 타이틀과 섹션 태그를 파라미터로 넘김 -->
<!-- 타이틀 태그와 섹션 태그를 파라미터로 넘길 수 있음 -->
<html th:replace="~{template/layoutExtend/layoutFile :: layout(~{::title},~{::section})}" xmlns:th="http://www.thymeleaf.org">
<head>
<title>메인 페이지 타이틀</title>
</head>
<body>
<section>
<p>메인 페이지 컨텐츠</p>
<div>메인 페이지 포함 내용</div>
</section>
</body>
</html>
결과
<!DOCTYPE html>
<!-- layoutFile.html로 layout 라는 이름으로 타이틀과 섹션 태그를 파라미터로 넘김 -->
<!-- 타이틀 태그와 섹션 태그를 파라미터로 넘길 수 있음 -->
<html>
<head>
<title>메인 페이지 타이틀</title>
</head>
<body>
<h1>레이아웃 H1</h1>
<section>
<p>메인 페이지 컨텐츠</p>
<div>메인 페이지 포함 내용</div>
</section>
<footer> 레이아웃 푸터 </footer>
</body>
</html>
템플릿 조각을 참조할 때 사용하는 표현식은 템플릿명::조각명 형식을 따른다. 템플릿명은 조각이 정의된 파일의 이름이며, 조각명은 해당 파일 내에서 th:fragment로 정의된 조각의 이름이다.
th:fragment 가 있는 태그는 다른곳에 포함되는 코드 조각으로 이해하면 된다.
파라미터 전달하기
템플릿 조각에 파라미터를 전달하여 동적인 내용을 생성할 수도 있다. 이를 위해 조각을 정의할 때 파라미터를 명시하고, 조각을 사용할 때 파라미터 값을 전달한다.
<!-- header.html -->
<div th:fragment="headerFragment (title)">
<header>
<h1 th:text="${title}">기본 타이틀</h1>
</header>
</div>
<!-- index.html에서 조각 사용하며 파라미터 전달 -->
<div th:replace="header.html::headerFragment (${pageTitle})"></div>
예시
컨트롤러
@GetMapping("/fragment")
public String template() {
return "template/fragment/fragmentMain";
}
footer/html
<!DOCTYPE html>
<html xmlns:th="http://www.thymeleaf.org">
<body>
<footer th:fragment="copy"> <!-- 이렇게 설정하면 함수 쓰듯이 copy 라는 이름으로 호출할 수 있다. (템플릿 조각) -->
푸터 자리 입니다.
</footer>
<footer th:fragment="copyParam (param1, param2)"> <!-- copyParam 라는 이름으로 파라미터를 사용할 수 있게 해준다.(템플릿 조각) -->
<p>파라미터 자리 입니다.</p>
<p th:text="${param1}"></p>
<p th:text="${param2}"></p>
</footer>
</body>
</html>
fragmentMain.html
<!DOCTYPE html>
<html xmlns:th="http://www.thymeleaf.org">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<h1>부분 포함</h1>
<h2>부분 포함 insert</h2>
<div th:insert="~{template/fragment/footer :: copy}"></div> <!-- div 태그 안에 copy 를 넣음 -->
<h2>부분 포함 replace</h2>
<div th:replace="~{template/fragment/footer :: copy}"></div> <!-- div 태그를 copy 가 대체함 -->
<h2>부분 포함 단순 표현식</h2>
<div th:replace="template/fragment/footer :: copy"></div> <!-- copy 가 단순하다면 ~{} 생략 가능 -->
<h1>파라미터 사용</h1>
<div th:replace="~{template/fragment/footer :: copyParam ('데이터1', '데이터2')}"></div> <!-- copyParam 템플릿 조각 으로 div 태그 대체 -->
</body>
</html>
결과
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<h1>부분 포함</h1>
<h2>부분 포함 insert</h2>
<div><footer> <!-- 이렇게 설정하면 함수 쓰듯이 copy 라는 이름으로 호출할 수 있다. (템플릿 조각) -->
푸터 자리 입니다.
</footer></div> <!-- div 태그 안에 copy 를 넣음 -->
<h2>부분 포함 replace</h2>
<footer> <!-- 이렇게 설정하면 함수 쓰듯이 copy 라는 이름으로 호출할 수 있다. (템플릿 조각) -->
푸터 자리 입니다.
</footer> <!-- div 태그를 copy 가 대체함 -->
<h2>부분 포함 단순 표현식</h2>
<footer> <!-- 이렇게 설정하면 함수 쓰듯이 copy 라는 이름으로 호출할 수 있다. (템플릿 조각) -->
푸터 자리 입니다.
</footer> <!-- copy 가 단순하다면 ~{} 생략 가능 -->
<h1>파라미터 사용</h1>
<footer> <!-- copyParam 라는 이름으로 파라미터를 사용할 수 있게 해준다.(템플릿 조각) -->
<p>파라미터 자리 입니다.</p>
<p>데이터1</p>
<p>데이터2</p>
</footer> <!-- copyParam 템플릿 조각 으로 div 태그 대체 -->
</body>
</html>
<!DOCTYPE html>
<html xmlns:th="http://www.thymeleaf.org">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<h1>컨텐츠에 데이터 출력하기</h1>
<ul>
<li>th:text 사용 <span th:text="${data}"></span></li>
<li>컨텐츠 안에서 직접 출력하기 = [[${data}]]</li>
</ul>
</body>
</html>
결과
Escape
뷰 템플릿으로 HTML 화면을 생성할 때는 출력하는 데이터에 < 과 > 같은 특수 문자가 있는 것을 주의해서 사용해야 한다.
"Hello <b>Spring!</b>"
이렇게 작성한 코드는 아래와 같이 변환된다.
Hello <b>Spring!</b>
HTML 엔티티
웹브라우저는 < 를HTML테그의 시작으로 인식한다. 따라서 < 를 태그의 시작이 아니라 문자로 표현할 수 있는 방법이 필요한데, 이것을 HTML 엔티티라 한다. 그리고 이렇게 HTML에서 사용하는 특수 문자를 HTML 엔티티로 변경하는 것을 이스케이프(escape)라 한다. 그리고 타임리프가 제공하는 th:text , [[...]] 는 기본적으로 이스케이프 (escape)를 제공한다.
예: <div th:if="${condition}">조건이 참일 때 보여질 내용</div>
th:unless
th:unless는 지정된 조건이 거짓(False)일 때 태그를 렌더링한다. th:if의 반대 역할을 한다.
예: <div th:unless="${condition}">조건이 거짓일 때 보여질 내용</div>
th:switch와 th:case
th:switch와 함께 사용되는 th:case는 다중 조건을 처리할 때 사용된다.
switch 문과 유사하게 작동한다.
Elvis 연산자
타임리프에서 Elvis 연산자는 널 값을 안전하게 처리하는데 사용된다. 이 연산자는 표현식이 널(null)인 경우 대체 값을 제공하는 방법이다. 타임리프의 표현식에서 ?: 기호를 사용하여 Elvis 연산자를 구현한다. 첫 번째 피연산자가 널이 아닌 경우 해당 값을 반환하고, 널인 경우 두 번째 피연산자의 값을 반환한다.
예를 들어, 사용자의 이름을 표시하되, 이름이 없는 경우 기본값으로 "익명"을 표시하고자 할 때 타임리프에서는 다음과 같이 Elvis 연산자를 사용할 수 있다.
<span th:text="${user.name} ?: '익명'"></span>
No-Operation
No-Operation, 줄여서 NOP라고도 불리는 것은, 실행될 때 아무런 동작도 하지 않는 연산을 말한다. 프로그래밍에서 NOP은 주로 코드의 흐름을 변경하지 않으면서 자리를 채우기 위해 사용된다. 예를 들어, 조건문에서 특정 조건 하에 아무런 동작도 수행하지 않으려 할 때 유용하다.
타임리프에서는 특별한 동작을 하지 않는 표현식으로 _ (언더스코어)를 사용한다. 이는 타임리프의 No-Operation이다. 타임리프 템플릿 내에서 어떤 조건이 만족하지 않을 때 아무런 동작도 하지 않기를 원할 경우, 이 No-Operation 표현식을 사용할 수 있다.
<!DOCTYPE html>
<html xmlns:th="http://www.thymeleaf.org">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<h1>예시</h1>
<span th:text="${data}">html data</span>
<h1>1. 표준 HTML 주석</h1> <!-- 소스 보기에서 보임 -->
<!-- <span th:text="${data}">html data</span> -->
<h1>2. 타임리프 파서 주석</h1> <!-- 소스 보기에서 안보임 -->
<!--/* [[${data}]] */-->
<!-- 위는 한줄 아래는 여러 라인 -->
<!--/*-->
<span th:text="${data}">html data</span>
<!--*/-->
<h1>3. 타임리프 프로토타입 주석</h1> <!-- 서버 사이드 렌더링시 보임, 단순 html 파일을 열었을 때는 안보임 -->
<!--/*/ <span th:text="${data}">html data</span> /*/-->
</body>
</html>
결과
블록
<th:block> 태그는 타임리프(Thymeleaf) 템플릿 엔진에서 사용하는 특별한 태그로, 실제 HTML 문서에 추가되지 않는 가상의 태그이다.
이 태그는 주로 그룹화된 표현식을 처리하거나, 템플릿 내에서 조건부 렌더링, 반복 등의 로직을 적용할 때 유용하게 사용된다.
<th:block>은 렌더링 결과에 포함되지 않기 때문에, HTML 문서의 구조에 영향을 주지 않으면서 타임리프의 다양한 기능을 활용할 수 있다는 장점이 있다.
예를 들어, 여러 태그에 걸쳐 같은 조건을 적용하고 싶은 경우나 반복문을 사용하여 여러 요소를 생성해야 할 때 <th:block>을 사용하여 이러한 로직을 간결하게 처리할 수 있다.
컨트롤러
@GetMapping("/block")
public String block(Model model) {
addUsers(model);
return "basic/block";
}
타임리프
<!DOCTYPE html>
<html xmlns:th="http://www.thymeleaf.org">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<!-- <th:block> 은 HTML 태그가 아닌 타임리프의 유일한 자체 태그 -->
<th:block th:each="user : ${users}">
<div>
사용자 이름1 <span th:text="${user.username}"></span>
사용자 나이1 <span th:text="${user.age}"></span>
</div>
<div>
요약 <span th:text="${user.username} + ' / ' + ${user.age}"></span>
</div>
</th:block>
</body>
<!-- 타임리프의 특성상 HTML 태그안에 속성으로 기능을 정의해서 사용하는데, 위 예처럼 이렇게 사용하기 애매한 경우에 사용하면 된다. <th:block> 은 렌더링시 제거된다. -->
</html>
결과
자바스크립트 인라인
타임리프(Thymeleaf)는 자바스크립트 내에서 서버 사이드 변수를 사용할 수 있도록 자바스크립트 인라인 기능을 제공한다.
이를 통해 HTML 템플릿 내부에서 자바스크립트 코드에 타임리프 변수와 표현식을 쉽게 삽입하고 처리할 수 있다. 자바스크립트 인라인을 사용하면, 서버에서 생성된 데이터를 자바스크립트 변수로 바로 할당하여 클라이언트 사이드에서 활용할 수 있다.
사용 방법
자바스크립트 인라인은 th:inline="javascript" 속성을 사용하여 활성화할 수 있다. 이 속성을 <script> 태그에 추가하면, 태그 내부에서 타임리프 표현식을 자바스크립트 코드와 함께 사용할 수 있다.
`<script th:inline="javascript">`
텍스트 렌더링
var username = [[${user.username}]];
인라인 사용 전: var username = userA;
인라인 사용 후: var username = "userA";
인라인 사용 전 렌더링 결과를 보면 userA 라는 변수 이름이 그대로 남아있다. 타임리프 입장에서는 정확하게 렌더링 한 것이지만 아마 개발자가 기대한 것은 다음과 같은 "userA"라는 문자일 것이다.
결과적으로 userA 가 변수명으로 사용되어서 자바스크립트 오류가 발생한다. 다음으로 나오는 숫자 age의 경우에는 " 가 필요 없기 때문에 정상 렌더링 된다.
인라인 사용 후 렌더링 결과를 보면 문자 타입인 경우 " 를 포함해준다. 추가로 자바스크립트에서 문제가 될 수 있는 문자가 포함되어 있으면 이스케이프 처리도 해준다. 예) " → ₩"
자바스크립트 내추럴 템플릿
타임리프는 HTML 파일을 직접 열어도 동작하는 내추럴 템플릿 기능을 제공한다. 자바스크립트 인라인 기능을 사용하면 주석을 활용해서 이 기능을 사용할 수 있다.
var username2 = /*[[${user.username}]]*/ "test username";
인라인 사용 전: var username2 = /*userA*/ "test username";
인라인 사용 후: var username2 = "userA";
인라인 사용 전 결과를 보면 정말 순수하게 그대로 해석을 해버렸다. 따라서 내추럴 템플릿 기능이 동작하지 않고, 심지어 렌더링 내용이 주석처리 되어 버린다.
인라인 사용 후 결과를 보면 주석 부분이 제거되고, 기대한 "userA"가 정확하게 적용된다.
객체
타임리프의 자바스크립트 인라인 기능을 사용하면 객체를 JSON으로 자동으로 변환해준다.
var user = [[${user}]];
인라인 사용 전: var user = BasicController.User(username=userA, age=10);
인라인 사용 후: var user = {"username":"userA","age":10};
인라인 사용 전은 객체의 toString()이 호출된 값이다.
인라인 사용 후는 객체를 JSON으로 변환해준다.
컨트롤러
@GetMapping("/javascript")
public String javascript(Model model) {
model.addAttribute("user", new User("userA", 10));
addUsers(model);
return "basic/javascript";
}
타임리프
<!DOCTYPE html>
<html xmlns:th="http://www.thymeleaf.org">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<!-- 자바스크립트 인라인 사용 전 -->
<script>
var username = [[${user.username}]]; <!-- 텍스트를 "로 감싸지 않아서 오류 발생 -->
var age = [[${user.age}]];
//자바스크립트 내추럴 템플릿
var username2 = /*[[${user.username}]]*/ "test username";
//객체
var user = [[${user}]]; <!-- toString()이 호출됨 -->
</script>
<!-- 자바스크립트 인라인 사용 후 -->
<script th:inline="javascript"> <!-- 자바스크립트 문법을 알아서 처리해줌 -->
var username = [[${user.username}]];
var age = [[${user.age}]];
//자바스크립트 내추럴 템플릿
var username2 = /*[[${user.username}]]*/ "test username";
//객체
var user = [[${user}]]; <!-- 인라인 사용 후는 객체를 JSON으로 변환 -->
</script>
<!-- 자바스크립트 인라인 each -->
<script th:inline="javascript"> <!-- 객체를 JSON으로 변환 후 반복 -->
[# th:each="user, stat : ${users}"]
var user[[${stat.count}]] = [[${user}]];
[/]
</script>
</body>
</html>
결과
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<!-- 자바스크립트 인라인 사용 전 -->
<script>
var username = userA; <!-- 텍스트를 "로 감싸지 않아서 오류 발생 -->
var age = 10;
//자바스크립트 내추럴 템플릿
var username2 = /*userA*/ "test username";
//객체
var user = BasicController.User(username=userA, age=10); <!-- toString()이 호출됨 -->
</script>
<!-- 자바스크립트 인라인 사용 후 -->
<script> <!-- 자바스크립트 문법을 알아서 처리해줌 -->
var username = "userA";
var age = 10;
//자바스크립트 내추럴 템플릿
var username2 = "userA";
//객체
var user = {"username":"userA","age":10}; <!-- 인라인 사용 후는 객체를 JSON으로 변환 -->
</script>
<script> <!-- 객체를 JSON으로 변환 후 반복 -->
var user1 = {"username":"userA","age":10};
var user2 = {"username":"userB","age":20};
var user3 = {"username":"userC","age":30};
</script>
</body>
</html>
이 글은 인프런 김영한님의 Spring 강의를 바탕으로 개인적인 정리를 위해 작성한 글입니다.
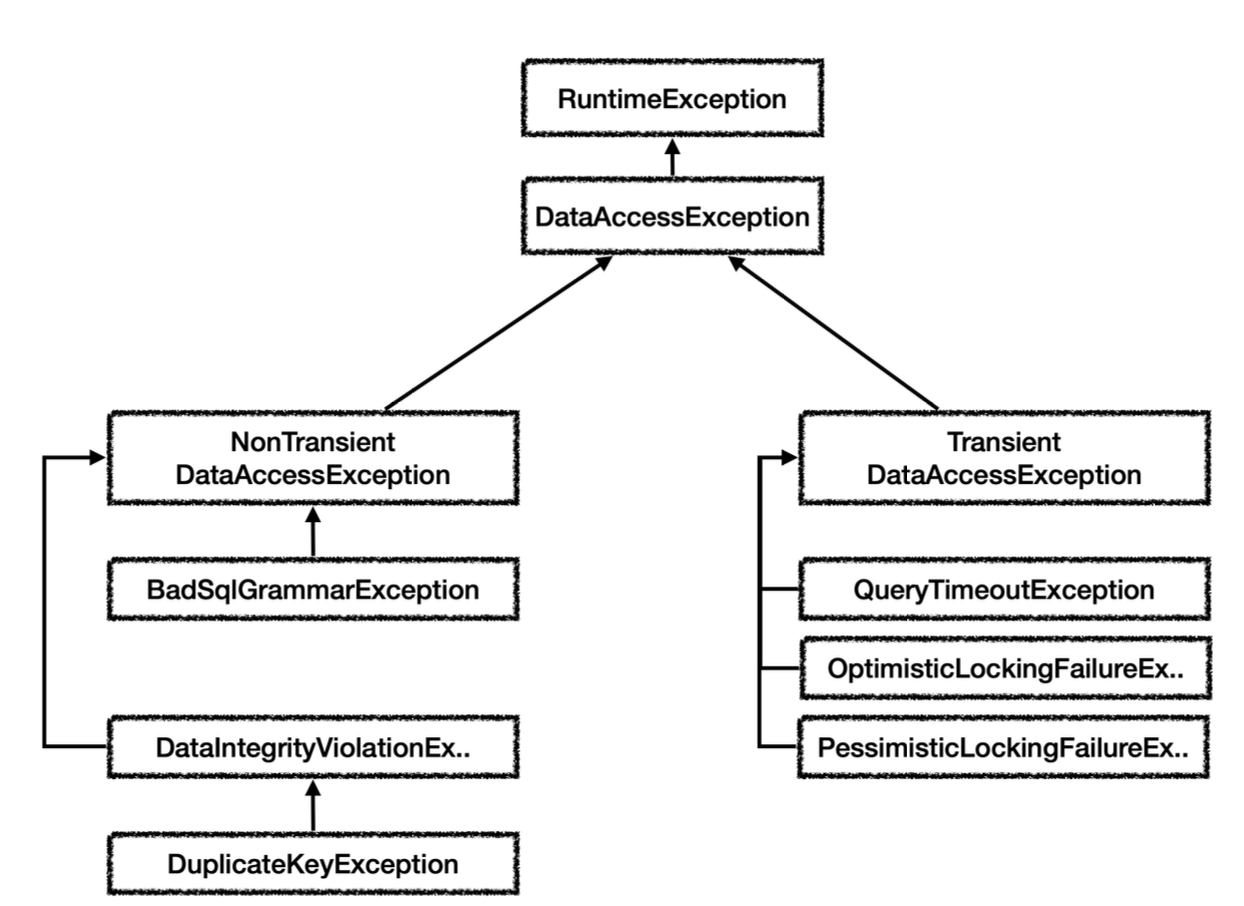
스프링 데이터 접근 예외 계층
스프링은 데이터 접근과 관련된 예외를 추상화해서 제공한다.
그림을 단순화 하기 위해 일부 계층을 생략
스프링은 데이터 접근 계층에 대한 수십 가지 예외를 정리해서 일관된 예외 계층을 제공한다.
각각의 예외는 특정 기술에 종속적이지 않게 설계되어 있다. 따라서 서비스 계층에서도 스프링이 제공하는 예외를 사용하면 된다. 예를 들어서 JDBC 기술을 사용하든, JPA 기술을 사용하든 스프링이 제공하는 예외를 사용하면 된다.
JDBC나 JPA를 사용할 때 발생하는 예외를 스프링이 제공하는 예외로 변환해주는 역할도 스프링이 제공한다.
예외의 최고 상위는 org.springframework.dao.DataAccessException 이다. 그림에서 보는 것 처럼 런타임 예외를 상속 받았기 때문에 스프링이 제공하는 데이터 접근 계층의 모든 예외는 런타임 예외이다.
DataAccessException 은 크게 2가지로 구분하는데 NonTransient 예외와 Transient 예외이다.
Transient 는 일시적이라는 뜻이다. Transient 하위 예외는 동일한 SQL을 다시 시도했을 때 성공할 가능성이 있다. 예를 들어서 쿼리 타임아웃, 락과 관련된 오류들이다. 이런 오류들은 데이터베이스 상태가 좋아지거나, 락이 풀렸을 때 다시 시도하면 성공할 수도 있다.
NonTransient 는 일시적이지 않다는 뜻이다. 같은 SQL을 그대로 반복해서 실행하면 실패한다. SQL 문법 오류, 데이터베이스 제약조건 위배 등이 있다.
스프링 메뉴얼에 모든 예외가 정리되어 있지는 않기 때문에 코드를 직접 열어서 확인해보는 것이 필요하다.
translate() 메서드의 첫번째 파라미터는 읽을 수 있는 설명이고(개발자가 알아보기 쉽게 설정), 두번째는 실행한 sql, 마지막은 발생된 SQLException 을 전달하면 된다. 이렇게 하면 적절한 스프링 데이터 접근 계층의 예외로 변환해서 반환해준다.
예제에서는 SQL 문법이 잘못되었으므로 BadSqlGrammarException 을 반환하는 것을 확인할 수 있다. 눈에 보이는 반환 타입은 최상위 타입인 DataAccessException 이지만 실제로는 BadSqlGrammarException 예외가 반환된다. 마지막에 assertThat() 부분을 확인하자.
참고로 BadSqlGrammarException 은 최상위 타입인 DataAccessException 를 상속 받아서 만들어진다.
스프링은 예외 변환기를 통해서 SQLException 의 ErrorCode 에 맞는 적절한 스프링 데이터 접근 예외로 변환해준다. 만약 서비스, 컨트롤러 계층에서 예외 처리가 필요하면 특정 기술에 종속적인 SQLException 같은 예외를 직접 사용하는 것이 아니라, 스프링이 제공하는 데이터 접근 예외를 사용하면 된다.
스프링 예외 추상화 덕분에 특정 기술에 종속적이지 않게 되었다.
JDBC에서 JPA같은 기술로 변경되어도 예외로 인한 변경을 최소화 할 수 있다. 향후 JDBC에서 JPA로 구현 기술을 변경하더라도, 스프링은 JPA 예외를 적절한 스프링 데이터 접근 예외로 변환해준다.
물론 스프링이 제공하는 예외를 사용하기 때문에 스프링에 대한 기술 종속성은 발생한다.
스프링에 대한 기술 종속성까지 완전히 제거하려면 예외를 모두 직접 정의하고 예외 변환도 직접 하면 되지만, 실용적인 방법은 아니다.
스프링 예외 추상화 적용
public class MemberRepositoryV4_2 implements MemberRepository{
private final DataSource dataSource;
private final SQLExceptionTranslator exTranslator;
public MemberRepositoryV4_2(DataSource dataSource) {
this.dataSource = dataSource;
//SQLExceptionTranslator 인터페이스에 여러가지가 있지만 SQLErrorCodeSQLExceptionTranslator 사용
this.exTranslator = new SQLErrorCodeSQLExceptionTranslator(dataSource);
}
@Override
public Member save(Member member) {
String sql = "insert into member(member_id, money) values(?, ?)";
try {
//데이터베이스 save(저장) 로직
} catch (SQLException e) {
throw exTranslator.translate("save", sql, e); //예외를 던짐
} finally {
close(con, pstmt, null);
}
}
@Override
public Member findById(String memberId) {
String sql = "select * from member where member_id = ?";
try {
//데이터베이스에서 특정 데이터를 찾는 로직
} catch (SQLException e) {
throw exTranslator.translate("findById", sql, e); //예외를 던짐
} finally {
close(con, pstmt, rs);
}
}
...
}
스프링이 예외를 추상화해준 덕분에, 서비스 계층은 특정 리포지토리의 구현 기술과 예외에 종속적이지 않게 할 수 있다.
따라서 서비스 계층은 특정 구현 기술이 변경되어도 그대로 유지할 수 있다. DI를 제대로 활용할 수 있게 된 것이다.
추가로 서비스 계층에서 예외를 잡아서 복구해야 하는 경우, 예외가 스프링이 제공하는 데이터 접근 예외로 변경되어서 서비스 계층에 넘어오기 때문에 필요한 경우 예외를 잡아서 복구하면 된다.
jdbcTemplate(JDBC 반복문제 해결)
JDBC 반복 문제
커넥션 조회, 커넥션 동기화
PreparedStatement 생성 및 파라미터 바인딩 쿼리 실행
결과 바인딩
예외 발생시 스프링 예외 변환기 실행
리소스 종료
데이터 접근 계층의 각각의 메서드에 jdbc 기술이 사용되면 상당히 많은 부분이 반복된다. 이런 반복을 효과적으로 처리하는 방법이 바로 템플릿 콜백 패턴이다.
스프링은 JDBC의 반복 문제를 해결하기 위해 JdbcTemplate이라는 템플릿을 제공한다.
@Slf4j
public class MemberRepositoryV5 implements MemberRepository {
private final JdbcTemplate template;
public MemberRepositoryV5(DataSource dataSource) {
template = new JdbcTemplate(dataSource);
}
@Override
public Member save(Member member) {
String sql = "insert into member(member_id, money) values(?, ?)";
template.update(sql, member.getMemberId(), member.getMoney());
//template.update()는 변경된 row 수를 리턴한다.
return member;
}
@Override
public Member findById(String memberId) {
String sql = "select * from member where member_id = ?";
return template.queryForObject(sql, memberRowMapper(), memberId); //주의
//select 문으로 객체를 반환할 때, 콜백 패턴으로 따로 처리를 해줘야 한다.
}
@Override
public void update(String memberId, int money) {
String sql = "update member set money=? where member_id=?";
template.update(sql, money, memberId);
}
@Override
public void delete(String memberId) {
String sql = "delete from member where member_id=?";
template.update(sql, memberId);
}
private RowMapper<Member> memberRowMapper() {
return (rs, rowNum) -> { //콜백패턴
Member member = new Member();
member.setMemberId(rs.getString("member_id"));
member.setMoney(rs.getInt("money"));
return member;
};
}
}
이 코드는 스프링 프레임워크의 JdbcTemplate 클래스의 인스턴스인 template을 사용하여 데이터베이스에서 단일 객체를 조회하는 것이다. 이 구문에서 사용되는 메서드와 매개변수의 역할은 다음과 같다.
template은 JdbcTemplate의 인스턴스이다. JdbcTemplate은 스프링이 제공하는 클래스로, JDBC를 통해 데이터베이스에 접근하여 작업을 수행할 때 반복되는 코드와 예외 처리를 간소화하는 역할을 한다.
queryForObject 메서드는 SQL 쿼리를 실행하여 결과로 반환되는 단일 객체를 조회하는 메서드이다. 이 메서드는 쿼리 결과가 정확히 하나의 객체만을 반환해야 한다. 반환되는 객체의 수가 하나가 아닌 경우 IncorrectResultSizeDataAccessException 예외가 발생한다.
sql은 데이터베이스에서 실행할 SQL 쿼리 문자열이다.
memberRowMapper()는 결과 행을 객체로 매핑하는 역할을 하는 RowMapper 인터페이스의 구현체를 반환하는 메서드이다. RowMapper는 SQL 쿼리의 결과로 얻어진 ResultSet의 각 행을 객체로 변환하는 방법을 정의한다.
memberId는 SQL 쿼리에서 사용할 매개변수이다. 이 경우, memberId는 조회하고자 하는 멤버의 식별자로 사용된다.
private RowMapper<Member> memberRowMapper() {
return (rs, rowNum) -> { //콜백패턴
Member member = new Member();
member.setMemberId(rs.getString("member_id"));
member.setMoney(rs.getInt("money"));
return member;
};
}
위 코드는 데이터베이스로부터 Member 객체를 조회하기 위한 RowMapper<Member> 구현체를 제공하는 메서드이다. RowMapper 인터페이스는 JDBC ResultSet의 각 행을 객체로 매핑하는 역할을 한다. 이 코드는 콜백 패턴을 사용하여, SQL 쿼리의 결과로 얻어진 ResultSet에서 데이터를 읽어 Member 객체를 생성하고 반환하는 과정을 정의한다.
private RowMapper<Member> memberRowMapper() 메서드는 RowMapper<Member> 타입의 객체를 반환한다. 이 객체는 ResultSet에서 데이터를 읽어 Member 객체로 변환하는 방법을 정의한다.
(rs, rowNum) -> 람다 표현식을 사용하여 RowMapper의 mapRow 메서드를 구현한다. 여기서 rs는 쿼리 결과로 얻어진 ResultSet 객체이고, rowNum은 현재 행의 번호이다.
Member member = new Member(); 새로운 Member 객체를 생성한다.
member.setMemberId(rs.getString("member_id")); ResultSet에서 "member_id" 컬럼의 값을 읽어 Member 객체의 memberId 필드에 설정한다.
member.setMoney(rs.getInt("money")); ResultSet에서 "money" 컬럼의 값을 읽어 Member 객체의 money 필드에 설정한다.
return member; 매핑된 Member 객체를 반환한다.
JdbcTemplate 은 JDBC로 개발할 때 발생하는 반복을 대부분 해결해준다.
그 뿐만 아니라 트랜잭션을 위한 커넥션 동기화는 물론이고, 예외 발생시 스프링 예외 변환기도 자동으로 실행해준다.
이 글은 인프런 김영한님의 Spring 강의를 바탕으로 개인적인 정리를 위해 작성한 글입니다.
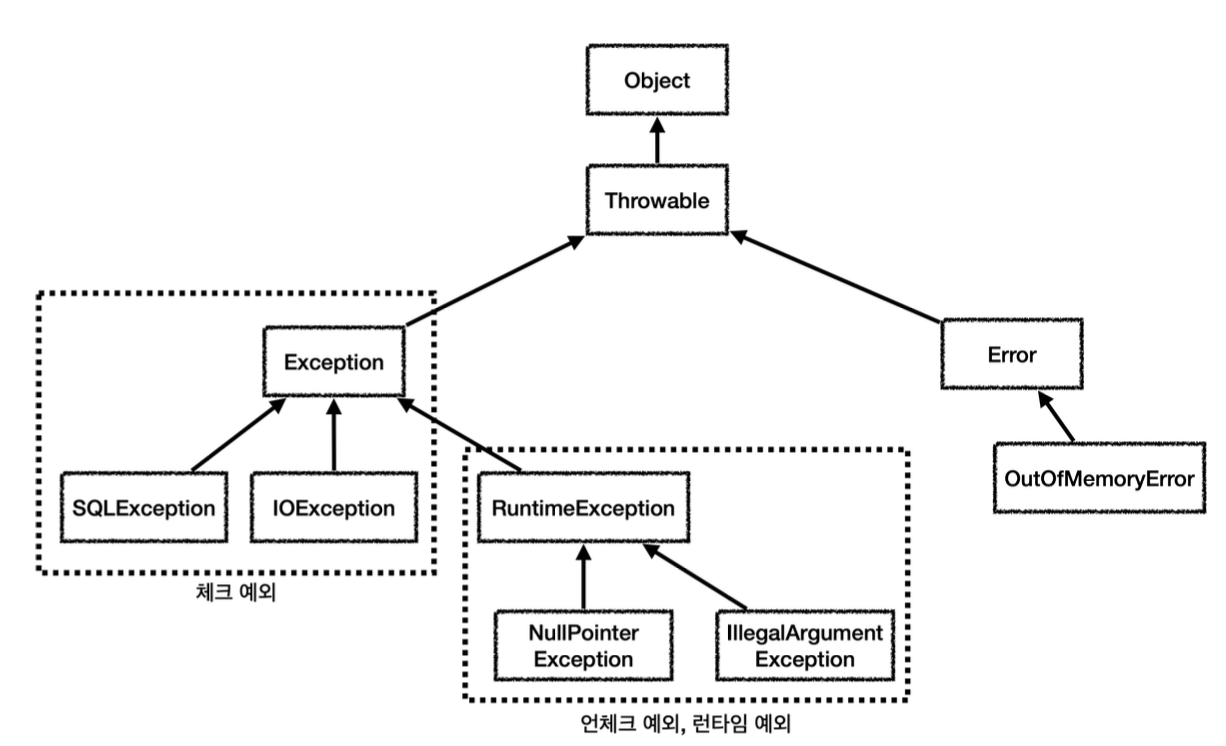
예외 계층과 체크, 언체크 예외
Object : 예외도 객체이다. 모든 객체의 최상위 부모는 Object이므로 예외의 최상위 부모도 Object이다.
Throwable: 최상위 예외이다. 하위에 Exception과 Error가 있다. 이 예외를 잡으면 Error 까지 잡기 때문에 Exception 예외부터 잡는다.
Error: 메모리 부족이나 심각한 시스템 오류와 같이 애플리케이션에서 복구 불가능한 시스템 예외이다. 개발자는 이 예외를 잡을 필요가 없다.
Exception: 체크 예외 애플리케이션 로직에서 사용할 수 있는 실질적인 최상위 예외이다. 이 예외를 상속받으면 체크 예외가 된다.
Exception과 그 하위 예외는 모두 컴파일러가 체크하는 체크 예외이다. 단 RuntimeException은 예외로 한다.
RuntimeException: 컴파일러가 체크하지 않는 언체크 예외이다. RuntimeException과 그 자식 예외는 모두 언체크 예외이다. RuntimeException의 이름을 따라서 RuntimeException과 그 하위 언체크 예외를 런타임 예외라고 많이 부른다. 이 예외를 상속받으면 언체크 예외가 된다.
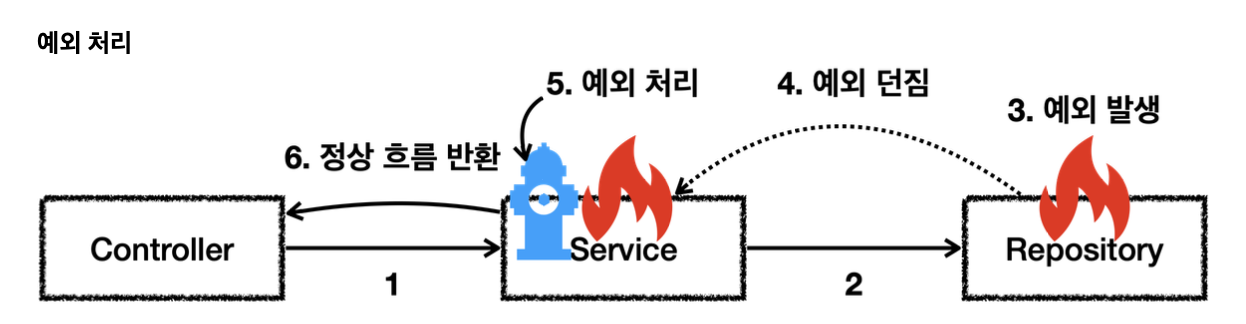
예외 기본 규칙
5번에서 예외를 처리하면 이후에는 애플리케이션 로직이 정상 흐름으로 동작한다.
예외를 처리하지 못하면 호출한 곳으로 예외를 계속 던지게 된다.
예외는 잡아서 처리하거나 던져야 한다. 예외를 잡거나 던질 때 지정한 예외뿐만 아니라 그 예외의 자식들도 함께 처리된다.
상위 예외를 catch 로 잡으면 그 하위 예외들도 모두 잡을 수 있다.
상위 예외를 throws 로 던지면 그 하위 예외들도 모두 던질 수 있다.
예외를 처리하지 못하고 계속 던지면 어떻게 될까?
자바 main() 쓰레드의 경우 예외 로그를 출력하면서 시스템이 종료된다. 웹 애플리케이션의 경우 여러 사용자의 요청을 처리하기 때문에 하나의 예외 때문에 시스템이 종료되면 안된다. WAS가 해당 예외를 받아서 처리하는데, 주로 사용자에게 개발자가 지정한, 오류 페이지를 보여준다.
체크 예외
Exception 과 그 하위 예외는 모두 컴파일러가 체크하는 체크 예외이다. 단 RuntimeException 은 예외로 한다. 체크 예외는 잡아서 처리하거나, 또는 밖으로 던지도록 선언해야한다. 그렇지 않으면 컴파일 오류가 발생한다.
체크 예외는 예외를 잡아서 처리할 수 없을 때, 예외를 밖으로 던지는 throws 예외 를 필수로 선언해야 한다. 그렇지 않으면 컴파일 오류가 발생한다. 이것 때문에 장점과 단점이 동시에 존재한다.
장점: 개발자가 실수로 예외를 누락하지 않도록 컴파일러를 통해 문제를 잡아주는 안전 장치이다.
단점: 실제로는 개발자가 모든 체크 예외를 반드시 잡거나 던지도록 처리해야 하기 때문에, 너무 번거로운 일이 된다. 크게 신경쓰고 싶지 않은 예외까지 모두 챙겨야 한다. 또한 신경 쓰고 싶지 않은 예외의 의존관계를 참조해야한다는 점도 있다.
기본적으로 언체크(런타임) 예외를 사용하는 것이 좋다.
체크 예외는 비즈니스 로직상 의도적으로 던지는 예외에만 사용하는 것이 좋다. 이 경우 해당 예외를 잡아서 반드시 처리해야 하는 문제일 때만 체크 예외를 사용해야 한다.
예를 들어서 다음과 같은 경우가 있다.
계좌 이체 실패 예외
결제시 포인트 부족 예외
로그인 ID, PW 불일치 예외
물론 이 경우에도 100% 체크 예외로 만들어야 하는 것은 아니다. 다만 계좌 이체 실패처럼 매우 심각한 문제는 개발자가 실수로 예외를 놓치면 안된다고 판단할 수 있다.
이 경우 체크 예외로 만들어 두면 컴파일러 를 통해 놓친 예외를 인지할 수 있다.
체크예외의 문제점
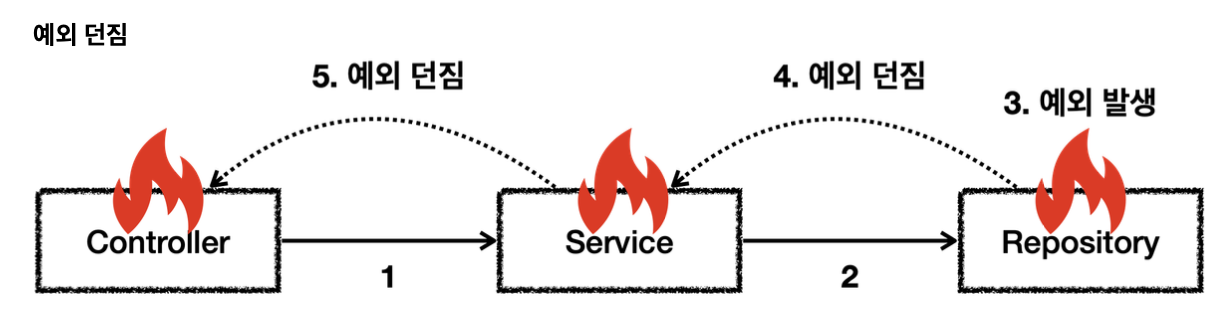
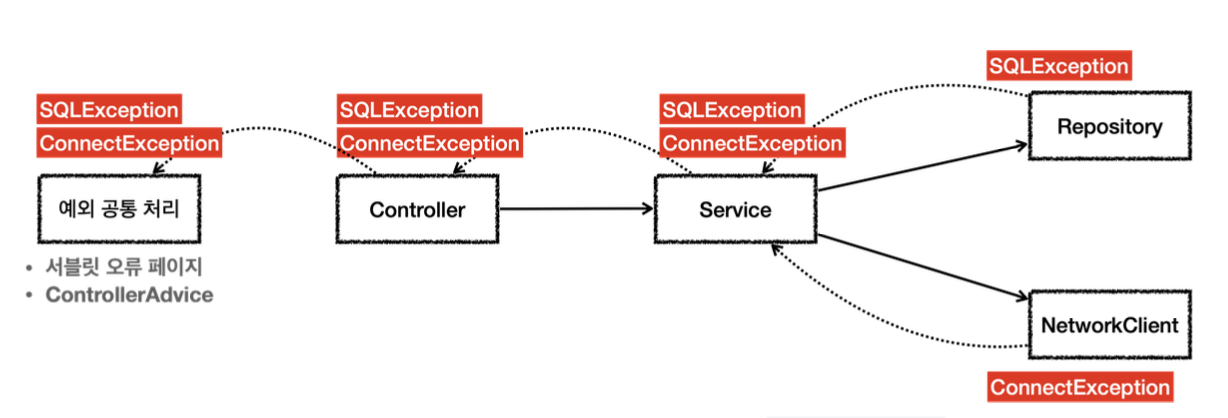
리포지토리는 DB에 접근해서 데이터를 저장하고 관리한다.여기서 SQLException 체크 예외를 던진다. NetworkClient는 외부 네트워크에 접속해서 어떤 기능을 처리하는 객체이다. 여기서는 ConnectException 체크 예외를 던진다.
서비스는 리포지토리와 NetworkClient를 둘다 호출한다. 따라서 두 곳에서 올라오는 체크 예외인 SQLException과 ConnectException을 처리해야 한다.
그런데 서비스는 이 둘을 처리할 방법을 모른다. ConnectException처럼 연결이 실패하거나, SQLException처럼 데이터베이스에서 발생하는 문제처럼 심각한 문제들은 대부분 애플리케이션 로직에서 처리할 방법이 없다. 서비스는 SQLException과 ConnectException을 처리할 수 없으므로 둘다 밖으로 던진다.
컨트롤러도 두 예외를 처리할 방법이 없다. 따라서 컨트롤러도 예외를 밖으로 던진다.
최종적으로 웹 애플리케이션이라면 서블릿의 오류 페이지나, 또는 스프링 MVC가 제공하는 ControllerAdvice에서 이런 예외를 공통으로 처리한다.
위 예시에서 체크 예외를 사용하면 2가지 문제가 있다.
복구 불가능한 예외
의존 관계에 대한 문제
복구 불가능한 예외
대부분의 서비스나 컨트롤러는 데이터베이스에서 발생한 문제 또는 네트워크 통신처럼 시스템 레벨에서 올라온 예외를 해결할 수 없다. 따라서 이런 문제들은 일관성 있게 공통으로 처리해야 한다.
오류 로그를 남기고 개발자가 해당 오류를 빠르게 인지하는 것이 필요하다. 서블릿 필터, 스프링 인터셉터, 스프링의 ControllerAdvice 를 사용하면 이런 부분을 깔끔하게 공통으로 해결할 수 있다.
의존관계에 대한 문제
시스템 레벨에서 발생한 예외는 복구 불가능한 예외이다. 그런데 체크 예외이기 때문에 컨트롤러나 서비스 입장에서는 본인이 처리할 수 없어도 어쩔 수 없이 throws를 통해 던지는 예외를 선언해야 한다.
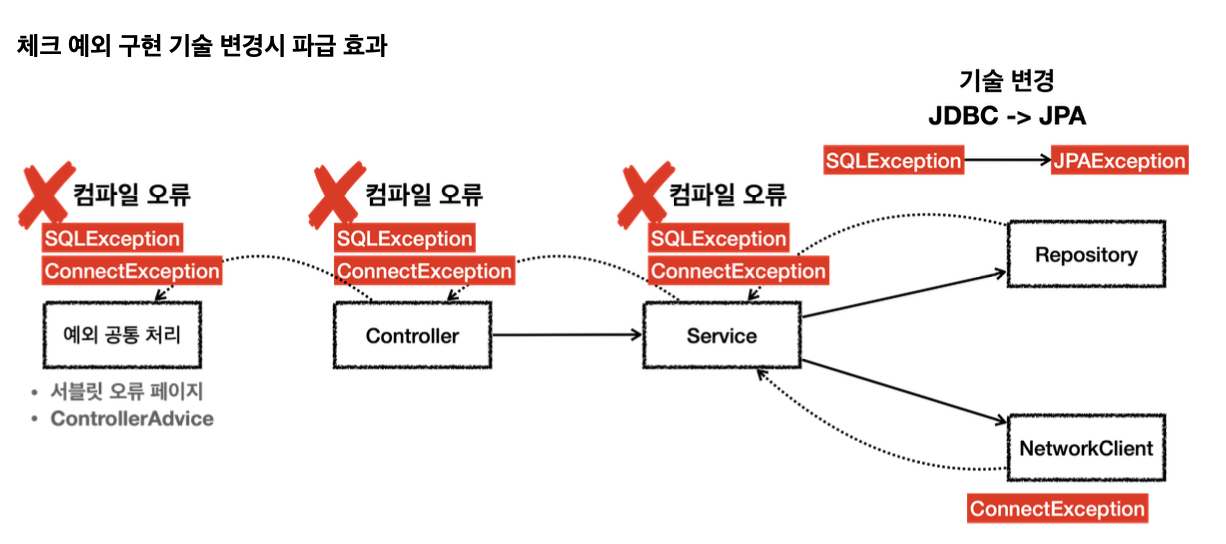
서비스, 컨트롤러에서 java.sql.SQLException을 의존하기 때문에 문제가 된다. 향후 리포지토리를 JDBC 기술이 아닌 다른 기술로 변경한다면, 그래서 SQLException이 아니라 예를 들어서 JPAException으로 예외가 변경된다면 SQLException에 의존하던 모든 서비스, 컨트롤러의 코드를 JPAException에 의존하도록 고쳐야 한다.
서비스나 컨트롤러 입장에서는 어차피 본인이 처리할 수도 없는 예외를 의존해야 하는 큰 단점이 발생하게 된다. 결과적으로 OCP, DI를 통해 클라이언트 코드의 변경 없이 대상 구현체를 변경할 수 있다는 장점이 체크 예외 때문에 발목을 잡게 된다.
throws Exceotion
체크 예외의 최상위 타입인 Exception 을 던지게 되면 다른 체크 예외를 체크할 수 있는 기능이 무효화 되고, 중요한 체크 예외를 다 놓치게 된다. 중간에 중요한 체크 예외가 발생해도 컴파일러는 Exception 을 던지기 때 문에 문법에 맞다고 판단해서 컴파일 오류가 발생하지 않는다. 이렇게 하면 모든 예외를 다 던지기 때문에 체크 예외를 의도한 대로 사용하는 것이 아니다. 따라서 꼭 필요한 경우가 아니면 이렇게 Exception 자체를 밖으로 던지는 것은 좋지 않은 방법이다.
언체크 예외
RuntimeException 과 그 하위 예외는 언체크 예외로 분류된다. 언체크 예외는 말 그대로 컴파일러가 예외를 체크하지 않는다는 뜻이다. 언체크 예외는 체크 예외와 기본적으로 동일하다. 차이가 있다면 예외를 던지는 throws 를 선언하지 않고, 생략 할 수 있다. 이 경우 자동으로 예외를 던진다.
언체크 예외는 예외를 잡아서 처리 할 수 없을 때,예외를 밖으로 던지는 throws 예외를 생략 할 수 있다. 이것때문에 장점과 단점이 동시에 존재한다.
장점: 신경쓰고 싶지 않은 언체크 예외를 무시할 수 있다. 체크 예외의 경우 처리할 수 없는 예외를 밖으로 던지려 면 항상 throws 예외 를 선언해야 하지만, 언체크 예외는 이 부분을 생략할 수 있다. 또한 신경 쓰고 싶지 않은 예외의 의존관계를 참조하지 않아도 되는 장점이 있다.
단점: 언체크 예외는 개발자가 실수로 예외를 누락할 수 있다. 반면에 체크 예외는 컴파일러를 통해 예외 누락을 잡아준다.
체크 예외에서의 문제점 해결
@Slf4j
public class UncheckedAppTest {
@Test
void unchecked() {
Controller controller = new Controller();
assertThatThrownBy(() -> controller.request())
.isInstanceOf(Exception.class);
}
@Test
void printEx() {
Controller controller = new Controller();
try {
controller.request();
} catch (Exception e) {
//e.printStackTrace();
log.info("ex", e);
}
}
static class Controller {
Service service = new Service();
public void request() {
service.logic();
}
}
static class Service {
Repository repository = new Repository();
NetworkClient networkClient = new NetworkClient();
public void logic() {
repository.call();
networkClient.call();
}
}
static class NetworkClient {
public void call() {
throw new RuntimeConnectException("연결 실패");
}
}
static class Repository {
public void call() {
try {
runSQL();
} catch (SQLException e) {
throw new RuntimeSQLException(e);
}
}
private void runSQL() throws SQLException {
throw new SQLException("ex");
}
}
static class RuntimeConnectException extends RuntimeException {
public RuntimeConnectException(String message) {
super(message);
}
}
static class RuntimeSQLException extends RuntimeException {
public RuntimeSQLException() {
}
public RuntimeSQLException(Throwable cause) {
super(cause);
/*
Throwable 타입의 인자 cause를 받는다.
이 생성자 내부에서 super(cause);를 호출함으로써, 받아온 원인 예외 cause를 상위 클래스인 RuntimeException의 생성자로 전달한다.
이 과정을 통해 RuntimeSQLException 인스턴스가 생성될 때, 그 원인이 되는 예외를 포함하게 된다.
이렇게 예외를 포함시키는 방식은 예외의 원인을 추적하는 데 매우 유용하다.
예외가 발생했을 때 스택 트레이스에서 이 원인 예외 정보를 함께 확인할 수 있어, 예외 처리와 디버깅에 도움이 된다.
*/
}
}
}
위 코드를 그림으로 나타내면 아래와 같다.
SQLException 을 런타임 예외인 RuntimeSQLException 으로 변환했다.
ConnectException 대신에 RuntimeConnectException 을 사용하도록 바꾸었다.
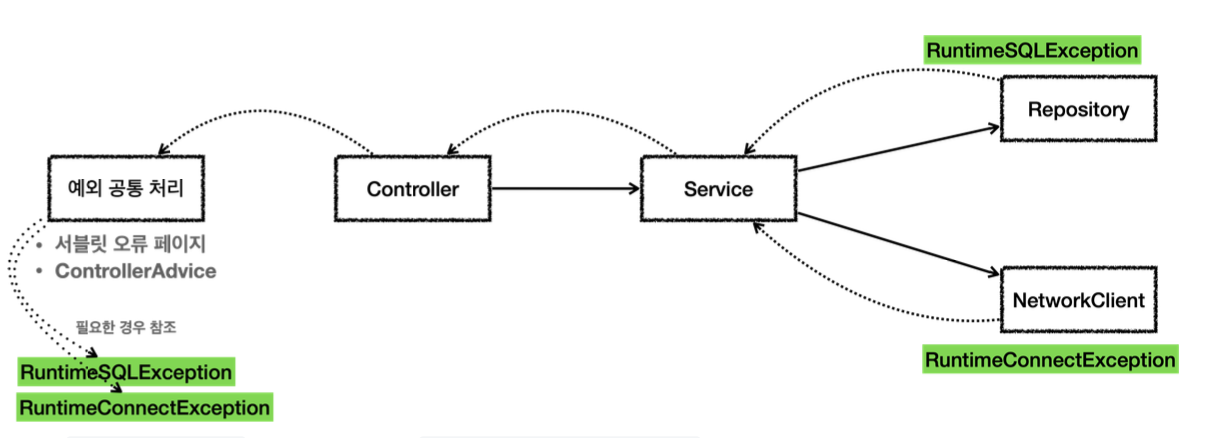
런타임 예외이기 때문에 서비스, 컨트롤러는 해당 예외들을 처리할 수 없다면 별도의 선언 없이 그냥 두면 된다.
예외 전환
리포지토리에서 체크 예외인 SQLException이 발생하면 런타임 예외인 RuntimeSQLException으로 전환해서 예외를 던진다. 참고로 이때 기존 예외를 포함해주어야 예외 출력시 스택 트레이스에서 기존 예외도 함께 확인할 수 있다. NetworkClient는 단순히 기존 체크 예외를 RuntimeConnectException이라는 런타임 예외가 발생하도록 코드를 바꾸었다.
런타임 예외 - 대부분 복구 불가능한 예외
시스템에서 발생한 예외는 대부분 복구 불가능 예외이다. 런타임 예외를 사용하면 서비스나 컨트롤러가 이런 복구 불가능한 예외를 신경쓰지 않아도 된다. 물론 이렇게 복구 불가능한 예외는 일관성 있게 공통으로 처리해야 한다.
런타임 예외 - 의존 관계에 대한 문제
런타임 예외는 해당 객체가 처리할 수 없는 예외는 무시하면 된다. 따라서 체크 예외처럼 예외를 강제로 의존하지 않아도 된다.
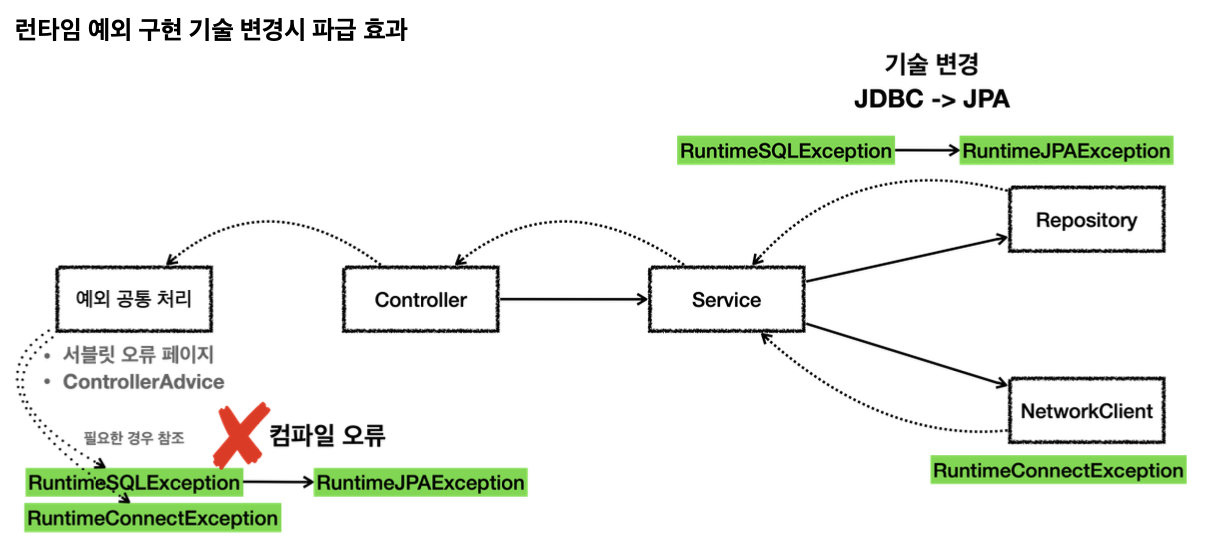
런타임 예외를 사용하면 중간에 기술이 변경되어도 해당 예외를 사용하지 않는 컨트롤러, 서비스에서는 코드를 변경하지 않아도 된다. 구현 기술이 변경되는 경우, 예외를 공통으로 처리하는 곳에서는 예외에 따른 다른 처리가 필요할 수 있다.
로그를 출력할 때 마지막 파라미터에 예외를 넣어주면 로그에 스택 트레이스를 출력할 수 있다.
예) log.info("message={}", "message", ex) , 여기에서 마지막에 ex를 전달하는 것을 확인할 수 있다.
이렇게 하면 스택 트레이스에 로그를 출력할 수 있다.
예) log.info("ex", ex) 이 예시에서는 파라미터가 없기 때문에, 예외만 파라미터에 전달하면 스택 트레이스를 로그에 출력할 수 있다. System.out 에 스택 트레이스를 출력하려면 e.printStackTrace() 를 사용하면 된다.
예외를 전환할 때는 꼭 기존 예외를 포함해야 한다. 그렇지 않으면 스택 트레이스를 확인할 때 심각한 문제가 발생한다.
기존 예외를 포함하는 경우
public void call() {
try {
runSQL();
} catch (SQLException e) {
throw new RuntimeSQLException(e); //기존 예외(e) 포함
}
}
기존 예외를 포함해야 실제로 시스템에서 발생한 오류의 원인을 확인할 수 있다.
기존 예외를 포함하지 않는 경우 -> 이렇게 사용하면 안됨
public void call() {
try {
runSQL();
} catch (SQLException e) {
throw new RuntimeSQLException(); //기존 예외(e) 제외
}
}
static class RuntimeSQLException extends RuntimeException {
public RuntimeSQLException() {
}
public RuntimeSQLException(Throwable cause) {
super(cause);
/*
Throwable 타입의 인자 cause를 받는다.
이 생성자 내부에서 super(cause);를 호출함으로써, 받아온 원인 예외 cause를 상위 클래스인 RuntimeException의 생성자로 전달한다.
이 과정을 통해 RuntimeSQLException 인스턴스가 생성될 때, 그 원인이 되는 예외를 포함하게 된다.
이렇게 예외를 포함시키는 방식은 예외의 원인을 추적하는 데 매우 유용하다.
예외가 발생했을 때 스택 트레이스에서 이 원인 예외 정보를 함께 확인할 수 있어, 예외 처리와 디버깅에 도움이 된다.
*/
}
}
스프링 부트가 기본으로 생성하는 데이터소스는 커넥션풀을 제공하는 HikariDataSource 이다.
커넥션풀과 관련된 설정도 application.properties 를 통해서 지정할 수 있다.
spring.datasource.url 속성이 없으면 내장 데이터베이스(메모리 DB)를 생성하려고 시도한다.
트랜잭션 매니저 - 자동 등록
스프링 부트는 적절한 트랜잭션 매니저( PlatformTransactionManager )를 자동으로 스프링 빈에 등록한다.
자동으로 등록되는 스프링 빈 이름: transactionManager
참고로 개발자가 직접 트랜잭션 매니저를 빈으로 등록하면 스프링 부트는 트랜잭션 매니저를 자동으로 등록하지 않는다.
어떤 트랜잭션 매니저를 선택할지는 현재 등록된 라이브러리를 보고 판단하는데, JDBC를 기술을 사용하면 DataSourceTransactionManager 를 빈으로 등록하고, JPA를 사용하면 JpaTransactionManager 를 빈으 로 등록한다. 둘다 사용하는 경우 JpaTransactionManager 를 등록한다.
JpaTransactionManager 는 DataSourceTransactionManager 가 제공하는 기능도 대부분 지원하기 때문이다.
정리
데이터소스와 트랜잭션 매니저는 스프링 부트가 제공하는 자동 빈 등록 기능을 사용하는 것이 편리하다.
추가로 application.properties 를 통해 설정도 편리하게 할 수 있다.
이전에 보았던 코드는 스프링 부트가 자동으로 데이터소스와 트랜잭션 매니저 빈을 등록해주기 때문에 아래와 같이 관련 부분은 등록을 안해도 된다.
@SpringBootTest
class MemberServiceV3_3Test {
@Autowired
MemberRepositoryV3 memberRepository;
@Autowired
MemberServiceV3_3 memberService;
@TestConfiguration
static class TestConfig {
@Bean
MemberRepositoryV3 memberRepositoryV3() {
return new MemberRepositoryV3(dataSource());
}
@Bean
MemberServiceV3_3 memberServiceV3_3() {
return new MemberServiceV3_3(memberRepositoryV3());
}
}
}
이 글은 인프런 김영한님의 Spring 강의를 바탕으로 개인적인 정리를 위해 작성한 글입니다.
트랜잭션 AOP(Aspect-Oriented Programming)는 스프링 프레임워크가 트랜잭션 관리를 위해 제공하는 선언적 트랜잭션 관리 방식이다. 이 방법을 통해 개발자는 비즈니스 로직과 트랜잭션 관리 코드를 분리할 수 있으며, 이로 인해 코드의 가독성과 유지보수성이 크게 향상된다. 스프링에서는 @Transactional 어노테이션을 사용하여 클래스나 메소드 레벨에서 트랜잭션을 선언적으로 관리할 수 있게 한다.
트랜잭션 AOP의 특징은 아래와 같다
@Transactional 어노테이션 사용: 개발자는 트랜잭션을 적용하고자 하는 메소드나 클래스에 @Transactional 어노테이션을 붙인다. 이 어노테이션은 스프링에게 해당 메소드나 클래스의 실행을 트랜잭션 경계로 관리하도록 지시한다.
프록시 기반의 AOP: 스프링은 @Transactional 어노테이션이 붙은 대상 객체를 대신하여 프록시 객체를 생성한다. 이 프록시 객체는 실제 객체의 메소드 호출을 가로채 트랜잭션을 시작하고, 메소드 실행이 성공적으로 완료되면 트랜잭션을 커밋하거나, 예외가 발생하면 롤백한다.
트랜잭션 매니저 연동: 스프링의 트랜잭션 AOP는 PlatformTransactionManager 인터페이스 구현체와 연동하여 트랜잭션을 관리한다. JDBC, Hibernate, JPA 등 다양한 데이터 액세스 기술에 맞는 트랜잭션 매니저를 설정할 수 있다.
트랜잭션 AOP를 사용함으로써 개발자는 복잡한 트랜잭션 관리 로직을 작성할 필요 없이, 비즈니스 로직에만 집중할 수 있다.또한, @Transactional 어노테이션을 통해 선언적으로 트랜잭션 관리를 할 수 있어, 코드의 가독성과 유지보수성이 크게 향상된다.
프록시를 도입하지 않으면 서비스 계층의 로직에서 트랜잭션을 직접 시작한다.
public void accountTransfer(String fromId, String toId, int money) throws SQLException {
TransactionStatus status = transactionManager.getTransaction(new DefaultTransactionDefinition()); //트랜잭션 시작
try {
bizLogic(fromId, toId, money); //비즈니스 로직
transactionManager.commit(status); //성공시 커밋
} catch (Exception e) {
transactionManager.rollback(status); //실패시 롤백
throw new IllegalStateException(e);
}
}
프록시를 사용하면 트랜잭션을 처리하는 객체와 비즈니스 로직을 처리하는 서비스 객체를 명확하게 분리할 수 있다.
@Transactional
public void accountTransfer(String fromId, String toId, int money) throws SQLException {
bizLogic(fromId, toId, money);
}
프록시 도입 전: 서비스에 비즈니스 로직과 트랜잭션 처리 로직이 함께 섞여있다.
프록시 도입 후: 트랜잭션 프록시가 트랜잭션 처리 로직을 모두 가져간다. 그리고 트랜잭션을 시작한 후에 실제 서 비스를 대신 호출한다. 트랜잭션 프록시 덕분에 서비스 계층에는 순수한 비즈니즈 로직만 남길 수 있다.
@Transactional 애노테이션은 메서드에 붙여도 되고, 클래스에 붙여도 된다. 클래스에 붙이면 외부에서 호출 가능한 public 메서드가 AOP 적용 대상이 된다.
프록시의 간단한 원리
스프링 AOP는 프록시 패턴을 기반으로 한다. 이는 스프링 컨테이너가 @Transactional 어노테이션이 붙은 클래스의 객체를 생성할 때, 원본 객체 대신 트랜잭션 로직을 추가로 갖는 프록시 객체를 생성하고, 이 프록시 객체가 원본 객체를 감싸는 구조이다. 이 프록시 객체는 원본 객체의 모든 메소드 호출을 가로채 트랜잭션 관리 기능을 수행한다.
트랜잭션 AOP를 사용할 때, 트랜잭션 매니저 관련 메소드들은 자동으로 실행된다. 이는 스프링 프레임워크가 @Transactional 어노테이션을 분석하고, 해당 어노테이션이 붙은 메소드를 실행할 때 자동으로 트랜잭션 경계를 설정하기 때문이다. 사용자는 복잡한 트랜잭션 관리 로직을 직접 작성할 필요 없이, 선언적으로 트랜잭션 관리를 할 수 있다.
트랜잭션 시작: @Transactional이 붙은 메소드 호출 시, 스프링 AOP는 먼저 PlatformTransactionManager를 사용하여 트랜잭션을 시작한다. 이 과정에서 getTransaction() 메소드가 내부적으로 호출되며, 필요한 트랜잭션 설정(전파 방식, 격리 수준 등)을 적용한다.
비즈니스 로직 실행: 트랜잭션이 시작된 후, 실제 비즈니스 로직이 있는 메소드의 내용이 실행된다.
트랜잭션 커밋 또는 롤백: 비즈니스 로직의 실행이 성공적으로 마무리되면, 스프링 AOP는 PlatformTransactionManager를 통해 트랜잭션을 커밋한다. 이때 commit() 메소드가 호출된다. 만약 실행 도중 예외가 발생하면, 스프링은 rollback() 메소드를 호출하여 트랜잭션을 롤백한다.
트랜잭션 매니저 관련 메소드들이 자동으로 실행될 때, 데이터 소스는 스프링의 의존성 주입(Dependency Injection, DI) 기능을 통해 자동으로 주입된다.
트랜잭션 프록시 코드 예시
public class TransactionProxy {
private MemberService target;
public void logic() { //트랜잭션 시작
TransactionStatus status = transactionManager.getTransaction(..);
try {
target.logic();//실제 대상 호출
transactionManager.commit(status); //성공시 커밋
} catch (Exception e) {
transactionManager.rollback(status); //실패시 롤백
throw new IllegalStateException(e);
}
}
}
public class Service {
public void logic() {
bizLogic(fromId, toId, money);//트랜잭션 관련 코드 제거, 순수 비즈니스 로직만 남음
}
}
참고
스프링 AOP를 적용하려면 어드바이저, 포인트컷, 어드바이스가 필요하다. 스프링은 트랜잭션 AOP 처리를 위해 다음 클래스를 제공한다. 스프링 부트를 사용하면 해당 빈들은 스프링 컨테이너에 자동으로 등록된다. 어드바이저: BeanFactoryTransactionAttributeSourceAdvisor 포인트컷: TransactionAttributeSourcePointcut 어드바이스: TransactionInterceptor