- OS : Ubuntu 24.04 LTS (GNU/Linux 6.8.0-1008-aws x86_64) (프리티어)
- DB : MySQL 8.X
문제 상황
ubuntu:~/spring-ml-practice/build/libs$ sudo java -jar spring-ml-practice-0.0.1-SNAPSHOT.jar
. ____ _ __ _ _
/\\ / ___'_ __ _ _(_)_ __ __ _ \ \ \ \
( ( )\___ | '_ | '_| | '_ \/ _ | \ \ \ \
\\/ ___)| |_)| | | | | || (_| | ) ) ) )
' |____| .__|_| |_|_| |_\__, | / / / /
=========|_|==============|___/=/_/_/_/
:: Spring Boot :: (v3.3.1)
2024-06-29T21:08:19.056Z INFO 5768 --- [spring-ml-practice] [ main] C.s.SpringMlPracticeApplication : Starting SpringMlPracticeApplication v0.0.1-SNAPSHOT using Java 17.0.11 with PID 5768 (/home/ubuntu/spring-ml-practice/build/libs/spring-ml-practice-0.0.1-SNAPSHOT.jar started by root in /home/ubuntu/spring-ml-practice/build/libs)
2024-06-29T21:08:19.071Z INFO 5768 --- [spring-ml-practice] [ main] C.s.SpringMlPracticeApplication : No active profile set, falling back to 1 default profile: "default"
2024-06-29T21:08:21.205Z INFO 5768 --- [spring-ml-practice] [ main] .s.d.r.c.RepositoryConfigurationDelegate : Bootstrapping Spring Data JPA repositories in DEFAULT mode.
2024-06-29T21:08:21.413Z INFO 5768 --- [spring-ml-practice] [ main] .s.d.r.c.RepositoryConfigurationDelegate : Finished Spring Data repository scanning in 179 ms. Found 6 JPA repository interfaces.
2024-06-29T21:08:23.227Z INFO 5768 --- [spring-ml-practice] [ main] o.s.b.w.embedded.tomcat.TomcatWebServer : Tomcat initialized with port 80 (http)
2024-06-29T21:08:23.264Z INFO 5768 --- [spring-ml-practice] [ main] o.apache.catalina.core.StandardService : Starting service [Tomcat]
2024-06-29T21:08:23.266Z INFO 5768 --- [spring-ml-practice] [ main] o.apache.catalina.core.StandardEngine : Starting Servlet engine: [Apache Tomcat/10.1.25]
2024-06-29T21:08:23.629Z INFO 5768 --- [spring-ml-practice] [ main] o.a.c.c.C.[Tomcat].[localhost].[/] : Initializing Spring embedded WebApplicationContext
2024-06-29T21:08:23.634Z INFO 5768 --- [spring-ml-practice] [ main] w.s.c.ServletWebServerApplicationContext : Root WebApplicationContext: initialization completed in 4422 ms
2024-06-29T21:08:24.834Z INFO 5768 --- [spring-ml-practice] [ main] o.hibernate.jpa.internal.util.LogHelper : HHH000204: Processing PersistenceUnitInfo [name: default]
2024-06-29T21:08:25.044Z INFO 5768 --- [spring-ml-practice] [ main] org.hibernate.Version : HHH000412: Hibernate ORM core version 6.5.2.Final
2024-06-29T21:08:25.145Z INFO 5768 --- [spring-ml-practice] [ main] o.h.c.internal.RegionFactoryInitiator : HHH000026: Second-level cache disabled
2024-06-29T21:08:26.039Z INFO 5768 --- [spring-ml-practice] [ main] o.s.o.j.p.SpringPersistenceUnitInfo : No LoadTimeWeaver setup: ignoring JPA class transformer
2024-06-29T21:08:26.126Z INFO 5768 --- [spring-ml-practice] [ main] com.zaxxer.hikari.HikariDataSource : HikariPool-1 - Starting...
2024-06-29T21:08:27.060Z INFO 5768 --- [spring-ml-practice] [ main] com.zaxxer.hikari.pool.HikariPool : HikariPool-1 - Added connection com.mysql.cj.jdbc.ConnectionImpl@56299b0e
2024-06-29T21:08:27.063Z INFO 5768 --- [spring-ml-practice] [ main] com.zaxxer.hikari.HikariDataSource : HikariPool-1 - Start completed.
2024-06-29T21:08:27.289Z WARN 5768 --- [spring-ml-practice] [ main] org.hibernate.orm.deprecation : HHH90000025: MySQLDialect does not need to be specified explicitly using 'hibernate.dialect' (remove the property setting and it will be selected by default)
2024-06-29T21:08:29.423Z INFO 5768 --- [spring-ml-practice] [ main] o.h.e.t.j.p.i.JtaPlatformInitiator : HHH000489: No JTA platform available (set 'hibernate.transaction.jta.platform' to enable JTA platform integration)
2024-06-29T21:08:29.433Z INFO 5768 --- [spring-ml-practice] [ main] j.LocalContainerEntityManagerFactoryBean : Initialized JPA EntityManagerFactory for persistence unit 'default'
2024-06-29T21:08:30.333Z INFO 5768 --- [spring-ml-practice] [ main] o.s.d.j.r.query.QueryEnhancerFactory : Hibernate is in classpath; If applicable, HQL parser will be used.
2024-06-29T21:08:31.922Z WARN 5768 --- [spring-ml-practice] [ main] JpaBaseConfiguration$JpaWebConfiguration : spring.jpa.open-in-view is enabled by default. Therefore, database queries may be performed during view rendering. Explicitly configure spring.jpa.open-in-view to disable this warning
2024-06-29T21:08:33.046Z INFO 5768 --- [spring-ml-practice] [ main] o.s.b.w.embedded.tomcat.TomcatWebServer : Tomcat started on port 80 (http) with context path '/'
2024-06-29T21:08:33.110Z INFO 5768 --- [spring-ml-practice] [ main] C.s.SpringMlPracticeApplication : Started SpringMlPracticeApplication in 15.326 seconds (process running for 16.976)
2024-06-29T21:08:33.120Z INFO 5768 --- [spring-ml-practice] [ main] C.s.config.DatabaseConnectionCheck : Database connected successfully.
2024-06-29T21:08:44.795Z INFO 5768 --- [spring-ml-practice] [p-nio-80-exec-1] o.a.c.c.C.[Tomcat].[localhost].[/] : Initializing Spring DispatcherServlet 'dispatcherServlet'
2024-06-29T21:08:44.796Z INFO 5768 --- [spring-ml-practice] [p-nio-80-exec-1] o.s.web.servlet.DispatcherServlet : Initializing Servlet 'dispatcherServlet'
2024-06-29T21:08:44.800Z INFO 5768 --- [spring-ml-practice] [p-nio-80-exec-1] o.s.web.servlet.DispatcherServlet : Completed initialization in 3 ms
Hibernate:
select
m1_0.member_email,
m1_0.activity_level,
m1_0.height,
m1_0.name,
m1_0.password,
m1_0.sex,
m1_0.weight
from
members m1_0
where
m1_0.member_email=?
2024-06-29T21:08:45.363Z WARN 5768 --- [spring-ml-practice] [p-nio-80-exec-1] o.h.engine.jdbc.spi.SqlExceptionHelper : SQL Error: 1146, SQLState: 42S02
2024-06-29T21:08:45.363Z ERROR 5768 --- [spring-ml-practice] [p-nio-80-exec-1] o.h.engine.jdbc.spi.SqlExceptionHelper : Table 'test.members' doesn't exist
주요한 부분은 아래와 같다.
2024-06-29T21:08:44.800Z INFO 5768 --- [spring-ml-practice] [p-nio-80-exec-1] o.s.web.servlet.DispatcherServlet : Completed initialization in 3 ms
Hibernate:
select
m1_0.member_email,
m1_0.activity_level,
m1_0.height,
m1_0.name,
m1_0.password,
m1_0.sex,
m1_0.weight
from
members m1_0
where
m1_0.member_email=?
2024-06-29T21:08:45.363Z WARN 5768 --- [spring-ml-practice] [p-nio-80-exec-1] o.h.engine.jdbc.spi.SqlExceptionHelper : SQL Error: 1146, SQLState: 42S02
2024-06-29T21:08:45.363Z ERROR 5768 --- [spring-ml-practice] [p-nio-80-exec-1] o.h.engine.jdbc.spi.SqlExceptionHelper : Table 'test.members' doesn't exist
test.member 테이블을 찾을 수 없다는 상황이다.
로컬 개발 환경에서는 h2 DB를 사용하였고, 실제 배포할 때는 MySQL을 사용했다.
h2에서는 아무 문제가 없었는데, 리눅스 환경과 MySQL을 사용하고나니 이런 상황이 발생하여 매우 당황했다.
members 테이블의 생성 쿼리는 아래와 같다.
CREATE TABLE Members (
member_email VARCHAR(255) PRIMARY KEY,
password VARCHAR(255) NOT NULL,
name VARCHAR(255) NOT NULL,
sex INT NOT NULL,
activity_level INT NOT NULL,
weight INT NOT NULL,
height INT NOT NULL
);
JPA 엔티티 클래스 코드는 아래와 같다.
@Entity
@Table(name = "Members")
@Getter @Setter
public class Member {
@Id
private String memberEmail;
private String password;
private String name;
private int sex;
private int activityLevel;
private int weight;
private int height;
}
맨 처음에 이 문제를 맞닥뜨렸을 때는 도대체 뭐가 문제인지 파악하기 힘들었다.
원인
주요 원인은 내 배포 환경인 우분투에서는 MySQL이 대소문자를 확실히 구분한다는 것이다.
mysql> SHOW VARIABLES LIKE 'lower_case_table_names';
+------------------------+-------+
| Variable_name | Value |
+------------------------+-------+
| lower_case_table_names | 0 |
+------------------------+-------+
1 row in set (0.01 sec)
MySQL의 lower_case_table_names 설정이 0이므로, 대소문자를 구분하게 되어 있다.
엔티티 클래스의 테이블 이름 매핑은 Members 로 되어있는데, 실제 DB에 저장되어있는 테이블 명은 members이기 때문이다.
하지만, 엔티티 클래스의 테이블 이름 매핑은 members 로 소문자로 바꿔 봤지만 해결되지 않았다.
해결 방법
현재 테이블 이름은 Members이고, MySQL에서는 테이블 이름을 대소문자를 구분하여 처리하고 있다.
MySQL의 lower_case_table_names 설정이 0이므로, 대소문자를 구분하게 되어 있다.
따라서 엔티티 클래스에서 테이블 이름을 소문자로 변경하는 것이 필요하다.
이 뿐만이 아니라 DB에 DDL 쿼리를 날릴 때, 테이블 명 또한 소문자로 변경이 필요하다.
-- 테이블 명 소문자로 변경
CREATE TABLE members (
member_email VARCHAR(255) PRIMARY KEY,
password VARCHAR(255) NOT NULL,
name VARCHAR(255) NOT NULL,
sex INT NOT NULL,
activity_level INT NOT NULL,
weight INT NOT NULL,
height INT NOT NULL
);
@Entity
@Table(name = "members") //매핑 테이블명 소문자로 변경
@Getter @Setter
public class Member {
@Id
private String memberEmail;
private String password;
private String name;
private int sex;
private int activityLevel;
private int weight;
private int height;
}
@Entity
@Getter
@Setter
public class Member {
@Id
@GeneratedValue
private Long id;
private String username;
public Member() {
}
public Member(String username) {
this.username = username;
}
}
MemberRepository
@Slf4j
@Repository
@RequiredArgsConstructor
public class MemberRepository {
private final EntityManager em;
@Transactional
public void save(Member member) {
log.info("member 저장");
em.persist(member);
}
public Optional<Member> find(String username) {
return em.createQuery("select m from Member m where m.username=:username", Member.class)
.setParameter("username", username)
.getResultList().stream().findAny();
}
}
Log
@Entity
@Getter
@Setter
public class Log {
@Id
@GeneratedValue
private Long id;
private String message;
public Log() {
}
public Log(String message) {
this.message = message;
}
}
LogRepository
@Slf4j
@Repository
@RequiredArgsConstructor
public class LogRepository {
private final EntityManager em;
@Transactional(propagation = Propagation.REQUIRES_NEW)
public void save(Log logMessage) {
log.info("log 저장");
em.persist(logMessage);
if (logMessage.getMessage().contains("로그예외")) {
log.info("log 저장시 예외 발생");
throw new RuntimeException("예외 발생");
}
}
public Optional<Log> find(String message) {
/*
getResultList 메소드를 호출하여 쿼리의 실행 결과를 리스트로 가져온다.
이후 Java 8의 스트림 API를 사용하여 해당 리스트를 스트림으로 변환하고, findAny 메소드를 통해 결과 리스트 중 임의의 하나를 선택한다.
findAny는 Optional<Log> 타입을 반환
*/
return em.createQuery("select l from Log l where l.message = :message", Log.class)
.setParameter("message", message)
.getResultList().stream().findAny();
}
}
MemberService
@Slf4j
@Service
@RequiredArgsConstructor
@Transactional
public class MemberService {
private final MemberRepository memberRepository;
private final LogRepository logRepository;
public void joinV1(String username) {
Member member = new Member(username);
Log logMessage = new Log(username);
log.info("== memberRepository 호출 시작 ==");
memberRepository.save(member);
log.info("== memberRepository 호출 종료 ==");
log.info("== logRepository 호출 시작 ==");
logRepository.save(logMessage);
log.info("== logRepository 호출 종료 ==");
}
public void joinV2(String username) {
Member member = new Member(username);
Log logMessage = new Log(username);
log.info("== memberRepository 호출 시작 ==");
memberRepository.save(member);
log.info("== memberRepository 호출 종료 ==");
log.info("== logRepository 호출 시작 ==");
try {
logRepository.save(logMessage);
} catch (RuntimeException e) {
log.info("log 저장에 실패했습니다. logMessage={}", logMessage.getMessage());
log.info("정상 흐름 변환");
}
log.info("== logRepository 호출 종료 ==");
}
}
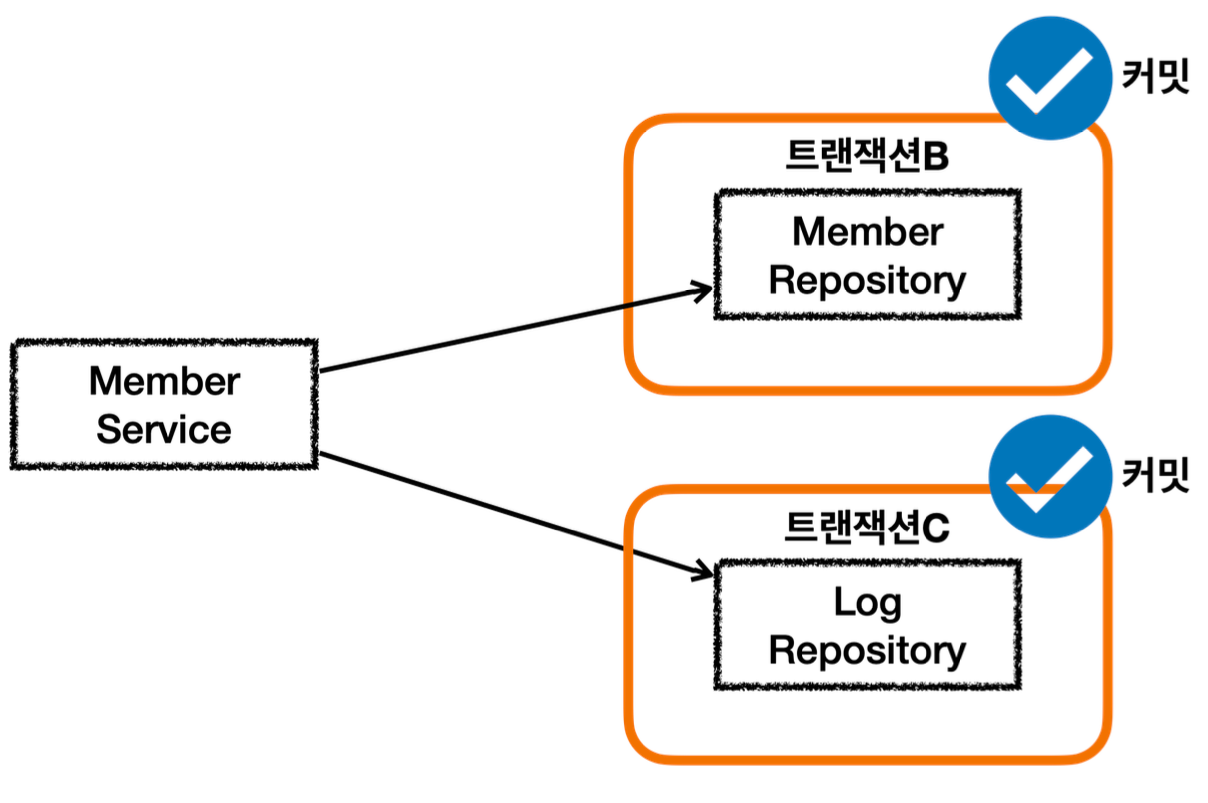
JPA를 통한 모든 데이터 변경(등록, 수정, 삭제)에는 트랜잭션이 필요하다. (조회는 트랜잭션 없이 가능하다.) 현재 서비스 계층에 트랜잭션이 없기 때문에 리포지토리에 트랜잭션이 있다.
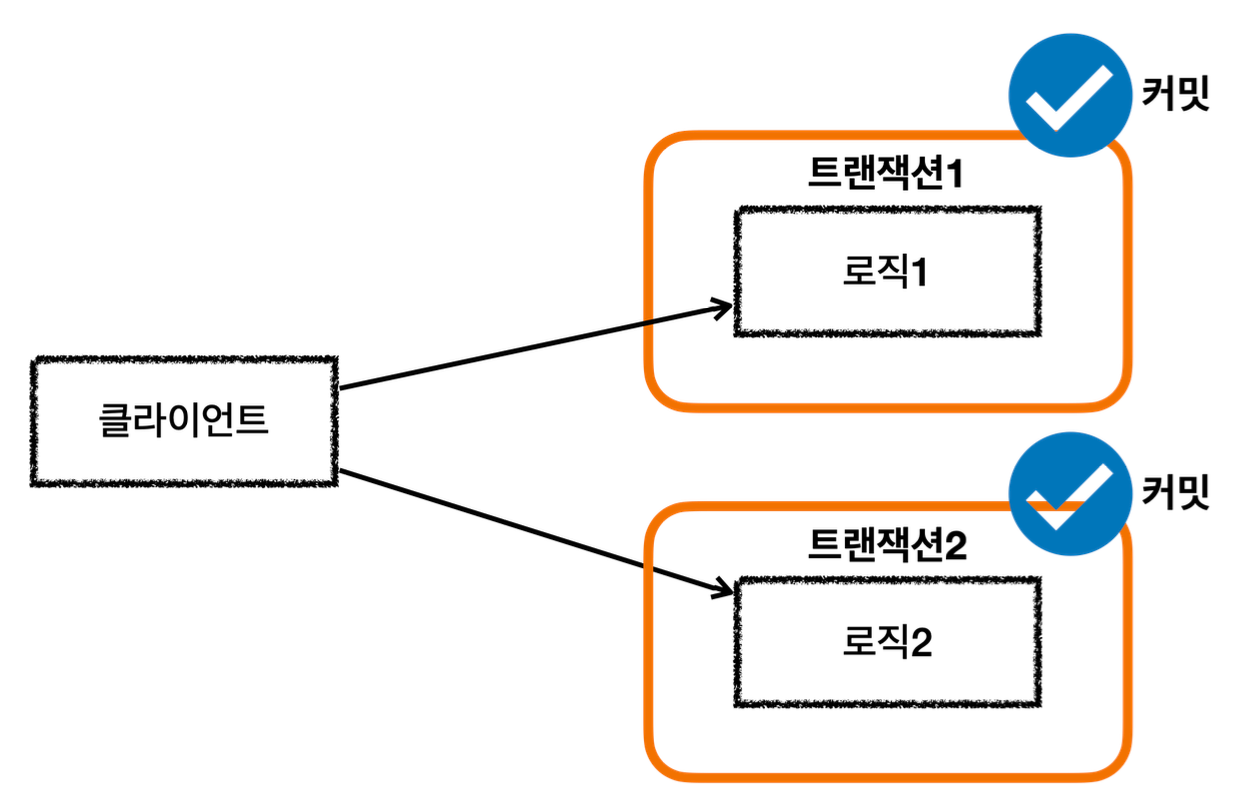
서비스 계층에 트랜잭션이 없을 때
커밋
서비스 계층에 트랜잭션이 없다.
회원, 로그 리포지토리가 각각 트랜잭션을 가지고 있다.
회원, 로그 리포지토리 둘다 커밋에 성공한다.
/**
* MemberService @Transactional:OFF
* MemberRepository @Transactional:ON
* LogRepository @Transactional:ON
*/
@Test
void outerTxOff_success() {
//given
String username = "outerTxOff_success";
//when
memberService.joinV1(username);
//then: 모든 데이터가 정상 저장된다.
assertTrue(memberRepository.find(username).isPresent());
assertTrue(logRepository.find(username).isPresent());
}
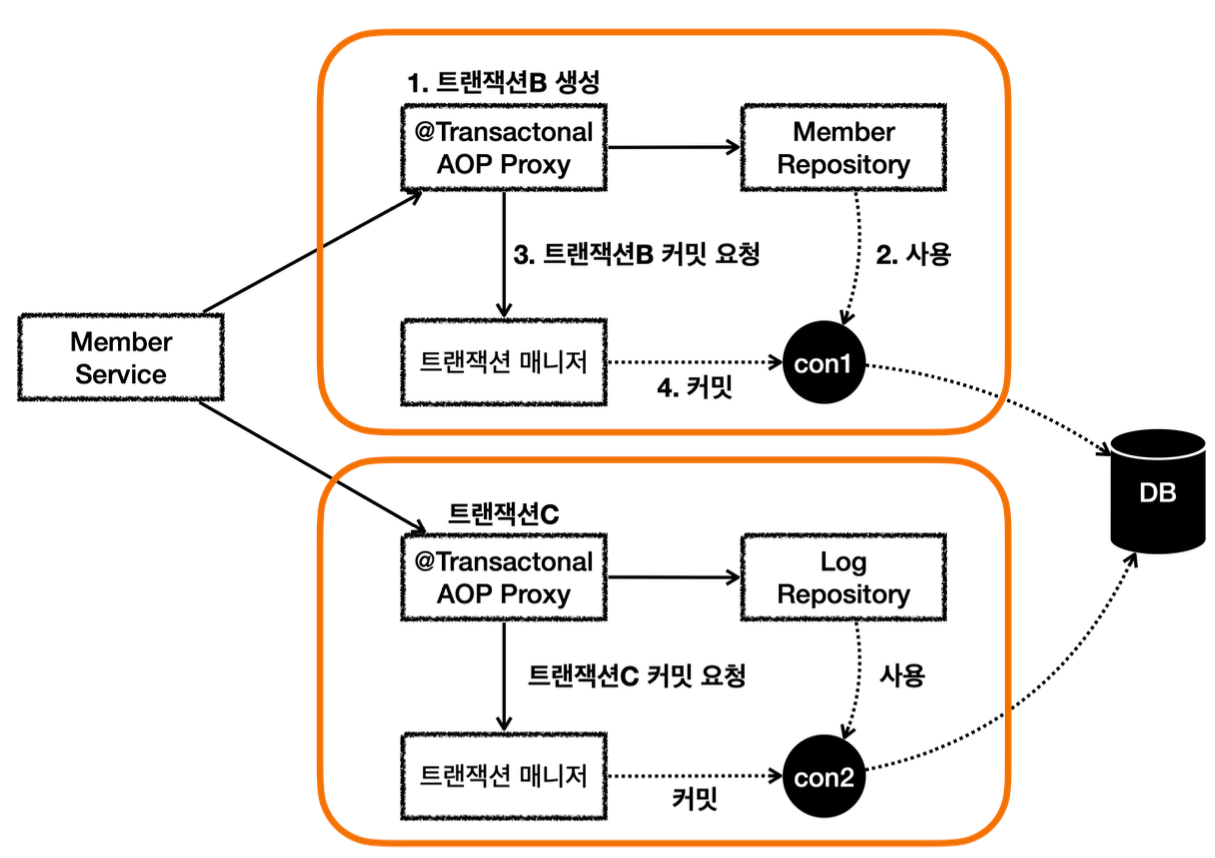
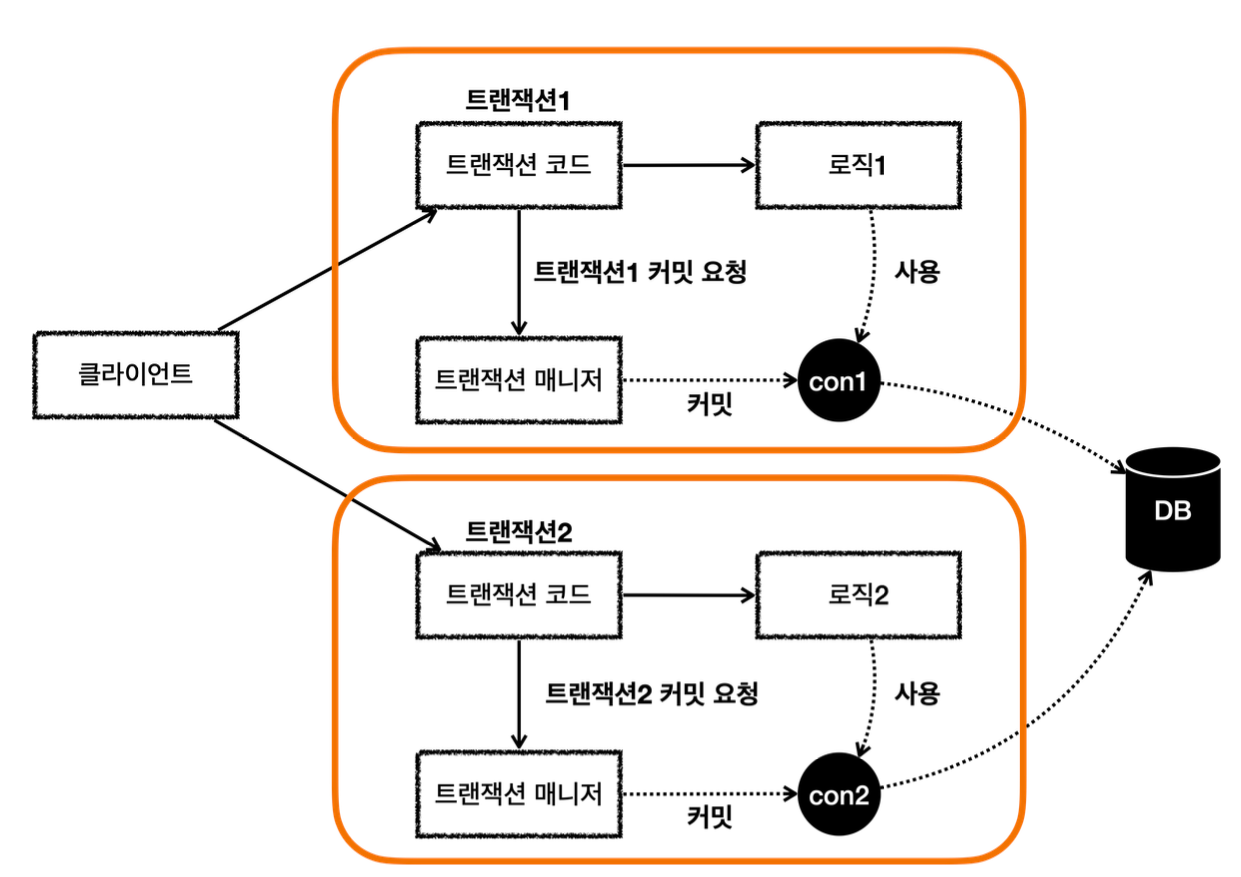
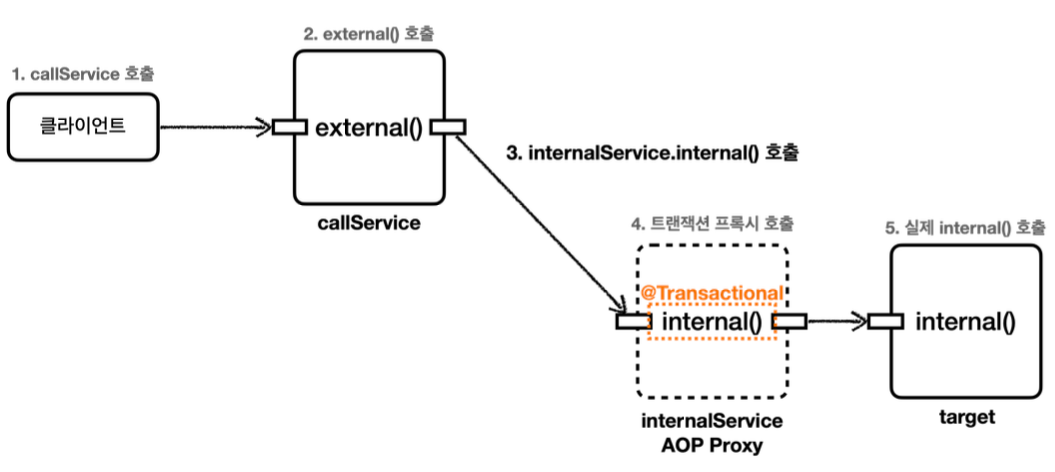
MemberService 에서 MemberRepository 를 호출한다. MemberRepository 에는 @Transactional 애노테이션이 있으므로 트랜잭션 AOP가 작동한다. 여기서 트랜잭션 매니저를 통해 트랜잭션을 시작한다. 이렇게 시작한 트랜잭션을 트랜잭션B라 하자. -그림에서는 생략했지만, 트랜잭션 매니저에 트랜잭션을 요청하면 데이터소스를 통해 커넥션 con1 을 획득 하고, 해당 커넥션을 수동 커밋 모드로 변경해서 트랜잭션을 시작한다. -그리고 트랜잭션 동기화 매니저를 통해 트랜잭션을 시작한 커넥션을 보관한다. -트랜잭션 매니저의 호출 결과로 status 를 반환한다. 여기서는 신규 트랜잭션 여부가 참이 된다.
MemberRepository 는 JPA를 통해 회원을 저장하는데, 이때 JPA는 트랜잭션이 시작된 con1 을 사용 해서 회원을 저장한다.
MemberRepository 가 정상 응답을 반환했기 때문에 트랜잭션 AOP는 트랜잭션 매니저에 커밋을 요청 한다.
트랜잭션 매니저는 con1 을 통해 물리 트랜잭션을 커밋한다. -물론 이 시점에 앞서 설명한 신규 트랜잭션 여부, rollbackOnly 여부를 모두 체크한다.
이렇게 해서 MemberRepository 와 관련된 모든 데이터는 정상 커밋되고, 트랜잭션B는 완전히 종료된다.
이후에 LogRepository 를 통해 트랜잭션C를 시작하고, 정상 커밋한다. 결과적으로 둘다 커밋되었으므로 Member, Log 모두 안전하게 저장된다.
@Transactional과 REQUIRED 트랜잭션 전파의 기본 값은 REQUIRED 이다. 따라서 다음 둘은 같다. -@Transactional(propagation = Propagation.REQUIRED) -@Transactional
REQUIRED 는 기존 트랜잭션이 없으면 새로운 트랜잭션을 만들고, 기존 트랜잭션이 있으면 참여한다.
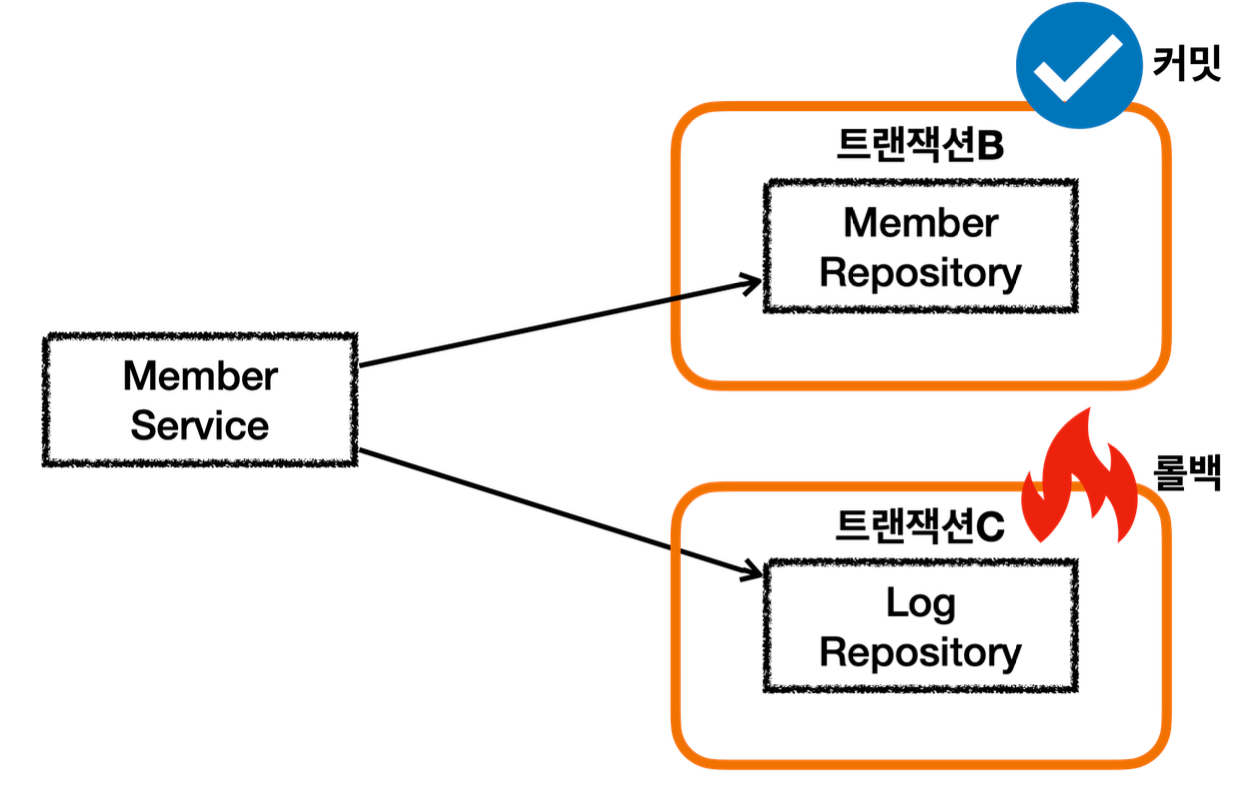
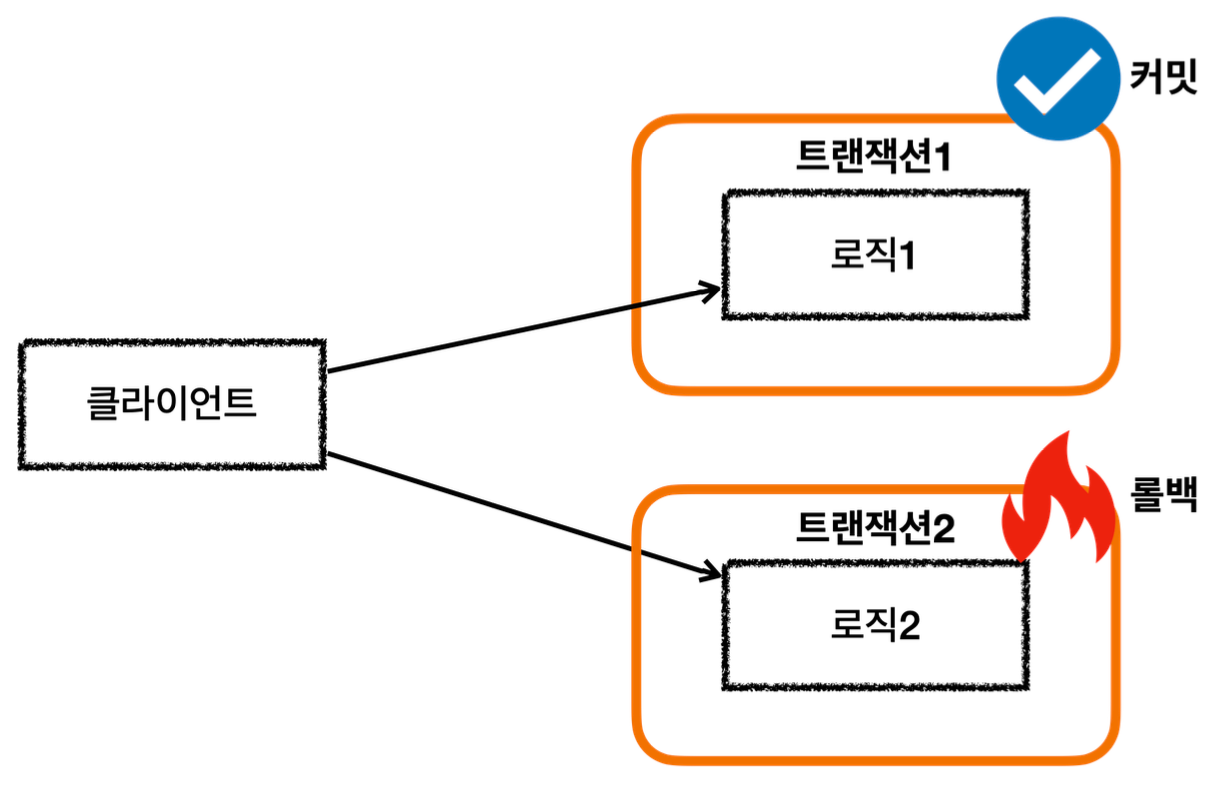
롤백
서비스 계층에 트랜잭션이 없다.
회원, 로그 리포지토리가 각각 트랜잭션을 가지고 있다.
회원 리포지토리는 정상 동작하지만 로그 리포지토리에서 예외가 발생한다.
/**
* MemberService @Transactional:OFF
* MemberRepository @Transactional:ON
* LogRepository @Transactional:ON Exception
*/
@Test
void outerTxOff_fail() {
//given
String username = "로그예외_outerTxOff_fail";
//when
assertThatThrownBy(() -> memberService.joinV1(username))
.isInstanceOf(RuntimeException.class);
//then: 완전히 롤백되지 않고, member 데이터가 남아서 저장된다.
assertTrue(memberRepository.find(username).isPresent());
assertTrue(logRepository.find(username).isEmpty());
}
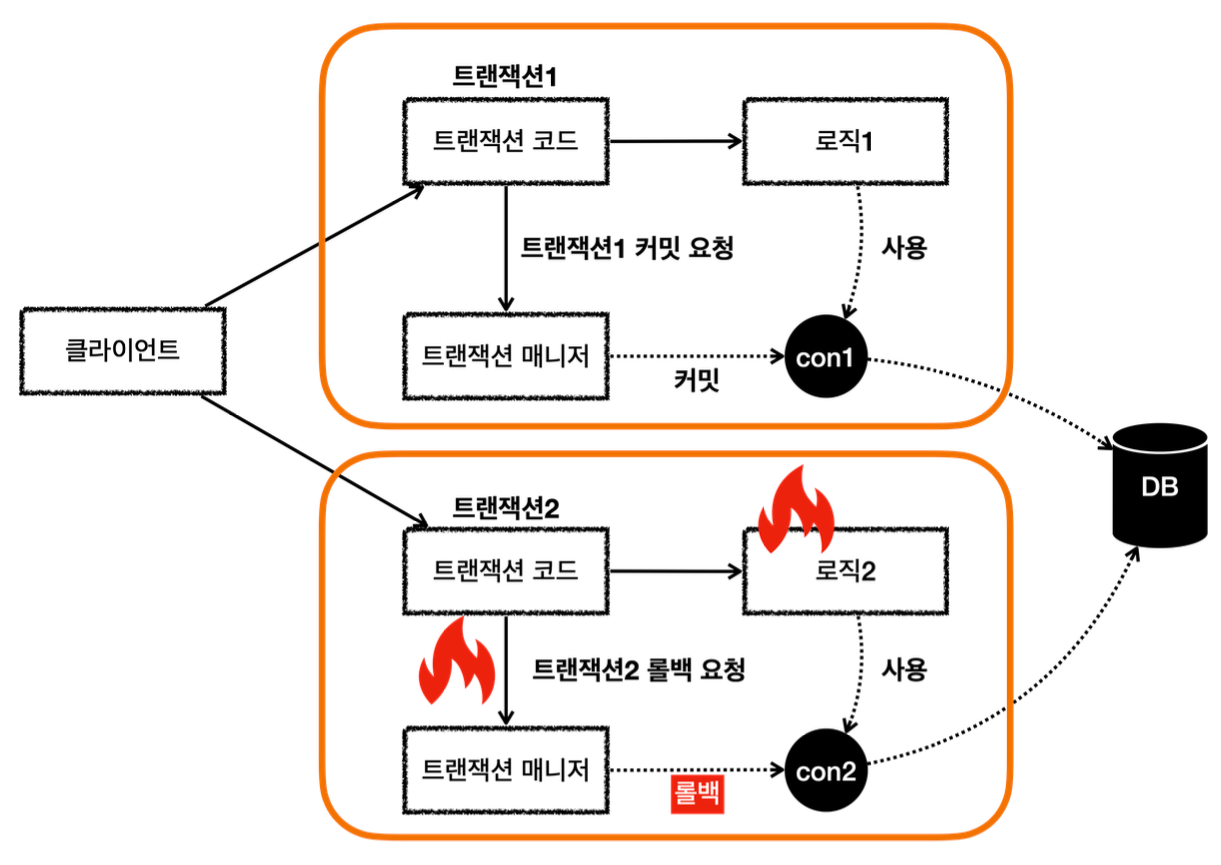
사용자 이름에 로그예외 라는 단어가 포함되어 있으면 LogRepository 에서 런타임 예외가 발생한다.
트랜잭션 AOP는 해당 런타임 예외를 확인하고 롤백 처리한다.
MemberService 에서 MemberRepository 를 호출하는 부분은 앞서 설명한 내용과 같다. 트랜잭션이 정상 커밋되고, 회원 데이터도 DB에 정상 반영된다.
MemberService 에서 LogRepository 를 호출하는데, 로그예외 라는 이름을 전달한다. 이 과정에서 새로운 트랜잭션 C가 만들어진다.
LogRepository 응답 로직
LogRepository 는 트랜잭션C와 관련된 con2 를 사용한다.
로그예외 라는 이름을 전달해서 LogRepository 에 런타임 예외가 발생한다.
LogRepository 는 해당 예외를 밖으로 던진다. 이 경우 트랜잭션 AOP가 예외를 받게된다.
런타임 예외가 발생해서 트랜잭션 AOP는 트랜잭션 매니저에 롤백을 호출한다.
트랜잭션 매니저는 신규 트랜잭션이므로 물리 롤백을 호출한다.
참고 트랜잭션 AOP도 결국 내부에서는 트랜잭션 매니저를 사용하게 된다.
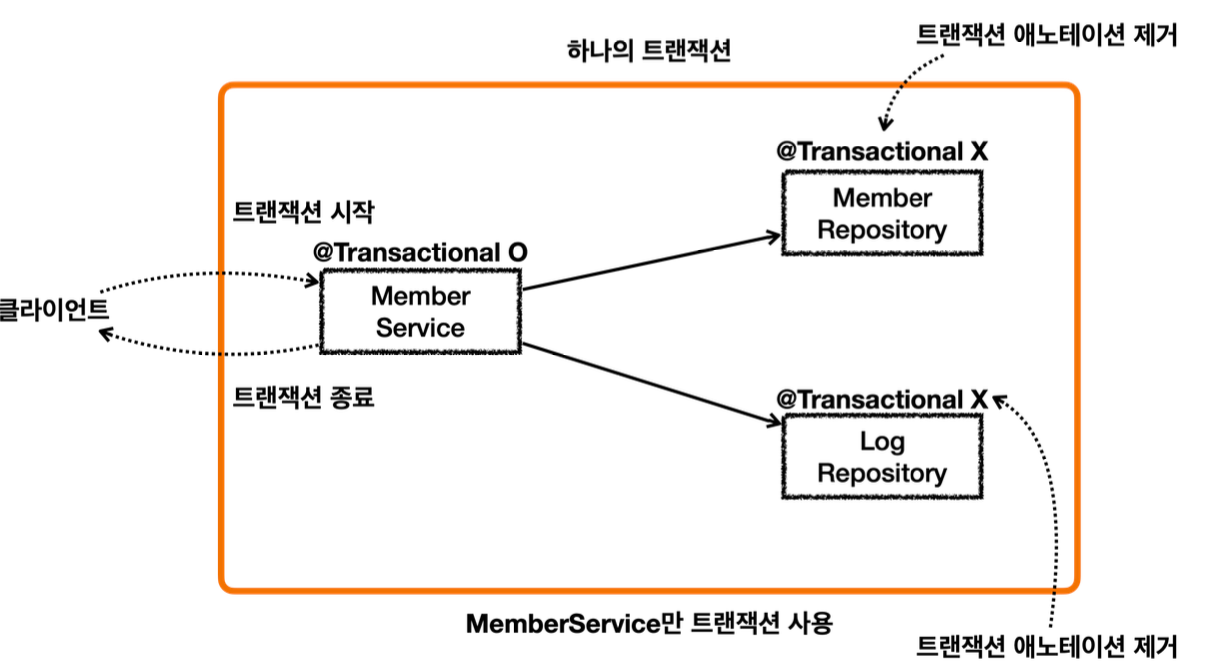
단일 트랜잭션
/**
* MemberService @Transactional:ON
* MemberRepository @Transactional:OFF
* LogRepository @Transactional:OFF
*/
@Test
void singleTx() {
//given
String username = "singleTx";
//when
memberService.joinV1(username);
//then: 모든 데이터가 정상 저장된다.
assertTrue(memberRepository.find(username).isPresent());
assertTrue(logRepository.find(username).isPresent());
}
이렇게 하면 MemberService 를 시작할 때 부터 종료할 때 까지의 모든 로직을 하나의 트랜잭션으로 묶을 수 있다. 물론 MemberService 가 MemberRepository , LogRepository 를 호출하므로 이 로직들은 같은 트랜잭션을 사용한다.
MemberService 만 트랜잭션을 처리하기 때문에 앞서 배운 논리 트랜잭션, 물리 트랜잭션, 외부 트랜잭션, 내부 트랜잭션, rollbackOnly , 신규 트랜잭션, 트랜잭션 전파와 같은 복잡한 것을 고민할 필요가 없다. 아주 단순하고 깔끔하게 트랜잭션을 묶을 수 있다.
@Transactional 이 MemberService 에만 붙어있기 때문에 여기에만 트랜잭션 AOP가 적용된다.
MemberRepository, LogRepository 는 트랜잭션 AOP가 적용되지 않는다.
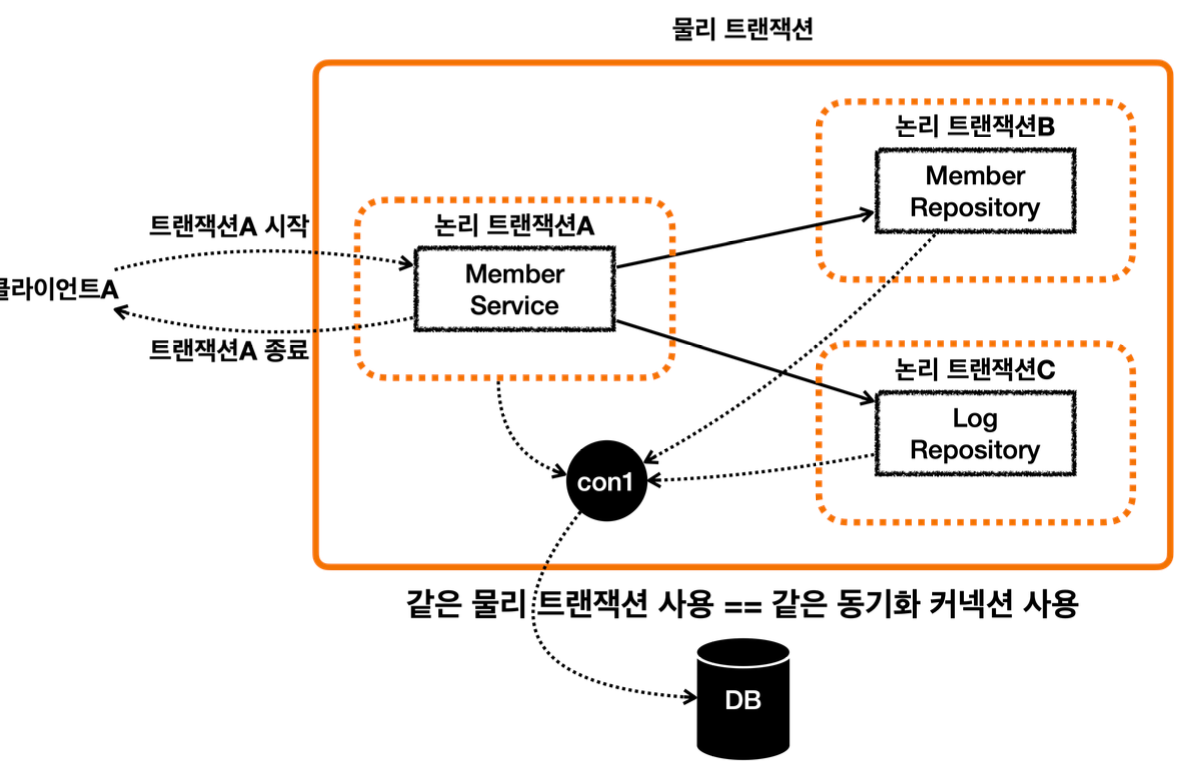
MemberService 의 시작부터 끝까지, 관련 로직은 해당 트랜잭션이 생성한 커넥션을 사용하게 된다.
MemberService 가 호출하는 MemberRepository , LogRepository 도 같은 커넥션을 사용하면서 자연스럽게 트랜잭션 범위에 포함된다.
참고 같은 쓰레드를 사용하면 트랜잭션 동기화 매니저는 같은 커넥션을 반환한다.
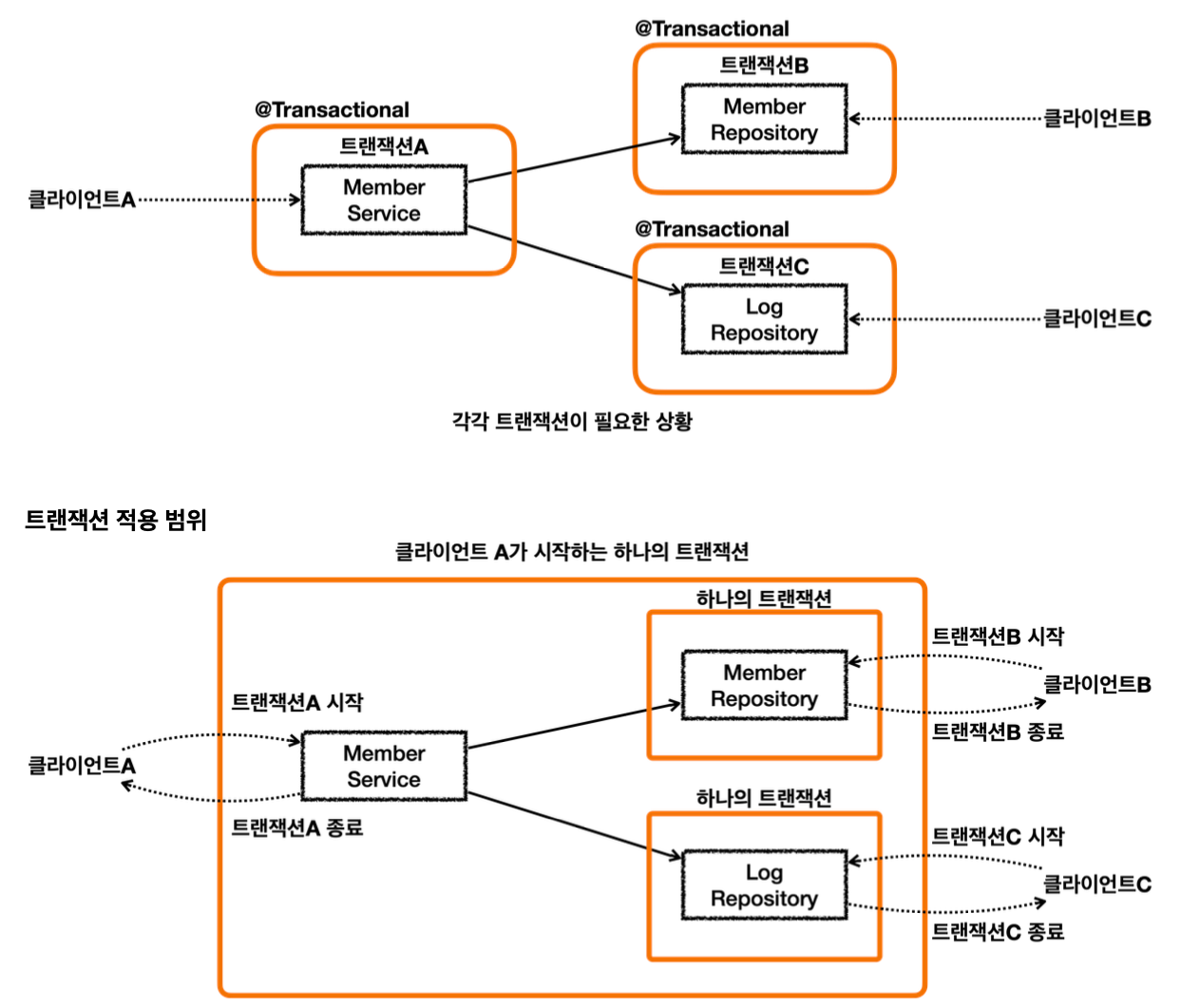
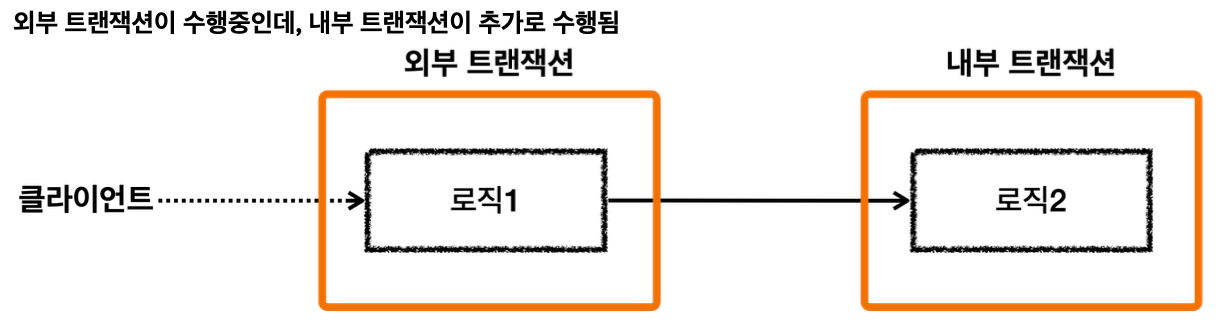
트랜잭션 전파
각각 트랜잭션이 필요한 상황
클라이언트 A는 MemberService 부터 MemberRepository, LogRepository 를 모두 하나의 트랜잭션으로 묶고 싶다.
클라이언트 B는 MemberRepository 만 호출하고 여기에만 트랜잭션을 사용하고 싶다.
클라이언트 C는 LogRepository 만 호출하고 여기에만 트랜잭션을 사용하고 싶다.
클라이언트 A만 생각하면 MemberService 에 트랜잭션 코드를 남기고, MemberRepository , LogRepository 의 트랜잭션 코드를 제거하면 깔끔하게 하나의 트랜잭션을 적용할 수 있다.
하지만 이렇게 되면 클라이언트 B, C가 호출하는 MemberRepository, LogRepository 에는 트랜잭션을 적용할 수 없다.
트랜잭션 전파 없이 이런 문제를 해결하려면 아마도 트랜잭션이 있는 메서드와 트랜잭션이 없는 메서드를 각각 만들어야 할 것이다.
더 복잡하게 다음과 같은 상황이 발생할 수도 있다.
클라이언트 Z가 호출하는 OrderService 에서도 트랜잭션을 시작할 수 있어야 하고, 클라이언트A가 호출하는 MemberService 에서도 트랜잭션을 시작할 수 있어야 한다.
이런 문제를 해결하기 위해 트랜잭션 전파가 필요한 것이다.
전파 커밋
@Transactional 이 적용되어 있으면 기본으로 REQUIRED 라는 전파 옵션을 사용한다.
이 옵션은 기존 트랜잭션이 없으면 트랜잭션을 생성하고, 기존 트랜잭션이 있으면 기존 트랜잭션에 참여한다. 참여한다는 뜻은 해당 트랜잭션을 그대로 따른다는 뜻이고, 동시에 같은 동기화 커넥션을 사용한다는 뜻이다.
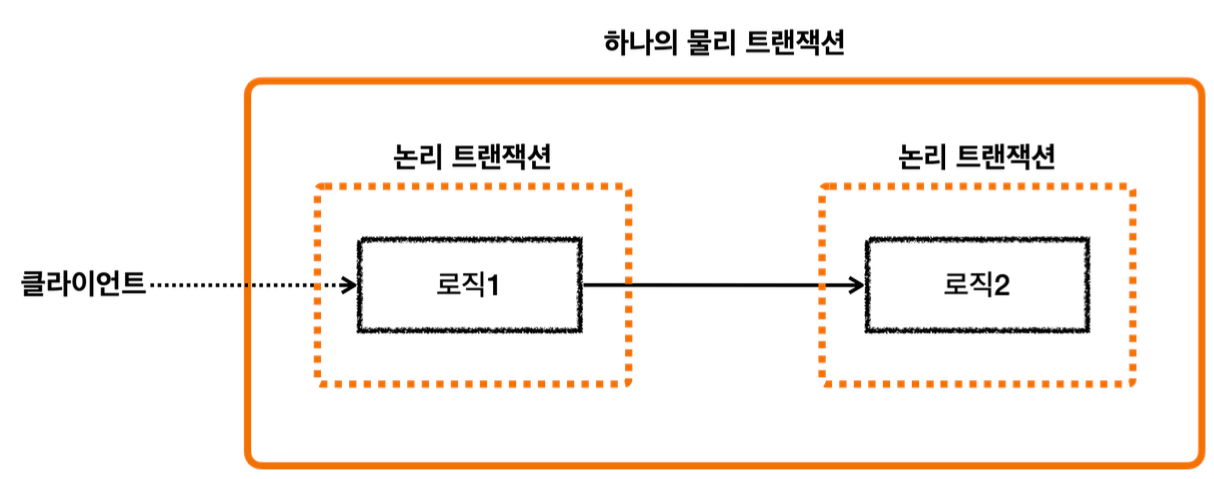
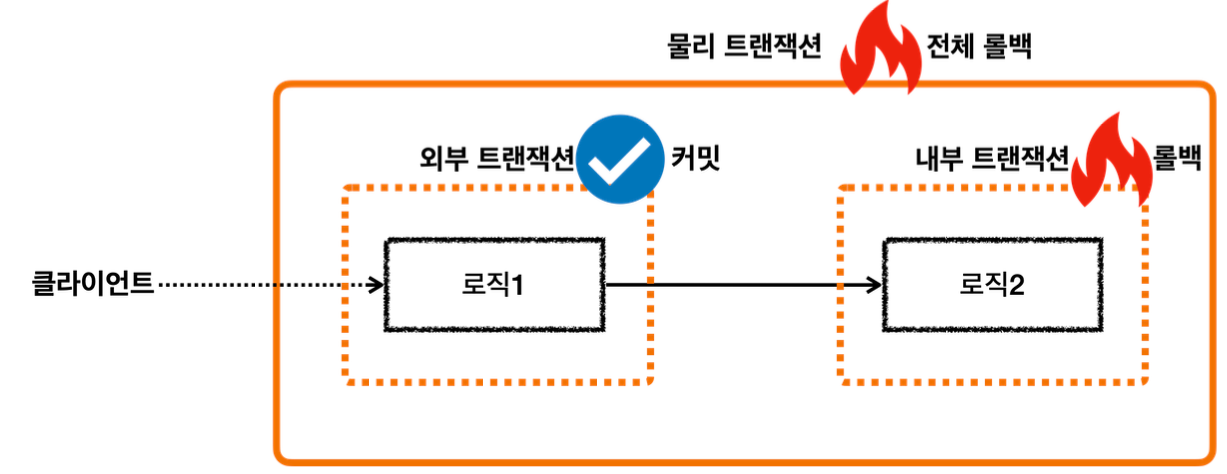
이렇게 둘 이상의 트랜잭션이 하나의 물리 트랜잭션에 묶이게 되면 둘을 구분하기 위해 논리 트랜잭션과 물리 트랜잭션으로 구분한다.
이 경우 외부에 있는 신규 트랜잭션만 실제 물리 트랜잭션을 시작하고 커밋한다.
내부에 있는 트랜잭션은 물리 트랜잭션 시작하거나 커밋하지 않는다.
모든 논리 트랜잭션을 커밋해야 물리 트랜잭션도 커밋된다. 하나라도 롤백되면 물리 트랜잭션은 롤백된다.
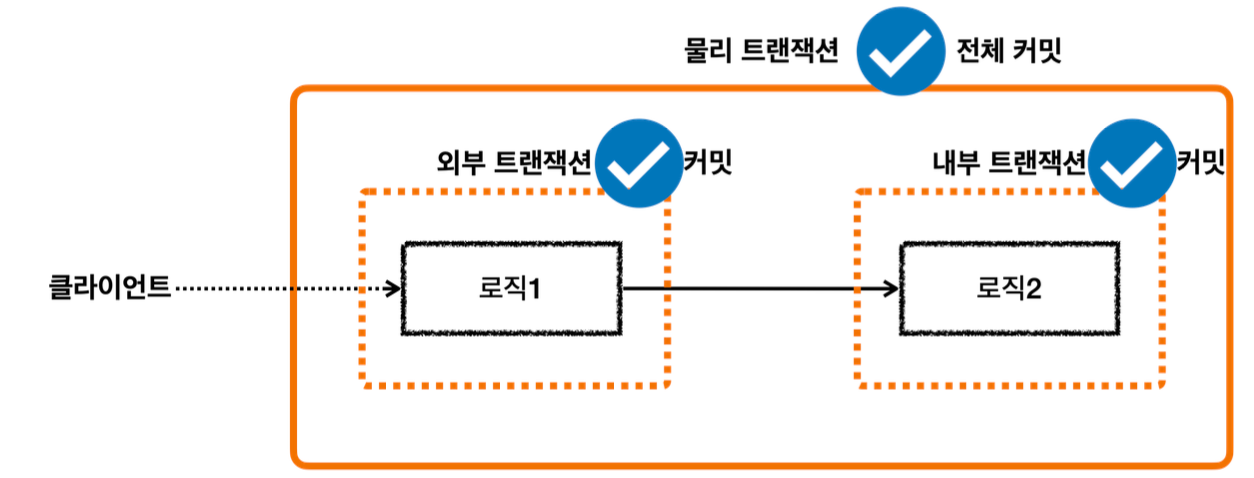
모든 논리 트랜잭션이 정상 커밋되는 경우
회원 리포지토리와 로그 리포지토리를 하나의 트랜잭션으로 묶는 가장 간단한 방법은 이 둘을 호출하는 회원 서비스에만 트랜잭션을 사용하는 것이다.
/**
* MemberService @Transactional:ON
* MemberRepository @Transactional:ON
* LogRepository @Transactional:ON
*/
@Test
void outerTxOn_success() {
//given
String username = "outerTxOn_success";
//when
memberService.joinV1(username);
//then: 모든 데이터가 정상 저장된다.
assertTrue(memberRepository.find(username).isPresent());
assertTrue(logRepository.find(username).isPresent());
}
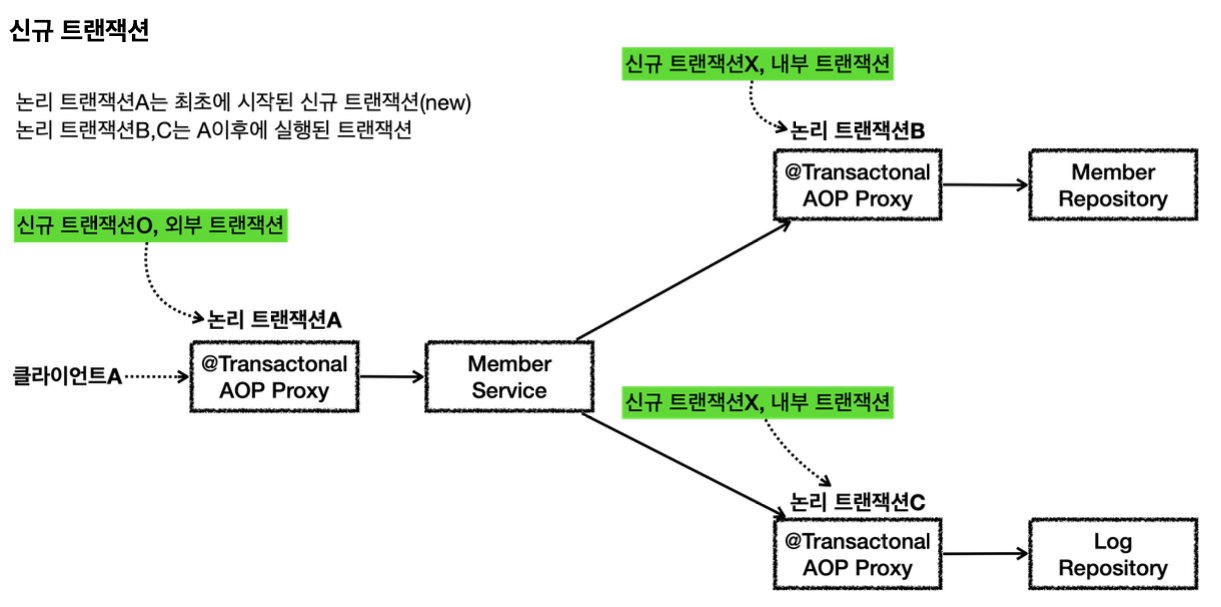
클라이언트A(여기서는 테스트 코드)가 MemberService 를 호출하면서 트랜잭션 AOP가 호출된다. -여기서 신규 트랜잭션이 생성되고, 물리 트랜잭션도 시작한다.
MemberRepository 를 호출하면서 트랜잭션 AOP가 호출된다. -이미 트랜잭션이 있으므로 기존 트랜잭션에 참여한다.
MemberRepository 의 로직 호출이 끝나고 정상 응답하면 트랜잭션 AOP가 호출된다. -트랜잭션 AOP는 정상 응답이므로 트랜잭션 매니저에 커밋을 요청한다. 이 경우 신규 트랜잭션이 아니므로 실제 커밋을 호출하지 않는다.
LogRepository 를 호출하면서 트랜잭션 AOP가 호출된다. -이미 트랜잭션이 있으므로 기존 트랜잭션에 참여한다.
LogRepository 의 로직 호출이 끝나고 정상 응답하면 트랜잭션 AOP가 호출된다. -트랜잭션 AOP는 정상 응답이므로 트랜잭션 매니저에 커밋을 요청한다. 이 경우 신규 트랜잭션이 아니므로 실제 커밋(물리 커밋)을 호출하지 않는다.
MemberService 의 로직 호출이 끝나고 정상 응답하면 트랜잭션 AOP가 호출된다. -트랜잭션 AOP는 정상 응답이므로 트랜잭션 매니저에 커밋을 요청한다. 이 경우 신규 트랜잭션이므로 물리 커밋을 호출한다.
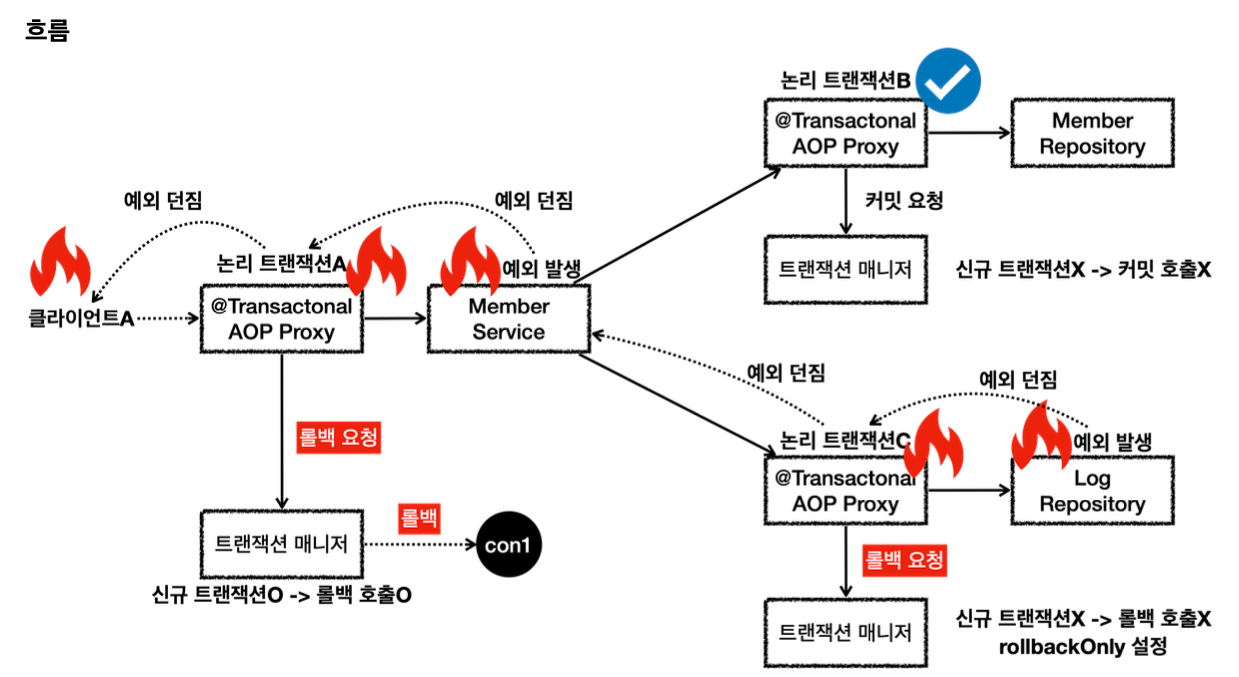
클라이언트A가 MemberService를 호출하면서 트랜잭션 AOP가 호출된다. -여기서 신규 트랜잭션이 생성되고, 물리 트랜잭션도 시작한다.
MemberRepository를 호출하면서 트랜잭션 AOP가 호출된다. -이미 트랜잭션이 있으므로 기존 트랜잭션에 참여한다.
MemberRepository의 로직 호출이 끝나고 정상 응답하면 트랜잭션 AOP가 호출된다. -트랜잭션 AOP는 정상 응답이므로 트랜잭션 매니저에 커밋을 요청한다. 이 경우 신규 트랜잭션이 아니므로 실제 커밋을 호출하지 않는다.
LogRepository를 호출하면서 트랜잭션 AOP가 호출된다. -이미 트랜잭션이 있으므로 기존 트랜잭션에 참여한다.
LogRepository 로직에서 런타임 예외가 발생한다. 예외를 던지면 트랜잭션 AOP가 해당 예외를 받게 된다. -트랜잭션 AOP는 런타임 예외가 발생했으므로 트랜잭션 매니저에 롤백을 요청한다. 이 경우 신규 트랜잭션이 아니므로 물리 롤백을 호출하지는 않는다. 대신에 rollbackOnly를 설정한다. -LogRepository가 예외를 던졌기 때문에 트랜잭션 AOP도 해당 예외를 그대로 밖으로 던진다.
MemberService에서도 런타임 예외를 받게 되는데, 여기 로직에서는 해당 런타임 예외를 처리하지 않고 밖으로 던진다. -트랜잭션 AOP는 런타임 예외가 발생했으므로 트랜잭션 매니저에 롤백을 요청한다. 이 경우 신규 트랜잭션이므로 물리 롤백을 호출한다. -참고로 이 경우 어차피 롤백이 되었기 때문에, rollbackOnly 설정은 참고하지 않는다. -MemberService가 예외를 던졌기 때문에 트랜잭션 AOP도 해당 예외를 그대로 밖으로 던진다.
클라이언트A는 LogRepository부터 넘어온 런타임 예외를 받게 된다.
회원과 회원 이력 로그를 처리하는 부분을 하나의 트랜잭션으로 묶은 덕분에 문제가 발생했을 때 회원과 회원 이력 로그가 모두 함께 롤백된다. 따라서 데이터 정합성에 문제가 발생하지 않는다.
예외가 발생해서 일부 커밋, 일부 롤백
회원 이력 로그를 DB에 남기는 작업에 가끔 문제가 발생해서 회원 가입 자체가 안되는 경우가 가끔 발생하게 되었다.
그래서 사용자들이 회원 가입에 실패해서 이탈하는 문제가 발생하기 시작했다.
회원 이력 로그의 경우 여러가지 방법으로 추후에 복구가 가능할 것으로 보인다.
그래서 비즈니스 요구사항이 변경되었다. 회원 가입을 시도한 로그를 남기는데 실패하더라도 회원 가입은 유지되어야 한다.
단순하게 생각해보면 LogRepository 에서 예외가 발생하면 그것을 MemberService 에서 예외를 잡아서 처리하면 될 것 같다.
이렇게 하면 MemberService 에서 정상 흐름으로 바꿀 수 있기 때문에 MemberService 의 트랜잭션 AOP에서 커밋을 수행할 수 있다.
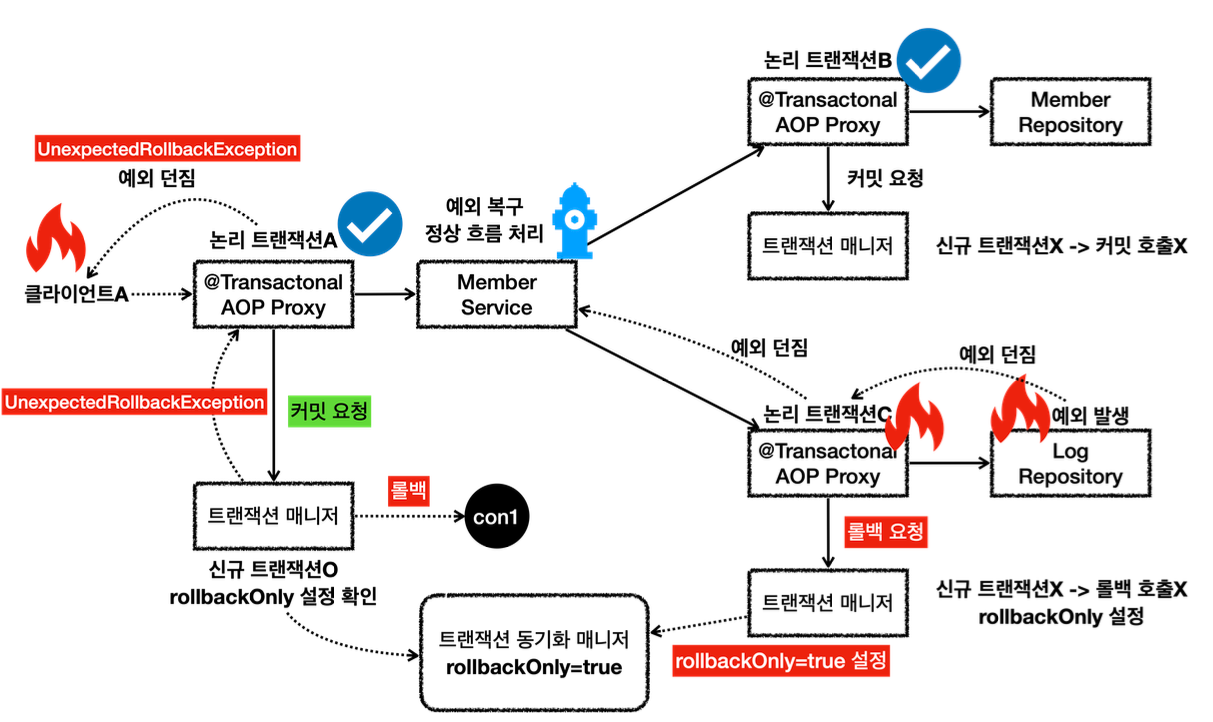
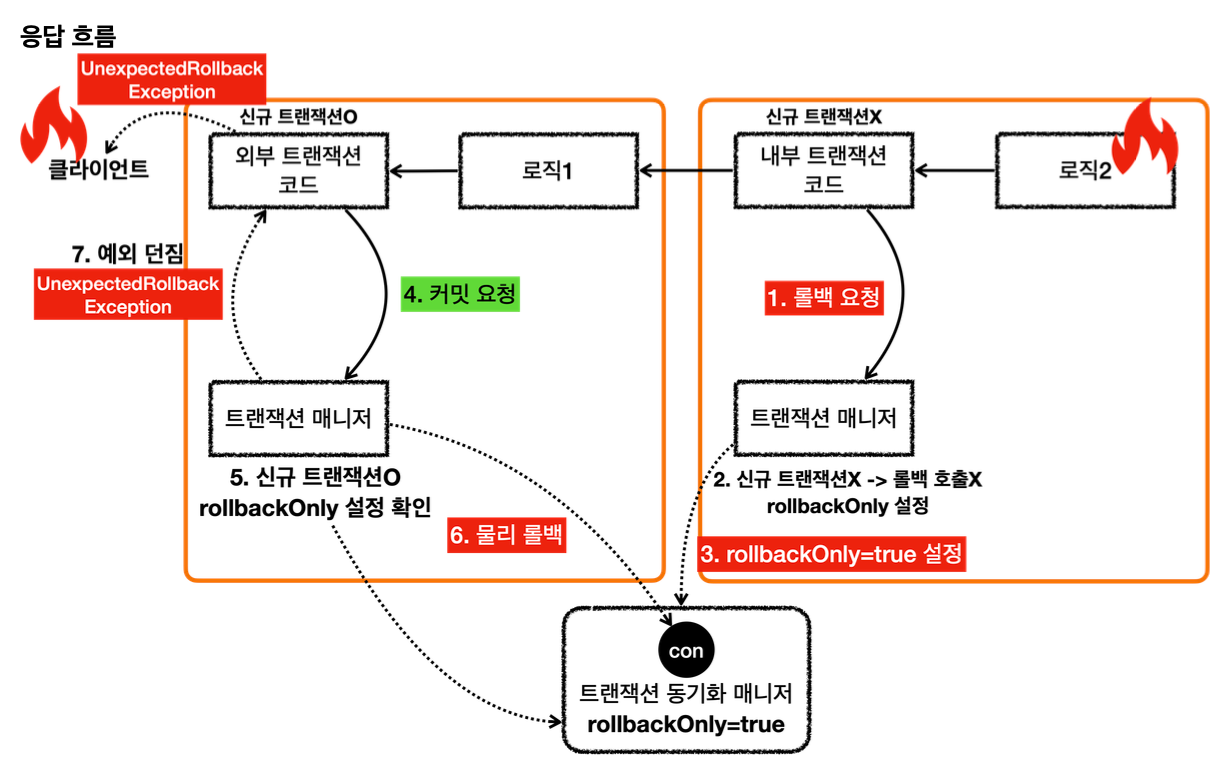
내부 트랜잭션에서 rollbackOnly 를 설정하기 때문에 결과적으로 정상 흐름 처리를 해서 외부 트랜잭션에서 커밋을 호출해도 물리 트랜잭션은 롤백된다. 그리고 UnexpectedRollbackException 이 던져진다.
LogRepository 에서 예외가 발생한다. 예외를 던지면 LogRepository 의 트랜잭션 AOP가 해당 예외를 받는다.
신규 트랜잭션이 아니므로 물리 트랜잭션을 롤백하지는 않고, 트랜잭션 동기화 매니저에 rollbackOnly 를 표시한다.
이후 트랜잭션 AOP는 전달 받은 예외를 밖으로 던진다.
예외가 MemberService 에 던져지고, MemberService 는 해당 예외를 복구한다. 그리고 정상적으로 리턴한다.
정상 흐름이 되었으므로 MemberService 의 트랜잭션 AOP는 커밋을 호출한다.
커밋을 호출할 때 신규 트랜잭션이므로 실제 물리 트랜잭션을 커밋해야 한다. 이때 rollbackOnly 를 체크한다.
rollbackOnly 가 체크 되어 있으므로 물리 트랜잭션을 롤백한다.
트랜잭션 매니저는 UnexpectedRollbackException 예외를 던진다.
트랜잭션 AOP도 전달받은 UnexpectedRollbackException 을 클라이언트에 던진다.
정리 -논리 트랜잭션 중 하나라도 롤백되면 전체 트랜잭션은 롤백된다. -내부 트랜잭션이 롤백 되었는데, 외부 트랜잭션이 커밋되면 UnexpectedRollbackException 예외가 발생한다. -rollbackOnly 상황에서 커밋이 발생하면 UnexpectedRollbackException 예외가 발생한다.
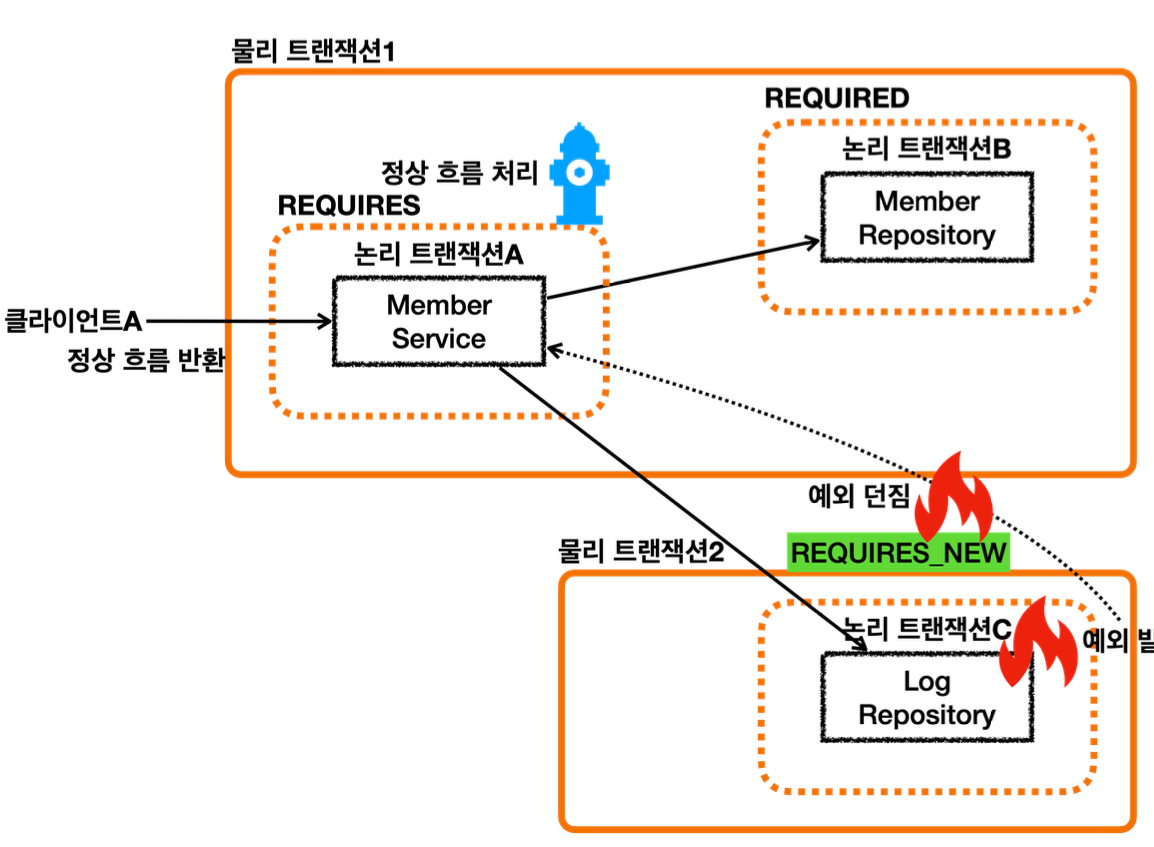
MemberRepository 는 REQUIRED 옵션을 사용한다. 따라서 기존 트랜잭션에 참여한다.
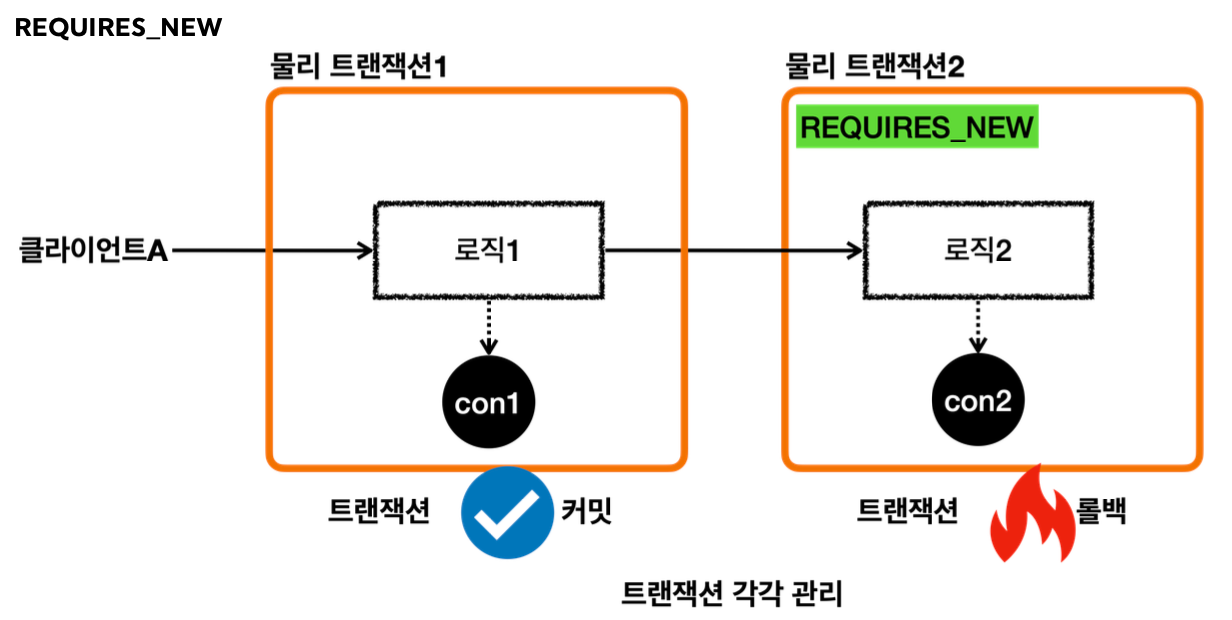
LogRepository 의 트랜잭션 옵션에 REQUIRES_NEW 를 사용했다.
REQUIRES_NEW 는 항상 새로운 트랜잭션을 만든다. 따라서 해당 트랜잭션 안에서는 DB 커넥션도 별도로 사용하게 된다.
REQUIRES_NEW 를 사용하게 되면 물리 트랜잭션 자체가 완전히 분리되어 버린다.
그리고 REQUIRES_NEW 는 신규 트랜잭션이므로 rollbackOnly 표시가 되지 않는다. 그냥 해당 트랜잭션이 물리 롤백되고 끝난다.
LogRepository에서 예외가 발생한다. 예외를 던지면 LogRepository의 트랜잭션 AOP가 해당 예외를 받는다.
REQUIRES_NEW를 사용한 신규 트랜잭션이므로 물리 트랜잭션을 롤백한다. 물리 트랜잭션을 롤백했으므로 rollbackOnly를 표시하지 않는다. 여기서 REQUIRES_NEW를 사용한 물리 트랜잭션은 롤백되고 완전히 끝이 난다.
이후 트랜잭션 AOP는 전달 받은 예외를 밖으로 던진다.
예외가 MemberService에 던져지고, MemberService는 해당 예외를 복구한다. 그리고 정상적으로 리턴한다.
정상 흐름이 되었으므로 MemberService의 트랜잭션 AOP는 커밋을 호출한다.
커밋을 호출할 때 신규 트랜잭션이므로 실제 물리 트랜잭션을 커밋해야 한다. 이때 rollbackOnly를 체크한다.
rollbackOnly가 없으므로 물리 트랜잭션을 커밋한다.
이후 정상 흐름이 반환된다.
결과적으로 회원 데이터는 저장되고, 로그 데이터만 롤백 되는 것을 확인할 수 있다.
정리
-논리 트랜잭션은 하나라도 롤백되면 관련된 물리 트랜잭션은 롤백되어 버린다. -이 문제를 해결하려면 REQUIRES_NEW를 사용해서 트랜잭션을 분리해야 한다. -예제를 단순화 하기 위해 MemberService가 MemberRepository, LogRepository만 호출하지만 실제로는 더 많은 리포지토리들을 호출하고 그 중에 LogRepository만 트랜잭션을 분리한다고 생각해보면 이해하는데 도움이 될 것이다.
주의
REQUIRES_NEW를 사용하면 하나의 HTTP 요청에 동시에 2개의 데이터베이스 커넥션을 사용하게 된다. 따라서 성능이 중요한 곳에서는 이런 부분을 주의해서 사용해야 한다. REQUIRES_NEW를 사용하지 않고 문제를 해결할 수 있는 단순한 방법이 있다면, 그 방법을 선택하는 것이 더 좋다.
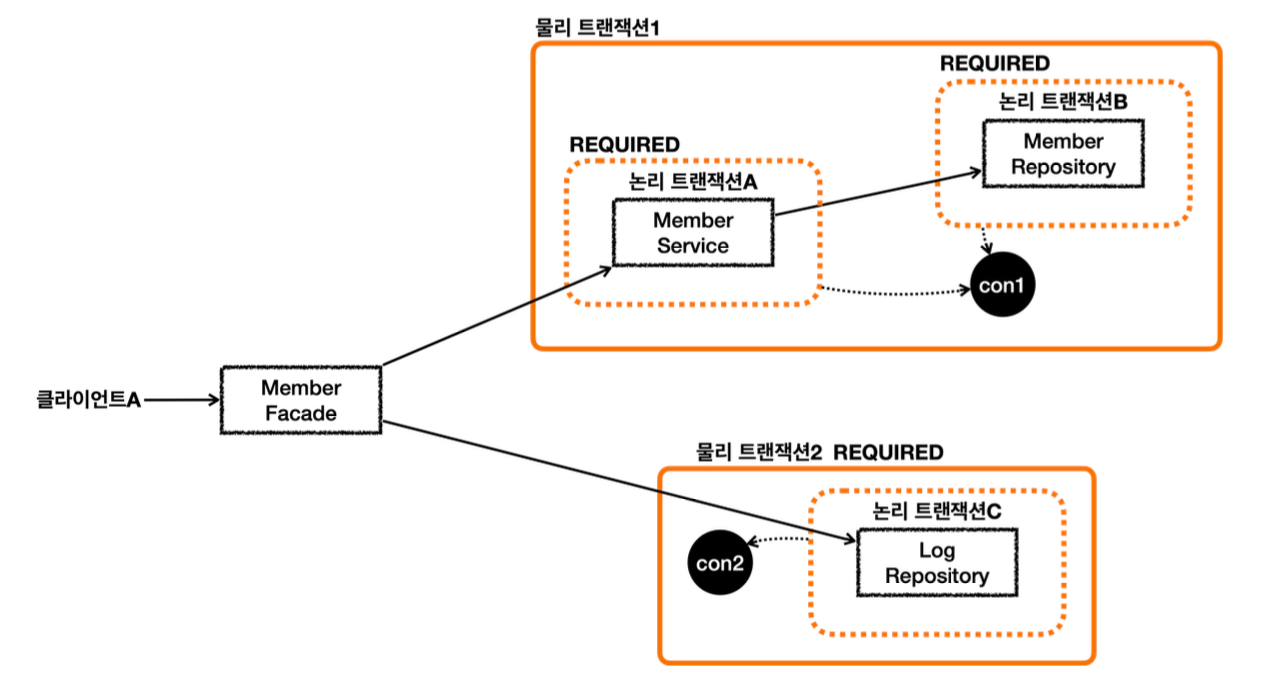
아래와 같이 REQUIRES_NEW 를 사용하지 않고 구조를 변경하는 것도 좋은 방법이다.
이렇게 하면 HTTP 요청에 동시에 2개의 커넥션을 사용하지는 않는다. 순차적으로 사용하고 반환하게 된다. 물론 구조상 REQUIRES_NEW 를 사용하는 것이 더 깔끔한 경우도 있으므로 각각의 장단점을 이해하고 적절하게 선택 해서 사용하면 된다.
@Slf4j
@SpringBootTest
public class BasicTxTest {
@Autowired
PlatformTransactionManager txManager;
@TestConfiguration
static class Config {
@Bean
public PlatformTransactionManager transactionManager(DataSource dataSource) {
return new DataSourceTransactionManager(dataSource);
}
}
@Test
void commit() {
log.info("트랜잭션 시작");
TransactionStatus status = txManager.getTransaction(new DefaultTransactionAttribute());
log.info("트랜잭션 커밋 시작");
txManager.commit(status);
log.info("트랜잭션 커밋 완료");
}
@Test
void rollback() {
log.info("트랜잭션 시작");
TransactionStatus status = txManager.getTransaction(new DefaultTransactionAttribute());
log.info("트랜잭션 롤백 시작");
txManager.rollback(status);
log.info("트랜잭션 롤백 완료");
}
}
@Autowired를 통해 PlatformTransactionManager의 인스턴스를 자동으로 주입받고 있다. 이는 스프링의 의존성 주입 기능을 활용하는 부분이다.
@TestConfiguration은 테스트 전용 설정을 정의할 때 사용되며, 이 예제에서는 데이터 소스로부터 트랜잭션 매니저(DataSourceTransactionManager)를 생성하고 빈으로 등록하는 설정을 포함하고 있다. 이렇게 함으로써 테스트 환경에서 데이터베이스 트랜잭션을 관리할 수 있게 된다.
commit 메소드와 rollback 메소드에서는 각각 트랜잭션을 시작, 커밋 또는 롤백하는 과정을 로깅으로 기록하고 있다. txManager.getTransaction(new DefaultTransactionAttribute())를 통해 새로운 트랜잭션을 시작하며, 이후 commit이나 rollback 메소드를 호출하여 트랜잭션을 완료한다.
외부 트랜잭션은 처음 수행된 트랜잭션이다. 이 경우 신규 트랜잭션( isNewTransaction=true)이 된다.
내부 트랜잭션을 시작하는 시점에는 이미 외부 트랜잭션이 진행중인 상태이다. 이 경우 내부 트랜잭션은 외부 트랜잭션에 참여한다.
트랜잭션 참여
내부 트랜잭션이 외부 트랜잭션에 참여한다는 뜻은 내부 트랜잭션이 외부 트랜잭션을 그대로 이어 받아서 따른다는 뜻이다. 다른 관점으로 보면 외부 트랜잭션의 범위가 내부 트랜잭션까지 넓어진다는 뜻이다. 외부에서 시작된 물리적인 트랜잭션의 범위가 내부 트랜잭션까지 넓어진다는 뜻이다.
정리하면 외부 트랜잭션과 내부 트랜잭션이 하나의 물리 트랜잭션으로 묶이는 것이다.
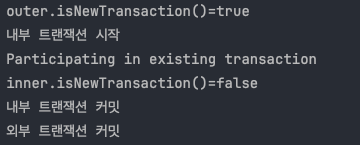
내부 트랜잭션은 이미 진행중인 외부 트랜잭션에 참여한다. 이 경우 신규 트랜잭션이 아니다 ( isNewTransaction=false)
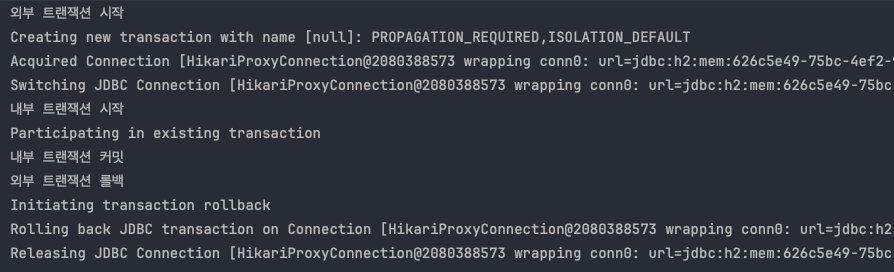
예제에서는 둘다 성공적으로 커밋했다.
내부 트랜잭션을 시작할 때 Participating in existing transaction 이라는 메시지를 확인할 수 있다.
이 메시지는 내부 트랜잭션이 기존에 존재하는 외부 트랜잭션에 참여한다는 뜻이다.
실행 결과를 보면 외부 트랜잭션을 시작하거나 커밋할 때는 DB 커넥션을 통한 물리 트랜잭션을 시작(manual commit)하고, DB 커넥션을 통해 커밋 하는 것을 확인할 수 있다.
그런데 내부 트랜잭션을 시작하거나 커밋할 때 는 DB 커넥션을 통해 커밋하는 로그를 전혀 확인할 수 없다.
정리하면 외부 트랜잭션만 물리 트랜잭션을 시작하고, 커밋한다.
만약 내부 트랜잭션이 실제 물리 트랜잭션을 커밋하면 트랜잭션이 끝나버리기 때문에, 트랜잭션을 처음 시작한 외부 트랜잭션까지 이어갈 수 없다.
따라서 내부 트랜잭션은 DB 커넥션을 통한 물리 트랜잭션을 커밋하면 안된다. 스프링은 이렇게 여러 트랜잭션이 함께 사용되는 경우, 처음 트랜잭션을 시작한 외부 트랜잭션이 실제 물리 트랜잭션을 관리하도록 한다.
이를 통해 트랜잭션 중복 커밋 문제를 해결한다.
위 과정을 그림으로 나타내면 아래와 같다.
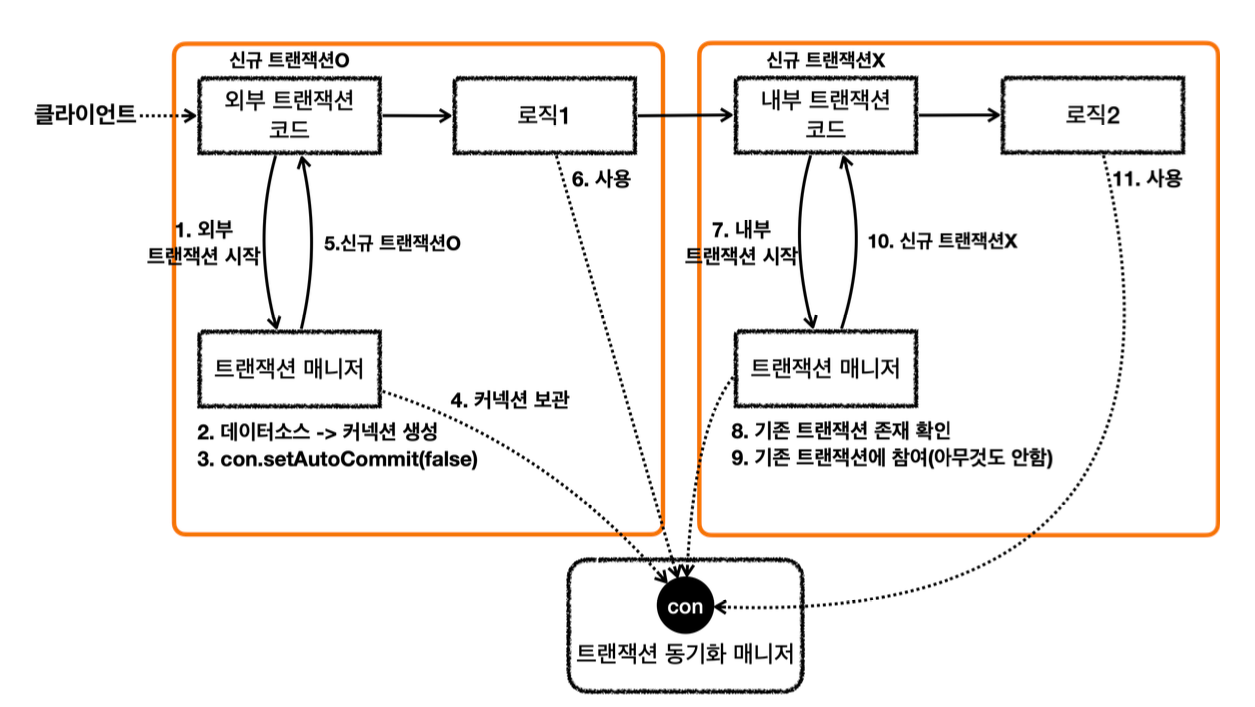
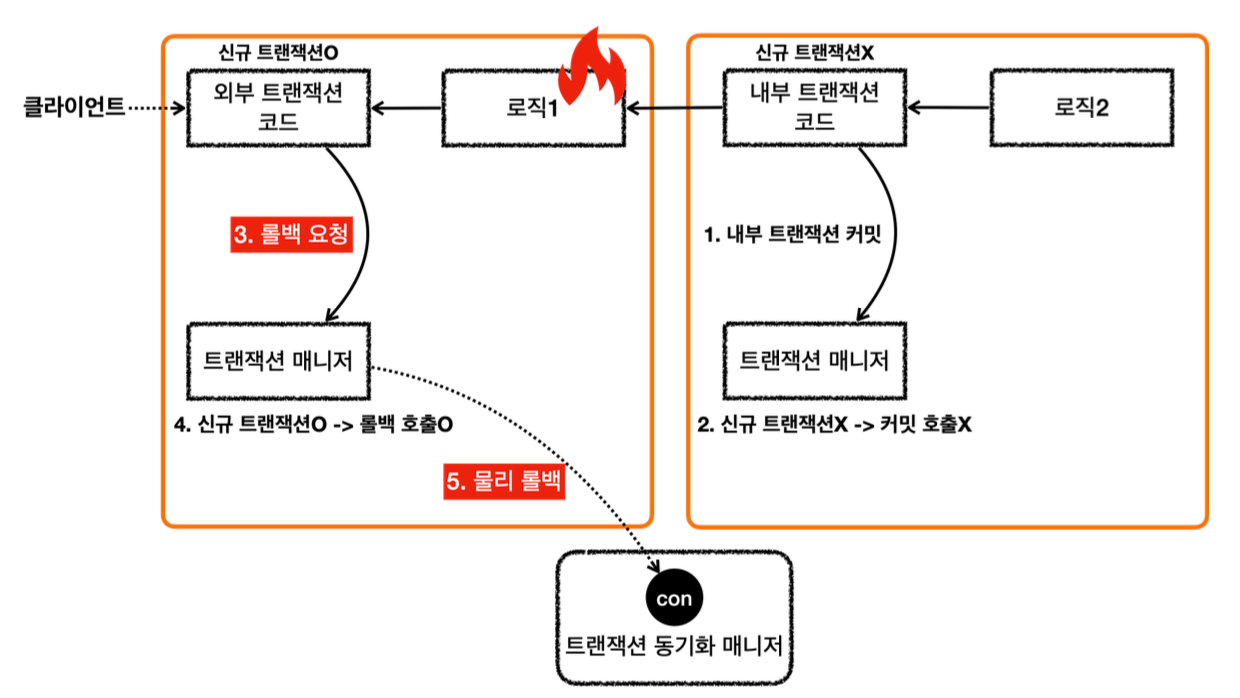
요청 흐름 - 외부 트랜잭션
1. txManager.getTransaction() 를 호출해서 외부 트랜잭션을 시작한다.
2. 트랜잭션 매니저는 데이터소스를 통해 커넥션을 생성한다.
3. 생성한 커넥션을 수동 커밋 모드(setAutoCommit(false))로 설정한다. - 물리 트랜잭션 시작
4. 트랜잭션 매니저는 트랜잭션 동기화 매니저에 커넥션을 보관한다.
5. 트랜잭션 매니저는 트랜잭션을 생성한 결과를 TransactionStatus 에 담아서 반환하는데, 여기에 신규 트랜잭션의 여부가 담겨 있다. isNewTransaction 를 통해 신규 트랜잭션 여부를 확인할 수 있다. 트랜잭션을 처음 시작했으므로 신규 트랜잭션이다.(true)
6. 로직1이 사용되고, 커넥션이 필요한 경우 트랜잭션 동기화 매니저를 통해 트랜잭션이 적용된 커넥션을 획득 해서 사용한다.
요청 흐름 - 내부 트랜잭션
7. txManager.getTransaction() 를 호출해서 내부 트랜잭션을 시작한다.
8. 트랜잭션 매니저는 트랜잭션 동기화 매니저를 통해서 기존 트랜잭션이 존재하는지 확인한다.
9. 기존 트랜잭션이 존재하므로 기존 트랜잭션에 참여한다. 기존 트랜잭션에 참여한다는 뜻은 사실 아무것도 하지 않는다는 뜻이다. -이미 기존 트랜잭션인 외부 트랜잭션에서 물리 트랜잭션을 시작했다. 그리고 물리 트랜잭션이 시작된 커넥션을 트랜잭션 동기화 매니저에 담아두었다. -따라서 이미 물리 트랜잭션이 진행중이므로 그냥 두면 이후 로직이 기존에 시작된 트랜잭션을 자연스럽게 사용하게 되는 것이다. -이후 로직은 자연스럽게 트랜잭션 동기화 매니저에 보관된 기존 커넥션을 사용하게 된다.
10. 트랜잭션 매니저는 트랜잭션을 생성한 결과를 TransactionStatus 에 담아서 반환하는데, 여기에서 isNewTransaction 를 통해 신규 트랜잭션 여부를 확인할 수 있다. 여기서는 기존 트랜잭션에 참여했기 때문에 신규 트랜잭션이 아니다. (false)
11. 로직2가 사용되고, 커넥션이 필요한 경우 트랜잭션 동기화 매니저를 통해 외부 트랜잭션이 보관한 커넥션을 획득해서 사용한다.
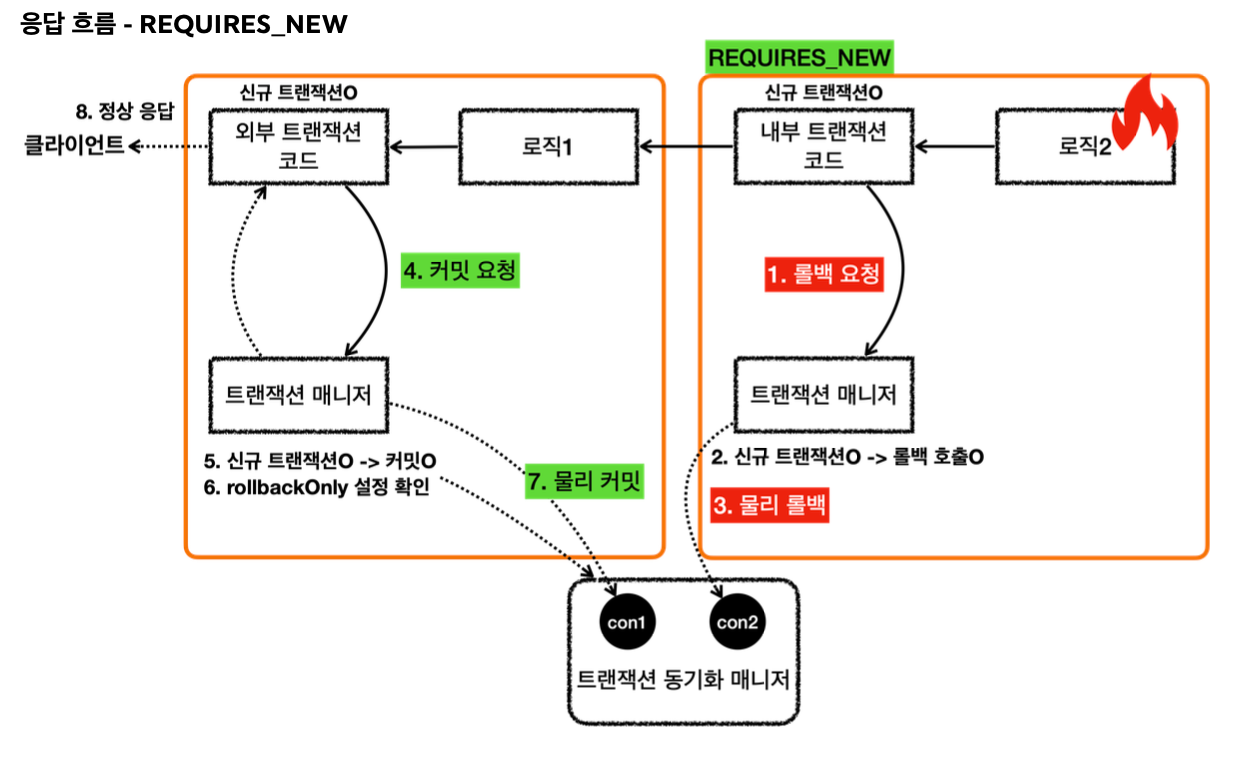
응답 흐름 - 내부 트랜잭션
12. 로직2가 끝나고 트랜잭션 매니저를 통해 내부 트랜잭션을 커밋한다.
13. 트랜잭션 매니저는 커밋 시점에 신규 트랜잭션 여부에 따라 다르게 동작한다. 이 경우 신규 트랜잭션이 아니기 때문에 실제 커밋을 호출하지 않는다. 실제 커넥션에 커밋이나 롤백을 호출하면 물리 트랜잭션이 끝나버린다. 아직 트랜잭션이 끝난 것이 아니기 때문에 실제 커밋을 호출하면 안된다. 물리 트랜잭션은 외부 트랜잭션을 종료할 때까지 이어져야한다.
응답 흐름 - 외부 트랜잭션
14. 로직1이 끝나고 트랜잭션 매니저를 통해 외부 트랜잭션을 커밋한다.
15. 트랜잭션 매니저는 커밋 시점에 신규 트랜잭션 여부에 따라 다르게 동작한다. 외부 트랜잭션은 신규 트랜잭션이다. 따라서 DB 커넥션에 실제 커밋을 호출한다.
16. 트랜잭션 매니저에 커밋하는 것이 논리적인 커밋이라면, 실제 커넥션에 커밋하는 것을 물리 커밋이라 할 수 있다. 실제 데이터베이스에 커밋이 반영되고, 물리 트랜잭션도 끝난다.
핵심 정리
핵심은 트랜잭션 매니저에 커밋을 호출한다고해서 항상 실제 커넥션에 물리 커밋이 발생하지는 않는다는 점이다.
신규 트랜잭션인 경우에만 실제 커넥션을 사용해서 물리 커밋과 롤백을 수행한다. 신규 트랜잭션이 아니면 실제 물리 커넥션을 사용하지 않는다.
이렇게 트랜잭션이 내부에서 추가로 사용되면 트랜잭션 매니저에 커밋하는 것이 항상 물리 커밋으로 이어지지 않는다. 그래서 이 경우 논리 트랜잭션과 물리 트랜잭션을 나누게 된다. 또는 외부 트랜잭션과 내부 트랜잭션으로 나누어 설명하기도 한다.
트랜잭션이 내부에서 추가로 사용되면, 트랜잭션 매니저를 통해 논리 트랜잭션을 관리하고, 모든 논리 트랜잭션이 커밋되면 물리 트랜잭션이 커밋된다고 이해하면 된다.
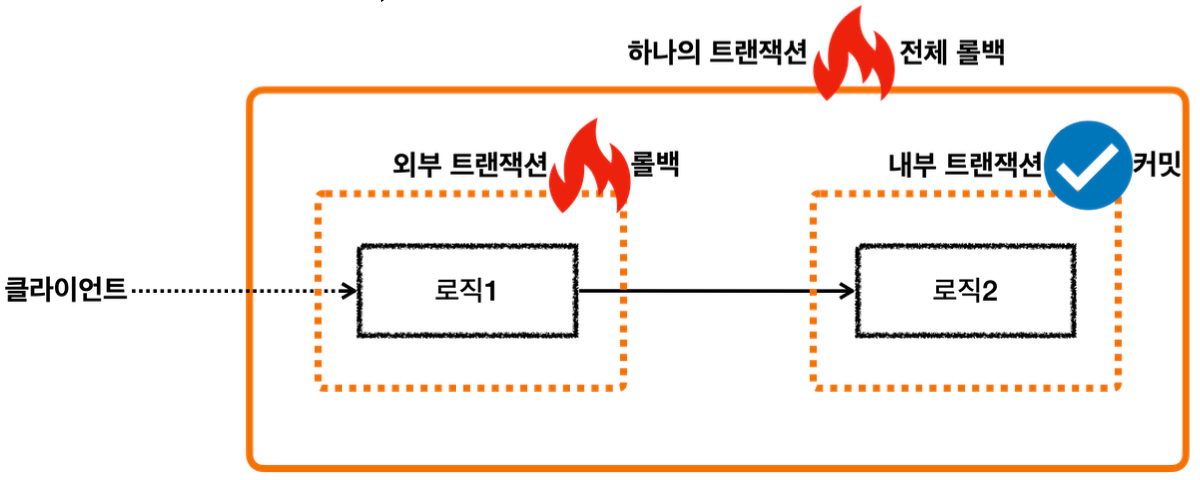
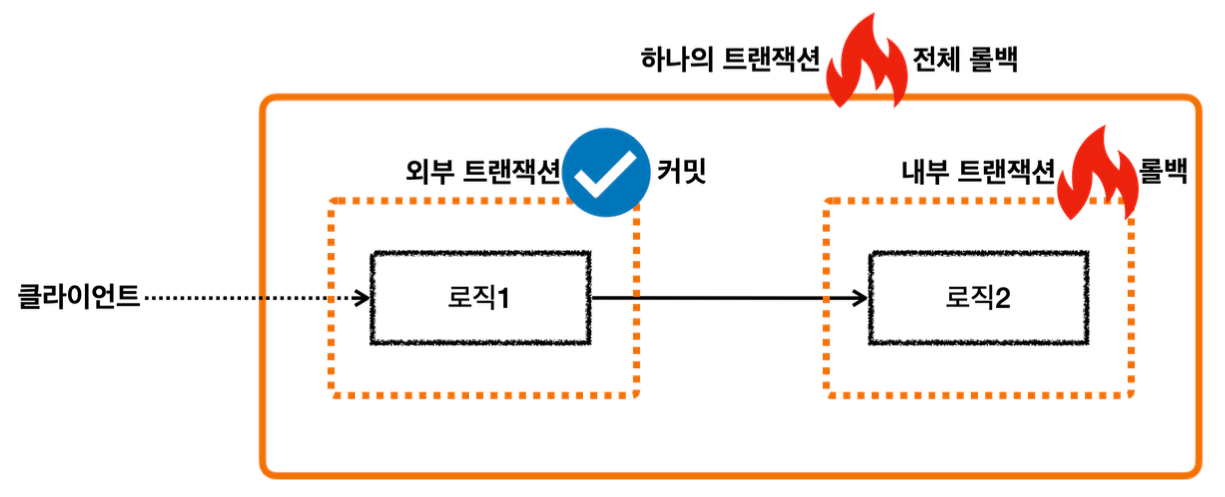
외부 롤백과 내부 롤백
외부 롤백
내부 트랜잭션은 커밋되는데, 외부 트랜잭션이 롤백되는 상황
논리 트랜잭션이 하나라도 롤백되면 전체 물리 트랜잭션은 롤백된다.
따라서 이 경우 내부 트랜잭션이 커밋했어도, 내부 트랜잭션 안에서 저장한 데이터도 모두 함께 롤백된다.
2. 트랜잭션 매니저는 커밋 시점에 신규 트랜잭션 여부에 따라 다르게 동작한다. 이 경우 신규 트랜잭션이 아니기 때문에 실제 커밋을 호출하지 않는다. 실제 커넥션에 커밋이나 롤백을 호출하면 물리 트랜잭션이 끝나버린다. 아직 트랜잭션이 끝난 것이 아니기 때문에 실제 커밋을 호출하면 안된다. 물리 트랜잭션은 외부 트랜잭션을 종료할 때까지 이어져야한다.
응답 흐름 - 외부 트랜잭션
3. 로직1이 끝나고 트랜잭션 매니저를 통해 외부 트랜잭션을 롤백한다.
4. 트랜잭션 매니저는 롤백 시점에 신규 트랜잭션 여부에 따라 다르게 동작한다. 외부 트랜잭션은 신규 트랜잭션이다. 따라서 DB 커넥션에 실제 롤백을 호출한다.
5. 트랜잭션 매니저에 롤백하는 것이 논리적인 롤백이라면, 실제 커넥션에 롤백하는 것을 물리 롤백이라 할 수 있다. 실제 데이터베이스에 롤백이 반영되고, 물리 트랜잭션도 끝난다.
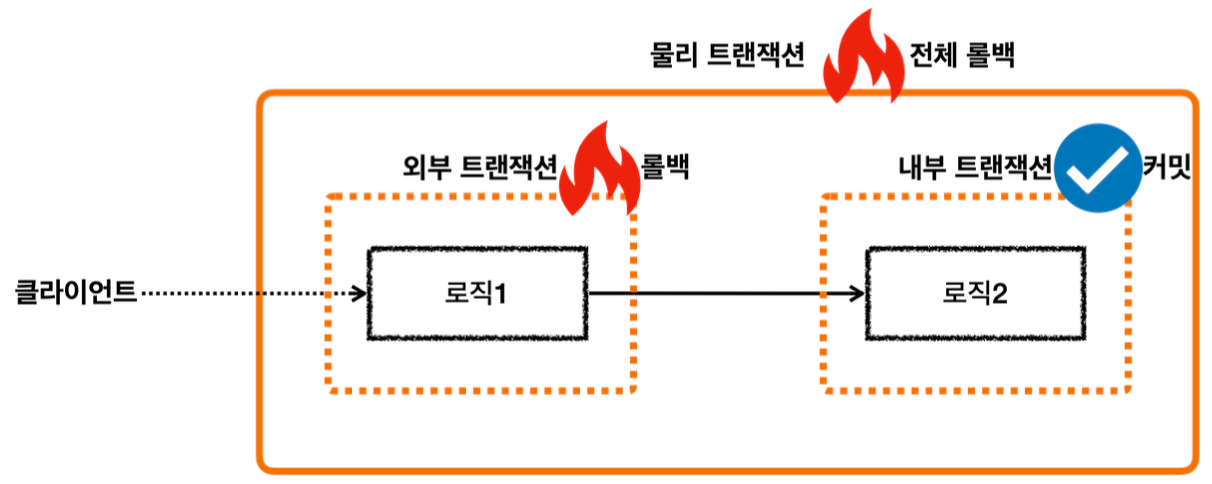
내부 롤백
내부 트랜잭션은 롤백되는데, 외부 트랜잭션이 커밋되는 상황
내부 트랜잭션이 롤백을 했지만, 내부 트랜잭션은 물리 트랜잭션에 영향을 주지 않는다. 그런데 외부 트랜잭션은 커밋을 해버린다.
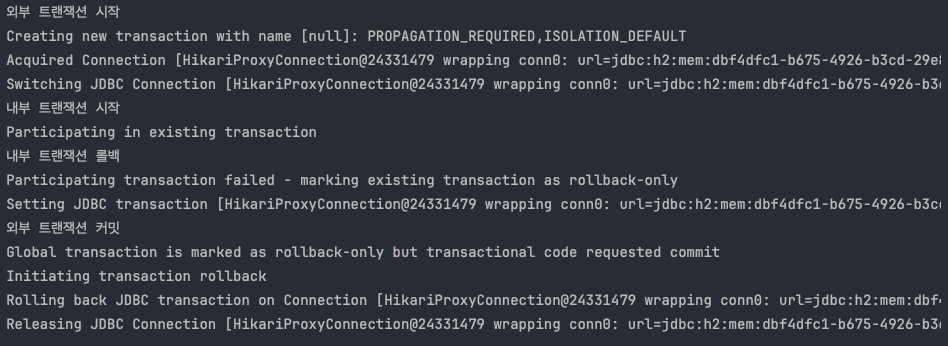
Participating transaction failed - marking existing transaction as rollback-only
내부 트랜잭션을 롤백하면 실제 물리 트랜잭션은 롤백하지 않는다. 대신에 기존 트랜잭션을 롤백 전용으로 표시한다.
외부 트랜잭션 커밋
외부 트랜잭션을 커밋한다.
Global transaction is marked as rollback-only
커밋을 호출했지만, 전체 트랜잭션이 롤백 전용으로 표시되어 있다. 따라서 물리 트랜잭션을 롤백한다.
응답 흐름 - 내부 트랜잭션
1. 로직2가 끝나고 트랜잭션 매니저를 통해 내부 트랜잭션을 롤백한다. (로직2에 문제가 있어서 롤백한다고 가정한다.)
2. 트랜잭션 매니저는 롤백 시점에 신규 트랜잭션 여부에 따라 다르게 동작한다. 이 경우 신규 트랜잭션이 아니 기 때문에 실제 롤백을 호출하지 않는다. 실제 커넥션에 커밋이나 롤백을 호출하면 물리 트랜잭션이 끝나버린다. 아직 트랜잭션이 끝난 것이 아니기 때문에 실제 롤백을 호출하면 안된다. 물리 트랜잭션은 외부 트랜잭션을 종료할 때 까지 이어져야한다.
3. 내부 트랜잭션은 물리 트랜잭션을 롤백하지 않는 대신에 트랜잭션 동기화 매니저에 rollbackOnly=true 라는 표시를 해둔다.
응답 흐름 - 외부 트랜잭션
4. 로직1이 끝나고 트랜잭션 매니저를 통해 외부 트랜잭션을 커밋한다.
5. 트랜잭션 매니저는 커밋 시점에 신규 트랜잭션 여부에 따라 다르게 동작한다. 외부 트랜잭션은 신규 트랜잭션이다. 따라서 DB 커넥션에 실제 커밋을 호출해야 한다. 이때 먼저 트랜잭션 동기화 매니저에 롤백 전용 (rollbackOnly=true) 표시가 있는지 확인한다. 롤백 전용 표시가 있으면 물리 트랜잭션을 커밋하는 것이 아니라 롤백한다.
6. 실제 데이터베이스에 롤백이 반영되고, 물리 트랜잭션도 끝난다.
7. 트랜잭션 매니저에 커밋을 호출한 개발자 입장에서는 분명 커밋을 기대했는데 롤백 전용 표시로 인해 실제로는 롤백이 되어버렸다. 이것은 조용히 넘어갈 수 있는 문제가 아니다. 시스템 입장에서는 커밋을 호출했지만 롤백이 되었다는 것은 분명하게 알려주어야 한다. 예를 들어서 고객은 주문이 성공했다고 생각했는데, 실제로는 롤백이 되어서 주문이 생성되지 않은 것이다. 스프링은 이 경우 UnexpectedRollbackException 런타임 예외를 던진다. 그래서 커밋을 시도했지만, 기대하지 않은 롤백이 발생했다는 것을 명확하게 알려준다.
정리
-논리 트랜잭션이 하나라도 롤백되면 물리 트랜잭션은 롤백된다. -내부 논리 트랜잭션이 롤백되면 롤백 전용 마크를 표시한다. -외부 트랜잭션을 커밋할 때 롤백 전용 마크를 확인한다. 롤백 전용 마크가 표시되어 있으면 물리 트랜잭션을 롤백하고, UnexpectedRollbackException 예외를 던진다.
참고
애플리케이션 개발에서 중요한 기본 원칙은 모호함을 제거하는 것이다. 개발은 명확해야 한다. 이렇게 커밋을 호출했는데, 내부에서 롤백이 발생한 경우 모호하게 두면 아주 심각한 문제가 발생한다. 이렇게 기대한 결과가 다른 경우 예외를 발생시켜서 명확하게 문제를 알려주는 것이 좋은 설계이다.
REQUIRES_NEW(외부 트랜잭션과 내부 트랜잭션을 완전히 분리해서 사용하는 방법)
REQUIRES_NEW는 외부 트랜잭션과 내부 트랜잭션을 완전히 분리해서 각각 별도의 물리 트랜잭션을 사용하는 방법이다. 그래서 커밋과 롤백도 각각 별도로 이루어지게 된다.
이 방법은 내부 트랜잭션에 문제가 발생해서 롤백해도, 외부 트랜잭션에는 영향을 주지 않는다. 반대로 외부 트랜잭션에 문제가 발생해도 내부 트랜잭션에 영향을 주지 않는다.
이렇게 물리 트랜잭션을 분리하려면 내부 트랜잭션을 시작할 때 REQUIRES_NEW 옵션을 사용하면 된다.
외부 트랜잭션과 내부 트랜잭션이 각각 별도의 물리 트랜잭션을 가진다.
별도의 물리 트랜잭션을 가진다는 뜻은 DB 커넥션을 따로 사용한다는 뜻이다.
이 경우 내부 트랜잭션이 롤백되면서 로직 2가 롤백되어도 로직 1에서 저장한 데이터에는 영향을 주지 않는다.
DefaultTransactionAttribute 객체 생성 TransactionDefinition 인터페이스를 구현한 DefaultTransactionAttribute 클래스의 인스턴스를 생성한다. 이 인스턴스는 트랜잭션의 다양한 속성을 정의하는 데 사용된다.
전파 행위 설정 생성된 definition 객체에 setPropagationBehavior 메소드를 호출하여 트랜잭션의 전파 행위를 PROPAGATION_REQUIRES_NEW로 설정한다. 이는 현재 진행 중인 트랜잭션이 있을 경우 이를 일시 중단하고 새로운 트랜잭션을 시작하게 한다. 즉, 호출된 메소드가 자신만의 독립적인 트랜잭션을 가지게 된다.
내부 트랜잭션을 시작할 때 전파 옵션인 propagationBehavior 에 PROPAGATION_REQUIRES_NEW 옵션을 주었다.
이 전파 옵션을 사용하면 내부 트랜잭션을 시작할 때 기존 트랜잭션에 참여하는 것이 아니라 새로운 물리 트랜잭션을 만들어서 시작하게 된다.
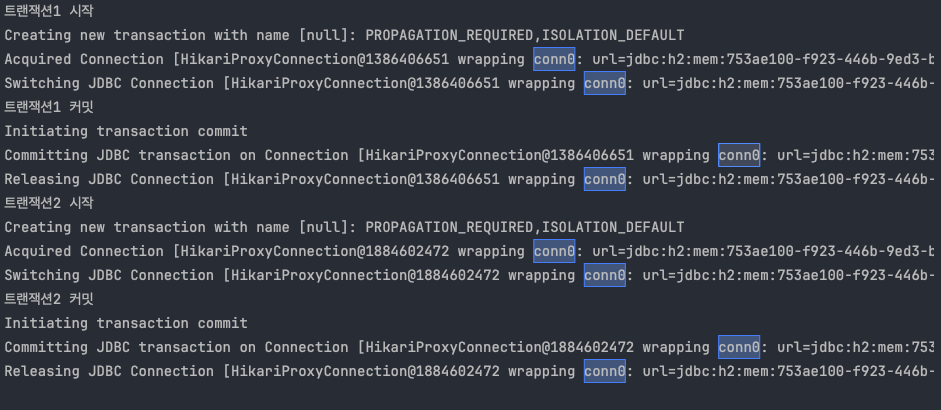
외부 트랜잭션 시작
외부 트랜잭션을 시작하면서 conn0 를 획득하고 manual commit 으로 변경해서 물리 트랜잭션을 시작한다.
외부 트랜잭션은 신규 트랜잭션이다.( outer.isNewTransaction()=true )
내부 트랜잭션 시작
내부 트랜잭션을 시작하면서 conn1 를 획득하고 manual commit 으로 변경해서 물리 트랜잭션을 시작한다.
내부 트랜잭션은 외부 트랜잭션에 참여하는 것이 아니라, PROPAGATION_REQUIRES_NEW 옵션을 사용했기 때문에 완전히 새로운 신규 트랜잭션으로 생성된다.( inner.isNewTransaction()=true )
내부 트랜잭션 롤백
내부 트랜잭션을 롤백한다.
내부 트랜잭션은 신규 트랜잭션이기 때문에 실제 물리 트랜잭션을 롤백한다. 내부 트랜잭션은 conn1 을 사용하므로 conn1 에 물리 롤백을 수행한다.
외부 트랜잭션 커밋
외부 트랜잭션을 커밋한다.
외부 트랜잭션은 신규 트랜잭션이기 때문에 실제 물리 트랜잭션을 커밋한다. 외부 트랜잭션은 conn0 를 사용하므로 conn0 에 물리 커밋을 수행한다.
코드 분석
외부 트랜잭션 시작: PlatformTransactionManager를 사용해 외부 트랜잭션을 시작한다. outer.isNewTransaction()은 true를 반환한다, 이는 외부 트랜잭션이 새로 시작됐음을 의미한다.
내부 트랜잭션 시작: PROPAGATION_REQUIRES_NEW 속성을 설정한 DefaultTransactionAttribute 인스턴스를 생성하고, 이를 사용해 내부 트랜잭션을 시작한다. 이 속성 덕분에, 내부 트랜잭션은 새로운 트랜잭션으로 시작되며, inner.isNewTransaction()은 true를 반환한다.
내부 트랜잭션 롤백: 내부 트랜잭션에 문제가 발생했을 때, txManager.rollback(inner)를 호출하여 내부 트랜잭션만 롤백한다. 이는 내부 트랜잭션에 의한 변경 사항이 데이터베이스에 반영되지 않도록 한다.
외부 트랜잭션 커밋: 마지막으로, 외부 트랜잭션은 정상적으로 커밋된다. 외부 트랜잭션의 작업은 성공적으로 데이터베이스에 반영된다.
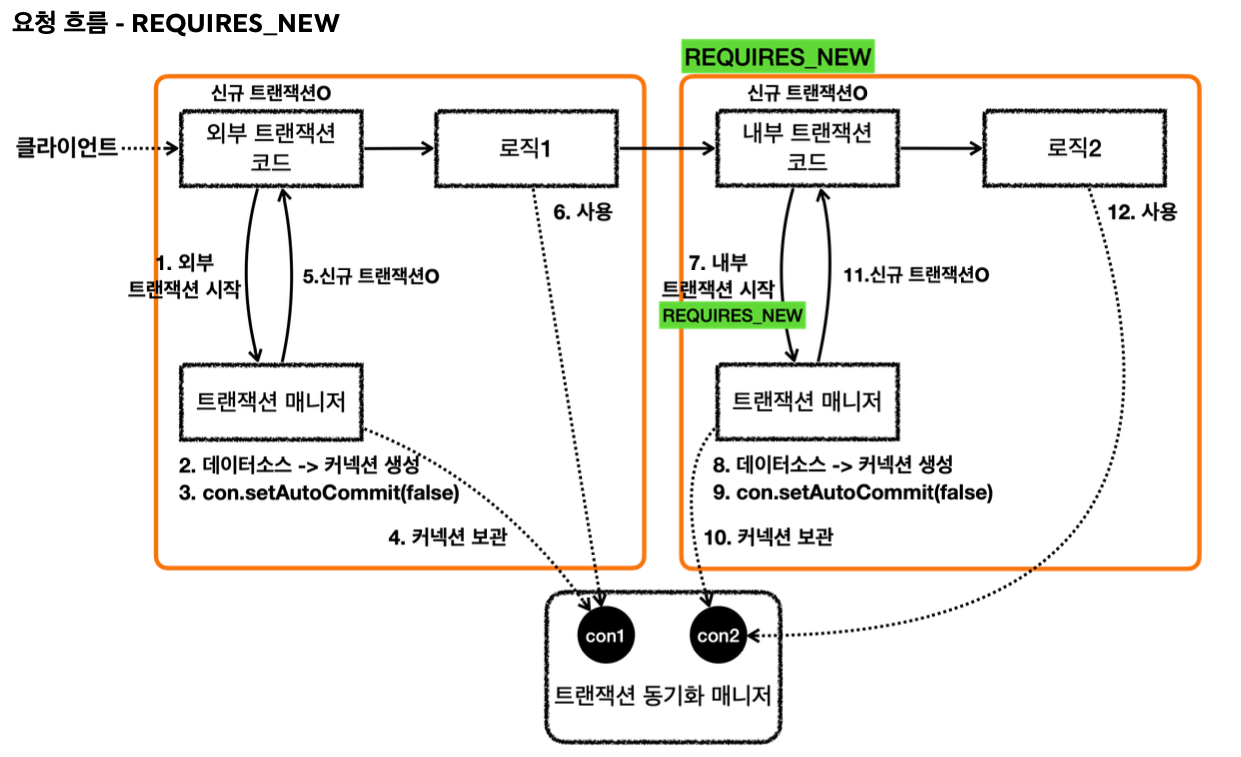
요청 흐름 - 외부 트랜잭션
1. txManager.getTransaction() 를 호출해서 외부 트랜잭션을 시작한다.
2. 트랜잭션 매니저는 데이터소스를 통해 커넥션을 생성한다.
3. 생성한 커넥션을 수동 커밋 모드(setAutoCommit(false))로 설정한다. - 물리 트랜잭션 시작
4. 트랜잭션 매니저는 트랜잭션 동기화 매니저에 커넥션을 보관한다. 트랜잭션 매니저는 트랜잭션을 생성한 결과를 TransactionStatus 에 담아서 반환하는데, 여기에 신규 트랜잭션의 여부가 담겨 있다. isNewTransaction 를 통해 신규 트랜잭션 여부를 확인할 수 있다. -> 트랜잭션을 처음 시작했으므로 신규 트랜잭션이다.(true)
6.로직1이 사용되고, 커넥션이 필요한 경우 트랜잭션 동기화 매니저를 통해 트랜잭션이 적용된 커넥션을 획득해서 사용한다.
요청 흐름 - 내부 트랜잭션
7. REQUIRES_NEW 옵션과 함께 txManager.getTransaction() 를 호출해서 내부 트랜잭션을 시작한다. 트랜잭션 매니저는 REQUIRES_NEW 옵션을 확인하고, 기존 트랜잭션에 참여하는 것이 아니라 새로운 트랜잭션을 시작한다.
8.트랜잭션 매니저는 데이터소스를 통해 커넥션을 생성한다.
9. 생성한 커넥션을 수동 커밋 모드(setAutoCommit(false))로 설정한다. - 물리 트랜잭션 시작
10. 트랜잭션 매니저는 트랜잭션 동기화 매니저에 커넥션을 보관한다. 이때 con1 은 잠시 보류되고, 지금부터는 con2 가 사용된다. (내부 트랜잭션을 완료할 때까지 con2 가 사용된다.)
11. 트랜잭션 매니저는 신규 트랜잭션의 생성한 결과를 반환한다. isNewTransaction == true
12. 로직2가 사용되고, 커넥션이 필요한 경우 트랜잭션 동기화 매니저에 있는 con2 커넥션을 획득해서 사용한다.
응답 흐름 - 내부 트랜잭션
1. 로직2가 끝나고 트랜잭션 매니저를 통해 내부 트랜잭션을 롤백한다. (로직2에 문제가 있어서 롤백한다고 가정한다.)
2. 트랜잭션 매니저는 롤백 시점에 신규 트랜잭션 여부에 따라 다르게 동작한다. 현재 내부 트랜잭션은 신규 트랜잭션이다. 따라서 실제 롤백을 호출한다.
3. 내부 트랜잭션이 con2 물리 트랜잭션을 롤백한다. 트랜잭션이 종료되고, con2는 종료되거나, 커넥션 풀에 반납된다. 이후에 con1의 보류가 끝나고, 다시 con1을 사용한다.
응답 흐름 - 외부 트랜잭션
4. 외부 트랜잭션에 커밋을 요청한다.
5. 외부 트랜잭션은 신규 트랜잭션이기 때문에 물리 트랜잭션을 커밋한다.
6. 이때 rollbackOnly 설정을 체크한다. rollbackOnly 설정이 없으므로 커밋한다.
7. 본인이 만든 con1 커넥션을 통해 물리 트랜잭션을 커밋한다. 트랜잭션이 종료되고, con1은 종료되거나, 커넥션 풀에 반납된다.
정리
REQUIRES_NEW 옵션을 사용하면 물리 트랜잭션이 명확하게 분리된다.
REQUIRES_NEW를 사용하면 데이터베이스 커넥션이 동시에 2개 사용된다는 점을 주의해야 한다.
다양한 전파 옵션
스프링은 다양한 트랜잭션 전파 옵션을 제공한다. 전파 옵션에 별도의 설정을 하지 않으면 REQUIRED 가 기본으로 사용된다.
실무에서는 대부분 REQUIRED 옵션을 사용한다.
그리고 아주 가끔 REQUIRES_NEW 을 사용하고, 나머지는 거의 사용하지 않는다.
REQUIRED
가장 많이 사용하는 기본 설정이다. 기존 트랜잭션이 없으면 생성하고, 있으면 참여한다. 트랜잭션이 필수라는 의미로 이해하면 된다. (필수이기 때문에 없으면 만들고, 있으면 참여한다.)
기존 트랜잭션 없음: 새로운 트랜잭션을 생성한다.
기존 트랜잭션 있음: 기존 트랜잭션에 참여한다.
REQUIRES_NEW
항상 새로운 트랜잭션을 생성한다.
기존 트랜잭션 없음: 새로운 트랜잭션을 생성한다.
기존 트랜잭션 있음: 새로운 트랜잭션을 생성한다.
SUPPORT
트랜잭션을 지원한다는 뜻이다. 기존 트랜잭션이 없으면, 없는대로 진행하고, 있으면 참여한다.
기존 트랜잭션 없음: 트랜잭션 없이 진행한다.
기존 트랜잭션 있음: 기존 트랜잭션에 참여한다.
NOT_SUPPORT
트랜잭션을 지원하지 않는다는 의미이다.
기존 트랜잭션 없음: 트랜잭션 없이 진행한다.
기존 트랜잭션 있음: 트랜잭션 없이 진행한다. (기존 트랜잭션은 보류한다)
MANDATORY
의무사항이다. 트랜잭션이 반드시 있어야 한다.
기존 트랜잭션이 없으면 IllegalTransactionStateException 예외 발생
기존 트랜잭션 있음: 기존 트랜잭션에 참여한다.
NEVER
트랜잭션을 사용하지 않는다는 의미이다. 기존 트랜잭션이 있으면 예외가 발생한다. 기존 트랜잭션도 허용하지 않는 강한 부정의 의미로 이해하면 된다.
기존 트랜잭션 없음: 트랜잭션 없이 진행한다.
기존 트랜잭션 있음: IllegalTransactionStateException 예외 발생
NESTED
기존 트랜잭션 없음: 새로운 트랜잭션을 생성한다.
기존 트랜잭션 있음: 중첩 트랜잭션을 만든다. 중첩 트랜잭션은 외부 트랜잭션의 영향을 받지만, 중첩 트랜잭션은 외부에 영향을 주지 않는다. 중첩 트랜잭션이 롤백되어도 외부 트랜잭션은 커밋할 수 있다. 외부 트랜잭션이 롤백되면 중첩 트랜잭션도 함께 롤백된다.
참고
JDBC savepoint 기능을 사용한다. DB 드라이버에서 해당 기능을 지원하는지 확인이 필요하다. 중첩 트랜잭션은 JPA에서는 사용할 수 없다.
트랜잭션 전파와 옵션
isolation , timeout , readOnly 는 트랜잭션이 처음 시작될 때만 적용된다. 트랜잭션에 참여하는 경우에는 적용되지 않는다. 예를 들어서 `REQUIRED` 를 통한 트랜잭션 시작, `REQUIRES_NEW` 를 통한 트랜잭션 시작 시점에만 적용된다.
@Transactional 을 통해 선언적 트랜잭션 방식을 사용하면 단순히 애노테이션 하나로 트랜잭션을 적용할 수 있다. 그런데 이 기능은 트랜잭션 관련 코드가 눈에 보이지 않고, AOP를 기반으로 동작하기 때문에, 실제 트랜잭션이 적용되 고 있는지 아닌지를 확인하기가 어렵다.
아래의 테스트 코드로 원리를 이해 할 수 있다.
@Slf4j
@SpringBootTest
public class TxBasicTest {
@Autowired
BasicService basicService;
@Test
void proxyCheck() {
//BasicService$$EnhancerBySpringCGLIB...
log.info("aop class={}", basicService.getClass());
assertThat(AopUtils.isAopProxy(basicService)).isTrue();
}
@Test
void txTest() {
basicService.tx();
basicService.nonTx();
}
@TestConfiguration
static class TxApplyBasicConfig {
@Bean
BasicService basicService() {
return new BasicService();
}
}
@Slf4j
@Transactional(readOnly = true)
static class BasicService {
//우선순위는 항상 더 구체적이고 자세한 것이 높은 우선순위를 가진다.
//클래스 레벨에서 (readOnly = true)이지만 메서드 레벨에서 (readOnly = false) 이기때문에 tx()는 읽기 작업과 쓰기 작업 모두 할 수 있다.
//(readOnly = true) : 읽기만 가능
//(readOnly = false) : 읽기. 쓰기 모두 가능
@Transactional(readOnly = false)
public void tx() {
log.info("call tx");
boolean txActive = TransactionSynchronizationManager.isActualTransactionActive(); //현재 쓰레드에 트랜잭션이 적용되어 있는지 확인할 수 있는 기능
log.info("tx active={}", txActive);
}
public void nonTx() {
log.info("call nonTx");
boolean txActive = TransactionSynchronizationManager.isActualTransactionActive(); //현재 쓰레드에 트랜잭션이 적용되어 있는지 확인할 수 있는 기능
log.info("tx active={}", txActive);
}
}
}
proxyCheck() - 실행
AopUtils.isAopProxy() : 선언적 트랜잭션 방식에서 스프링 트랜잭션은 AOP를 기반으로 동작한다.
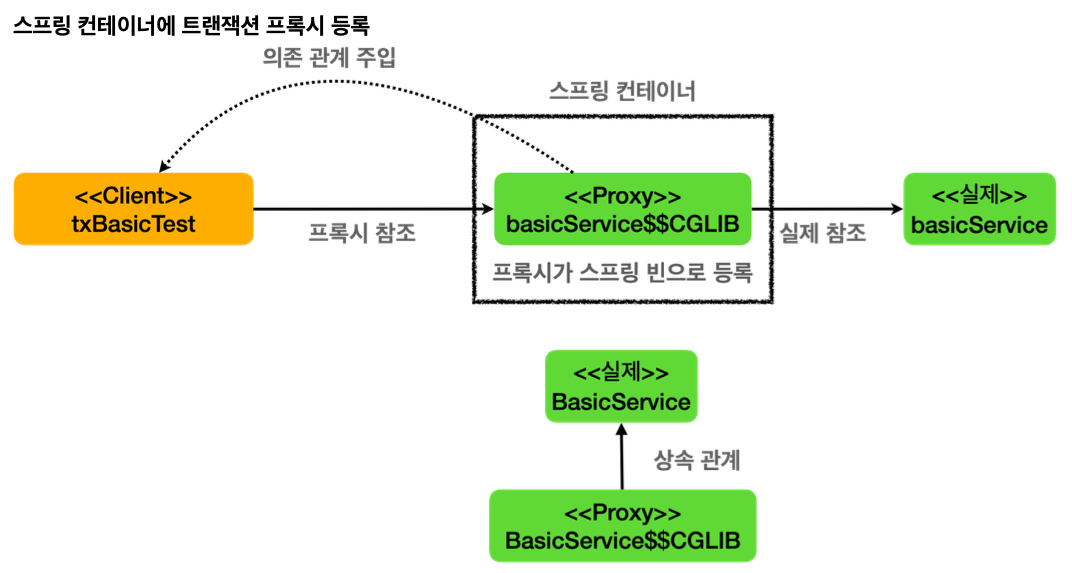
@Transactional 을 메서드나 클래스에 붙이면 해당 객체는 트랜잭션 AOP 적용의 대상이 되고, 결과적으로 실제 객체 대신에 트랜잭션을 처리해주는 프록시 객체가 스프링 빈에 등록된다. 그리고 주입을 받을 때도 실제 객 체 대신에 프록시 객체가 주입된다.
클래스 이름을 출력해보면 basicService$$EnhancerBySpringCGLIB... 라고 프록시 클래스의 이름이 출력되는 것을 확인할 수 있다.
@Transactional 애노테이션이 특정 클래스나 메서드에 하나라도 있으면 트랜잭션 AOP는 프록시를 만들어서 스프링 컨테이너에 등록한다. 그리고 실제 basicService 객체 대신에 프록시인 basicService$ $CGLIB 를 스프링 빈에 등록한다.
그리고 프록시는 내부에 실제 basicService 를 참조하게 된다. 여기서 핵 심은 실제 객체 대신에 프록시가 스프링 컨테이너에 등록되었다는 점이다.
클라이언트인 txBasicTest 는 스프링 컨테이너에 @Autowired BasicService basicService 로 의존관계 주입을 요청한다.
스프링 컨테이너에는 실제 객체 대신에 프록시가 스프링 빈으로 등록되어 있기 때문에 프록시를 주입한다.
프록시는 BasicService 를 상속해서 만들어지기 때문에 다형성을 활용할 수 있다. 따라서 BasicService 대신에 프록시인BasicService$$CGLIB 를 주입할 수 있다.
클라이언트가 주입 받은 basicService$$CGLIB 는 트랜잭션을 적용하는 프록시이다.
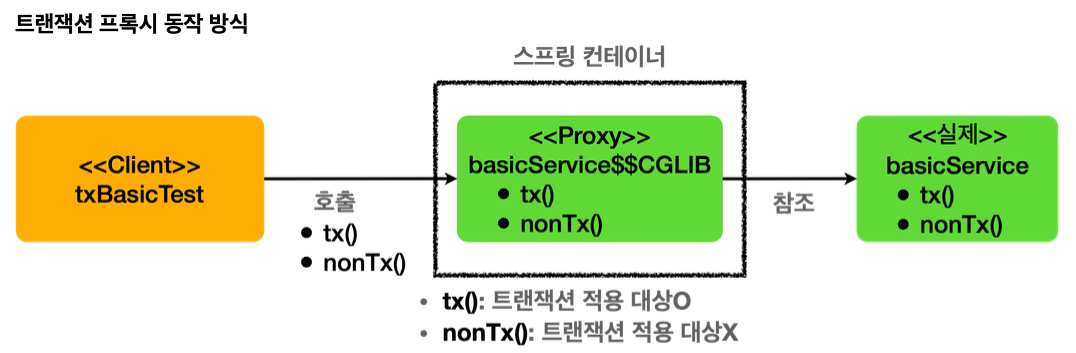
basicService.tx() 호출
클라이언트가 basicService.tx() 를 호출하면, 프록시의 tx() 가 호출된다. 여기서 프록시는 tx() 메서드가 트랜잭션을 사용할 수 있는지 확인해본다. tx() 메서드에는 @Transactional 이 붙어있으므로 트랜잭션 적용 대상이다. 따라서 트랜잭션을 시작한 다음에 실제 basicService.tx() 를 호출한다. 그리고 실제 basicService.tx() 의 호출이 끝나서 프록시로 제어가(리턴) 돌아오면 프록시는 트랜잭션 로직을 커밋하거나 롤백해서 트랜잭션을 종료한다.
basicService.nonTx() 호출
클라이언트가 basicService.nonTx() 를 호출하면, 트랜잭션 프록시의 nonTx() 가 호출된다. 여기서 nonTx() 메서드가 트랜잭션을 사용할 수 있는지 확인해본다.
nonTx() 에는 @Transactional 이 없으므 로 적용 대상이 아니다. 따라서 트랜잭션을 시작하지 않고, basicService.nonTx() 를 호출하고 종료한다.
스프링 프레임워크에서는 여러 개의 트랜잭션 매니저를 사용할 수 있다. value 속성은 사용할 트랜잭션 매니저의 빈 이름을 지정한다. 만약 애플리케이션에 여러 트랜잭션 매니저가 존재할 경우, 이 속성을 통해 특정 트랜잭션 매니저를 선택할 수 있다. 기본값은 ""이며, 이 경우 스프링은 기본 트랜잭션 매니저를 사용한다.
public class TxService {
@Transactional("memberTxManager")
public void member() {...}
@Transactional("orderTxManager")
public void order() {...}
}
어노테이션에서 속성이 하나인 경우 위 예처럼 value 는 생략하고 값을 바로 넣을 수 있다.
rollbackFor
예외 발생시 스프링 트랜잭션의 기본 정책은 다음과 같다.
언체크 예외인 RuntimeException , Error 와 그 하위 예외가 발생하면 롤백한다.
체크 예외인 Exception 과 그 하위 예외들은 커밋한다.
rollbackFor는 트랜잭션이 롤백되어야 하는 예외를 지정한다. 이 속성에 지정된 예외 타입이 메소드 실행 중에 발생하면, 스프링은 자동으로 트랜잭션을 롤백한다. 이는 RuntimeException과 그 서브 클래스에 대해 기본적으로 적용되지만, 체크 예외에 대해서는 명시적으로 지정해야 한다.
@Transactional(rollbackFor = Exception.class)
이렇게 지정하면 체크 예외인 Exception 이 발생해도 롤백하게 된다. (하위 예외들도 대상에 포함된다.)
noRollbackFor
이 속성은 트랜잭션이 롤백되지 않아야 하는 예외를 지정한다. 즉, 이 속성에 지정된 예외가 발생해도 트랜잭션이 계속 커밋되도록 한다.
propagation
트랜잭션의 전파 동작을 결정한다. 예를 들어, 이미 진행 중인 트랜잭션이 있는 상황에서 새로운 트랜잭션을 시작할지, 혹은 기존 트랜잭션에 참여할지를 결정한다. Propagation.REQUIRED는 기본값이며, 현재 진행 중인 트랜잭션이 없을 경우 새로운 트랜잭션을 시작한다.
isolation
데이터베이스 트랜잭션의 격리 수준을 설정한다. 격리 수준에 따라 다른 트랜잭션으로부터의 동시성 문제를 어떻게 처리할지 결정한다. Isolation.DEFAULT는 데이터베이스의 기본 격리 수준을 사용한다.
대부분 데이터베이스에서 설정한 기준을 따른다. 애플리케이션 개발자가 트랜잭션 격리 수준을 직접 지정하는 경우는 드물다.
DEFAULT : 데이터베이스에서 설정한 격리 수준을 따른다.
READ_UNCOMMITTED` : 커밋되지 않은 읽기
READ_COMMITTED : 커밋된 읽기
REPEATABLE_READ : 반복 가능한 읽기
SERIALIZABLE : 직렬화 가능
timeout
트랜잭션이 완료되기를 기다리는 최대 시간을 초 단위로 지정한다. 이 시간을 초과하면 트랜잭션은 타임아웃되고 롤백된다. TransactionDefinition.TIMEOUT_DEFAULT는 데이터베이스 또는 트랜잭션 매니저의 기본 설정을 사용한다.
readOnly
이 속성이 true로 설정되면, 해당 트랜잭션은 읽기 전용으로 간주된다. 이는 트랜잭션이 데이터를 변경하지 않고 오직 읽기만 수행함을 나타낸다. 읽기 전용 트랜잭션은 성능 최적화에 도움을 줄 수 있다.
트랜잭션은 기본적으로 읽기 쓰기가 모두 가능한 트랜잭션이 생성된다. readOnly=true 옵션을 사용하면 읽기 전용 트랜잭션이 생성된다. 이 경우 등록, 수정, 삭제가 안되고 읽기 기능만 작동한다. (드라이버나 데이터베이스에 따라 정상 동작하지 않는 경우도 있다.) 그리고 readOnly 옵션을 사용하면 읽기에서 다양한 성능 최적화가 발생할 수 있다.
label
트랜잭션에 대한 라벨을 제공하여, 모니터링이나 로깅 시 트랜잭션을 식별하는 데 도움을 준다. 이는 트랜잭션을 보다 쉽게 추적하고 관리하는 데 유용하다. (일반적으로 잘 사용 안함)
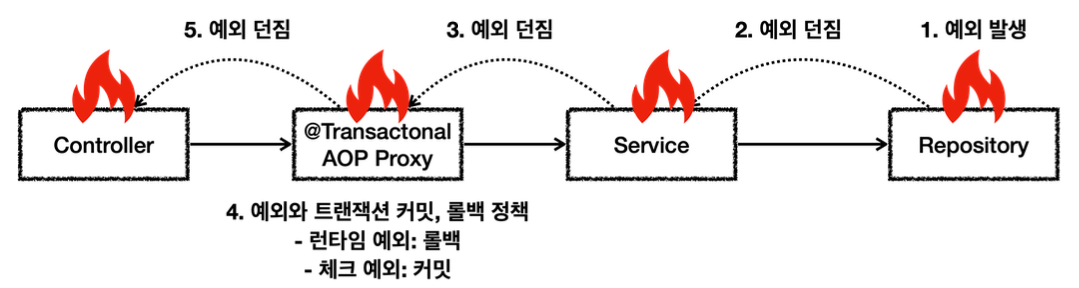
예외와 트랜잭션 커밋, 롤백
예외가 발생했는데,내부에서 예외를 처리하지 못하고, 트랜잭션 범위(@Transactional가 적용된 AOP)밖으로 예외를 던지면 어떻게 될까?
예외 발생시 스프링 트랜잭션 AOP는 예외의 종류에 따라 트랜잭션을 커밋하거나 롤백한다.
언체크 예외인 RuntimeException , Error 와 그 하위 예외가 발생하면 트랜잭션을 롤백한다.
체크 예외인 Exception 과 그 하위 예외가 발생하면 트랜잭션을 커밋한다.
물론 정상 응답(리턴)하면 트랜잭션을 커밋한다.
@SpringBootTest
public class RollbackTest {
@Autowired
RollbackService service;
@Test
void runtimeException() {
assertThatThrownBy(() -> service.runtimeException())
.isInstanceOf(RuntimeException.class);
}
@Test
void checkedException() {
assertThatThrownBy(() -> service.checkedException())
.isInstanceOf(MyException.class);
}
@Test
void rollbackFor() {
assertThatThrownBy(() -> service.rollbackFor())
.isInstanceOf(MyException.class);
}
@TestConfiguration
static class RollbackTestConfig {
@Bean
RollbackService rollbackService() {
return new RollbackService();
}
}
@Slf4j
static class RollbackService {
//런타임 예외 발생: 롤백 @Transactional
public void runtimeException() {
log.info("call runtimeException");
throw new RuntimeException();
}
//체크 예외 발생: 커밋
@Transactional
public void checkedException() throws MyException {
log.info("call checkedException");
throw new MyException();
}
//체크 예외 rollbackFor 지정: 롤백
@Transactional(rollbackFor = MyException.class)
public void rollbackFor() throws MyException {
log.info("call rollbackFor");
throw new MyException();
}
}
static class MyException extends Exception {
}
}
runtimeException: 이 메소드는 RuntimeException을 발생시키며, @Transactional 어노테이션이 없으므로 스프링의 기본 설정에 따라 이러한 종류의 예외 발생 시 트랜잭션이 롤백된다.
checkedException: 이 메소드는 @Transactional 어노테이션을 사용하여 선언적 트랜잭션 관리를 활성화하지만, 스프링의 기본 설정은 체크 예외가 발생할 때 트랜잭션을 롤백하지 않는다. 따라서 MyException 체크 예외가 발생하더라도 트랜잭션은 커밋된다.
rollbackFor: 이 메소드는 @Transactional(rollbackFor = MyException.class) 어노테이션을 사용하여, MyException 예외가 발생할 경우 명시적으로 트랜잭션을 롤백하도록 지정한다. 따라서 MyException이 발생하면 롤백이 수행된다.
CREATE USER HR IDENTIFIED BY tiger
GRANT RESOURCE, CONNECT TO HR;
grant create session, create table, create procedure to HR;
ALTER USER HR quota unlimited on USERS;
/*Data for the table regions*/
INSERT INTO regions(region_id,region_name) VALUES (1,'Europe');
INSERT INTO regions(region_id,region_name) VALUES (2,'Americas');
INSERT INTO regions(region_id,region_name) VALUES (3,'Asia');
INSERT INTO regions(region_id,region_name) VALUES (4,'Middle East and Africa');
/*Data for the table countries */
INSERT INTO countries(country_id,country_name,region_id) VALUES ('AR','Argentina',2);
INSERT INTO countries(country_id,country_name,region_id) VALUES ('AU','Australia',3);
INSERT INTO countries(country_id,country_name,region_id) VALUES ('BE','Belgium',1);
INSERT INTO countries(country_id,country_name,region_id) VALUES ('BR','Brazil',2);
INSERT INTO countries(country_id,country_name,region_id) VALUES ('CA','Canada',2);
INSERT INTO countries(country_id,country_name,region_id) VALUES ('CH','Switzerland',1);
INSERT INTO countries(country_id,country_name,region_id) VALUES ('CN','China',3);
INSERT INTO countries(country_id,country_name,region_id) VALUES ('DE','Germany',1);
INSERT INTO countries(country_id,country_name,region_id) VALUES ('DK','Denmark',1);
INSERT INTO countries(country_id,country_name,region_id) VALUES ('EG','Egypt',4);
INSERT INTO countries(country_id,country_name,region_id) VALUES ('FR','France',1);
INSERT INTO countries(country_id,country_name,region_id) VALUES ('HK','HongKong',3);
INSERT INTO countries(country_id,country_name,region_id) VALUES ('IL','Israel',4);
INSERT INTO countries(country_id,country_name,region_id) VALUES ('IN','India',3);
INSERT INTO countries(country_id,country_name,region_id) VALUES ('IT','Italy',1);
INSERT INTO countries(country_id,country_name,region_id) VALUES ('JP','Japan',3);
INSERT INTO countries(country_id,country_name,region_id) VALUES ('KW','Kuwait',4);
INSERT INTO countries(country_id,country_name,region_id) VALUES ('MX','Mexico',2);
INSERT INTO countries(country_id,country_name,region_id) VALUES ('NG','Nigeria',4);
INSERT INTO countries(country_id,country_name,region_id) VALUES ('NL','Netherlands',1);
INSERT INTO countries(country_id,country_name,region_id) VALUES ('SG','Singapore',3);
INSERT INTO countries(country_id,country_name,region_id) VALUES ('UK','United Kingdom',1);
INSERT INTO countries(country_id,country_name,region_id) VALUES ('US','United States of America',2);
INSERT INTO countries(country_id,country_name,region_id) VALUES ('ZM','Zambia',4);
INSERT INTO countries(country_id,country_name,region_id) VALUES ('ZW','Zimbabwe',4);
/*Data for the table locations */
INSERT INTO locations(location_id,street_address,postal_code,city,state_province,country_id) VALUES (1400,'2014 Jabberwocky Rd','26192','Southlake','Texas','US');
INSERT INTO locations(location_id,street_address,postal_code,city,state_province,country_id) VALUES (1500,'2011 Interiors Blvd','99236','South San Francisco','California','US');
INSERT INTO locations(location_id,street_address,postal_code,city,state_province,country_id) VALUES (1700,'2004 Charade Rd','98199','Seattle','Washington','US');
INSERT INTO locations(location_id,street_address,postal_code,city,state_province,country_id) VALUES (1800,'147 Spadina Ave','M5V 2L7','Toronto','Ontario','CA');
INSERT INTO locations(location_id,street_address,postal_code,city,state_province,country_id) VALUES (2400,'8204 Arthur St',NULL,'London',NULL,'UK');
INSERT INTO locations(location_id,street_address,postal_code,city,state_province,country_id) VALUES (2500,'Magdalen Centre, The Oxford Science Park','OX9 9ZB','Oxford','Oxford','UK');
INSERT INTO locations(location_id,street_address,postal_code,city,state_province,country_id) VALUES (2700,'Schwanthalerstr. 7031','80925','Munich','Bavaria','DE');
/*Data for the table jobs */
INSERT INTO jobs(job_id,job_title,min_salary,max_salary) VALUES (1,'Public Accountant',4200.00,9000.00);
INSERT INTO jobs(job_id,job_title,min_salary,max_salary) VALUES (2,'Accounting Manager',8200.00,16000.00);
INSERT INTO jobs(job_id,job_title,min_salary,max_salary) VALUES (3,'Administration Assistant',3000.00,6000.00);
INSERT INTO jobs(job_id,job_title,min_salary,max_salary) VALUES (4,'President',20000.00,40000.00);
INSERT INTO jobs(job_id,job_title,min_salary,max_salary) VALUES (5,'Administration Vice President',15000.00,30000.00);
INSERT INTO jobs(job_id,job_title,min_salary,max_salary) VALUES (6,'Accountant',4200.00,9000.00);
INSERT INTO jobs(job_id,job_title,min_salary,max_salary) VALUES (7,'Finance Manager',8200.00,16000.00);
INSERT INTO jobs(job_id,job_title,min_salary,max_salary) VALUES (8,'Human Resources Representative',4000.00,9000.00);
INSERT INTO jobs(job_id,job_title,min_salary,max_salary) VALUES (9,'Programmer',4000.00,10000.00);
INSERT INTO jobs(job_id,job_title,min_salary,max_salary) VALUES (10,'Marketing Manager',9000.00,15000.00);
INSERT INTO jobs(job_id,job_title,min_salary,max_salary) VALUES (11,'Marketing Representative',4000.00,9000.00);
INSERT INTO jobs(job_id,job_title,min_salary,max_salary) VALUES (12,'Public Relations Representative',4500.00,10500.00);
INSERT INTO jobs(job_id,job_title,min_salary,max_salary) VALUES (13,'Purchasing Clerk',2500.00,5500.00);
INSERT INTO jobs(job_id,job_title,min_salary,max_salary) VALUES (14,'Purchasing Manager',8000.00,15000.00);
INSERT INTO jobs(job_id,job_title,min_salary,max_salary) VALUES (15,'Sales Manager',10000.00,20000.00);
INSERT INTO jobs(job_id,job_title,min_salary,max_salary) VALUES (16,'Sales Representative',6000.00,12000.00);
INSERT INTO jobs(job_id,job_title,min_salary,max_salary) VALUES (17,'Shipping Clerk',2500.00,5500.00);
INSERT INTO jobs(job_id,job_title,min_salary,max_salary) VALUES (18,'Stock Clerk',2000.00,5000.00);
INSERT INTO jobs(job_id,job_title,min_salary,max_salary) VALUES (19,'Stock Manager',5500.00,8500.00);
/*Data for the table departments */
INSERT INTO departments(department_id,department_name,location_id) VALUES (1,'Administration',1700);
INSERT INTO departments(department_id,department_name,location_id) VALUES (2,'Marketing',1800);
INSERT INTO departments(department_id,department_name,location_id) VALUES (3,'Purchasing',1700);
INSERT INTO departments(department_id,department_name,location_id) VALUES (4,'Human Resources',2400);
INSERT INTO departments(department_id,department_name,location_id) VALUES (5,'Shipping',1500);
INSERT INTO departments(department_id,department_name,location_id) VALUES (6,'IT',1400);
INSERT INTO departments(department_id,department_name,location_id) VALUES (7,'Public Relations',2700);
INSERT INTO departments(department_id,department_name,location_id) VALUES (8,'Sales',2500);
INSERT INTO departments(department_id,department_name,location_id) VALUES (9,'Executive',1700);
INSERT INTO departments(department_id,department_name,location_id) VALUES (10,'Finance',1700);
INSERT INTO departments(department_id,department_name,location_id) VALUES (11,'Accounting',1700);
/*Data for the table employees */
INSERT INTO employees(employee_id,first_name,last_name,email,phone_number,hire_date,job_id,salary,manager_id,department_id) VALUES (100,'Steven','King','steven.king@sqltutorial.org','515.123.4567',DATE '1987-06-17',4,24000.00,NULL,9);
INSERT INTO employees(employee_id,first_name,last_name,email,phone_number,hire_date,job_id,salary,manager_id,department_id) VALUES (101,'Neena','Kochhar','neena.kochhar@sqltutorial.org','515.123.4568',DATE '1989-09-21',5,17000.00,100,9);
INSERT INTO employees(employee_id,first_name,last_name,email,phone_number,hire_date,job_id,salary,manager_id,department_id) VALUES (102,'Lex','De Haan','lex.de haan@sqltutorial.org','515.123.4569',DATE '1993-01-13',5,17000.00,100,9);
INSERT INTO employees(employee_id,first_name,last_name,email,phone_number,hire_date,job_id,salary,manager_id,department_id) VALUES (103,'Alexander','Hunold','alexander.hunold@sqltutorial.org','590.423.4567',DATE '1990-01-03',9,9000.00,102,6);
INSERT INTO employees(employee_id,first_name,last_name,email,phone_number,hire_date,job_id,salary,manager_id,department_id) VALUES (104,'Bruce','Ernst','bruce.ernst@sqltutorial.org','590.423.4568',DATE '1991-05-21',9,6000.00,103,6);
INSERT INTO employees(employee_id,first_name,last_name,email,phone_number,hire_date,job_id,salary,manager_id,department_id) VALUES (105,'David','Austin','david.austin@sqltutorial.org','590.423.4569',DATE '1997-06-25',9,4800.00,103,6);
INSERT INTO employees(employee_id,first_name,last_name,email,phone_number,hire_date,job_id,salary,manager_id,department_id) VALUES (106,'Valli','Pataballa','valli.pataballa@sqltutorial.org','590.423.4560',DATE '1998-02-05',9,4800.00,103,6);
INSERT INTO employees(employee_id,first_name,last_name,email,phone_number,hire_date,job_id,salary,manager_id,department_id) VALUES (107,'Diana','Lorentz','diana.lorentz@sqltutorial.org','590.423.5567',DATE '1999-02-07',9,4200.00,103,6);
INSERT INTO employees(employee_id,first_name,last_name,email,phone_number,hire_date,job_id,salary,manager_id,department_id) VALUES (108,'Nancy','Greenberg','nancy.greenberg@sqltutorial.org','515.124.4569',DATE '1994-08-17',7,12000.00,101,10);
INSERT INTO employees(employee_id,first_name,last_name,email,phone_number,hire_date,job_id,salary,manager_id,department_id) VALUES (109,'Daniel','Faviet','daniel.faviet@sqltutorial.org','515.124.4169',DATE '1994-08-16',6,9000.00,108,10);
INSERT INTO employees(employee_id,first_name,last_name,email,phone_number,hire_date,job_id,salary,manager_id,department_id) VALUES (110,'John','Chen','john.chen@sqltutorial.org','515.124.4269',DATE '1997-09-28',6,8200.00,108,10);
INSERT INTO employees(employee_id,first_name,last_name,email,phone_number,hire_date,job_id,salary,manager_id,department_id) VALUES (111,'Ismael','Sciarra','ismael.sciarra@sqltutorial.org','515.124.4369',DATE '1997-09-30',6,7700.00,108,10);
INSERT INTO employees(employee_id,first_name,last_name,email,phone_number,hire_date,job_id,salary,manager_id,department_id) VALUES (112,'Jose Manuel','Urman','jose manuel.urman@sqltutorial.org','515.124.4469',DATE '1998-03-07',6,7800.00,108,10);
INSERT INTO employees(employee_id,first_name,last_name,email,phone_number,hire_date,job_id,salary,manager_id,department_id) VALUES (113,'Luis','Popp','luis.popp@sqltutorial.org','515.124.4567',DATE '1999-12-07',6,6900.00,108,10);
INSERT INTO employees(employee_id,first_name,last_name,email,phone_number,hire_date,job_id,salary,manager_id,department_id) VALUES (114,'Den','Raphaely','den.raphaely@sqltutorial.org','515.127.4561',DATE '1994-12-07',14,11000.00,100,3);
INSERT INTO employees(employee_id,first_name,last_name,email,phone_number,hire_date,job_id,salary,manager_id,department_id) VALUES (115,'Alexander','Khoo','alexander.khoo@sqltutorial.org','515.127.4562',DATE '1995-05-18',13,3100.00,114,3);
INSERT INTO employees(employee_id,first_name,last_name,email,phone_number,hire_date,job_id,salary,manager_id,department_id) VALUES (116,'Shelli','Baida','shelli.baida@sqltutorial.org','515.127.4563',DATE '1997-12-24',13,2900.00,114,3);
INSERT INTO employees(employee_id,first_name,last_name,email,phone_number,hire_date,job_id,salary,manager_id,department_id) VALUES (117,'Sigal','Tobias','sigal.tobias@sqltutorial.org','515.127.4564',DATE '1997-07-24',13,2800.00,114,3);
INSERT INTO employees(employee_id,first_name,last_name,email,phone_number,hire_date,job_id,salary,manager_id,department_id) VALUES (118,'Guy','Himuro','guy.himuro@sqltutorial.org','515.127.4565',DATE '1998-11-15',13,2600.00,114,3);
INSERT INTO employees(employee_id,first_name,last_name,email,phone_number,hire_date,job_id,salary,manager_id,department_id) VALUES (119,'Karen','Colmenares','karen.colmenares@sqltutorial.org','515.127.4566',DATE '1999-08-10',13,2500.00,114,3);
INSERT INTO employees(employee_id,first_name,last_name,email,phone_number,hire_date,job_id,salary,manager_id,department_id) VALUES (120,'Matthew','Weiss','matthew.weiss@sqltutorial.org','650.123.1234',DATE '1996-07-18',19,8000.00,100,5);
INSERT INTO employees(employee_id,first_name,last_name,email,phone_number,hire_date,job_id,salary,manager_id,department_id) VALUES (121,'Adam','Fripp','adam.fripp@sqltutorial.org','650.123.2234',DATE '1997-04-10',19,8200.00,100,5);
INSERT INTO employees(employee_id,first_name,last_name,email,phone_number,hire_date,job_id,salary,manager_id,department_id) VALUES (122,'Payam','Kaufling','payam.kaufling@sqltutorial.org','650.123.3234',DATE '1995-05-01',19,7900.00,100,5);
INSERT INTO employees(employee_id,first_name,last_name,email,phone_number,hire_date,job_id,salary,manager_id,department_id) VALUES (123,'Shanta','Vollman','shanta.vollman@sqltutorial.org','650.123.4234',DATE '1997-10-10',19,6500.00,100,5);
INSERT INTO employees(employee_id,first_name,last_name,email,phone_number,hire_date,job_id,salary,manager_id,department_id) VALUES (126,'Irene','Mikkilineni','irene.mikkilineni@sqltutorial.org','650.124.1224',DATE '1998-09-28',18,2700.00,120,5);
INSERT INTO employees(employee_id,first_name,last_name,email,phone_number,hire_date,job_id,salary,manager_id,department_id) VALUES (145,'John','Russell','john.russell@sqltutorial.org',NULL,DATE '1996-10-01',15,14000.00,100,8);
INSERT INTO employees(employee_id,first_name,last_name,email,phone_number,hire_date,job_id,salary,manager_id,department_id) VALUES (146,'Karen','Partners','karen.partners@sqltutorial.org',NULL,DATE '1997-01-05',15,13500.00,100,8);
INSERT INTO employees(employee_id,first_name,last_name,email,phone_number,hire_date,job_id,salary,manager_id,department_id) VALUES (176,'Jonathon','Taylor','jonathon.taylor@sqltutorial.org',NULL,DATE '1998-03-24',16,8600.00,100,8);
INSERT INTO employees(employee_id,first_name,last_name,email,phone_number,hire_date,job_id,salary,manager_id,department_id) VALUES (177,'Jack','Livingston','jack.livingston@sqltutorial.org',NULL,DATE '1998-04-23',16,8400.00,100,8);
INSERT INTO employees(employee_id,first_name,last_name,email,phone_number,hire_date,job_id,salary,manager_id,department_id) VALUES (178,'Kimberely','Grant','kimberely.grant@sqltutorial.org',NULL,DATE '1999-05-24',16,7000.00,100,8);
INSERT INTO employees(employee_id,first_name,last_name,email,phone_number,hire_date,job_id,salary,manager_id,department_id) VALUES (179,'Charles','Johnson','charles.johnson@sqltutorial.org',NULL,DATE '2000-01-04',16,6200.00,100,8);
INSERT INTO employees(employee_id,first_name,last_name,email,phone_number,hire_date,job_id,salary,manager_id,department_id) VALUES (192,'Sarah','Bell','sarah.bell@sqltutorial.org','650.501.1876',DATE '1996-02-04',17,4000.00,123,5);
INSERT INTO employees(employee_id,first_name,last_name,email,phone_number,hire_date,job_id,salary,manager_id,department_id) VALUES (193,'Britney','Everett','britney.everett@sqltutorial.org','650.501.2876',DATE '1997-03-03',17,3900.00,123,5);
INSERT INTO employees(employee_id,first_name,last_name,email,phone_number,hire_date,job_id,salary,manager_id,department_id) VALUES (200,'Jennifer','Whalen','jennifer.whalen@sqltutorial.org','515.123.4444',DATE '1987-09-17',3,4400.00,101,1);
INSERT INTO employees(employee_id,first_name,last_name,email,phone_number,hire_date,job_id,salary,manager_id,department_id) VALUES (201,'Michael','Hartstein','michael.hartstein@sqltutorial.org','515.123.5555',DATE '1996-02-17',10,13000.00,100,2);
INSERT INTO employees(employee_id,first_name,last_name,email,phone_number,hire_date,job_id,salary,manager_id,department_id) VALUES (202,'Pat','Fay','pat.fay@sqltutorial.org','603.123.6666',DATE '1997-08-17',11,6000.00,201,2);
INSERT INTO employees(employee_id,first_name,last_name,email,phone_number,hire_date,job_id,salary,manager_id,department_id) VALUES (203,'Susan','Mavris','susan.mavris@sqltutorial.org','515.123.7777',DATE '1994-06-07',8,6500.00,101,4);
INSERT INTO employees(employee_id,first_name,last_name,email,phone_number,hire_date,job_id,salary,manager_id,department_id) VALUES (204,'Hermann','Baer','hermann.baer@sqltutorial.org','515.123.8888',DATE '1994-06-07',12,10000.00,101,7);
INSERT INTO employees(employee_id,first_name,last_name,email,phone_number,hire_date,job_id,salary,manager_id,department_id) VALUES (205,'Shelley','Higgins','shelley.higgins@sqltutorial.org','515.123.8080',DATE '1994-06-07',2,12000.00,101,11);
INSERT INTO employees(employee_id,first_name,last_name,email,phone_number,hire_date,job_id,salary,manager_id,department_id) VALUES (206,'William','Gietz','william.gietz@sqltutorial.org','515.123.8181',DATE '1994-06-07',1,8300.00,205,11);
/*Data for the table dependents */
INSERT INTO dependents(dependent_id,first_name,last_name,relationship,employee_id) VALUES (1,'Penelope','Gietz','Child',206);
INSERT INTO dependents(dependent_id,first_name,last_name,relationship,employee_id) VALUES (2,'Nick','Higgins','Child',205);
INSERT INTO dependents(dependent_id,first_name,last_name,relationship,employee_id) VALUES (3,'Ed','Whalen','Child',200);
INSERT INTO dependents(dependent_id,first_name,last_name,relationship,employee_id) VALUES (4,'Jennifer','King','Child',100);
INSERT INTO dependents(dependent_id,first_name,last_name,relationship,employee_id) VALUES (5,'Johnny','Kochhar','Child',101);
INSERT INTO dependents(dependent_id,first_name,last_name,relationship,employee_id) VALUES (6,'Bette','De Haan','Child',102);
INSERT INTO dependents(dependent_id,first_name,last_name,relationship,employee_id) VALUES (7,'Grace','Faviet','Child',109);
INSERT INTO dependents(dependent_id,first_name,last_name,relationship,employee_id) VALUES (8,'Matthew','Chen','Child',110);
INSERT INTO dependents(dependent_id,first_name,last_name,relationship,employee_id) VALUES (9,'Joe','Sciarra','Child',111);
INSERT INTO dependents(dependent_id,first_name,last_name,relationship,employee_id) VALUES (10,'Christian','Urman','Child',112);
INSERT INTO dependents(dependent_id,first_name,last_name,relationship,employee_id) VALUES (11,'Zero','Popp','Child',113);
INSERT INTO dependents(dependent_id,first_name,last_name,relationship,employee_id) VALUES (12,'Karl','Greenberg','Child',108);
INSERT INTO dependents(dependent_id,first_name,last_name,relationship,employee_id) VALUES (13,'Uma','Mavris','Child',203);
INSERT INTO dependents(dependent_id,first_name,last_name,relationship,employee_id) VALUES (14,'Vivien','Hunold','Child',103);
INSERT INTO dependents(dependent_id,first_name,last_name,relationship,employee_id) VALUES (15,'Cuba','Ernst','Child',104);
INSERT INTO dependents(dependent_id,first_name,last_name,relationship,employee_id) VALUES (16,'Fred','Austin','Child',105);
INSERT INTO dependents(dependent_id,first_name,last_name,relationship,employee_id) VALUES (17,'Helen','Pataballa','Child',106);
INSERT INTO dependents(dependent_id,first_name,last_name,relationship,employee_id) VALUES (18,'Dan','Lorentz','Child',107);
INSERT INTO dependents(dependent_id,first_name,last_name,relationship,employee_id) VALUES (19,'Bob','Hartstein','Child',201);
INSERT INTO dependents(dependent_id,first_name,last_name,relationship,employee_id) VALUES (20,'Lucille','Fay','Child',202);
INSERT INTO dependents(dependent_id,first_name,last_name,relationship,employee_id) VALUES (21,'Kirsten','Baer','Child',204);
INSERT INTO dependents(dependent_id,first_name,last_name,relationship,employee_id) VALUES (22,'Elvis','Khoo','Child',115);
INSERT INTO dependents(dependent_id,first_name,last_name,relationship,employee_id) VALUES (23,'Sandra','Baida','Child',116);
INSERT INTO dependents(dependent_id,first_name,last_name,relationship,employee_id) VALUES (24,'Cameron','Tobias','Child',117);
INSERT INTO dependents(dependent_id,first_name,last_name,relationship,employee_id) VALUES (25,'Kevin','Himuro','Child',118);
INSERT INTO dependents(dependent_id,first_name,last_name,relationship,employee_id) VALUES (26,'Rip','Colmenares','Child',119);
INSERT INTO dependents(dependent_id,first_name,last_name,relationship,employee_id) VALUES (27,'Julia','Raphaely','Child',114);
INSERT INTO dependents(dependent_id,first_name,last_name,relationship,employee_id) VALUES (28,'Woody','Russell','Child',145);
INSERT INTO dependents(dependent_id,first_name,last_name,relationship,employee_id) VALUES (29,'Alec','Partners','Child',146);
INSERT INTO dependents(dependent_id,first_name,last_name,relationship,employee_id) VALUES (30,'Sandra','Taylor','Child',176);
쿼리를 정상적으로 모두 입력했다면 아래의 명령어로 제대로 테이블이 생성되고 입력되었는지 테스트 해볼 수 있다.
SELECT e.FIRST_NAME , e.LAST_NAME, d.DEPARTMENT_NAME, m.LAST_NAME
FROM EMPLOYEES e
JOIN DEPARTMENTS d ON e.DEPARTMENT_ID =d.DEPARTMENT_ID
LEFT OUTER JOIN EMPLOYEES m ON e.MANAGER_ID = m.EMPLOYEE_ID ;
이 글은 인프런 김영한님의 Spring 강의를 바탕으로 개인적인 정리를 위해 작성한 글입니다.
MyBatis 소개와 장점 및 단점
MyBatis는 자바(JAVA) 언어로 작성된 오픈 소스 SQL 매핑 프레임워크이다. JDBC(Java Database Connectivity) 위에 구축되어 데이터베이스와의 상호작용을 추상화하며, 개발자가 SQL 문을 직접 제어할 수 있게 해주는 특징을 가진다. 이는 개발자가 객체와 SQL 문 사이의 매핑을 설정하여, 데이터베이스 작업을 더 쉽고 직관적으로 할 수 있게 돕는다.
MyBatis의 주요 기능
SQL 분리: MyBatis는 SQL을 자바 코드에서 분리하여 XML 파일이나 어노테이션에 작성하도록 한다. 이로써, SQL 관리가 용이하고 가독성이 높아진다.
동적 SQL: 조건에 따라 SQL 쿼리를 동적으로 생성할 수 있는 기능을 제공한다. 이는 검색 조건이 다양하고 복잡한 어플리케이션에서 유용하다.
결과 매핑: SQL 쿼리 결과를 자바 객체에 자동으로 매핑한다. 컬럼 이름과 객체 필드 이름이 다른 경우에도 매핑 설정을 통해 쉽게 처리할 수 있다.
MyBatis의 장점
직접적인 SQL 제어: MyBatis는 개발자가 SQL을 직접 작성하게 함으로써, 세밀한 쿼리 최적화와 복잡한 쿼리 작성이 가능하다.
학습 곡선: MyBatis의 학습 곡선은 Hibernate나 JPA 같은 다른 ORM 프레임워크에 비해 상대적으로 낮다. SQL을 이미 알고 있다면 쉽게 배울 수 있다.
유연성: 동적 SQL 지원을 통해 다양한 상황에 맞춤형 쿼리를 쉽게 작성할 수 있다는 점에서 유연성이 뛰어나다.
통합성: Spring Framework와 같은 다른 자바 프레임워크와의 통합이 용이하다.
MyBatis의 단점
SQL 중심적: 모든 SQL 쿼리를 개발자가 직접 관리해야 하므로, SQL에 익숙하지 않은 개발자에게는 단점이 될 수 있다.
복잡한 관계 매핑: 복잡한 객체 관계를 매핑하는 것이 JPA나 Hibernate에 비해 더 어렵고 수작업이 많이 필요하다.
세션 관리: MyBatis에서는 SQL 세션을 직접 관리해야 할 필요가 있는데, 이는 때때로 복잡할 수 있다. MyBatis는 SQL을 직접 다루고 싶어하는 개발자에게 매우 유용한 도구이다. 동시에, 프로젝트의 요구 사항이나 팀의 기술 스택에 따라 ORM 프레임워크를 선택해야 한다. 복잡한 도메인 모델이나 객체 관계 매핑이 중요한 프로젝트의 경우, JPA나 Hibernate와 같은 다른 ORM 솔루션이 더 적합할 수 있다.
MyBatis는 JdbcTemplate 보다 더 많은 기능을 제공하는 SQL Mapper 이다.
기본적으로 JdbcTemplate이 제공하는 대부분의 기능을 제공한다.
JdbcTemplate과 비교해서 MyBatis의 가장 매력적인 점은 SQL을 XML에 편리하게 작성할 수 있고 또 동적 쿼리를 매우 편리하게 작성할 수 있다는 점이다.
mybatis.type-aliases-package : 마이바티스에서 타입 정보를 사용할 때는 패키지 이름을 적어주어야 하는데, 여기에 명시하면 패키지 이름 을 생략할 수 있다. 지정한 패키지와 그 하위 패키지가 자동으로 인식된다. 여러 위치를 지정하려면 ,와 ; 로 구분하면 된다.
mybatis.configuration.map-underscore-to-camel-case : JdbcTemplate의 BeanPropertyRowMapper 처럼 언더바를 카멜로 자동 변경해주는 기능을 활성화 한다.
관례의 불일치
자바 객체에는 주로 camelCase 표기법을 사용한다. itemName 처럼 중간에 낙타 봉이 올라와 있는 표기법이다. 반면에 관계형 데이터베이스에서는 주로 언더스코어를 사용하는 snake_case 표기법을 사용한다.item_name 처럼 중간에 언더스코어를 사용하는 표기법이다.
이렇게 관례로 많이 사용하다 보니 map-underscore-to-camel-case 기능을 활성화 하면 언더스코어 표기법을 카멜로 자동 변환해준다. 따라서 DB에서 select item_name 으로 조회해도 객체의 itemName (setItemName()) 속성에 값이 정상 입력된다.
정리하면 해당 옵션을 켜면 snake_case는 자동으로 해결되니 그냥 두면 되고, 컬럼 이름과 객체 이름이 완전히 다른 경우에는 조회 SQL에서 별칭을 사용하면 된다. 예) - DB select item_name - 객체 name
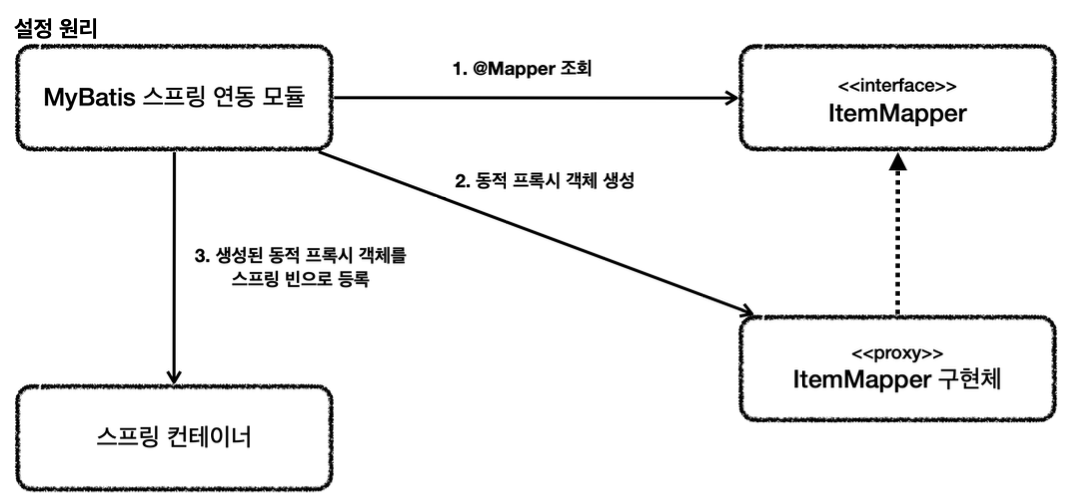
마이바티스 매핑 XML을 호출해주는 매퍼 인터페이스이다. 이 인터페이스에는 @Mapper 애노테이션을 붙여주어야 한다. 그래야 MyBatis에서 인식할 수 있다. 이 인터페이스의 메서드를 호출하면 다음에 보이는 xml 의 해당 SQL을 실행하고 결과를 돌려준다.
@Mapper
마이바티스(MyBatis) 프레임워크에서 사용되며, 인터페이스를 마이바티스의 매퍼로 표시한다. 이 애노테이션을 사용함으로써 해당 인터페이스의 메소드들이 SQL 쿼리와 매핑될 수 있게 되며, 마이바티스는 이를 통해 SQL 세션을 관리하고, 쿼리 실행 및 결과 매핑을 처리한다.
매퍼 인터페이스 표시: @Mapper 애노테이션은 특정 인터페이스가 마이바티스 매퍼 인터페이스임을 나타낸다. 이는 마이바티스에게 이 인터페이스의 메소드를 데이터베이스 쿼리와 매핑하기 위한 것임을 알린다.
SQL 세션 관리: 마이바티스는 @Mapper로 표시된 인터페이스를 사용하여 내부적으로 SQL 세션을 관리한다. 개발자는 SQL 세션을 직접 열고 닫을 필요 없이, 매퍼 인터페이스를 통해 데이터베이스 작업을 수행할 수 있다.
쿼리 실행 및 결과 매핑: 매퍼 인터페이스의 메소드는 SQL 쿼리나 명령어와 직접 연결된다. 마이바티스는 이 메소드들을 호출할 때 적절한 SQL 쿼리를 실행하고, 결과를 자바 객체로 매핑한다.
-void save() 메소드: 새로운 Item 객체를 데이터베이스에 저장한다. 이 작업은 XML 매핑 파일의 <insert> 태그를 통해 구현된다.
-void update() 메소드: 기존의 Item 객체를 업데이트한다. 이 때, @Param 애노테이션을 사용하여 메소드의 파라미터를 SQL 쿼리에 바인딩한다.
-findById() 메소드: 주어진 ID에 해당하는 Item 객체를 찾아 반환한다.
-findAll() 메소드: 조건에 맞는 모든 Item 객체를 찾아 리스트로 반환한다. 이 메소드는 동적 SQL을 사용하여 구현된다.
같은 위치에 실행할 SQL이 있는 XML 매핑 파일이 있어야한다.
참고로 자바 코드가 아니기 때문에 스프링 부트에서 src/main/resources 하위에 만들되, 패키지 위치는 맞추어 주어야 한다.
@Param
스프링 프레임워크의 일부로, 주로 스프링 데이터 JPA나 마이바티스(MyBatis) 같은 ORM(Object-Relational Mapping) 라이브러리에서 메소드 파라미터를 SQL 쿼리에 바인딩할 때 사용된다.
@Param 어노테이션을 사용하면 메소드 파라미터를 쿼리 내의 명시적인 파라미터로 전달할 수 있으며, 이는 코드의 가독성과 유지보수성을 향상시킨다.
메소드 파라미터를 XML 또는 어노테이션으로 작성된 SQL 쿼리에 바인딩할 수 있다. 마이바티스는 @Param 애노테이션을 통해 여러 파라미터를 쿼리에 전달할 때 특히 유용하다.
@Mapper
public interface UserMapper {
@Select("SELECT * FROM users WHERE username = #{username} AND age = #{age}")
User findUserByNameAndAge(@Param("username") String username, @Param("age") int age);
}
이 예시에서는 @Param 애노테이션을 사용하여 username과 age 두 파라미터를 SQL 쿼리에 바인딩한다. 마이바티스는 이 애노테이션을 통해 메소드 파라미터의 값을 쿼리의 #{username}과 #{age}에 동적으로 삽입한다.
ItemMapper 인터페이스의 구현체
MyBatis를 사용할 때, 일반적으로 인터페이스의 구현체를 직접 작성하지 않는다. 대신, MyBatis가 런타임에 마이바티스의 매퍼 XML 파일이나 어노테이션을 기반으로 자동으로 구현체를 생성한다.
매퍼 구현체
마이바티스 스프링 연동 모듈이 만들어주는 temMapper 의 구현체 덕분에 인터페이스 만으로 편리하게 XML 의 데이터를 찾아서 호출할 수 있다.
원래 마이바티스를 사용하려면 더 번잡한 코드를 거쳐야 하는데, 이런 부분을 인터페이스 하나로 매우 깔끔하고 편리하게 사용할 수 있다.
매퍼 구현체는 예외 변환까지 처리해준다. MyBatis에서 발생한 예외를 스프링 예외 추상화인 DataAccessException 에 맞게 변환해서 반환해준다. JdbcTemplate이 제공하는 예외 변환 기능을 여기서도 제공한다고 이해하면 된다.
매퍼 구현체 덕분에 마이바티스를 스프링에 편리하게 통합해서 사용할 수 있다.
매퍼 구현체를 사용하면 스프링 예외 추상화도 함께 적용된다.
마이바티스 스프링 연동 모듈이 많은 부분을 자동으로 설정해주는데, 데이터베이스 커넥션, 트랜잭션과 관련된 기능도 마이바티스와 함께 연동하고, 동기화해준다.
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="hello.itemservice.repository.mybatis.ItemMapper">
<insert id="save" useGeneratedKeys="true" keyProperty="id">
insert into item (item_name, price, quantity)
values (#{itemName}, #{price}, #{quantity})
</insert>
<update id="update">
update item
set item_name=#{updateParam.itemName},
price=#{updateParam.price},
quantity=#{updateParam.quantity}
where id = #{id}
</update>
<select id="findById" resultType="Item">
select id, item_name, price, quantity
from item
where id = #{id}
</select>
<select id="findAll" resultType="Item">
select id, item_name, price, quantity
from item
<where>
<if test="itemName != null and itemName != ''">
and item_name like concat('%',#{itemName},'%')
</if>
<if test="maxPrice != null">
and price <= #{maxPrice}
</if>
</where>
</select>
</mapper>
namespace : 앞서 만든 매퍼 인터페이스를 지정하면 된다.
참고 - XML 파일 경로 수정하기
XML 파일을 원하는 위치에 두고 싶으면 application.properties 에 다음과 같이 설정하면 된다. mybatis.mapper-locations=classpath:mapper/**/*.xml 이렇게 하면 resources/mapper 를 포함한 그 하위 폴더에 있는 XML을 XML 매핑 파일로 인식한다. 이 경우 파일 이름은 자유롭게 설정해도 된다.
save 메소드에 해당하는 SQL 쿼리를 정의한다. useGeneratedKeys="true"와 keyProperty="id"를 설정함으로써, 데이터베이스에 새로운 레코드가 삽입될 때 생성된 키(예: auto-increment ID)를 Item 객체의 id 필드에 자동으로 할당한다.
Insert SQL은 <insert> 를 사용하면 된다. id 에는 매퍼 인터페이스에 설정한 메서드 이름을 지정하면 된다. 여기서는 메서드 이름이 save() 이므로 save 로 지정하면 된다.
파라미터는 #{} 문법을 사용하면 된다. 그리고 매퍼에서 넘긴 객체의 프로퍼티 이름을 적어주면 된다. #{} 문법을 사용하면PreparedStatement 를 사용한다. JDBC의 ? 를 치환한다 생각하면 된다.
useGeneratedKeys 는 데이터베이스가 키를 생성해 주는 IDENTITY 전략일 때 사용한다. keyProperty 는 생성되는 키의 속성 이름을 지정한다. Insert가 끝나면 item 객체의 id 속성에 생성된 값이 입력된다.
<update> 태그
import org.apache.ibatis.annotations.Param;
void update(@Param("id") Long id, @Param("updateParam") ItemUpdateDto updateParam);
<update id="update">
update item
set item_name=#{updateParam.itemName},
price=#{updateParam.price},
quantity=#{updateParam.quantity}
where id = #{id}
</update>
update 메소드의 SQL 쿼리를 정의한다. 이 쿼리는 updateParam 객체의 필드 값을 사용하여 특정 id를 가진 레코드를 업데이트한다.
Update SQL은 <update> 를 사용하면 된다. 여기서는 파라미터가 Long id , ItemUpdateDto updateParam 으로 2개이다. 파라미터가 1개만 있으면 @Param 을 지정하지 않아도 되지만, 파라미터가 2개 이상이면 @Param 으로 이름을 지정해서 파라미터를 구분해야 한다.
<select> 태그
Optional<Item> findById(Long id);
<select id="findById" resultType="Item">
select id, item_name, price, quantity
from item
where id = #{id}
</select>
findById와 findAll 메소드에 해당하는 SQL 쿼리를 정의한다. findById는 단일 Item 객체를 반환하는 반면, findAll은 조건에 따라 여러 Item 객체를 리스트로 반환한다. findAll 메소드에서는 <where> 및 <if> 태그를 사용한 동적 SQL을 통해, itemName이나 maxPrice 같은 조건에 따라 다양한 검색 쿼리를 실행할 수 있다.
Select SQL은 <select> 를 사용하면 된다.
resultType 은 반환 타입을 명시하면 된다. 여기서는 결과를 Item 객체에 매핑한다.
application.properties 에 mybatis.type-aliases- package=hello.itemservice.domain 속성을 지정한 덕분에 모든 패키지 명을 다 적지는 않아도 된다. 그렇지 않으면 모든 패키지 명을 다 적어야 한다. JdbcTemplate의 BeanPropertyRowMapper 처럼 SELECT SQL의 결과를 편리하게 객체로 바로 변환해준다.
자바 코드에서 반환 객체가 하나이면 Item , Optional<Item> 과 같이 사용하면 되고, 반환 객체가 하나 이상 이면 컬렉션을 사용하면 된다. 주로 List 를 사용한다.
findAll - 동적 SQL
List<Item> findAll(ItemSearchCond itemSearch);
<select id="findAll" resultType="Item">
select id, item_name, price, quantity
from item
<where>
<if test="itemName != null and itemName != ''">
and item_name like concat('%',#{itemName},'%')
</if>
<if test="maxPrice != null">
and price <= #{maxPrice}
</if>
</where>
</select>
findAll 메소드의 SQL 쿼리에서 와 를 사용하여 조건에 따라 다르게 실행되는 SQL을 구현한다. 예를 들어, itemName 조건이 주어지면 item_name 컬럼에 대해 LIKE 검색을 수행하고, maxPrice 조건이 주어지면 가격에 대한 비교 조건을 적용한다.
이와 같은 동적 SQL은 검색 조건이 유연하게 변경될 수 있는 경우에 매우 유용하다.
Mybatis는 <where> , <if> 같은 동적 쿼리 문법을 통해 편리한 동적 쿼리를 지원한다. <if> 는 해당 조건이 만족하면 구문을 추가한다. <where> 은 적절하게 where 문장을 만들어준다.
예제에서 <if> 가 모두 실패하게 되면 SQL where 를 만들지 않는다.
예제에서 <if> 가 하나라도 성공하면 처음 나타나는 and 를 where 로 변환해준다.
XML 특수문자
→and price <= #{maxPrice}
여기에보면 <= 를사용하지않고 <= 를사용한것을확인할수있다.그 이유는 XML에서는 데이터 영역에 <, > 같은 특수문자를 사용할 수 없기 때문이다.
이유는 간단한데, XML에서 TAG가 시작하거나 종료할때 <, >와 같은 특수문자를 사용하기 때문이다.
마이바티스가 제공하는 최고의 기능이자 마이바티스를 사용하는 이유는 바로 동적 SQL 기능 때문이다.
동적 쿼리를 위해 제공되는 기능은 다음과 같다.
if
choose (when, otherwise)
trim (where, set)
foreach
if
<select id="findActiveBlogWithTitleLike" resultType="Blog">
SELECT * FROM BLOG
WHERE state = ‘ACTIVE’
<if test="title != null">
AND title like #{title}
</if>
</select>
해당 조건에 따라 값을 추가할지 말지 판단한다.
내부의 문법은 OGNL을 사용한다.
choose, when, otherwise
<select id="findActiveBlogLike" resultType="Blog">
SELECT * FROM BLOG WHERE state = ‘ACTIVE’
<choose>
<when test="title != null">
AND title like #{title}
</when>
<when test="author != null and author.name != null">
AND author_name like #{author.name}
</when>
<otherwise>
AND featured = 1
</otherwise>
</choose>
</select>
자바의 switch 구문과 유사한 구문도 사용할 수 있다.
trim, where, set
<select id="findActiveBlogLike" resultType="Blog">
SELECT * FROM BLOG
WHERE
<if test="state != null">
state = #{state}
</if>
<if test="title != null">
AND title like #{title}
</if>
<if test="author != null and author.name != null">
AND author_name like #{author.name}
</if>
</select>
이 예제의 문제점은 문장을 모두 만족하지 않을 때 발생한다.
모두 만족하지 않게 되면 아래와 같은 SQL이 완성된다. 이는 문법 오류다.
SELECT * FROM BLOG
WHERE
title 만 만족할 때도 문제가 발생한다.
SELECT * FROM BLOG
WHERE
AND title like ‘someTitle’
결국 WHERE 문을 언제 넣어야 할지 상황에 따라서 동적으로 달라지는 문제가 있다. <where> 를 사용하면 이런 문제를 해결할 수 있다.
<select id="findActiveBlogLike"
resultType="Blog">
SELECT * FROM BLOG
<where>
<if test="state != null">
state = #{state}
</if>
<if test="title != null">
AND title like #{title}
</if>
<if test="author != null and author.name != null">
AND author_name like #{author.name}
</if>
</where>
</select>
<where> 는 문장이 없으면 where 를 추가하지 않는다. 문장이 있으면 where 를 추가한다. 만약 and 가 먼저 시작 된다면 and 를 지운다.
다음과 같이 trim 이라는 기능으로 사용해도 된다. 이렇게 정의하면 <where> 와 같은 기능을 수행한다.