![[Spring Data JPA] Spring Data JPA](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2Fdkzxgg%2FbtsI0y0Jv3E%2FAAAAAAAAAAAAAAAAAAAAAP2d0mXwFjAEbepIdPuQK9urB2mrmC6OGRHJscofYtpo%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1774969199%26allow_ip%3D%26allow_referer%3D%26signature%3Db47coOW4Z%252Bp17RgLvGppHA234m0%253D)

이 글은 인프런 김영한님의 Spring 강의를 바탕으로 개인적인 정리를 위해 작성한 글입니다.
Spring Data JPA는 스프링 프레임워크에서 제공하는 데이터 접근 계층(Data Access Layer)을 쉽게 구현할 수 있도록 지원하는 모듈이다.
JPA(Java Persistence API)를 사용하여 데이터베이스와의 상호작용을 단순화하고, 보일러플레이트 코드를 최소화하는 데 중점을 둔다.
레포지토리 추상화
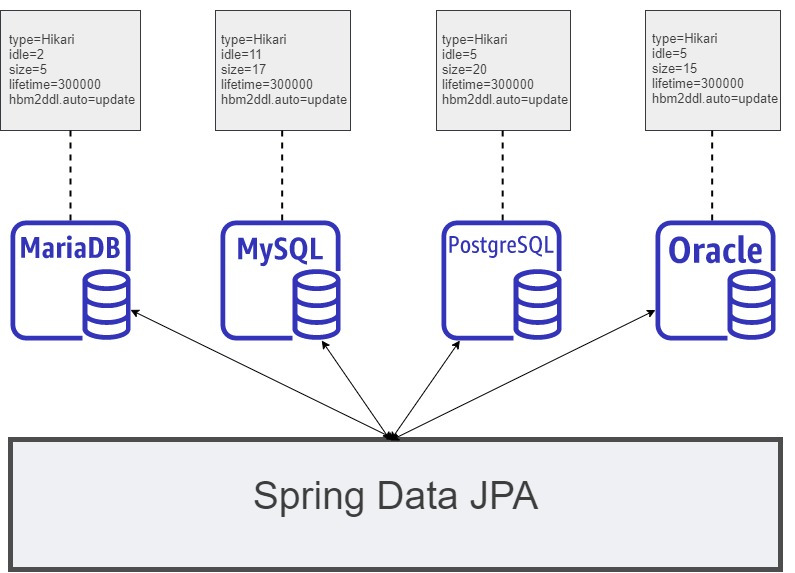
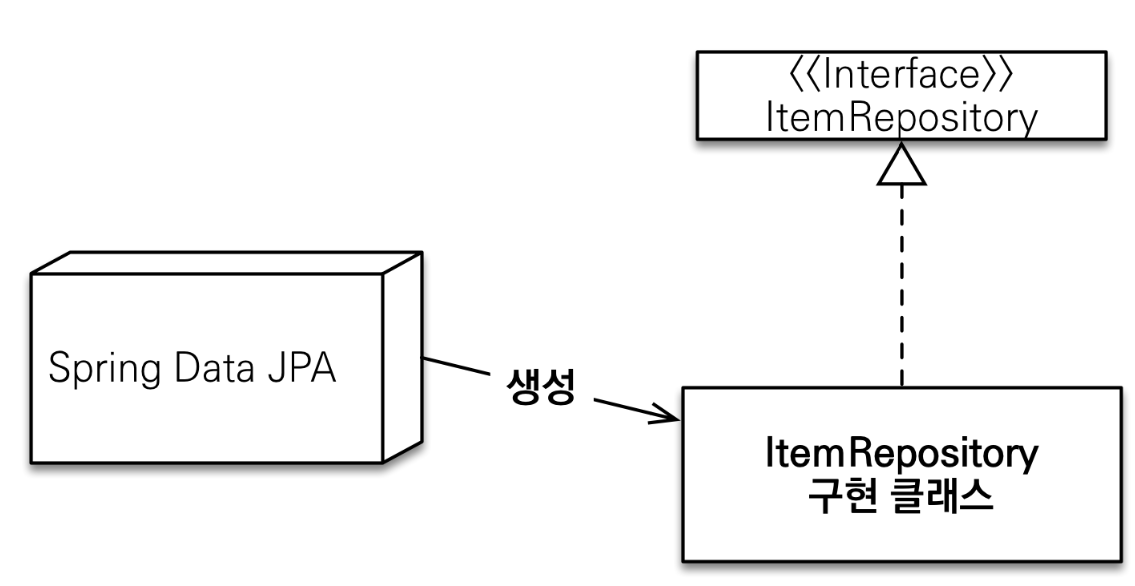
- Spring Data JPA는 JPA 엔티티를 관리하기 위한 기본적인 CRUD(Create, Read, Update, Delete) 작업을 자동으로 생성해주는 레포지토리 인터페이스를 제공한다.
- JpaRepository, CrudRepository, PagingAndSortingRepository와 같은 기본 인터페이스를 확장하면, 수동으로 구현하지 않고도 대부분의 데이터 접근 작업을 처리할 수 있다.
- 제네릭은 <엔티티 타입, 식별자 타입> 설정
import org.springframework.data.jpa.repository.JpaRepository;
public interface ItemRepository extends JpaRepository<Item, Long> { //제네릭은 <엔티티 타입, 식별자 타입> 설정
}이 인터페이스만 정의하면, Spring Data JPA는 기본적인 CRUD 메서드(예: save, findById, findAll, deleteById 등)를 자동으로 구현한다.

쿼리 메서드 생성
Spring Data JPA는 메서드 이름을 기반으로 쿼리를 자동으로 생성할 수 있다.
예를 들어, findByUsername이라는 메서드를 정의하면, Spring Data JPA는 이 메서드를 호출하여 username 필드를 기반으로 데이터를 조회하는 쿼리를 생성한다.
public interface MemberRepository extends JpaRepository<Member, Long> { //제네릭은 <엔티티 타입, 식별자 타입> 설정
List<Member> findByUsername(String username);
}여기서 findByUsername 메서드는 username 필드 값을 기준으로 Member 엔티티를 조회하는 SQL 쿼리를 자동으로 생성한다.
JPQL 및 네이티브 쿼리 지원
복잡한 쿼리가 필요한 경우, @Query 어노테이션을 사용하여 JPQL(Java Persistence Query Language) 또는 네이티브 SQL 쿼리를 직접 정의할 수 있다.
import org.springframework.data.jpa.repository.Query;
import org.springframework.data.repository.query.Param;
public interface MemberRepository extends JpaRepository<Member, Long> {
@Query("SELECT m FROM Member m WHERE m.username = :username AND m.age = :age")
List<Member> findUser(@Param("username") String username, @Param("age") int age);
}이 예제는 username과 age를 매개변수로 받아 특정 조건에 맞는 Member를 조회하는 JPQL 쿼리를 정의한 것이다.
페이징 및 정렬 기능
Spring Data JPA는 페이징과 정렬 기능을 쉽게 구현할 수 있도록 지원한다.
메서드에 Pageable 또는 Sort 파라미터를 추가하면 자동으로 페이징 및 정렬된 결과를 제공한다.
public interface MemberRepository extends JpaRepository<Member, Long> {
Page<Member> findByAge(int age, Pageable pageable);
}위 예제에서 findByAge 메서드는 특정 나이의 Member들을 페이징된 형태로 반환한다.
주요 메서드
save(S entity)
주어진 엔티티를 저장한다. 이때, 만약 엔티티가 새로 생성된 것이라면 데이터베이스에 삽입(insert)되고, 이미 존재하는 엔티티라면 병합(merge)되어 업데이트된다.
- 새로운 엔티티: EntityManager.persist()가 호출되어 새로운 엔티티로 데이터베이스에 추가된다.
- 기존 엔티티: EntityManager.merge()가 호출되어 기존 엔티티를 업데이트한다.
delete(T entity)
주어진 엔티티를 데이터베이스에서 삭제한다.
- EntityManager.remove() 메서드를 호출하여 엔티티를 영속성 컨텍스트에서 제거한 후, 데이터베이스에서도 삭제된다.
findById(ID id)
주어진 식별자(ID)에 해당하는 엔티티를 조회한다.
- EntityManager.find()를 호출하여 데이터베이스에서 식별자에 해당하는 엔티티를 조회하고, 조회된 엔티티를 반환한다.
- 반환 타입은 Optional<T>로, 엔티티가 존재하지 않을 경우 Optional.empty()를 반환한다.
getOne(ID id)
주어진 식별자(ID)에 해당하는 엔티티의 프록시 객체를 조회한다.
- EntityManager.getReference()를 호출하여 해당 엔티티의 프록시 객체를 반환한다.
- 실제로 데이터베이스에 쿼리가 날아가는 것이 아니라, 엔티티의 참조만을 가지고 있는 프록시가 반환되며, 이 프록시 객체는 실제 데이터가 필요할 때 지연 로딩(Lazy Loading) 방식으로 데이터베이스에서 데이터를 가져온다.
findAll(...)
데이터베이스에 있는 모든 엔티티를 조회한다. 이때, 정렬(Sort)이나 페이징(Pageable) 조건을 파라미터로 전달할 수 있다.
- EntityManager.createQuery()를 통해 모든 엔티티를 조회하는 쿼리를 실행한다. Sort와 Pageable을 파라미터로 전달하면 정렬된 결과 또는 페이징된 결과를 반환한다.
- 페이징된 결과를 받을 경우, 반환 타입은 Page<T>이며, 정렬된 결과를 받을 경우 List<T>가 반환된다.
'Back-End > JPA' 카테고리의 다른 글
| [Spring Data JPA] 확장 기능 (0) | 2024.08.14 |
|---|---|
| [Spring Data JPA] 쿼리 메서드 기능 (0) | 2024.08.13 |
| [JPA] 컬렉션 조회 최적화(OneToMany) (0) | 2024.08.11 |
| [JPA] 지연 로딩과 조회 성능 최적화(ManyToOne, OneToOne) (0) | 2024.08.10 |
| [JPA] 병합(Merge)과 변경 감지(Dirty Checking) (0) | 2024.08.05 |
![[Spring Data JPA] 확장 기능](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FcmfHDB%2FbtsI0LTP0Md%2FAAAAAAAAAAAAAAAAAAAAAKn7SMDRBJAKLRJ7uXuLohDxhNSjjoNrR4XgsuFZhYx6%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1774969199%26allow_ip%3D%26allow_referer%3D%26signature%3D2NB27tJRQHoLFy6rBuFvGk8qAqk%253D)
![[Spring Data JPA] 쿼리 메서드 기능](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2Fcaedyj%2FbtsI1mSLGez%2FAAAAAAAAAAAAAAAAAAAAAJ6MLLV2GgxQ4alp15TbkNfB-ypIU26n20J_0Ix0FDvZ%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1774969199%26allow_ip%3D%26allow_referer%3D%26signature%3DoQ%252BEuv6ZC0J6h34dXlLU1XMJ64c%253D)
![[JPA] 컬렉션 조회 최적화(OneToMany)](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FcPEBjp%2FbtsIZJ2TTLZ%2FAAAAAAAAAAAAAAAAAAAAABa-gwpUru2z5Y4agoyHx7GTDB6vNTfN513TUdKEhRCh%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1774969199%26allow_ip%3D%26allow_referer%3D%26signature%3DeM8dkMP%252F5ZALE409vbiW6Dxv2zI%253D)
![[JPA] 지연 로딩과 조회 성능 최적화(ManyToOne, OneToOne)](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2Fdd6go1%2FbtsIZZEt1Wz%2FAAAAAAAAAAAAAAAAAAAAAKf-_-lXHghZFafGB3Tf22OWBMFVxQbeKCJ3Tz53kLIM%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1774969199%26allow_ip%3D%26allow_referer%3D%26signature%3DtW3ZGp4CKPO45poR3qJfii0YM4s%253D)