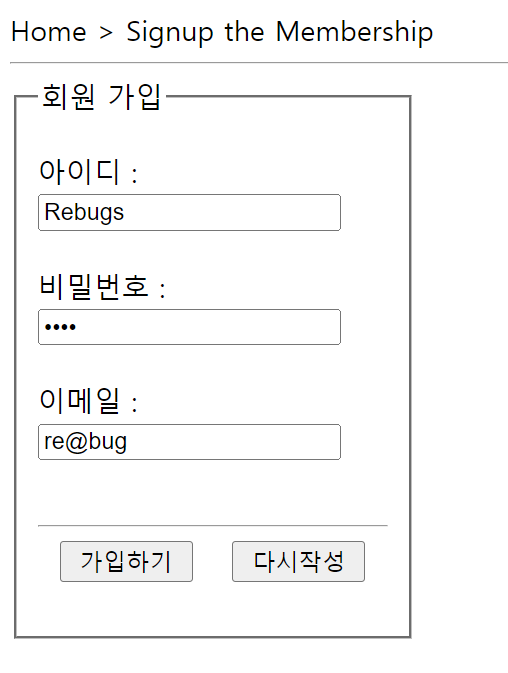
이 글은 혼자 공부하는 SQL(저자 : 우재남)의 책과 유튜브 영상을 참고하여 개인적으로 정리하는 글임을 알립니다.
테이블은 표 형태로 구성된 2차원 구조로, 행과 열로 구성되어 있다.
행은 row나 recode라고 부르며, 열은 column 또는 field라고 부른다.
테이블을 생성하기 전에 테이블의 구조를 정의해야 한다.
데이터 형식을 활용해서 각 열에 가장 적합한 데이터 형식을 지정한다.
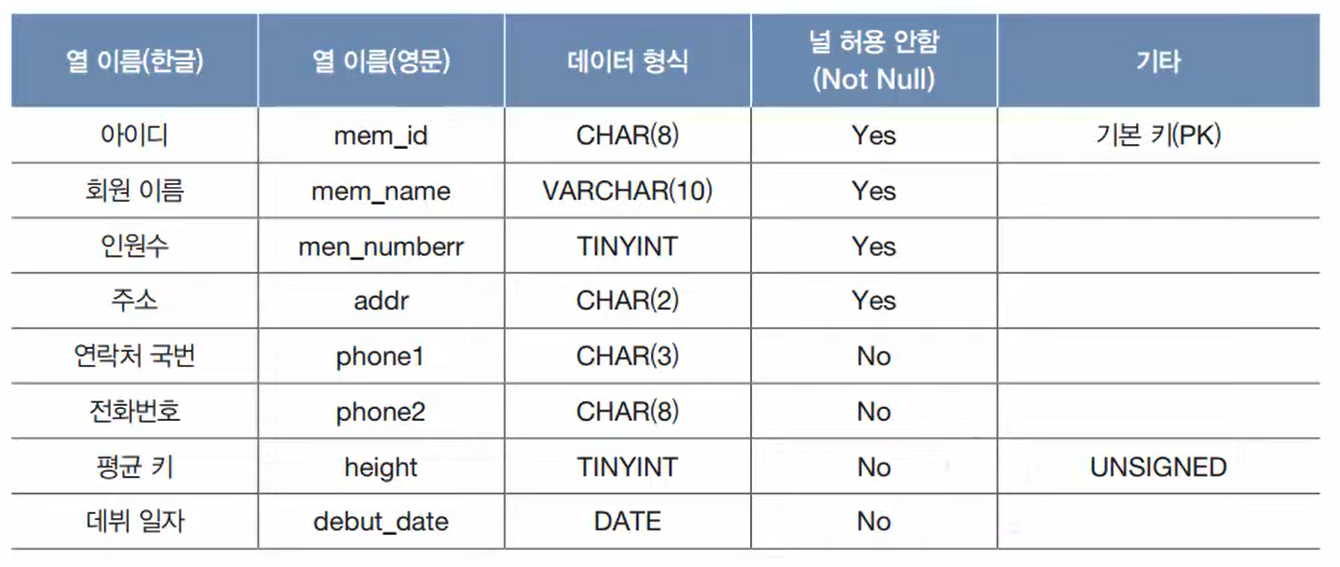
회원 테이블 생성 SQL
CREATE TABLE member -- 회원 테이블
( mem_id CHAR(8) NOT NULL PRIMARY KEY,
mem_name VARCHAR(10) NOT NULL,
mem_number TINYINT NOT NULL,
addr CHAR(2) NOT NULL,
phone1 CHAR(3) NULL,
phone2 CHAR(8) NULL,
height TINYINT UNSIGNED NULL,
debut_date DATE NULL
);
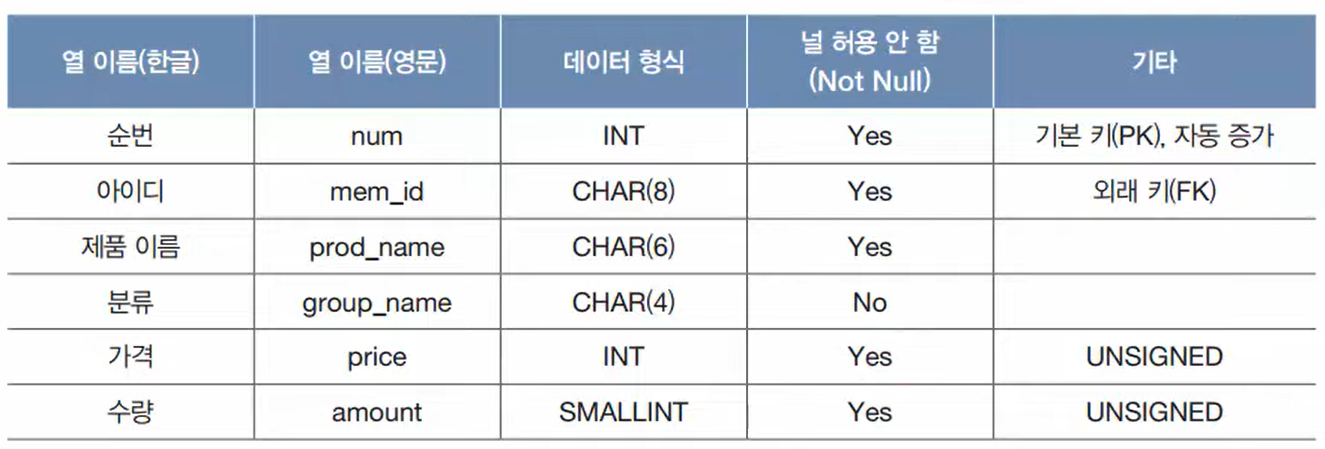
구매 테이블 생성 SQL
CREATE TABLE buy
( num INT AUTO_INCREMENT NOT NULL PRIMARY KEY,
mem_id CHAR(8) NOT NULL,
prod_name CHAR(6) NOT NULL,
group_name CHAR(4) NULL ,
price INT UNSIGNED NOT NULL,
amount SMALLINT UNSIGNED NOT NULL ,
FOREIGN KEY(mem_id) REFERENCES member(mem_id)
);
import java.io.BufferedReader;
import java.io.InputStreamReader;
public class Main
{
static public boolean KMP(String str, String pattern)
{
int LPS[] = new int[pattern.length()]; //LPS 배열 생성
int index = 0; //IDX, 찾을 문자열의 비교 인덱스를 뜻하기도 하며, 접두사와 접미사가 같을 때 최대 길이를 뜻하기도 함
for (int i = 1; i < pattern.length(); i++) //LPS배열의 값을 입력
{
if (pattern.charAt(i) == pattern.charAt(index)) LPS[i] = ++index; //접두사와 접미사가 같을 때, index를 1 증가
else //접두사와 접미사가 같지 않을 때
{
if (index != 0) //0이면 더 이상 돌아갈 위치가 없음
{
index = LPS[index - 1]; //LPS[index - 1] : 이전 위치로 돌아가야 할 위치를 나타냄, 이 위치에서부터 비교를 다시 시작하여 일치하는 부분을 찾음
--i; // 현재 위치에서부터 다시 패턴 매칭을 시도(여기서 --i하고 이후 루프에서 ++i가 될테니)
}
}
}
index = 0; //0으로 초기화
for(int i = 0; i < str.length(); i++) //문자열 탐색 시작
{
while(index > 0 && str.charAt(i) != pattern.charAt(index)) index = LPS[index - 1]; //LPS[index - 1] : 이전으로 돌아가야할 위치
if(str.charAt(i) == pattern.charAt(index)) //접두사와 접미사가 같을 때
{
//IDX는 접두사와 접미사가 같을 때 최대 길이를 뜻하기도 하는데, 이것이 pattern의 길이와 같다면 탐색 성공
if(index == pattern.length() - 1) return true;
else ++index; //길이가 같지 않다면 index를 1증가
}
}
return false;
}
public static void main(String[] args) throws Exception
{
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
String str = br.readLine();
String pattern = br.readLine();
boolean flag = KMP(str, pattern);
System.out.print(flag ? 1 : 0);
}
}
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.util.ArrayList;
public class Main
{
static public ArrayList<Integer> KMP(String str, String pattern)
{
ArrayList<Integer> idxList = new ArrayList<>(); //찾는 문자열을 발견시 해당 문자열의 시작 인덱스를 저장하는 리스트
int LPS[] = new int[pattern.length()]; //LPS 배열 생성
int index = 0; //IDX, 찾을 문자열의 비교 인덱스를 뜻하기도 하며, 접두사와 접미사가 같을 때 최대 길이를 뜻하기도 함
for (int i = 1; i < pattern.length(); i++) //LPS배열의 값을 입력
{
if (pattern.charAt(i) == pattern.charAt(index)) LPS[i] = ++index; //접두사와 접미사가 같을 때, index를 1 증가
else //접두사와 접미사가 같지 않을 때
{
if (index != 0) //0이면 더 이상 돌아갈 위치가 없음
{
index = LPS[index - 1]; //LPS[index - 1] : 이전 위치로 돌아가야 할 위치를 나타냄, 이 위치에서부터 비교를 다시 시작하여 일치하는 부분을 찾음
--i; // 현재 위치에서부터 다시 패턴 매칭을 시도(여기서 --i하고 이후 루프에서 ++i가 될테니)
}
}
}
index = 0; //0으로 초기화
for(int i = 0; i < str.length(); i++) //문자열 탐색 시작
{
while(index > 0 && str.charAt(i) != pattern.charAt(index)) index = LPS[index - 1]; //LPS[index - 1] : 이전으로 돌아가야할 위치
if(str.charAt(i) == pattern.charAt(index)) //접두사와 접미사가 같을 때
{
if(index == pattern.length() - 1) //IDX는 접두사와 접미사가 같을 때 최대 길이를 뜻하기도 하는데, 이것이 pattern의 길이와 같다면 탐색 성공
{
idxList.add(i - index); //일치하는 첫 번째 인덱스를 추가
index = LPS[index]; //LPS[index] : 현재 일치하는 부분의 최대 길이를 나타내며, 이 길이만큼은 이미 패턴과 일치함이 보장
}
else ++index; //길이가 같지 않다면 index를 1증가
}
}
System.out.println(idxList.size()); //리스트의 사이즈 = 몇 번 나오는지 횟수
return idxList;
}
public static void main(String[] args) throws Exception
{
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
String str = br.readLine();
String pattern = br.readLine();
ArrayList<Integer> list = KMP(str, pattern); //시작 인덱스들을 받아옴
for (Integer i : list) System.out.print(i + 1 + " "); //시작 인덱스들을 출력
}
}
본 게시글은 이수안컴퓨터연구소의 데이터베이스 유튜브 동영상을 개인적으로 정리하는 글입니다.
Join
두 개 이상의 테이블을 서로 연결하는데 사용되는 기법
테이블들은 특정 규칙에 따라 서로 상호 관계를 가짐
조인 기법
설명
카티션 곱(Cartesian Product)
모든 행에 대해서 조인
동등 조인(Equi Join)
조인 조건이 정확히 일치할 때 조회
비동등 조인(Non Equi Join)
조인 조건이 정확히 일치하지 않는 경우 조회
외부 조인(Outer Join)
조인 조건이 정확히 일치하지 않아도 모두 조회
자체 조인(Self Join)
자체 테이블에서 조인하여 조회
카티션 곱(Cartesian Product)
공통되는 컬럼 없이 조인 조건이 없어서 모든 데이터가 조회
발생가능한 모든 경우의 수의 행이 출력되는 것을 의미
N 개의 행을 가진 테이블과 M 개의 행을 가진 테이블의 카티시안 곱은 N*M
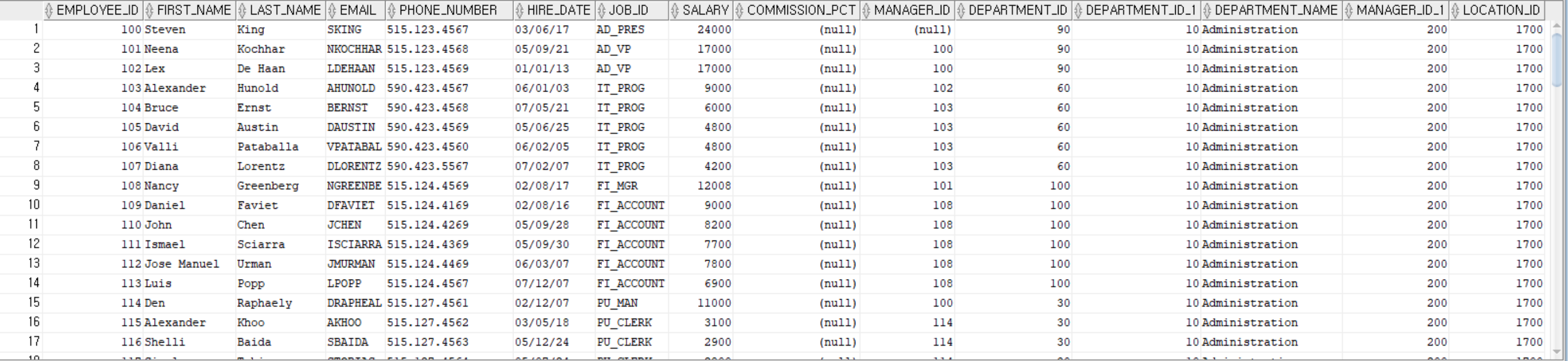
SELECT * FROM employees;
SELECT * FROM departments;
SELECT * FROM employees, departments;
내부 조인
동등 조인
조인하는 테이블에서 조인 조건이 일치하는 것만 조회
SELECT * FROM jobs, job_history
WHERE jobs.job_id = job_history.job_id;
SELECT * FROM countries C, locations L
WHERE C.country_id = L.country_id;
SELECT * FROM employees E, departments D
WHERE E.department_id = D.department_id;
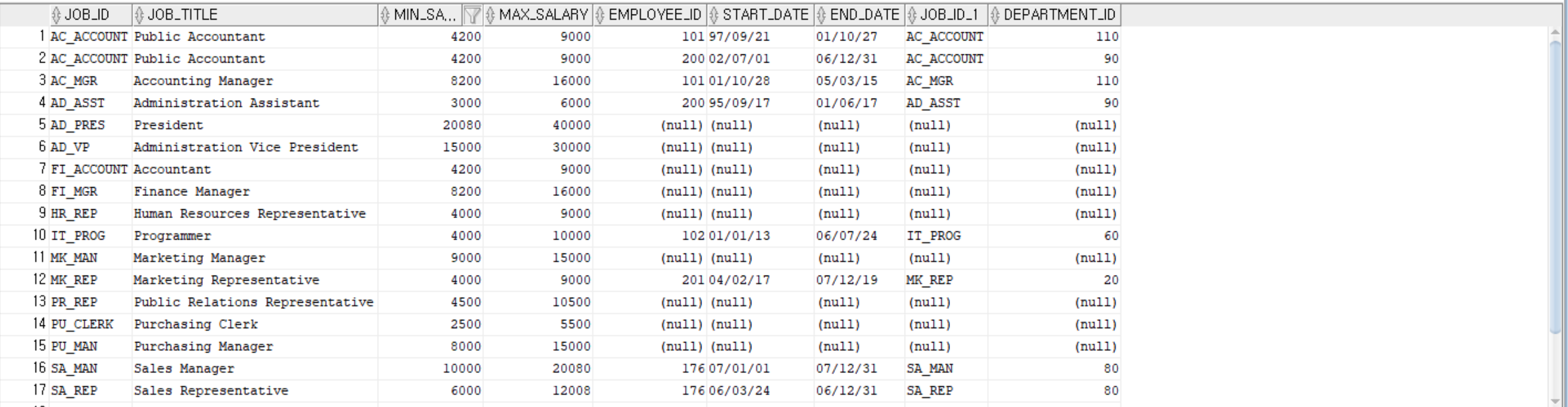
비동등 조인
테이블의 동일한 컬럼 없이 다른 조건으로 조인하는 방법
--j테이블의 최소 월급과 j테이블의 최대 월급 사이의 값을 가지는 E테이블의 월급이 있다면
--E테이블과 J테이블의 모든 컬럼 값을 출력
SELECT * FROM employees E, jobs J
WHERE E.salary BETWEEN J.min_salary AND J.max_salary;
--E 테이블의 고용날짜가 H테이블의 시작 날짜와 H테이블의 끝 날짜사이를 만족하는 데이터가 있다면
--E.first_name, E.hire_date, H.start_date, H.end_date를 출력
SELECT E.first_name, E.hire_date, H.start_date, H.end_date
FROM employees E, job_history H
WHERE E.hire_date BETWEEN H.start_date AND H.end_date;
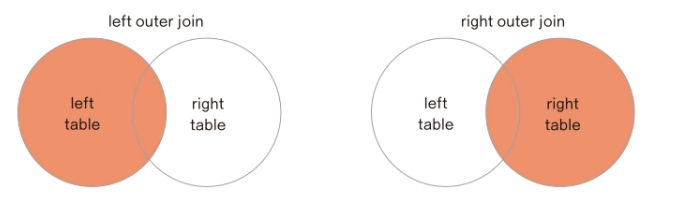
외부 조인
외부 조인은 동등 조인 조건을 만족하지 못해 누락되는 행을 출력하기 위해 사용
외부조인은 (+)기호를 사용 (+) 기호는 데이터 값이 부족한 테이블의 열 이름 뒤에 기술 즉, (+)는 위 그림에서 색이 칠해져 있지 않은 테이블을 뜻함, 따라서 두 테이블의 교집합 부분만 null값이 아닌 값이 출력되고, 교집합이 없는 부분은 null값이 출력됨
예를 들어, 회원 테이블과 구매 테이블이 있다고 가정하면, 구매를 하지 않은 회원이 충분히 존재할 수 있다. 따라서 회원 테이블과 구매 테이블을 동시에 보고 싶다면 구매 테이블에(+)를 붙이면 구매를 하지 않은 회원은 null로 보여진다.
SELECT * FROM jobs J, job_history H
WHERE J.job_id = H.job_id(+);
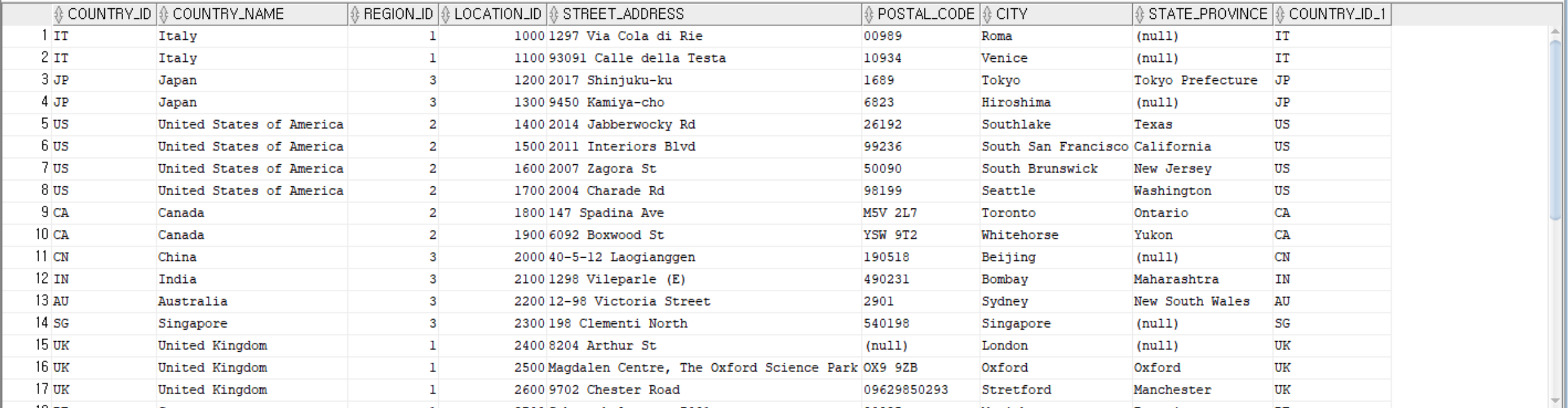
SELECT * FROM countries C, locations L
WHERE C.country_id = L.country_id(+);
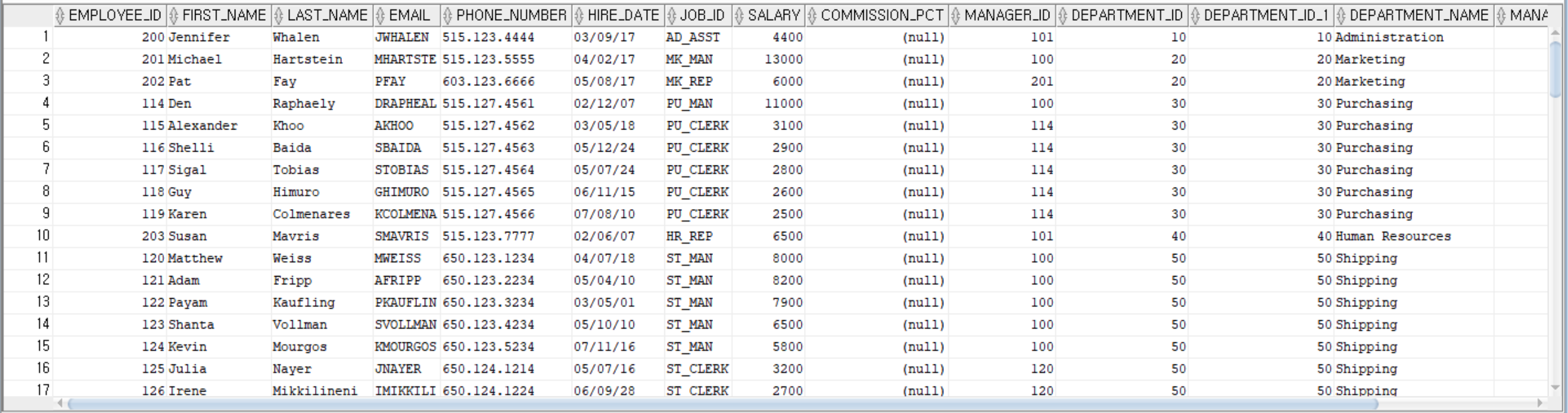
SELECT * FROM employees E, departments D
WHERE E.department_id(+) = D.department_id;
자체 조인
자기 자신의 테이블과 조인하는 방법
자체 조인은 자신이 자신과 조인한다는 의미이다. 그래서 자체 조인은 1개의 테이블을 사용한다.
직원 테이블을 조회한다고 해보자.
직원은 상급자일 수도 있고, 하급자일 수도 있다.
상급자는 여러 하급자를 가질 수 있다.
따라서 직원 테이블 내에서 특정 상급자 밑에 어떤 하급자들이 있는지 알아볼 때 등의 경우에 자체 조인을 사용한다.
SELECT E.first_name, E.last_name, M.first_name, M.last_name
FROM employees E, employees M
WHERE E.manager_id = M.employee_id;
연습 문제
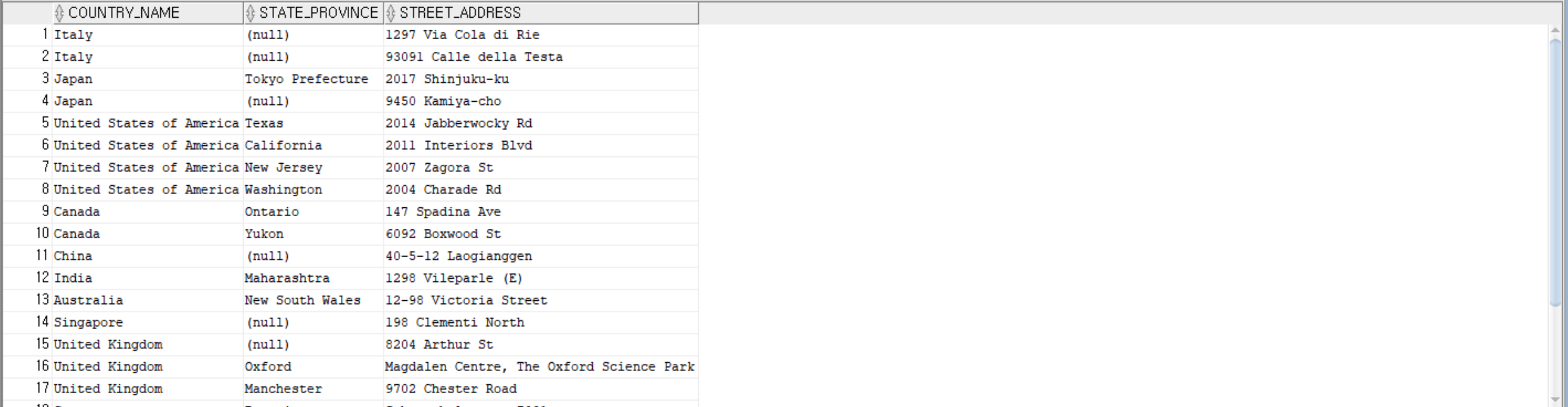
--countries 테이블과 locations 테이블을 country_id를 기준으로 조인하여 country_name, state_province, street_address를 조회
SELECT C.country_name, L.state_province, L.street_address
FROM countries C, locations L
WHERE c.country_id = L.country_id;
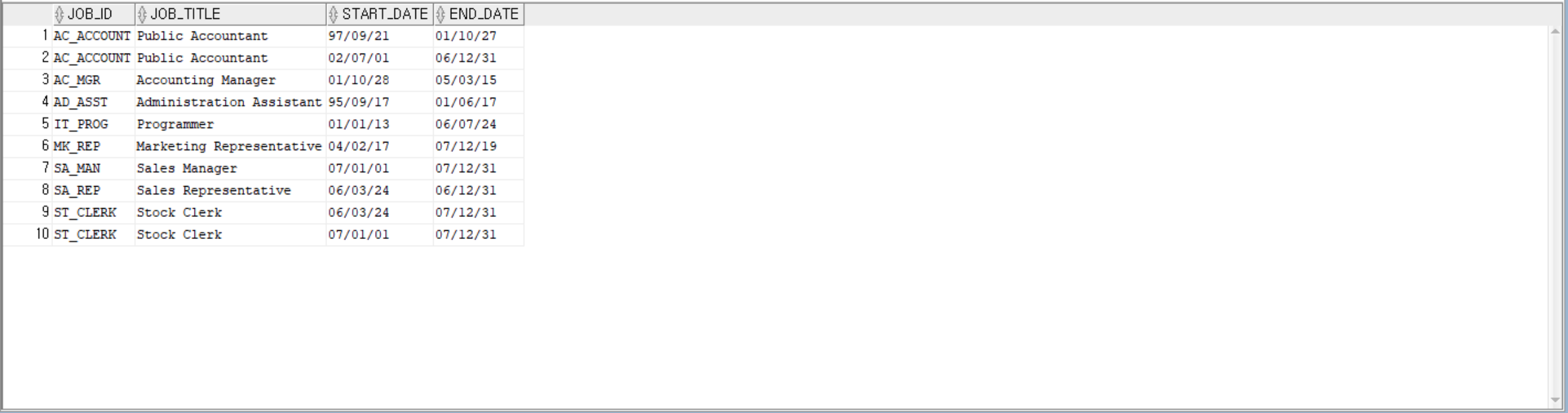
--jobs 테이블과 job_history 테이블을 job_id를 기준으로 조인하여 job_id, job_title, start_date, end_date를 조회
SELECT J.job_id, J.job_title, H.start_date, H.end_date
FROM jobs J, job_history H
WHERE j.job_id = H.job_id;
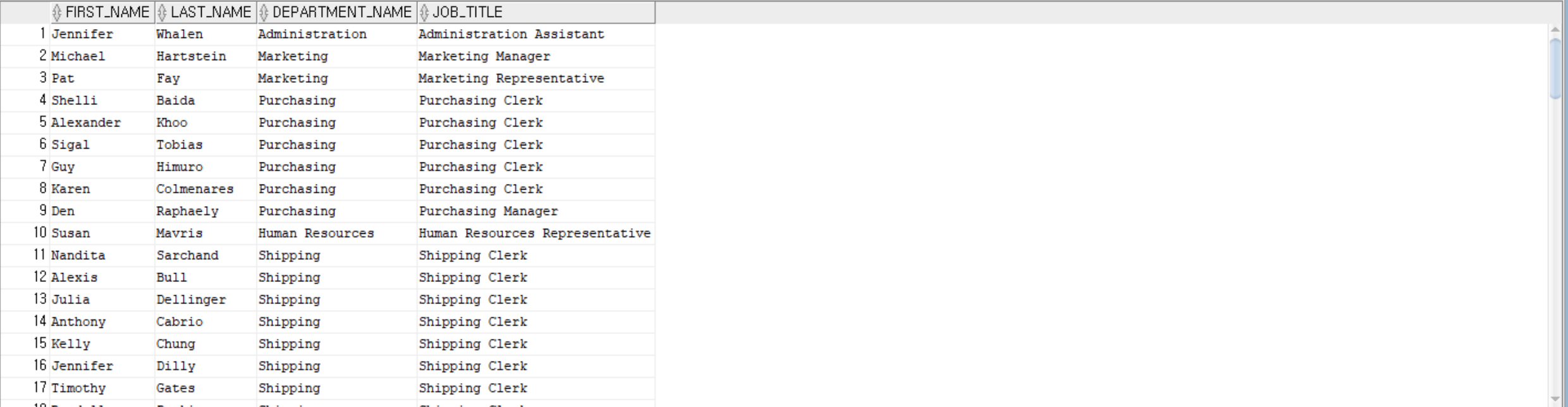
--employees 테이블과 departments 테이블을 department_id 기준으로 조인하고, employees 테이블과 jobs 테이블을 job_id 기준으로
--조인하여 first_name, last_name, department_name, job_title을 조회
SELECT E.first_name, E.last_name, D.department_name, J.job_title
FROM employees E, departments D, jobs J
WHERE E.department_id = D.department_id
AND E.job_id = J.job_id;
--countries 테이블과 locations 테이블을 country_id를 기준으로 조인하여 country_name, state_province, street_address를 조회
SELECT C.country_id, C.country_name, L.city
FROM countries C,locations L
WHERE C.country_id = L.country_id(+);
--jobs 테이블과 job_history 테이블을 job_id를 기준으로 조인하여 job_id, job_title, start_date, end_date를 조회
SELECT E.employee_id, E.first_name, E.last_name, D.department_name
FROM employees E, departments D
WHERE E.department_id = D.department_id(+)
ORDER BY E.employee_id;
--employees 테이블과 departments 테이블을 department_id 기준으로 조인하고, employees 테이블과 jobs 테이블을 job_id 기준으로 조인하여
--first_name, last_name, department_name, job_title을 조회
SELECT E.first_name || ' ' || E.last_name employee, M.first_name || ' ' || M.last_name manager
FROM employees E, employees M
WHERE E.manager_id = M.employee_id
ORDER BY E.employee_id;
이 알고리즘을 만든 Knuth, Morris, Prett 이렇게 3명의 앞 글자를 하나씩 따서 명명하여 KMP 알고리즘이라고 한다.
KMP 문자열 탐색 알고리즘의 시간 복잡도는 O(N+M)이다.(전체 문자열 길이 = N, 찾는 문자열 길이 = M)
LPS 배열 계산 O(M) + 매칭 O(N)
KMP 알고리즘의 핵심 아이디어
IDX
0
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
Text
A
B
C
D
A
B
D
A
B
C
D
A
B
E
A
B
C
D
Pattern
A
B
C
D
A
B
E
위 표에서 text와 pattern 모두 0, 1번째 인덱스와 4, 5번째 인덱스의 값이 동일하다는 것을 알 수 있다.
즉, 앞에서 2개 뒤에서 2개가 같다는 것을 알 수 있다.
또한 6번째 인덱스부터 text와 pattern이 다르다는 것을 알 수 있다.
text와 pattern 모두 0, 1번째 인덱스와 4, 5번째 인덱스의 값이 동일하고, 6번째 인덱스부터 text와 pattern이 다르기 때문에, 다음 문자열 비교를 할 때, pattern의 첫 시작을 text와 pattern이 다른 곳(IDX 6)으로부터 앞에서 2번째인 인덱스 4부터 시작한다는 개념이다.
문자열이 불일치 할 때, 탐색을 시작했던 위치의 다음 문자 부터가 아닌 일정 부분을 건너 뛸 수 있다는 것이 핵심이다.
아래의 표를 보면 이해가 될 것이다.
IDX
0
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
Text
A
B
C
D
A
B
D
A
B
C
D
A
B
E
A
B
C
D
Pattern
A
B
C
D
A
B
E
여기서는 앞에서 몇개 뒤에서 몇개가 같은게 없다.
그리고 6번째 인덱스부터 text와 pattern이 다르다.
그러면 다음 문자열 비교를 할 때, pattern의 첫 시작을 text와 pattern이 다른 곳(IDX 6)부터 다시 비교를 하는 것이다.
IDX
0
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
Text
A
B
C
D
A
B
D
A
B
C
D
A
B
E
A
B
C
D
Pattern
A
B
C
D
A
B
E
IDX 6부터 pattern의 길이(6)를 더한 IDX 12까지 일치하는 것이 없으므로 한 칸 옆으로 pattern을 이동시킨다.
IDX
0
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
Text
A
B
C
D
A
B
D
A
B
C
D
A
B
E
A
B
C
D
Pattern
A
B
C
D
A
B
E
Text의 IDX7부터 찾는 문자열이 있음을 알 수 있다.
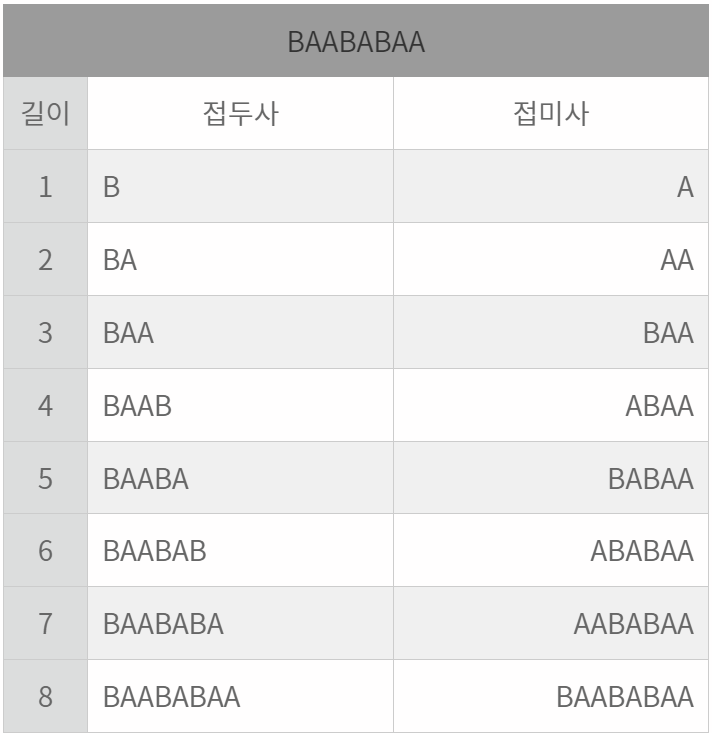
Prefix(접두사), Suffix(접미사), LPS배열
Prefix(접두사)와 Suffix(접미사)의 개념은 아래의 표를 보면 이해가 될 것이다.
BAABABAA 문자열에서 얻을 수 있는 접두사와 접미사는 아래와 같다.
BAABABAA
길이
접두사
접미사
1
B
A
2
BA
AA
3
BAA
BAA
4
BAAB
ABAA
5
BAABA
BABAA
6
BAABAB
ABABAA
7
BAABABA
AABABAA
8
BAABABAA
BAABABAA
LPS : Longest proper Prefix which is also Suffix
LPS의 길이를 담는 LPS 배열은 KMP 알고리즘에서 중요한 역할을 하는 배열이다.
Pattern "ABAABAB"에 대한 LPS 배열은 아래와 같다.
IDX
index까지의 패턴
LPS의 길이
0
A
0
1
AB
0
2
ABA
1
3
ABAA
1
4
ABAAB
2
5
ABAABA
3
6
ABAABAB
2
위 표에서 IDX 3인 경우를 살펴보면
IDX
index까지의 패턴
LPS의 길이
3
ABAA
1
왜 LPS의 길이가 1인지는 아래와 같다.
길이
접두사
접미사
1
A
A
2
AB
AA
3
ABA
BAA
접두사와 접미사가 일치하는 최대 길이는 1이다
즉, 접두사와 접미사가 같을때, 그 최대 길이는 1이다.
이와 같이 접두사와 접미사가 같을 때, 그 최대 길이를 가지고 있는 배열이 바로 LPS배열이다.
LPS 배열이 의미하는 것
IDX
index까지의 패턴
LPS의 길이
0
A
0
1
AB
0
2
ABA
1
3
ABAA
1
4
ABAAB
2
5
ABAABA
3
6
ABAABAB
2
IDX
index까지의 패턴
LPS의 길이
5
ABAABA
3
IDX
0
1
2
3
4
5
6
7
8
Text
A
B
A
A
B
A
Z
Pattern
A
B
A
A
B
A
B
전체 패턴 "ABAABAB" 중에서 일부인 "ABAABA" 까지 일치하고 그 다음 글자에서 불일치 했다면
다음 번 비교는 접두사가 다시 나타나는 IDX3 부터 시작하면 효율적이다.
즉, 틀린 위치인 IDX6에서 LPS의 길이인 3을 빼서 IDX3부터 다음 번 비교를 시작하면 되는 것이다.
이후 비교에서 IDX3부터 IDX5까지는 이미 일치하다는 것을 알고 있기 때문에, IDX6부터 비교를 하면 되는 것이다.
IDX
0
1
2
3
4
5
6
7
8
Text
A
B
A
A
B
A
Z
..
..
Pattern
A
B
A
A
B
A
구현
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.util.ArrayList;
public class Main
{
static public ArrayList<Integer> KMP(String str, String pattern)
{
ArrayList<Integer> idxList = new ArrayList<>(); //찾는 문자열을 발견시 해당 문자열의 시작 인덱스를 저장하는 리스트
int LPS[] = new int[pattern.length()]; //LPS 배열 생성
int index = 0; //IDX, 찾을 문자열의 비교 인덱스를 뜻하기도 하며, 접두사와 접미사가 같을 때 최대 길이를 뜻하기도 함
for (int i = 1; i < pattern.length(); i++) //LPS배열의 값을 입력
{
if (pattern.charAt(i) == pattern.charAt(index)) LPS[i] = ++index; //접두사와 접미사가 같을 때, index를 1 증가
else //접두사와 접미사가 같지 않을 때
{
if (index != 0) //0이면 더 이상 돌아갈 위치가 없음
{
index = LPS[index - 1]; //LPS[index - 1] : 이전 위치로 돌아가야 할 위치를 나타냄, 이 위치에서부터 비교를 다시 시작하여 일치하는 부분을 찾음
--i; // 현재 위치에서부터 다시 패턴 매칭을 시도(여기서 --i하고 이후 루프에서 ++i가 될테니)
}
}
}
index = 0; //0으로 초기화
for(int i = 0; i < str.length(); i++) //문자열 탐색 시작
{
while(index > 0 && str.charAt(i) != pattern.charAt(index)) index = LPS[index - 1]; //LPS[index - 1] : 이전으로 돌아가야할 위치
if(str.charAt(i) == pattern.charAt(index)) //접두사와 접미사가 같을 때
{
if(index == pattern.length() - 1) //IDX는 접두사와 접미사가 같을 때 최대 길이를 뜻하기도 하는데, 이것이 pattern의 길이와 같다면 탐색 성공
{
idxList.add(i - (index - 1)); //일치하는 첫 번째 인덱스를 추가
index = LPS[index]; //LPS[index] : 현재 일치하는 부분의 최대 길이를 나타내며, 이 길이만큼은 이미 패턴과 일치함이 보장
}
else ++index; //길이가 같지 않다면 index를 1증가
}
}
return idxList;
}
public static void main(String[] args) throws Exception
{
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
String str = br.readLine();
String pattern = br.readLine();
ArrayList<Integer> list = KMP(str, pattern); //시작 인덱스들을 받아옴
System.out.println(list.size() + "개 발견");
System.out.print("인덱스 : ");
for (Integer i : list) System.out.print(i + " "); //시작 인덱스들을 출력
}
}
이 글은 혼자 공부하는 SQL(저자 : 우재남)의 책과 유튜브 영상을 참고하여 개인적으로 정리하는 글임을 알립니다.
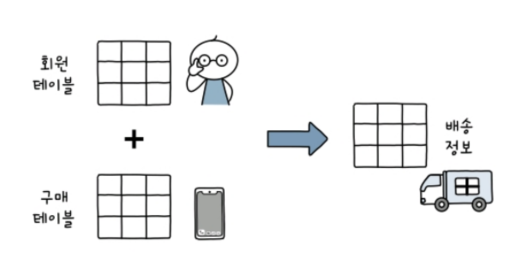
join이란 두 개의 테이블을 서로 묶어서 하나의 결과를 만들어 내는 것을 말한다.
두 테이블을 엮어야만 원하는 형태가 나오는 경우도 많다.
인터넷 마켓 데이터베이스의 회원 테이블과 구매 테이블을 예로 들 수 있다.
회원 테이블에는 회원의 이름과 연락처가 있고, 구매 테이블에는 회원이 구매한 물건이 있다.
물건을 배송하려면 회원 테이블의 회원 이름과 연락처, 구매 테이블의 회원이 구매한 물건에 대한 정보가 함께 필요하다.
이렇게 두 테이블을 엮어서 하나의 배송을 위한 정보를 추출하는 것이 대표적인 join이다.
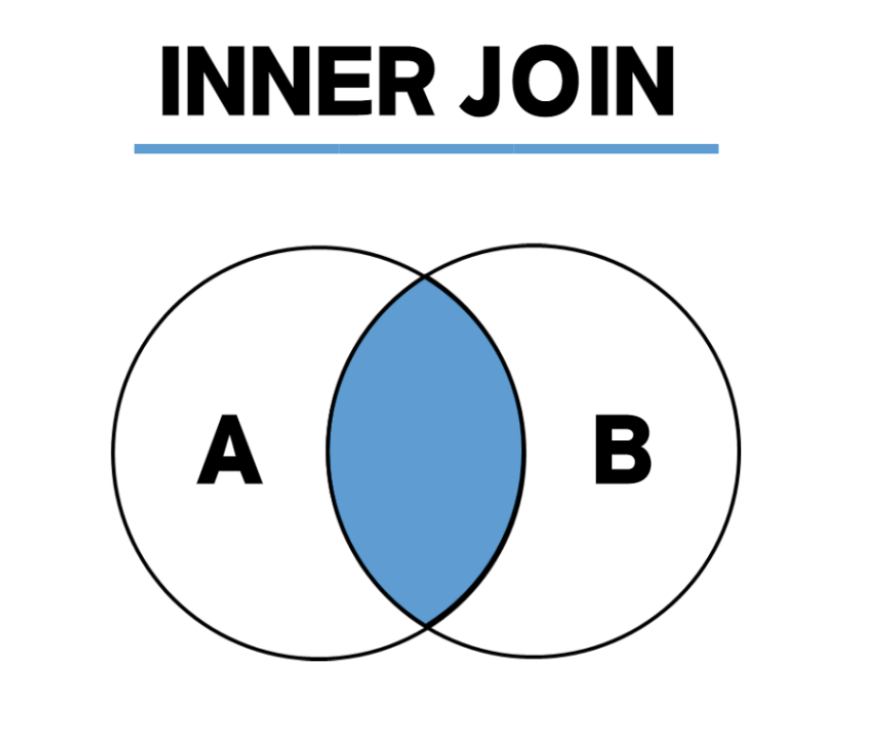
내부 조인(Inner Join)
두 테이블을 연결할 때 가장 많이 사용되는 것이 내부 조인이다.
그냥 조인이라 부르면 내부 조인을 의미하는 것이다.
두 테이블의 조인을 위해서는 기본키(PRIMARY KEY, PK)와 외래키(FOREIGN KEY, FK) 관계로 맺어져야 하고, 이를 일대다 관계라고 한다.
일대다 관계의 이해
두 테이블의 조인을 위해서는 테이블이 일대다(one to many) 관계로 연결되어야 한다.
데이터베이스의 테이블은 하나로 구성되는 것보다는 여러 정보를 주제에 따라 분리해서 저장하는 것이 효율적이다.
이 분리된 테이블은 서로 관계를 맺고 있다.
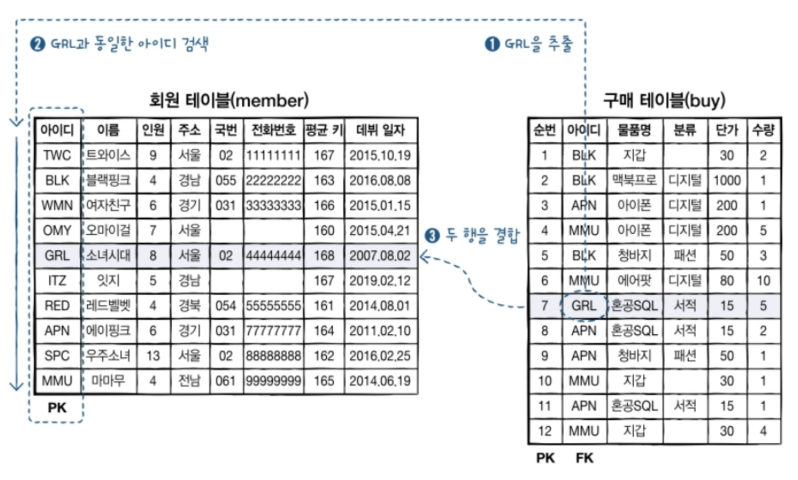
이러한 대표적인 사례가 인터넷 마켓 데이터베이스(market_db)의 회원 테이블과 구매 테이블이다.
아래와 같이 morket_db에서 회원 테이블의 아이디와 구매 테이블의 아이디는 일대다 관계이다.
일대다 관계란 한쪽 테이블에는 하나의 값만 존재해야 하지만, 연결된 다른 테이블에는 여러개의 값이 존재할 수 있는 관계를 말한다.
예를 들어, 회원 테이블에서 블랙핑크의 아이디는 BLK로 1명(1, one) 밖에 없다. 그래서 회원 테이블의 아이디를 기본 키로 지정했다.
구매 테이블의 아이디에서 3개의 BLK를 찾을 수 있다. 즉, 회원은 1명이지만 이 회원은 구매를 여러 번(다, many)할 수 있는 것이다.
그래서 구매 테이블의 아이디는 기본 키가 아닌 외래 키로 설정했다.
일대다 관계는 주로 기본 키와 외래 키 관계로 맺어져 있다. 그래서 일대다 관계를 PK-FK 관계라 부르기도 한다.
내부 조인의 기본
내부 조인의 형식은 아래와 같다.
구매 테이블에는 물건을 구매한 회원의 아이디와 물건 등의 정보만 있다.
이 물건을 배송하기 위해서는 구매한 회원의 주소 및 연락처를 알아야 한다.
이 회원의 주소, 연락처를 알기 위해 정보가 있는 회원 테이블과 결합하는 것이 내부 조인이다.
SELECT * FROM buy INNER JOIN member ON buy.mem_id = member.mem_id;
이렇게 쿼리를 작성하면, 구매 테이블과 회원 테이블이 mem_id를 기준으로 결합이 된다.
즉, 구매 테이블의 모든 행이 회원 테이블과 결합이 된다.
구매 테이블에서 GRL이라는 아이디를 가진 사람이 구매한 물건을 발송하기 위해 아래와 같이 조인해서 이름/주소/연락처 등을 검색할 수 있다.
SELECT *
FROM buy
INNER JOIN member
ON buy.mem_id = member.mem_id
WHERE buy.mem_id = 'GRL';
내부 조인의 간결한 표현
이것은 열이 너무 많아 복잡해 보이므로 필요한 아이디/이름/구매 물품/주소/연락처만 추출하려면 아래와 같이 퀴리를 작성한다.
SELECT buy.mem_id, mem_name, prod_name, addr, CONCAT(phone1, phone2) AS '연락처'
FROM buy
INNER JOIN member
ON buy.mem_id = member.mem_id;
별칭
FROM 절에 나오는 테이블의 이름 뒤에 별칭을 줄 수 있다.
SELECT B.mem_id, M.mem_name, B.prod_name, M.addr,
CONCAT(M.phone1, M.phone2) AS '연락처'
FROM buy B
INNER JOIN member M
ON B.mem_id = M.mem_id;
결과는 똑같이 나오는 것을 확인할 수 있다.
내부 조인의 활용
구매한 회원의 아이디/이름/구매한 제품/주소를 정렬하여 출력하면 아래와 같다.
SELECT M.mem_id, M.mem_name, B.prod_name, M.addr
FROM buy B
INNER JOIN member M
ON B.mem_id = M.mem_id
ORDER BY M.mem_id;
구매한 회원의 구매 기록과 더불어 구매하지 않은 회원의 이름/주소가 같이 검색되도록 하려면 아래와 같이 검색되도록 하려면 외부 조인을 사용해야 한다.
즉, 지금까지 사용한 내부 조인은 두 테이블에 모두 있는 내용만 조인되는 방식이다.
만약, 양쪽 중에 한 곳이라도 내용이 있을 때 조인하려면 외부 조인을 사용해야 한다.
구매 이력이 있는 회원들에게 감사문 보내기 구매를 한 이력이 있는 회원들에게 감사문을 보내려면, 구매를 몇번 했는지와 상관없이 한 번만 구매를 했으면 감사문을 보낼 대상이 된다. 즉, 중복을 제거해야 한다.
SELECT DISTINCT M.mem_id, M.mem_name, M.addr
FROM buy B
INNER JOIN member M
ON B.mem_id = M.mem_id
ORDER BY M.mem_id;
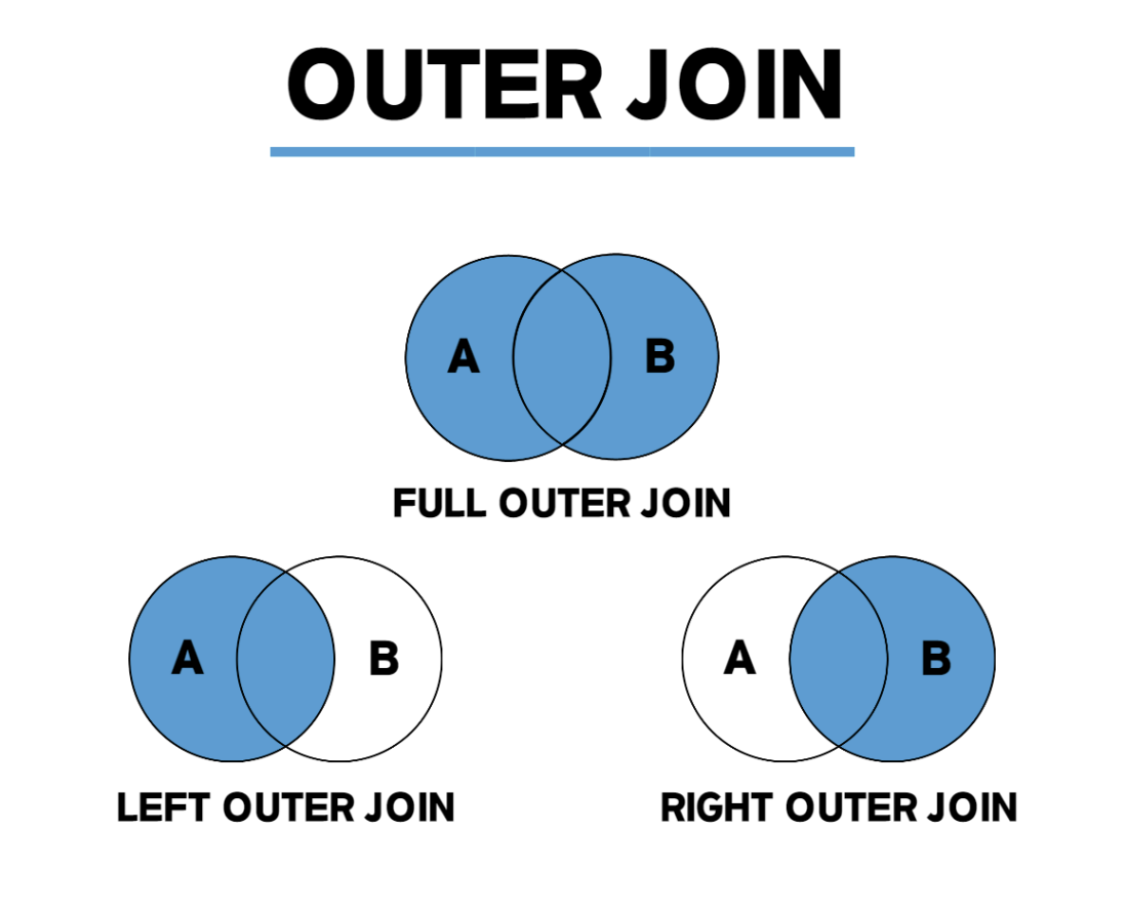
외부 조인(Outer Join)
내부 조인은 두 테이블에 모두 데이터가 있어야만 결과가 나온다.
이와 달리 외부 조인은 한쪽에만 데이터가 있어도 결과가 나온다.
LEFT OUTER JOIN: 왼쪽 테이블의 모든 값이 출력되는 조인
RIGHT OUTER JOIN: 오른쪽 테이블의 모든 값이 출력되는 조인
FULL OUTER JOIN: 왼쪽 또는 오른쪽 테이블의 모든 값이 출력되는 조인
외부 조인의 기본
외부 조인은 두 테이블을 조인할 때 필요한 내용이 한쪽 테이블에만 있어도 결과를 추출할 수 있다.
외부 조인의 형식은 아래와 같다.
내부 조인에서 해결하지 못한 전체 회원의 구매 기록(구매 기록이 없는 회원의 정보도 함께)출력을 외부조인으로 쿼리를 작성하면 아래와 같다.
SELECT M.mem_id, M.mem_name, B.prod_name, M.addr
FROM member M
LEFT OUTER JOIN buy B
ON M.mem_id = B.mem_id
ORDER BY M.mem_id;
member 테이블이 왼쪽 테이블, buy 테이블이 오른쪽 테이블인 상태이다.
RIGHT OUTTER JOIN으로 동일한 결과를 출력하려면 아래와 같이 단순히 왼쪽과 오른쪽 테이블의 위치만 바꾸면 된다.
SELECT M.mem_id, M.mem_name, B.prod_name, M.addr
FROM buy B
RIGHT OUTER JOIN member M
ON M.mem_id = B.mem_id
ORDER BY M.mem_id;
buy 테이블이 왼쪽 테이블, member 테이블이 오른쪽 테이블인 상태이다.
FULL OUTTER JOIN은 왼쪽 외부 조인과 오른쪽 외부 조인이 합쳐진 것이다.
왼쪽이든 오른쪽이든 한쪽에 들어 있는 내용이면 출력한다.
자주 사용하지 않는다.
외부 조인의 활용
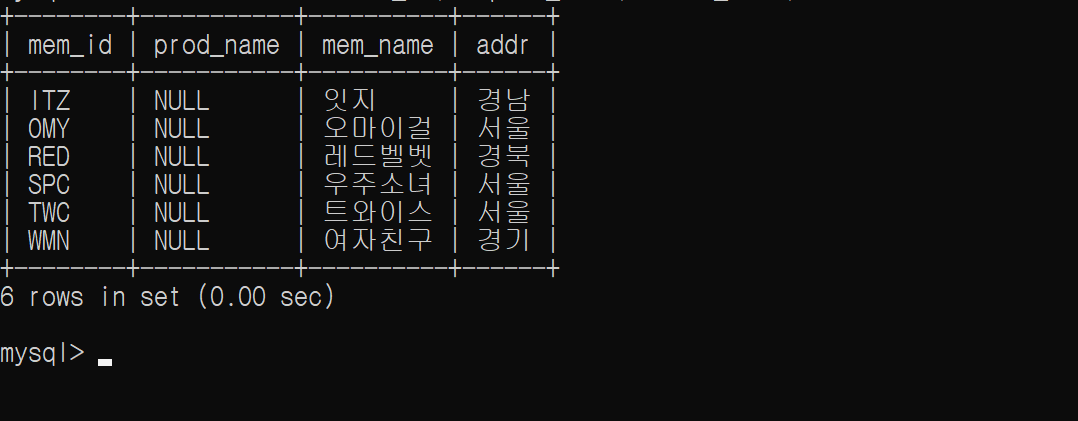
회원으로 가입만 하고, 한 번도 구매한 적이 없는 회원의 목록을 추출하는 쿼리는 아래와 같다.
SELECT DISTINCT M.mem_id, B.prod_name, M.mem_name, M.addr
FROM member M
LEFT OUTER JOIN buy B
ON M.mem_id = B.mem_id
WHERE B.prod_name IS NULL
ORDER BY M.mem_id;
IS NULL 구문은 널(NULL) 값인지 비교한다.
외부 조인 정리
기타 조인
내부 조인이나 외부 조인처럼 자주 사용되지는 않지만 가끔 유용하게 사용되는 조인으로 상호 조인과 자체 조인도 있다.
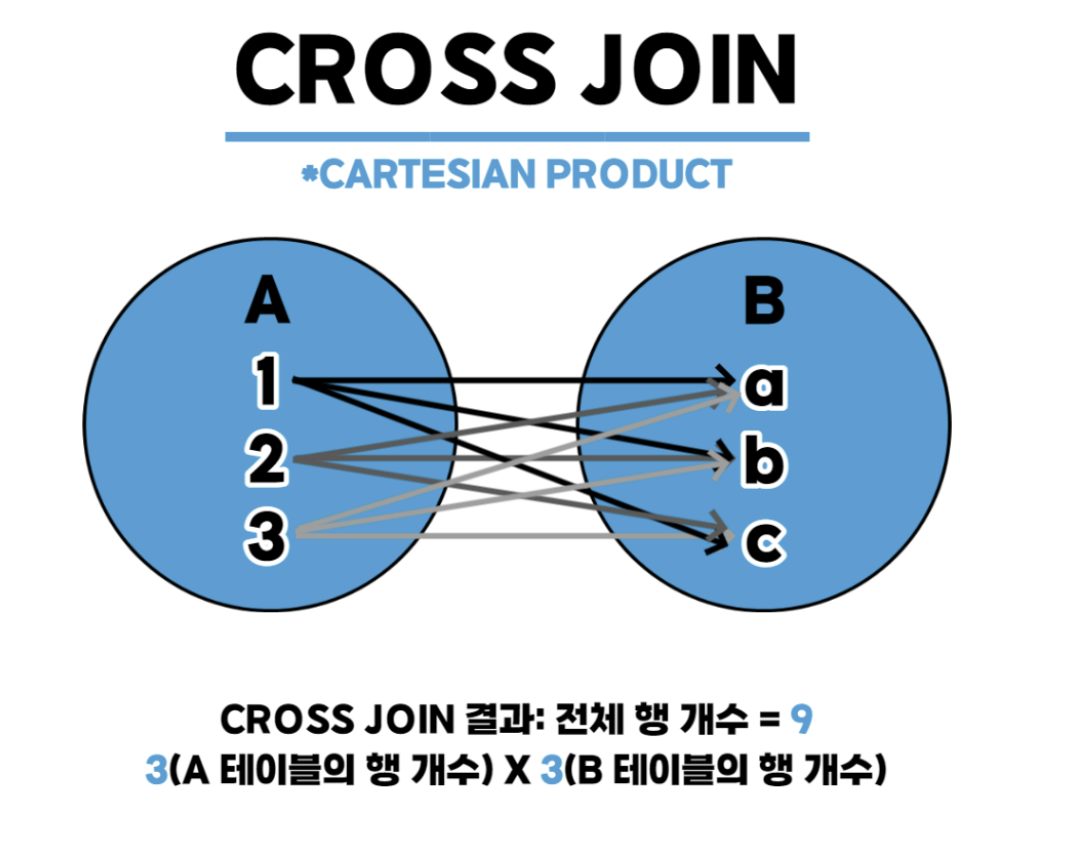
상호 조인(Cross Join)
한쪽 테이블의 모든 행과 다른 쪽 테이블의 모든 행을 조인시키는 기능입니다. 상호 조인 결과의 전체 행 개수는 두 테이블의 각 행의 개수를 곱한 수만큼 됩니다. 카티션 곱(CARTESIAN PRODUCT)라고도 한다.
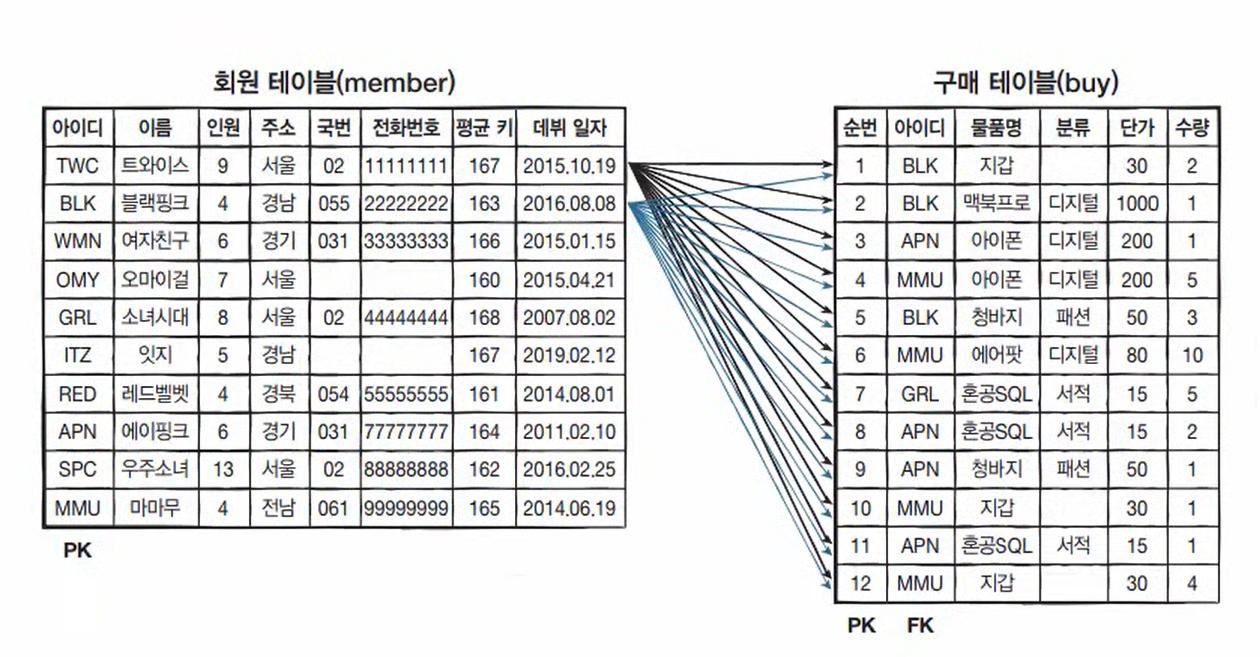
회원 테이블의 첫 행은 구매 테이블의 모든 행과 조인된다.
나머지 행도 마찬가지이다.
즉, 회원 테이블의 첫 행이 구매 테이블의 12개 행과 결합된다.
또 회원 테이블의 두 번째 행이 구매 테이블의 12개 행과 결합된다.
이런 식으로 회원 테이블의 모든 행이 구매 테이블의 모든 행과 결합된다.
최종적으로 회원 테이블의 10개 행과 구매 테이블의 12개 행을 곱해서 총 120개의 결과가 생성된다.
상호 조인은 아래와 같은 특징을 갖는다.
ON 구문을 사용할 수 없다.
결과의 내용은 의미가 없다.(랜덤으로 조인하기 때문)
상호 조인의 주 용도는 테스트하기 위해 대용량의 데이터를 생성할 때 쓰인다.
자체 조인(Self Join)
내부 조인, 외부 조인, 상호 조인은 모두 2개의 테이블을 조인했다.
자체 조인은 자신이 자신과 조인한다는 의미이다.
그래서 자체 조인은 1개의 테이블을 사용한다.
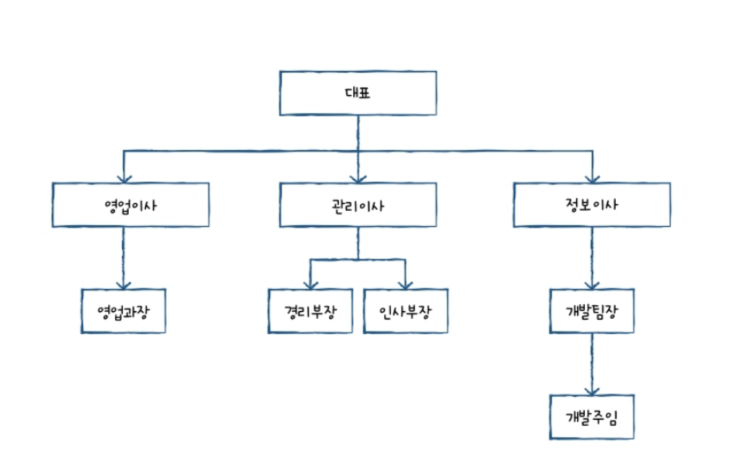
예를 들어, 관리 이사는 직원이므로 직원 열에 속한다.
그러면서 동시에 경리부장과 인사부장의 상관이어서 직속 상관 열에도 속한다.
만약, 직원 중 경리부장의 직속상관인 관리이사의 사내 연락처를 알고 싶다면 EMP열과 MANAGER 열을 조인해야 한다.
CREATE TABLE emp_table (emp CHAR(4), manager CHAR(4), phone VARCHAR(8));
INSERT INTO emp_table VALUES('대표', NULL, '0000');
INSERT INTO emp_table VALUES('영업이사', '대표', '1111');
INSERT INTO emp_table VALUES('관리이사', '대표', '2222');
INSERT INTO emp_table VALUES('정보이사', '대표', '3333');
INSERT INTO emp_table VALUES('영업과장', '영업이사', '1111-1');
INSERT INTO emp_table VALUES('경리부장', '관리이사', '2222-1');
INSERT INTO emp_table VALUES('인사부장', '관리이사', '2222-2');
INSERT INTO emp_table VALUES('개발팀장', '정보이사', '3333-1');
INSERT INTO emp_table VALUES('개발주임', '정보이사', '3333-1-1');
이렇게 만든 테이블은 아래와 같은 구조를 갖는다.
이제 관리 이사의 사내 전화번호를 알고 싶다면 아래와 같은 쿼리를 작성하면 된다.
SELECT A.emp "직원" , B.emp "직속상관", B.phone "직속상관연락처"
FROM emp_table A
INNER JOIN emp_table B
ON A.manager = B.emp
WHERE A.emp = '경리부장';
즉, 아래와 같이 2개의 테이블이 조인 되는 것처럼 구성된 것이다.
이렇든 하나의 테이블에 같은 데이터가 있지만 2개 이상의 열로 존재할 때 자체 조인을 할 수 있다.